 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-performance Semantic Segmentation Using Very Deep Fully Convolutional Networks
Apr 15, 2016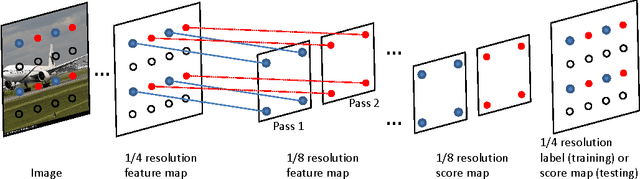
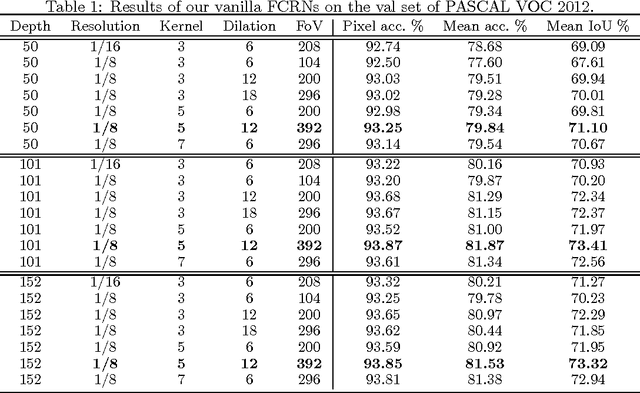
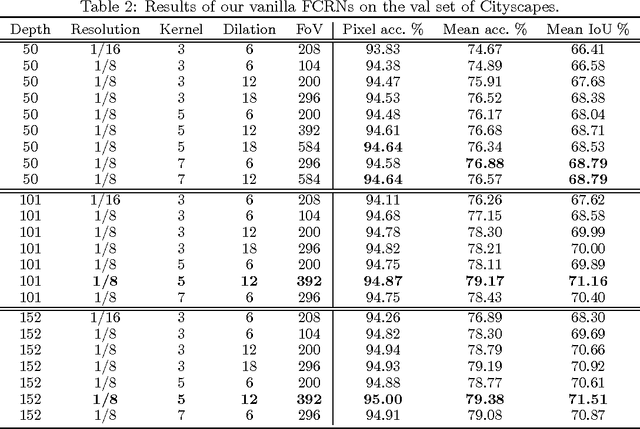
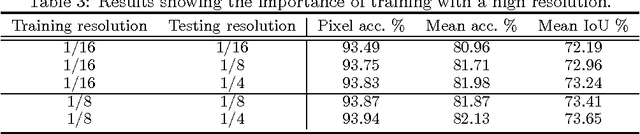
We propose a method for high-performance semantic image segmentation (or semantic pixel labelling) based on very deep residual networks, which achieves the state-of-the-art performance. A few design factors are carefully considered to this end. We make the following contributions. (i) First, we evaluate different variations of a fully convolutional residual network so as to find the best configuration, including the number of layers, the resolution of feature maps, and the size of field-of-view. Our experiments show that further enlarging the field-of-view and increasing the resolution of feature maps are typically beneficial, which however inevitably leads to a higher demand for GPU memories. To walk around the limitation, we propose a new method to simulate a high resolution network with a low resolution network, which can be applied during training and/or testing. (ii) Second, we propose an online bootstrapping method for training. We demonstrate that online bootstrapping is critically important for achieving good accuracy. (iii) Third we apply the traditional dropout to some of the residual blocks, which further improves the performance. (iv) Finally, our method achieves the currently best mean intersection-over-union 78.3\% on the PASCAL VOC 2012 dataset, as well as on the recent dataset Cityscapes.
Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources
Apr 14, 2016

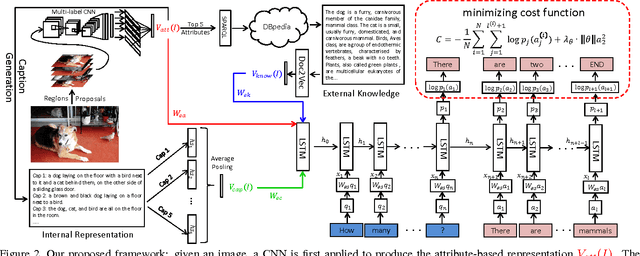
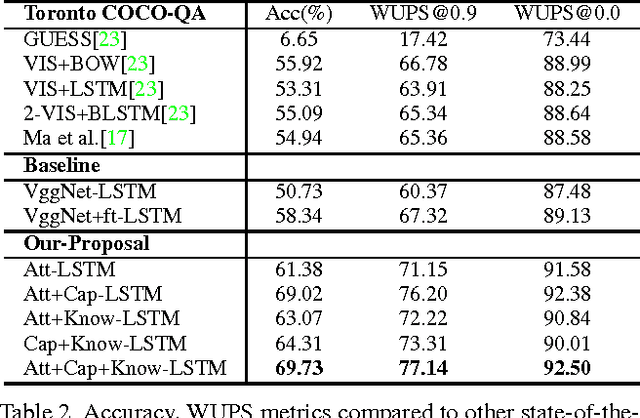
We propose a method for visual question answering which combines an internal representation of the content of an image with information extracted from a general knowledge base to answer a broad range of image-based questions. This allows more complex questions to be answered using the predominant neural network-based approach than has previously been possible. It particularly allows questions to be asked about the contents of an image, even when the image itself does not contain the whole answer. The method constructs a textual representation of the semantic content of an image, and merges it with textual information sourced from a knowledge base, to develop a deeper understanding of the scene viewed. Priming a recurrent neural network with this combined information, and the submitted question, leads to a very flexible visual question answering approach. We are specifically able to answer questions posed in natural language, that refer to information not contained in the image. We demonstrate the effectiveness of our model on two publicly available datasets, Toronto COCO-QA and MS COCO-VQA and show that it produces the best reported results in both cases.
Less is more: zero-shot learning from online textual documents with noise suppression
Apr 05, 2016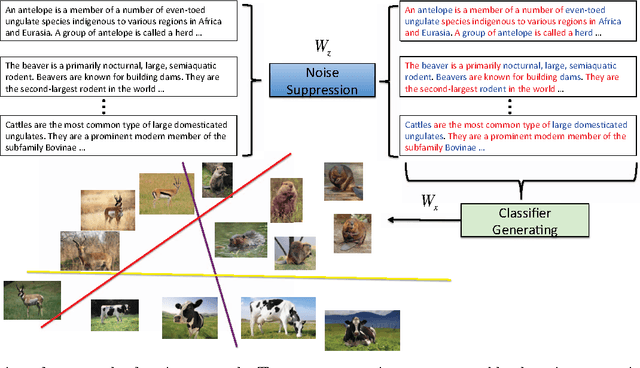
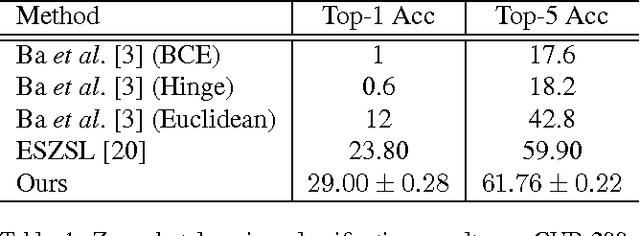
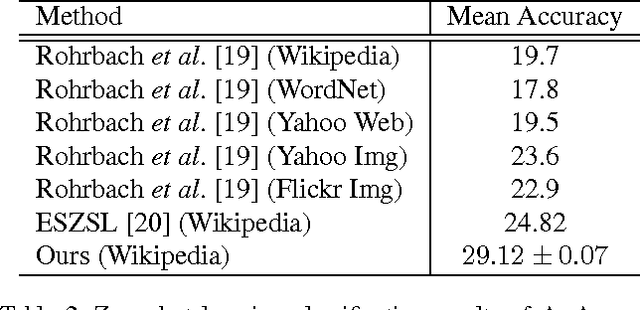
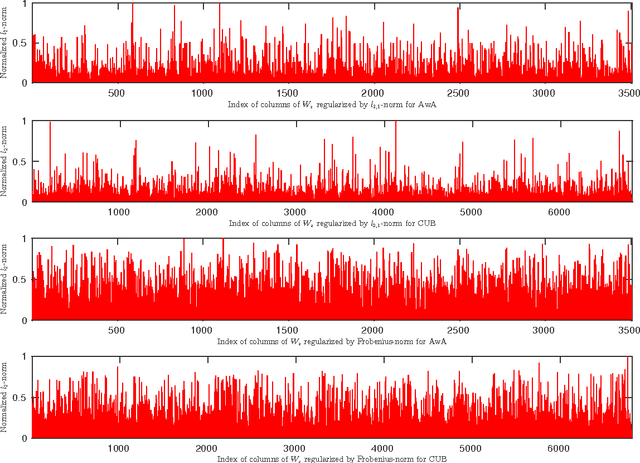
Classifying a visual concept merely from its associated online textual source, such as a Wikipedia article, is an attractive research topic in zero-shot learning because it alleviates the burden of manually collecting semantic attributes. Several recent works have pursued this approach by exploring various ways of connecting the visual and text domains. This paper revisits this idea by stepping further to consider one important factor: the textual representation is usually too noisy for the zero-shot learning application. This consideration motivates us to design a simple-but-effective zero-shot learning method capable of suppressing noise in the text. More specifically, we propose an $l_{2,1}$-norm based objective function which can simultaneously suppress the noisy signal in the text and learn a function to match the text document and visual features. We also develop an optimization algorithm to efficiently solve the resulting problem. By conducting experiments on two large datasets, we demonstrate that the proposed method significantly outperforms the competing methods which rely on online information sources but without explicit noise suppression. We further make an in-depth analysis of the proposed method and provide insight as to what kind of information in documents is useful for zero-shot learning.
Learning from Imbalanced Multiclass Sequential Data Streams Using Dynamically Weighted Conditional Random Fields
Mar 11, 2016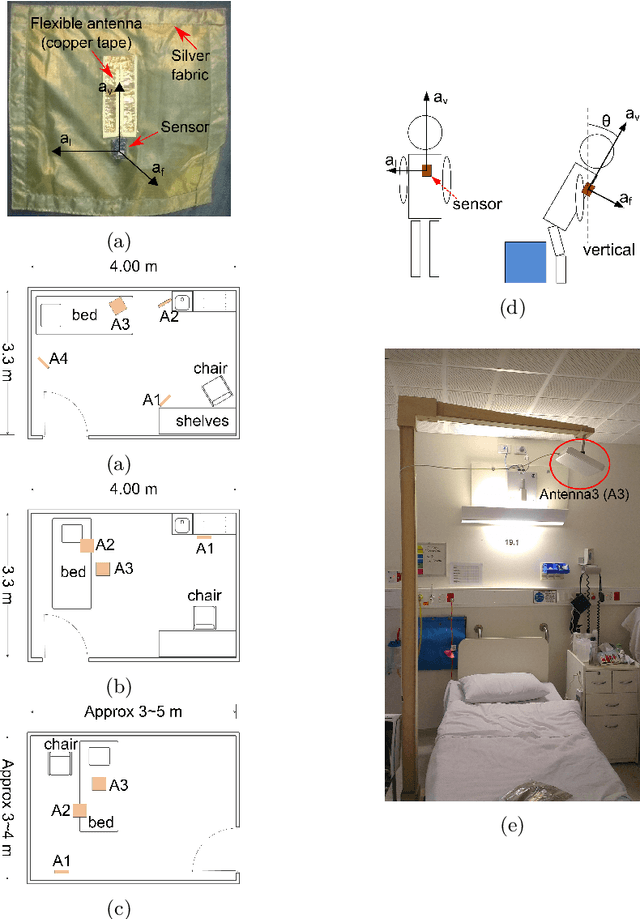
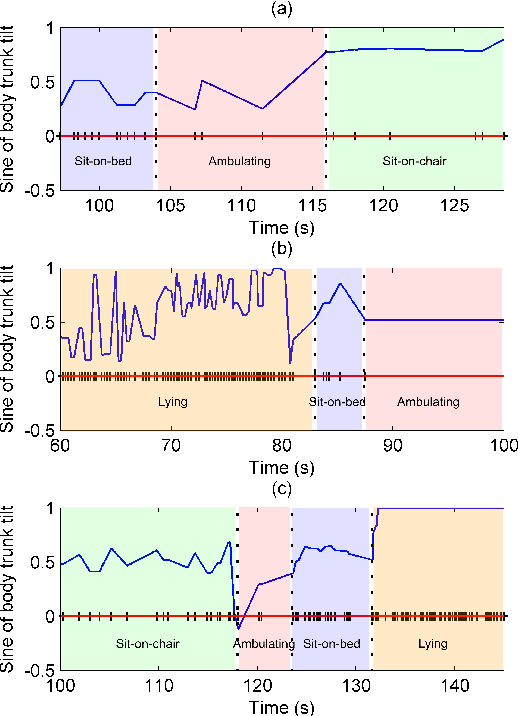
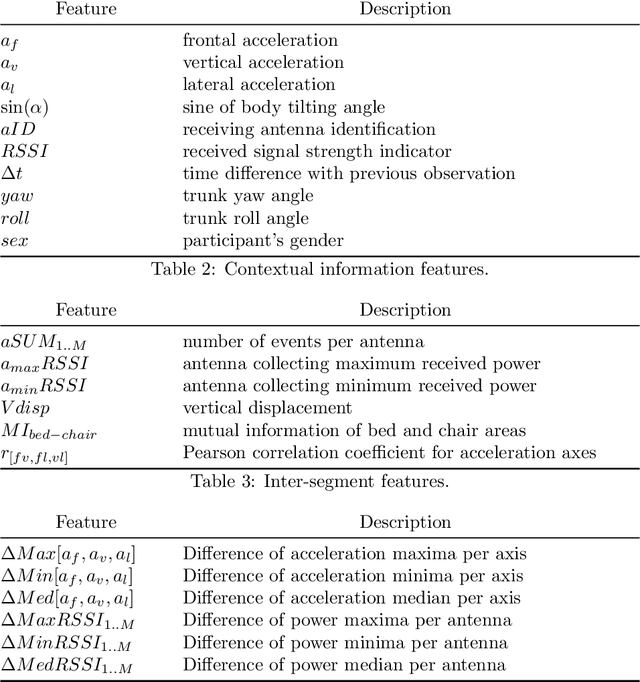
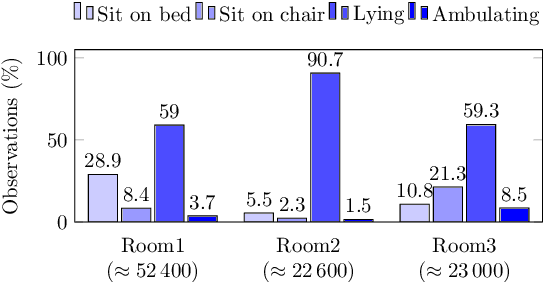
The present study introduces a method for improving the classification performance of imbalanced multiclass data streams from wireless body worn sensors. Data imbalance is an inherent problem in activity recognition caused by the irregular time distribution of activities, which are sequential and dependent on previous movements. We use conditional random fields (CRF), a graphical model for structured classification, to take advantage of dependencies between activities in a sequence. However, CRFs do not consider the negative effects of class imbalance during training. We propose a class-wise dynamically weighted CRF (dWCRF) where weights are automatically determined during training by maximizing the expected overall F-score. Our results based on three case studies from a healthcare application using a batteryless body worn sensor, demonstrate that our method, in general, improves overall and minority class F-score when compared to other CRF based classifiers and achieves similar or better overall and class-wise performance when compared to SVM based classifiers under conditions of limited training data. We also confirm the performance of our approach using an additional battery powered body worn sensor dataset, achieving similar results in cases of high class imbalance.
Hi Detector, What's Wrong with that Object? Identifying Irregular Object From Images by Modelling the Detection Score Distribution
Feb 14, 2016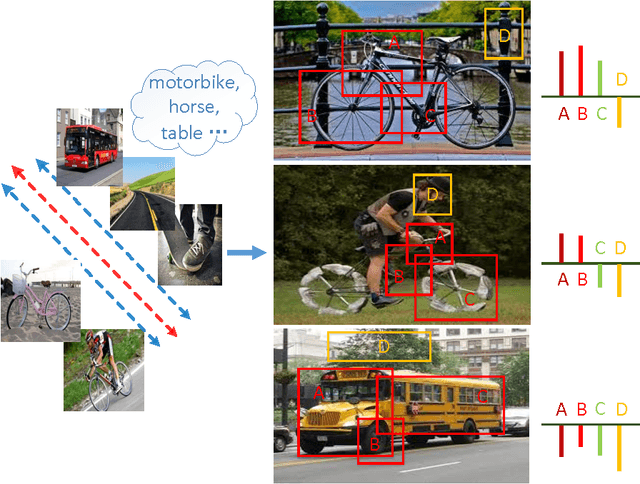


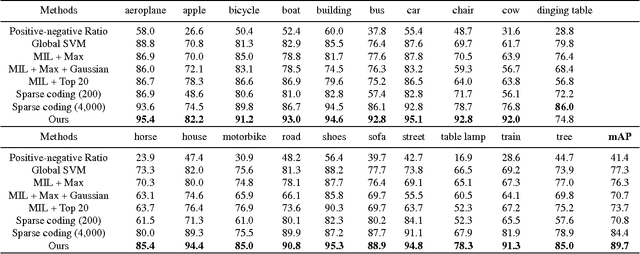
In this work, we study the challenging problem of identifying the irregular status of objects from images in an "open world" setting, that is, distinguishing the irregular status of an object category from its regular status as well as objects from other categories in the absence of "irregular object" training data. To address this problem, we propose a novel approach by inspecting the distribution of the detection scores at multiple image regions based on the detector trained from the "regular object" and "other objects". The key observation motivating our approach is that for "regular object" images as well as "other objects" images, the region-level scores follow their own essential patterns in terms of both the score values and the spatial distributions while the detection scores obtained from an "irregular object" image tend to break these patterns. To model this distribution, we propose to use Gaussian Processes (GP) to construct two separate generative models for the case of the "regular object" and the "other objects". More specifically, we design a new covariance function to simultaneously model the detection score at a single region and the score dependencies at multiple regions. We finally demonstrate the superior performance of our method on a large dataset newly proposed in this paper.
Explicit Knowledge-based Reasoning for Visual Question Answering
Nov 12, 2015
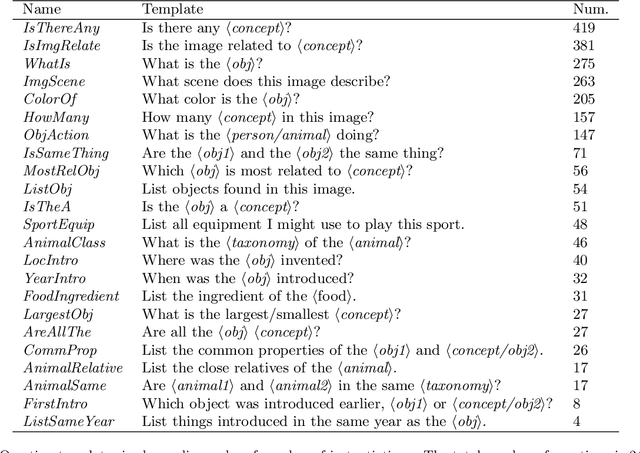
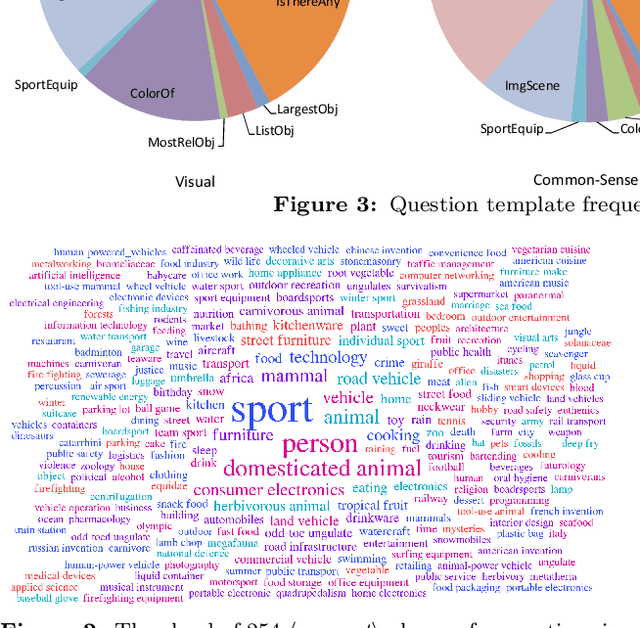
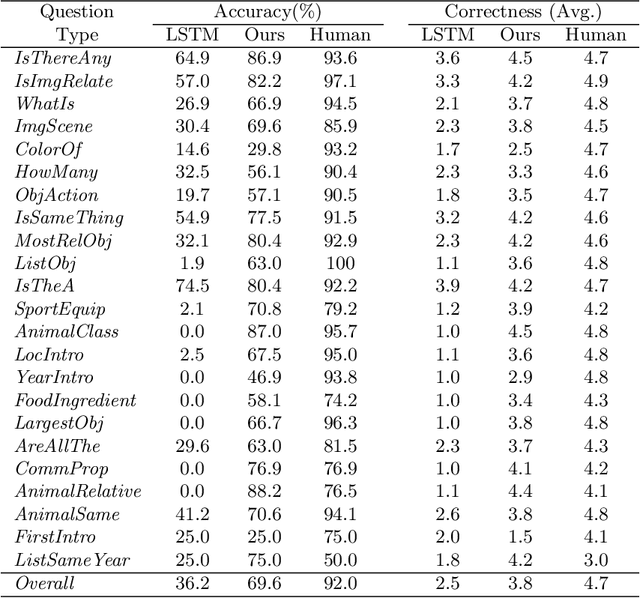
We describe a method for visual question answering which is capable of reasoning about contents of an image on the basis of information extracted from a large-scale knowledge base. The method not only answers natural language questions using concepts not contained in the image, but can provide an explanation of the reasoning by which it developed its answer. The method is capable of answering far more complex questions than the predominant long short-term memory-based approach, and outperforms it significantly in the testing. We also provide a dataset and a protocol by which to evaluate such methods, thus addressing one of the key issues in general visual ques- tion answering.
Fast detection of multiple objects in traffic scenes with a common detection framework
Oct 12, 2015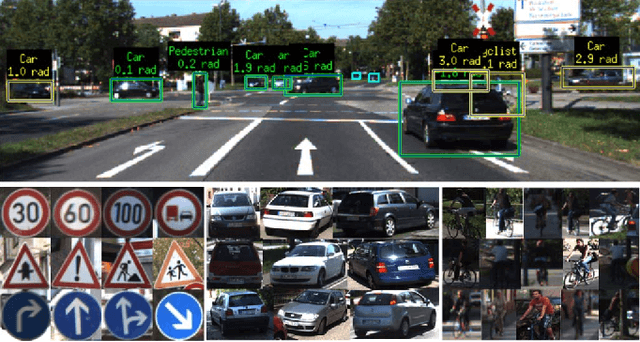
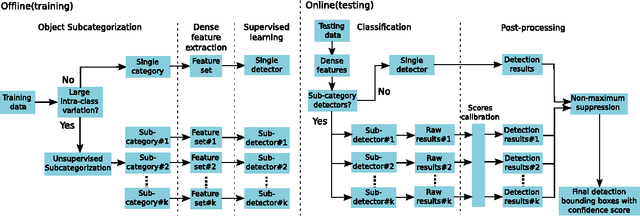
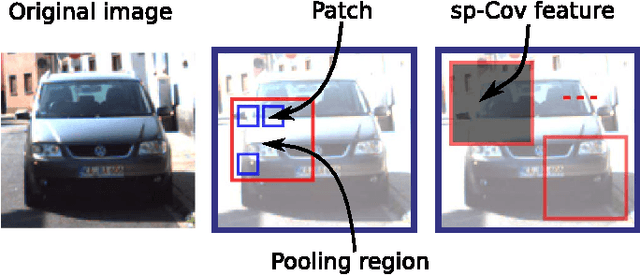
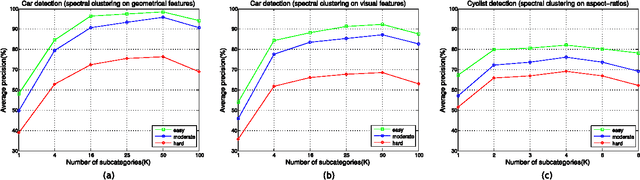
Traffic scene perception (TSP) aims to real-time extract accurate on-road environment information, which in- volves three phases: detection of objects of interest, recognition of detected objects, and tracking of objects in motion. Since recognition and tracking often rely on the results from detection, the ability to detect objects of interest effectively plays a crucial role in TSP. In this paper, we focus on three important classes of objects: traffic signs, cars, and cyclists. We propose to detect all the three important objects in a single learning based detection framework. The proposed framework consists of a dense feature extractor and detectors of three important classes. Once the dense features have been extracted, these features are shared with all detectors. The advantage of using one common framework is that the detection speed is much faster, since all dense features need only to be evaluated once in the testing phase. In contrast, most previous works have designed specific detectors using different features for each of these objects. To enhance the feature robustness to noises and image deformations, we introduce spatially pooled features as a part of aggregated channel features. In order to further improve the generalization performance, we propose an object subcategorization method as a means of capturing intra-class variation of objects. We experimentally demonstrate the effectiveness and efficiency of the proposed framework in three detection applications: traffic sign detection, car detection, and cyclist detection. The proposed framework achieves the competitive performance with state-of- the-art approaches on several benchmark datasets.
Efficient Semidefinite Branch-and-Cut for MAP-MRF Inference
Sep 09, 2015
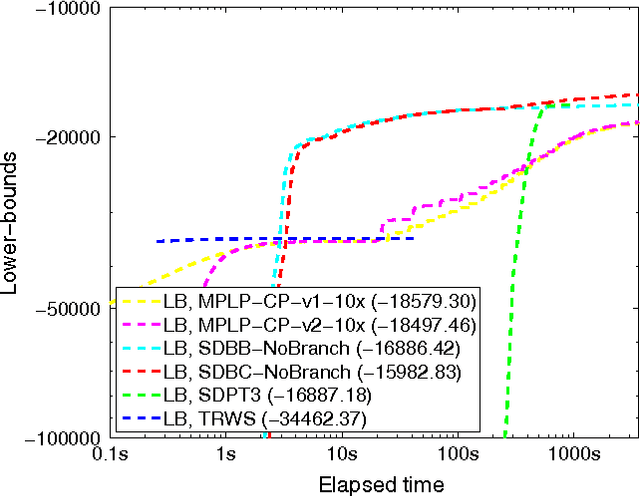
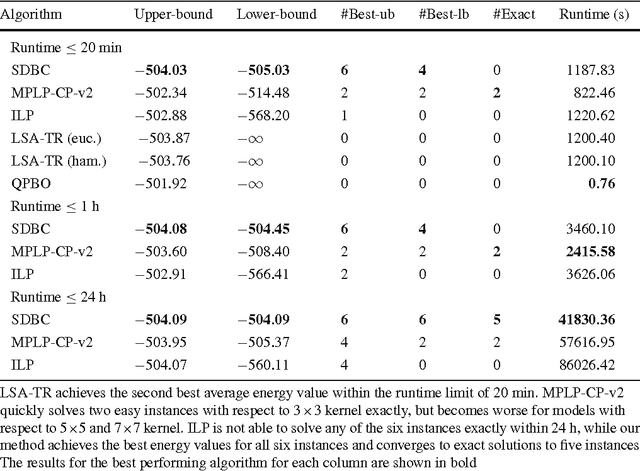
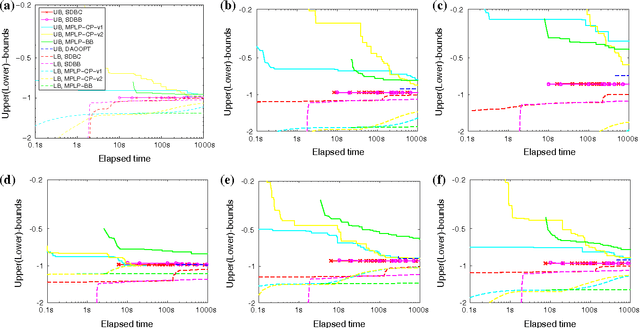
We propose a Branch-and-Cut (B&C) method for solving general MAP-MRF inference problems. The core of our method is a very efficient bounding procedure, which combines scalable semidefinite programming (SDP) and a cutting-plane method for seeking violated constraints. In order to further speed up the computation, several strategies have been exploited, including model reduction, warm start and removal of inactive constraints. We analyze the performance of the proposed method under different settings, and demonstrate that our method either outperforms or performs on par with state-of-the-art approaches. Especially when the connectivities are dense or when the relative magnitudes of the unary costs are low, we achieve the best reported results. Experiments show that the proposed algorithm achieves better approximation than the state-of-the-art methods within a variety of time budgets on challenging non-submodular MAP-MRF inference problems.
Deeply Learning the Messages in Message Passing Inference
Sep 08, 2015

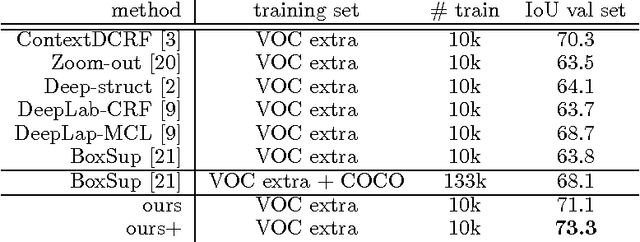

Deep structured output learning shows great promise in tasks like semantic image segmentation. We proffer a new, efficient deep structured model learning scheme, in which we show how deep Convolutional Neural Networks (CNNs) can be used to estimate the messages in message passing inference for structured prediction with Conditional Random Fields (CRFs). With such CNN message estimators, we obviate the need to learn or evaluate potential functions for message calculation. This confers significant efficiency for learning, since otherwise when performing structured learning for a CRF with CNN potentials it is necessary to undertake expensive inference for every stochastic gradient iteration. The network output dimension for message estimation is the same as the number of classes, in contrast to the network output for general CNN potential functions in CRFs, which is exponential in the order of the potentials. Hence CNN message learning has fewer network parameters and is more scalable for cases that a large number of classes are involved. We apply our method to semantic image segmentation on the PASCAL VOC 2012 dataset. We achieve an intersection-over-union score of 73.4 on its test set, which is the best reported result for methods using the VOC training images alone. This impressive performance demonstrates the effectiveness and usefulness of our CNN message learning method.
Pedestrian Detection with Spatially Pooled Features and Structured Ensemble Learning
Jun 28, 2015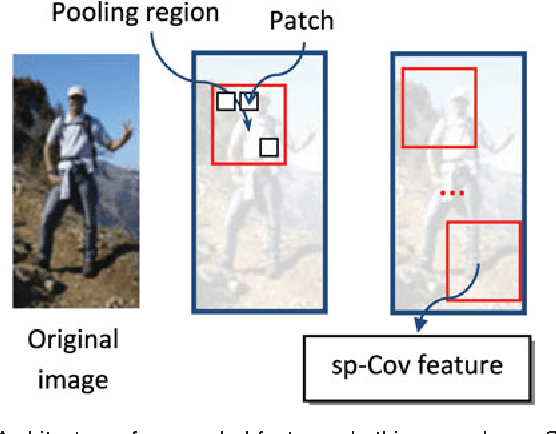
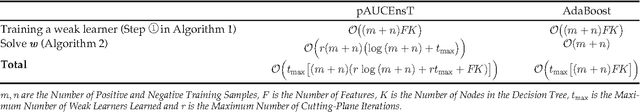

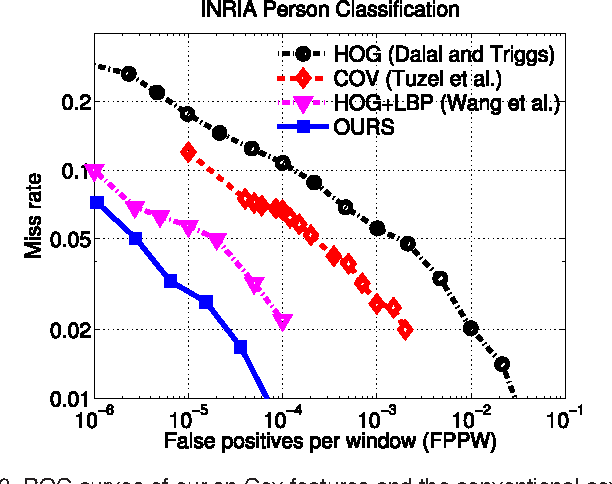
Many typical applications of object detection operate within a prescribed false-positive range. In this situation the performance of a detector should be assessed on the basis of the area under the ROC curve over that range, rather than over the full curve, as the performance outside the range is irrelevant. This measure is labelled as the partial area under the ROC curve (pAUC). We propose a novel ensemble learning method which achieves a maximal detection rate at a user-defined range of false positive rates by directly optimizing the partial AUC using structured learning. In order to achieve a high object detection performance, we propose a new approach to extract low-level visual features based on spatial pooling. Incorporating spatial pooling improves the translational invariance and thus the robustness of the detection process. Experimental results on both synthetic and real-world data sets demonstrate the effectiveness of our approach, and we show that it is possible to train state-of-the-art pedestrian detectors using the proposed structured ensemble learning method with spatially pooled features. The result is the current best reported performance on the Caltech-USA pedestrian detection dataset.