 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Graph Learning with Unique Optimal Solutions
Feb 21, 2021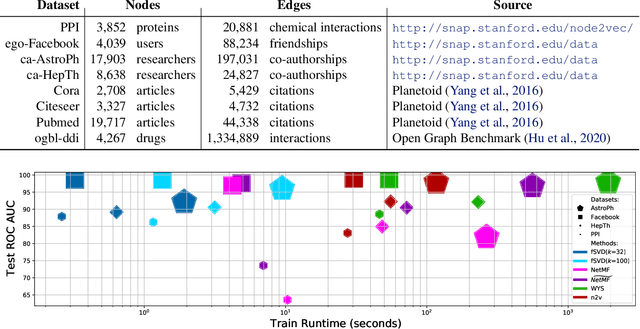
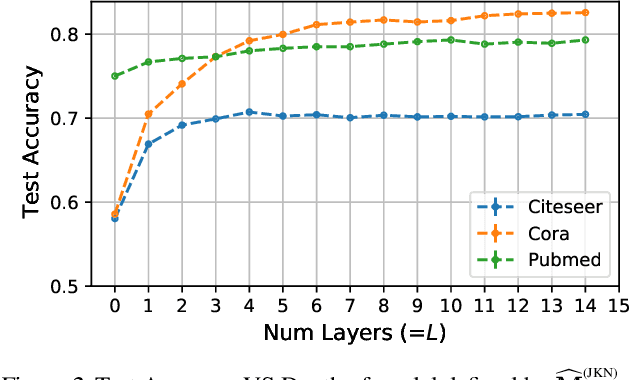
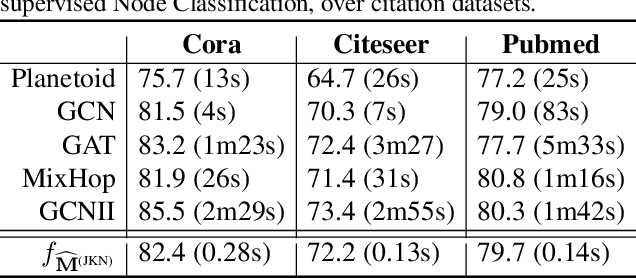
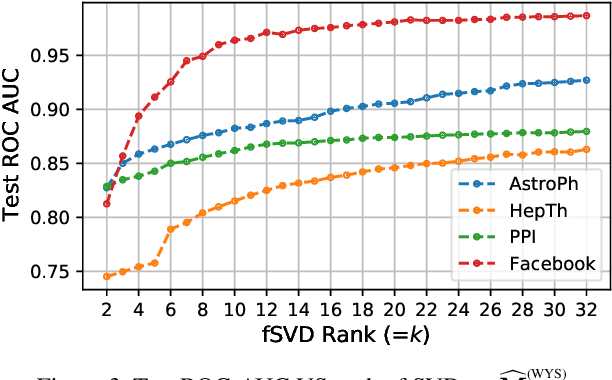
Graph Representation Learning (GRL) has been advancing at an unprecedented rate. However, many results rely on careful design and tuning of architectures, objectives, and training schemes. We propose efficient GRL methods that optimize convexified objectives with known closed form solutions. Guaranteed convergence to a global optimum releases practitioners from hyper-parameter and architecture tuning. Nevertheless, our proposed method achieves competitive or state-of-the-art performance on popular GRL tasks while providing orders of magnitude speedup. Although the design matrix ($\mathbf{M}$) of our objective is expensive to compute, we exploit results from random matrix theory to approximate solutions in linear time while avoiding an explicit calculation of $\mathbf{M}$. Our code is online: http://github.com/samihaija/tf-fsvd
Graph Traversal with Tensor Functionals: A Meta-Algorithm for Scalable Learning
Feb 08, 2021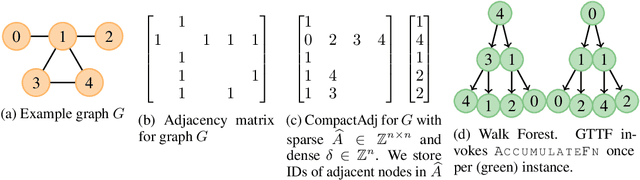
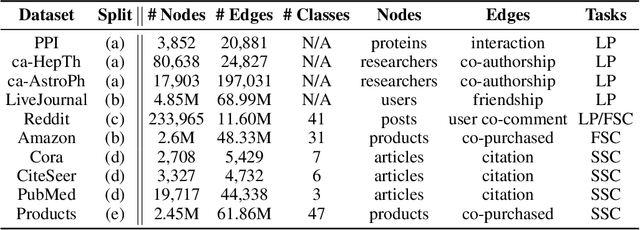


Graph Representation Learning (GRL) methods have impacted fields from chemistry to social science. However, their algorithmic implementations are specialized to specific use-cases e.g.message passing methods are run differently from node embedding ones. Despite their apparent differences, all these methods utilize the graph structure, and therefore, their learning can be approximated with stochastic graph traversals. We propose Graph Traversal via Tensor Functionals(GTTF), a unifying meta-algorithm framework for easing the implementation of diverse graph algorithms and enabling transparent and efficient scaling to large graphs. GTTF is founded upon a data structure (stored as a sparse tensor) and a stochastic graph traversal algorithm (described using tensor operations). The algorithm is a functional that accept two functions, and can be specialized to obtain a variety of GRL models and objectives, simply by changing those two functions. We show for a wide class of methods, our algorithm learns in an unbiased fashion and, in expectation, approximates the learning as if the specialized implementations were run directly. With these capabilities, we scale otherwise non-scalable methods to set state-of-the-art on large graph datasets while being more efficient than existing GRL libraries - with only a handful of lines of code for each method specialization. GTTF and its various GRL implementations are on: https://github.com/isi-usc-edu/gttf.
DiSCoL: Toward Engaging Dialogue Systems through Conversational Line Guided Response Generation
Feb 03, 2021
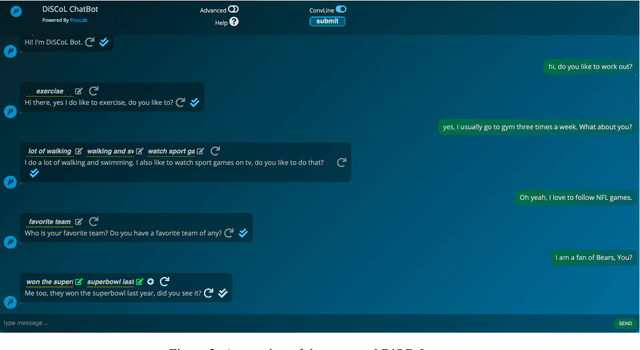
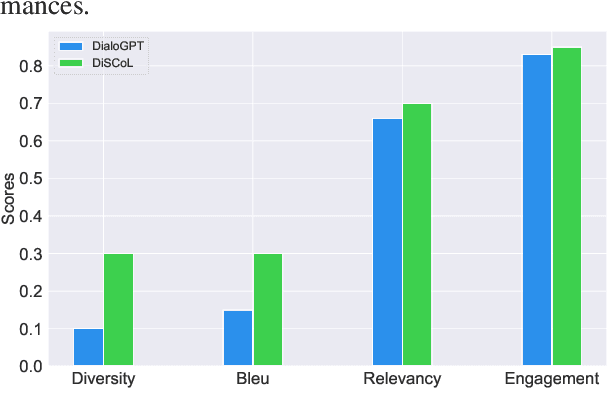
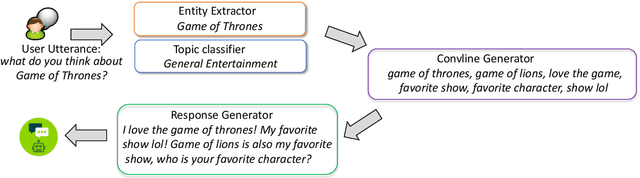
Having engaging and informative conversations with users is the utmost goal for open-domain conversational systems. Recent advances in transformer-based language models and their applications to dialogue systems have succeeded to generate fluent and human-like responses. However, they still lack control over the generation process towards producing contentful responses and achieving engaging conversations. To achieve this goal, we present \textbf{DiSCoL} (\textbf{Di}alogue \textbf{S}ystems through \textbf{Co}versational \textbf{L}ine guided response generation). DiSCoL is an open-domain dialogue system that leverages conversational lines (briefly \textbf{convlines}) as controllable and informative content-planning elements to guide the generation model produce engaging and informative responses. Two primary modules in DiSCoL's pipeline are conditional generators trained for 1) predicting relevant and informative convlines for dialogue contexts and 2) generating high-quality responses conditioned on the predicted convlines. Users can also change the returned convlines to \textit{control} the direction of the conversations towards topics that are more interesting for them. Through automatic and human evaluations, we demonstrate the efficiency of the convlines in producing engaging conversations.
Likelihood Ratio Exponential Families
Jan 15, 2021
The exponential family is well known in machine learning and statistical physics as the maximum entropy distribution subject to a set of observed constraints, while the geometric mixture path is common in MCMC methods such as annealed importance sampling. Linking these two ideas, recent work has interpreted the geometric mixture path as an exponential family of distributions to analyze the thermodynamic variational objective (TVO). We extend these likelihood ratio exponential families to include solutions to rate-distortion (RD) optimization, the information bottleneck (IB) method, and recent rate-distortion-classification approaches which combine RD and IB. This provides a common mathematical framework for understanding these methods via the conjugate duality of exponential families and hypothesis testing. Further, we collect existing results to provide a variational representation of intermediate RD or TVO distributions as a minimizing an expectation of KL divergences. This solution also corresponds to a size-power tradeoff using the likelihood ratio test and the Neyman Pearson lemma. In thermodynamic integration bounds such as the TVO, we identify the intermediate distribution whose expected sufficient statistics match the log partition function.
Exacerbating Algorithmic Bias through Fairness Attacks
Dec 16, 2020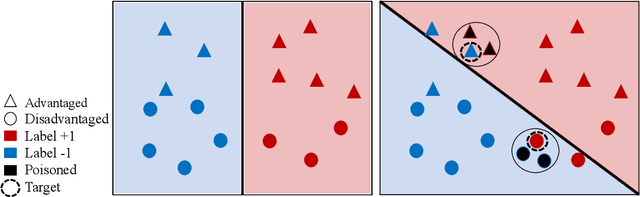
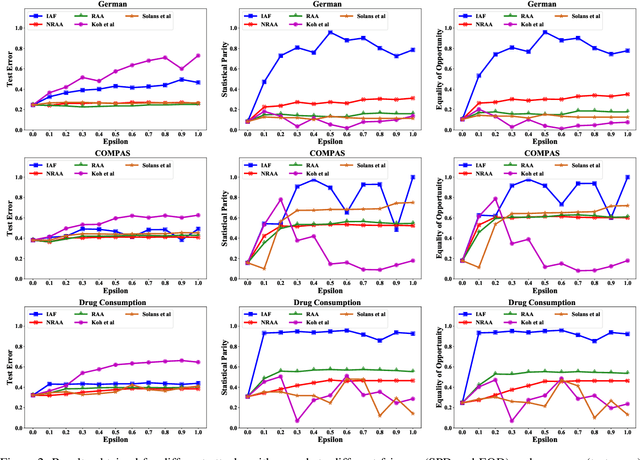
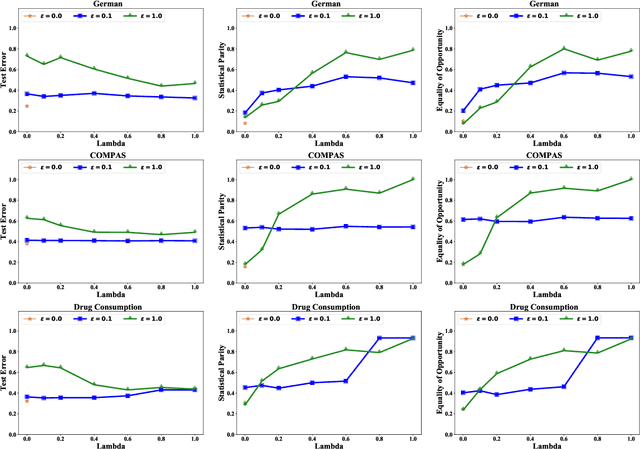
Algorithmic fairness has attracted significant attention in recent years, with many quantitative measures suggested for characterizing the fairness of different machine learning algorithms. Despite this interest, the robustness of those fairness measures with respect to an intentional adversarial attack has not been properly addressed. Indeed, most adversarial machine learning has focused on the impact of malicious attacks on the accuracy of the system, without any regard to the system's fairness. We propose new types of data poisoning attacks where an adversary intentionally targets the fairness of a system. Specifically, we propose two families of attacks that target fairness measures. In the anchoring attack, we skew the decision boundary by placing poisoned points near specific target points to bias the outcome. In the influence attack on fairness, we aim to maximize the covariance between the sensitive attributes and the decision outcome and affect the fairness of the model. We conduct extensive experiments that indicate the effectiveness of our proposed attacks.
Annealed Importance Sampling with q-Paths
Dec 14, 2020
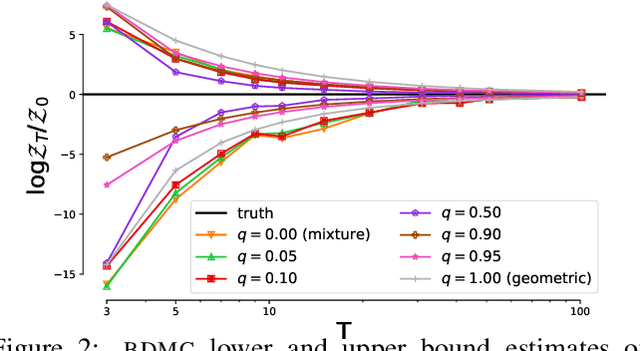

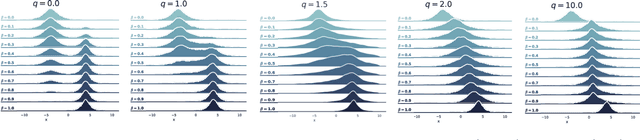
Annealed importance sampling (AIS) is the gold standard for estimating partition functions or marginal likelihoods, corresponding to importance sampling over a path of distributions between a tractable base and an unnormalized target. While AIS yields an unbiased estimator for any path, existing literature has been primarily limited to the geometric mixture or moment-averaged paths associated with the exponential family and KL divergence. We explore AIS using $q$-paths, which include the geometric path as a special case and are related to the homogeneous power mean, deformed exponential family, and $\alpha$-divergence.
MUSCLE: Strengthening Semi-Supervised Learning Via Concurrent Unsupervised Learning Using Mutual Information Maximization
Nov 30, 2020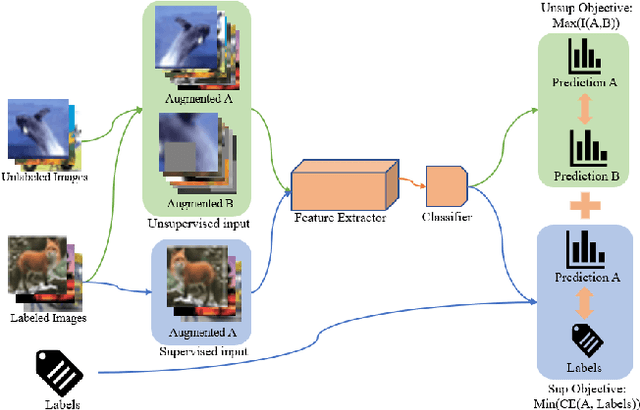
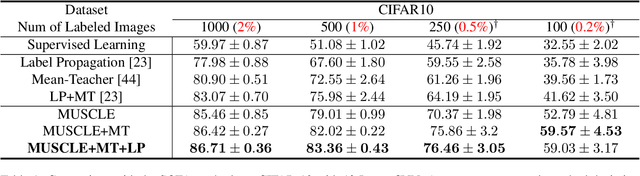

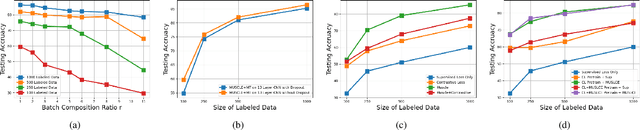
Deep neural networks are powerful, massively parameterized machine learning models that have been shown to perform well in supervised learning tasks. However, very large amounts of labeled data are usually needed to train deep neural networks. Several semi-supervised learning approaches have been proposed to train neural networks using smaller amounts of labeled data with a large amount of unlabeled data. The performance of these semi-supervised methods significantly degrades as the size of labeled data decreases. We introduce Mutual-information-based Unsupervised & Semi-supervised Concurrent LEarning (MUSCLE), a hybrid learning approach that uses mutual information to combine both unsupervised and semi-supervised learning. MUSCLE can be used as a stand-alone training scheme for neural networks, and can also be incorporated into other learning approaches. We show that the proposed hybrid model outperforms state of the art on several standard benchmarks, including CIFAR-10, CIFAR-100, and Mini-Imagenet. Furthermore, the performance gain consistently increases with the reduction in the amount of labeled data, as well as in the presence of bias. We also show that MUSCLE has the potential to boost the classification performance when used in the fine-tuning phase for a model pre-trained only on unlabeled data.
One-shot Learning for Temporal Knowledge Graphs
Oct 23, 2020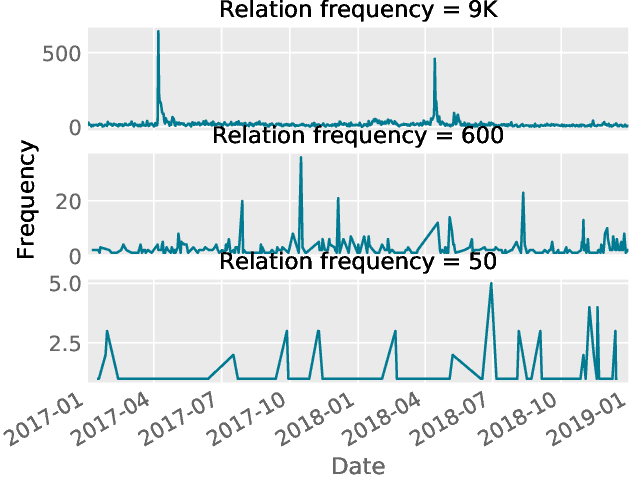
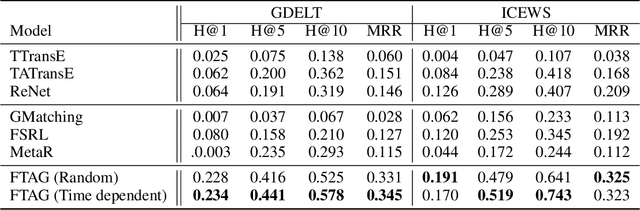
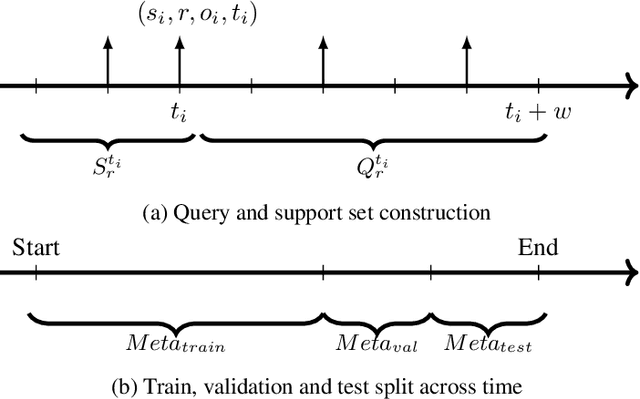

Most real-world knowledge graphs are characterized by a long-tail relation frequency distribution where a significant fraction of relations occurs only a handful of times. This observation has given rise to recent interest in low-shot learning methods that are able to generalize from only a few examples. The existing approaches, however, are tailored to static knowledge graphs and not easily generalized to temporal settings, where data scarcity poses even bigger problems, e.g., due to occurrence of new, previously unseen relations. We address this shortcoming by proposing a one-shot learning framework for link prediction in temporal knowledge graphs. Our proposed method employs a self-attention mechanism to effectively encode temporal interactions between entities, and a network to compute a similarity score between a given query and a (one-shot) example. Our experiments show that the proposed algorithm outperforms the state of the art baselines for two well-studied benchmarks while achieving significantly better performance for sparse relations.
Leveraging Clickstream Trajectories to Reveal Low-Quality Workers in Crowdsourced Forecasting Platforms
Sep 04, 2020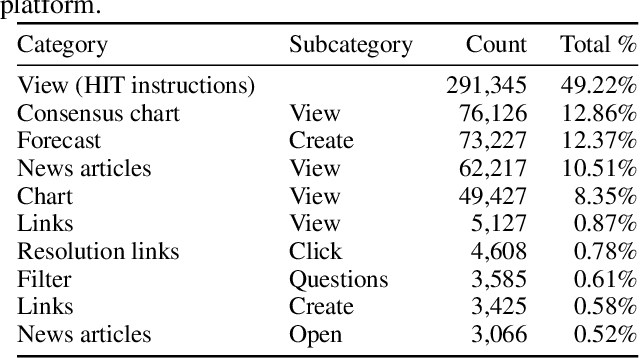
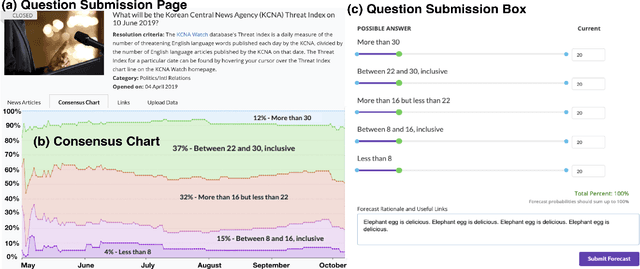
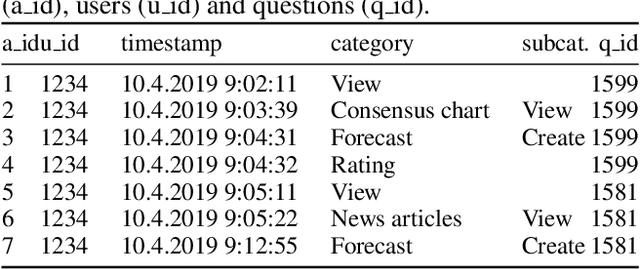
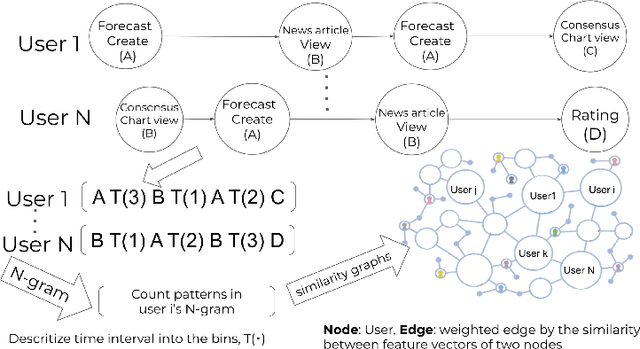
Crowdwork often entails tackling cognitively-demanding and time-consuming tasks. Crowdsourcing can be used for complex annotation tasks, from medical imaging to geospatial data, and such data powers sensitive applications, such as health diagnostics or autonomous driving. However, the existence and prevalence of underperforming crowdworkers is well-recognized, and can pose a threat to the validity of crowdsourcing. In this study, we propose the use of a computational framework to identify clusters of underperforming workers using clickstream trajectories. We focus on crowdsourced geopolitical forecasting. The framework can reveal different types of underperformers, such as workers with forecasts whose accuracy is far from the consensus of the crowd, those who provide low-quality explanations for their forecasts, and those who simply copy-paste their forecasts from other users. Our study suggests that clickstream clustering and analysis are fundamental tools to diagnose the performance of crowdworkers in platforms leveraging the wisdom of crowds.
Compressing Deep Neural Networks via Layer Fusion
Jul 29, 2020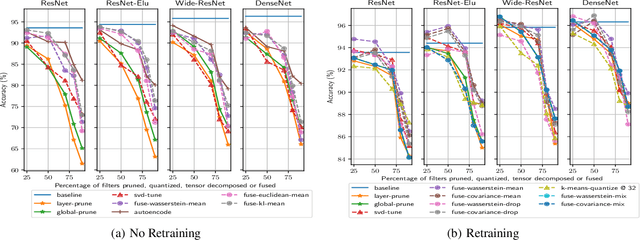
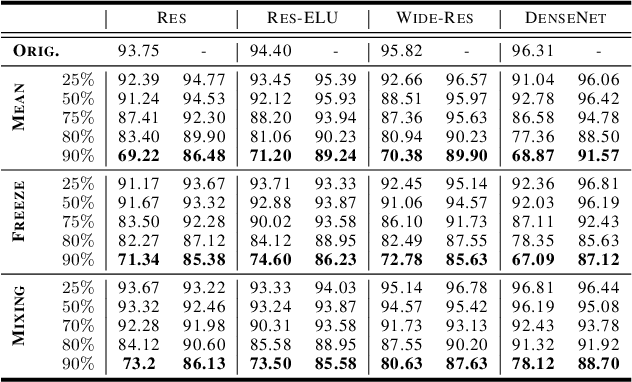
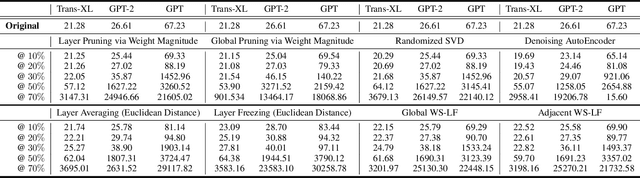
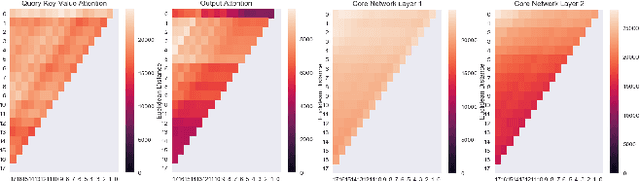
This paper proposes \textit{layer fusion} - a model compression technique that discovers which weights to combine and then fuses weights of similar fully-connected, convolutional and attention layers. Layer fusion can significantly reduce the number of layers of the original network with little additional computation overhead, while maintaining competitive performance. From experiments on CIFAR-10, we find that various deep convolution neural networks can remain within 2\% accuracy points of the original networks up to a compression ratio of 3.33 when iteratively retrained with layer fusion. For experiments on the WikiText-2 language modelling dataset where pretrained transformer models are used, we achieve compression that leads to a network that is 20\% of its original size while being within 5 perplexity points of the original network. We also find that other well-established compression techniques can achieve competitive performance when compared to their original networks given a sufficient number of retraining steps. Generally, we observe a clear inflection point in performance as the amount of compression increases, suggesting a bound on the amount of compression that can be achieved before an exponential degradation in performance.