 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoastTerm: a Corpus for Multidisciplinary Term Extraction in Coastal Scientific Literature
Jun 13, 2024



The growing impact of climate change on coastal areas, particularly active but fragile regions, necessitates collaboration among diverse stakeholders and disciplines to formulate effective environmental protection policies. We introduce a novel specialized corpus comprising 2,491 sentences from 410 scientific abstracts concerning coastal areas, for the Automatic Term Extraction (ATE) and Classification (ATC) tasks. Inspired by the ARDI framework, focused on the identification of Actors, Resources, Dynamics and Interactions, we automatically extract domain terms and their distinct roles in the functioning of coastal systems by leveraging monolingual and multilingual transformer models. The evaluation demonstrates consistent results, achieving an F1 score of approximately 80\% for automated term extraction and F1 of 70\% for extracting terms and their labels. These findings are promising and signify an initial step towards the development of a specialized Knowledge Base dedicated to coastal areas.
Does It Make Sense to Explain a Black Box With Another Black Box?
Apr 23, 2024



Although counterfactual explanations are a popular approach to explain ML black-box classifiers, they are less widespread in NLP. Most methods find those explanations by iteratively perturbing the target document until it is classified differently by the black box. We identify two main families of counterfactual explanation methods in the literature, namely, (a) \emph{transparent} methods that perturb the target by adding, removing, or replacing words, and (b) \emph{opaque} approaches that project the target document into a latent, non-interpretable space where the perturbation is carried out subsequently. This article offers a comparative study of the performance of these two families of methods on three classical NLP tasks. Our empirical evidence shows that opaque approaches can be an overkill for downstream applications such as fake news detection or sentiment analysis since they add an additional level of complexity with no significant performance gain. These observations motivate our discussion, which raises the question of whether it makes sense to explain a black box using another black box.
"Honey, Tell Me What's Wrong", Global Explanation of Textual Discriminative Models through Cooperative Generation
Oct 27, 2023



The ubiquity of complex machine learning has raised the importance of model-agnostic explanation algorithms. These methods create artificial instances by slightly perturbing real instances, capturing shifts in model decisions. However, such methods rely on initial data and only provide explanations of the decision for these. To tackle these problems, we propose Therapy, the first global and model-agnostic explanation method adapted to text which requires no input dataset. Therapy generates texts following the distribution learned by a classifier through cooperative generation. Because it does not rely on initial samples, it allows to generate explanations even when data is absent (e.g., for confidentiality reasons). Moreover, conversely to existing methods that combine multiple local explanations into a global one, Therapy offers a global overview of the model behavior on the input space. Our experiments show that although using no input data to generate samples, Therapy provides insightful information about features used by the classifier that is competitive with the ones from methods relying on input samples and outperforms them when input samples are not specific to the studied model.
A Comprehensive Survey of Document-level Relation Extraction (2016-2023)
Oct 12, 2023



Document-level relation extraction (DocRE) is an active area of research in natural language processing (NLP) concerned with identifying and extracting relationships between entities beyond sentence boundaries. Compared to the more traditional sentence-level relation extraction, DocRE provides a broader context for analysis and is more challenging because it involves identifying relationships that may span multiple sentences or paragraphs. This task has gained increased interest as a viable solution to build and populate knowledge bases automatically from unstructured large-scale documents (e.g., scientific papers, legal contracts, or news articles), in order to have a better understanding of relationships between entities. This paper aims to provide a comprehensive overview of recent advances in this field, highlighting its different applications in comparison to sentence-level relation extraction.
s-LIME: Reconciling Locality and Fidelity in Linear Explanations
Aug 02, 2022The benefit of locality is one of the major premises of LIME, one of the most prominent methods to explain black-box machine learning models. This emphasis relies on the postulate that the more locally we look at the vicinity of an instance, the simpler the black-box model becomes, and the more accurately we can mimic it with a linear surrogate. As logical as this seems, our findings suggest that, with the current design of LIME, the surrogate model may degenerate when the explanation is too local, namely, when the bandwidth parameter $\sigma$ tends to zero. Based on this observation, the contribution of this paper is twofold. Firstly, we study the impact of both the bandwidth and the training vicinity on the fidelity and semantics of LIME explanations. Secondly, and based on our findings, we propose \slime, an extension of LIME that reconciles fidelity and locality.
REMI: Mining Intuitive Referring Expressions on Knowledge Bases
Nov 04, 2019
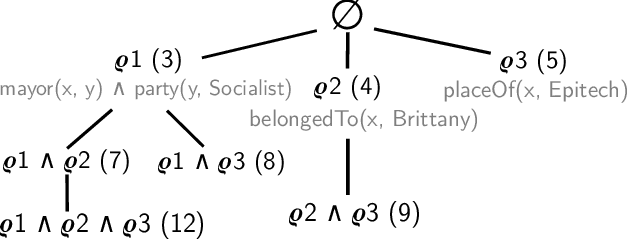


A referring expression (RE) is a description that identifies a set of instances unambiguously. Mining REs from data finds applications in natural language generation, algorithmic journalism, and data maintenance. Since there may exist multiple REs for a given set of entities, it is common to focus on the most intuitive ones, i.e., the most concise and informative. In this paper we present REMI, a system that can mine intuitive REs on large RDF knowledge bases. Our experimental evaluation shows that REMI finds REs deemed intuitive by users. Moreover we show that REMI is several orders of magnitude faster than an approach based on inductive logic programming.