 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-SGD: Biasing Gradient Descent Into Wide Valleys
Apr 21, 2017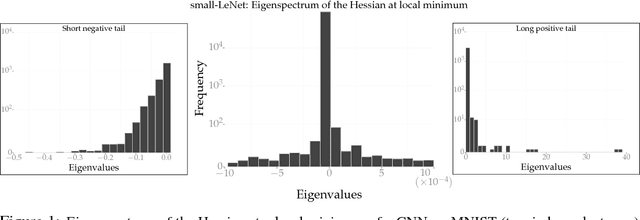
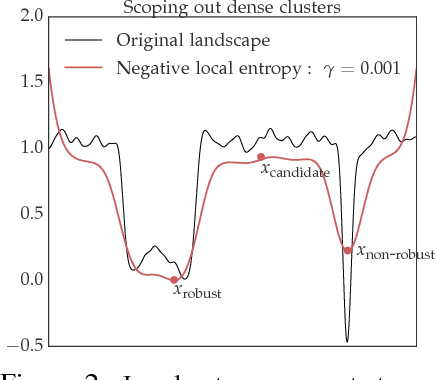
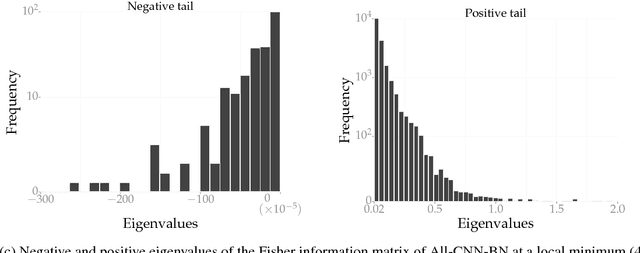
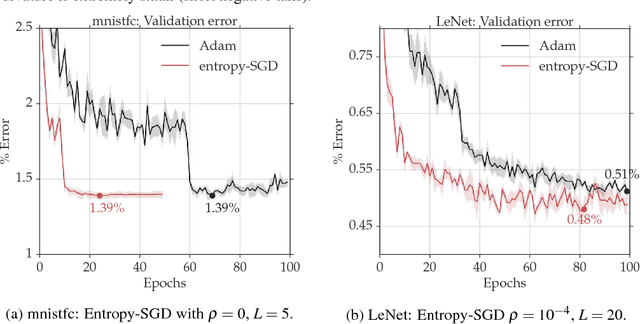
This paper proposes a new optimization algorithm called Entropy-SGD for training deep neural networks that is motivated by the local geometry of the energy landscape. Local extrema with low generalization error have a large proportion of almost-zero eigenvalues in the Hessian with very few positive or negative eigenvalues. We leverage upon this observation to construct a local-entropy-based objective function that favors well-generalizable solutions lying in large flat regions of the energy landscape, while avoiding poorly-generalizable solutions located in the sharp valleys. Conceptually, our algorithm resembles two nested loops of SGD where we use Langevin dynamics in the inner loop to compute the gradient of the local entropy before each update of the weights. We show that the new objective has a smoother energy landscape and show improved generalization over SGD using uniform stability, under certain assumptions. Our experiments on convolutional and recurrent networks demonstrate that Entropy-SGD compares favorably to state-of-the-art techniques in terms of generalization error and training time.
Simultaneous Learning of Trees and Representations for Extreme Classification and Density Estimation
Mar 02, 2017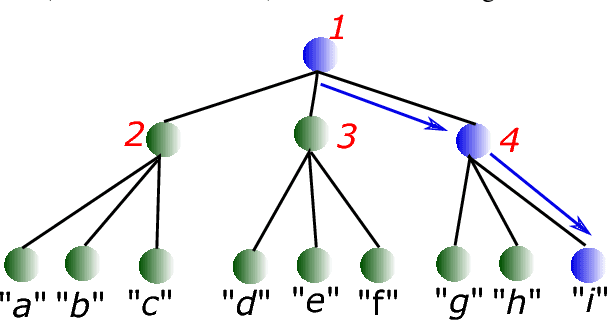
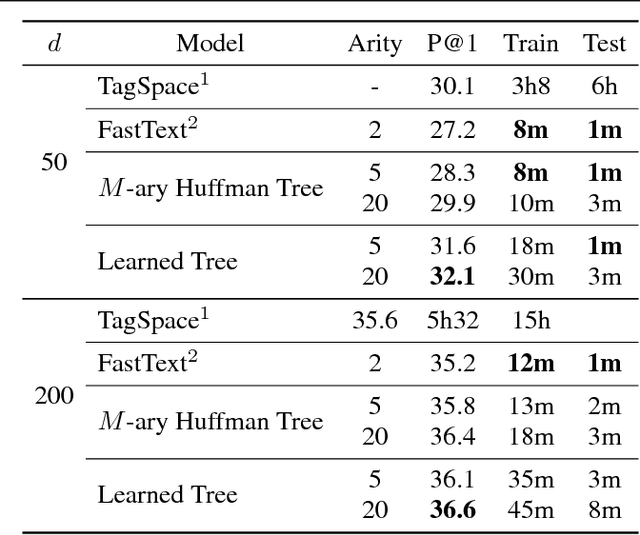
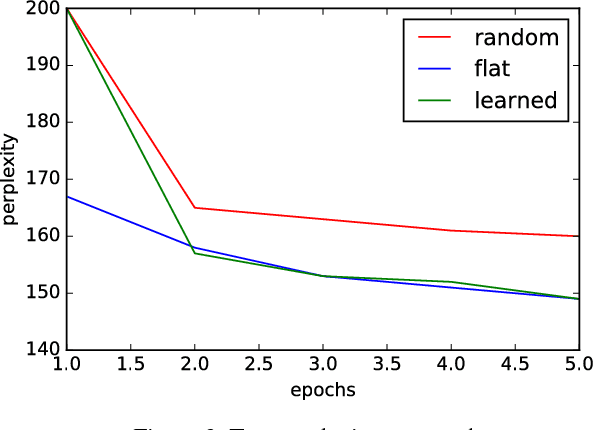
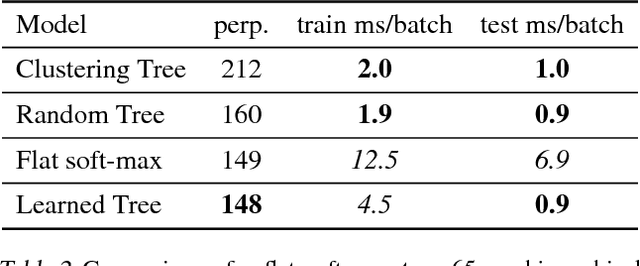
We consider multi-class classification where the predictor has a hierarchical structure that allows for a very large number of labels both at train and test time. The predictive power of such models can heavily depend on the structure of the tree, and although past work showed how to learn the tree structure, it expected that the feature vectors remained static. We provide a novel algorithm to simultaneously perform representation learning for the input data and learning of the hierarchi- cal predictor. Our approach optimizes an objec- tive function which favors balanced and easily- separable multi-way node partitions. We theoret- ically analyze this objective, showing that it gives rise to a boosting style property and a bound on classification error. We next show how to extend the algorithm to conditional density estimation. We empirically validate both variants of the al- gorithm on text classification and language mod- eling, respectively, and show that they compare favorably to common baselines in terms of accu- racy and running time.
Structured adaptive and random spinners for fast machine learning computations
Nov 26, 2016
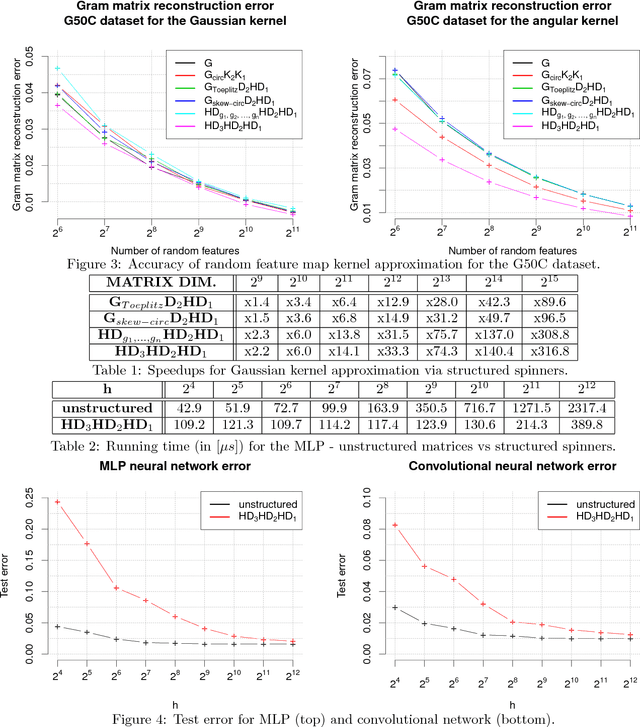
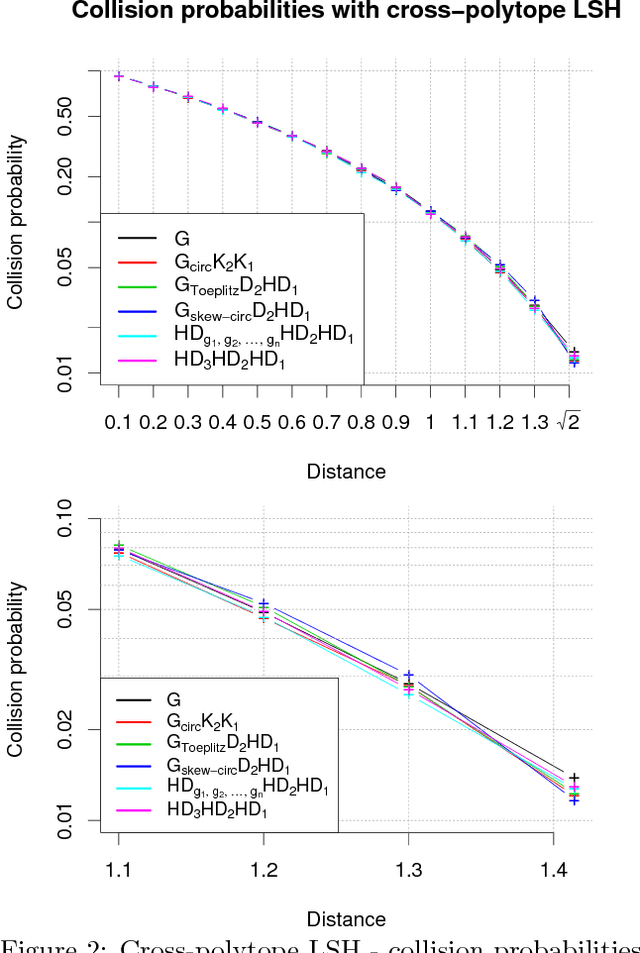
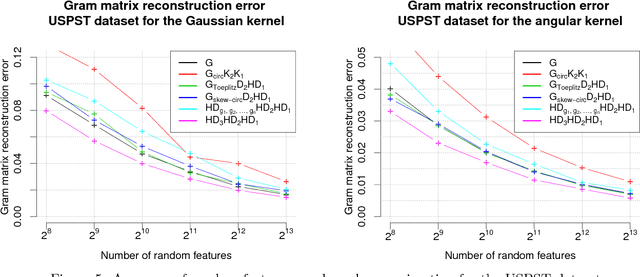
We consider an efficient computational framework for speeding up several machine learning algorithms with almost no loss of accuracy. The proposed framework relies on projections via structured matrices that we call Structured Spinners, which are formed as products of three structured matrix-blocks that incorporate rotations. The approach is highly generic, i.e. i) structured matrices under consideration can either be fully-randomized or learned, ii) our structured family contains as special cases all previously considered structured schemes, iii) the setting extends to the non-linear case where the projections are followed by non-linear functions, and iv) the method finds numerous applications including kernel approximations via random feature maps, dimensionality reduction algorithms, new fast cross-polytope LSH techniques, deep learning, convex optimization algorithms via Newton sketches, quantization with random projection trees, and more. The proposed framework comes with theoretical guarantees characterizing the capacity of the structured model in reference to its unstructured counterpart and is based on a general theoretical principle that we describe in the paper. As a consequence of our theoretical analysis, we provide the first theoretical guarantees for one of the most efficient existing LSH algorithms based on the HD3HD2HD1 structured matrix [Andoni et al., 2015]. The exhaustive experimental evaluation confirms the accuracy and efficiency of structured spinners for a variety of different applications.
Binary embeddings with structured hashed projections
Jul 01, 2016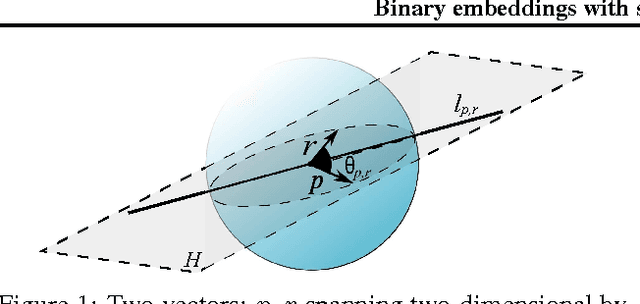
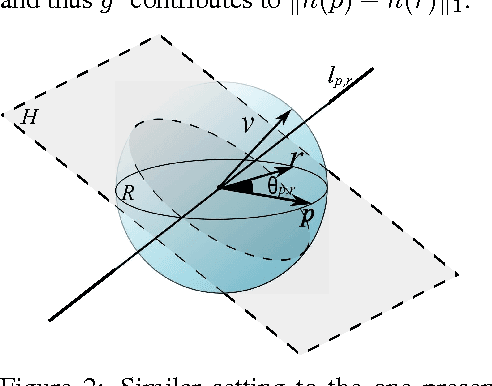
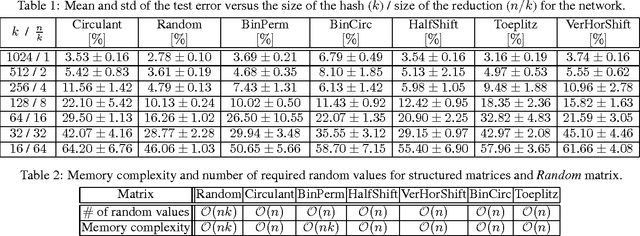
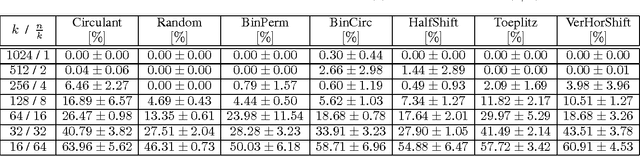
We consider the hashing mechanism for constructing binary embeddings, that involves pseudo-random projections followed by nonlinear (sign function) mappings. The pseudo-random projection is described by a matrix, where not all entries are independent random variables but instead a fixed "budget of randomness" is distributed across the matrix. Such matrices can be efficiently stored in sub-quadratic or even linear space, provide reduction in randomness usage (i.e. number of required random values), and very often lead to computational speed ups. We prove several theoretical results showing that projections via various structured matrices followed by nonlinear mappings accurately preserve the angular distance between input high-dimensional vectors. To the best of our knowledge, these results are the first that give theoretical ground for the use of general structured matrices in the nonlinear setting. In particular, they generalize previous extensions of the Johnson-Lindenstrauss lemma and prove the plausibility of the approach that was so far only heuristically confirmed for some special structured matrices. Consequently, we show that many structured matrices can be used as an efficient information compression mechanism. Our findings build a better understanding of certain deep architectures, which contain randomly weighted and untrained layers, and yet achieve high performance on different learning tasks. We empirically verify our theoretical findings and show the dependence of learning via structured hashed projections on the performance of neural network as well as nearest neighbor classifier.
On the boosting ability of top-down decision tree learning algorithm for multiclass classification
May 17, 2016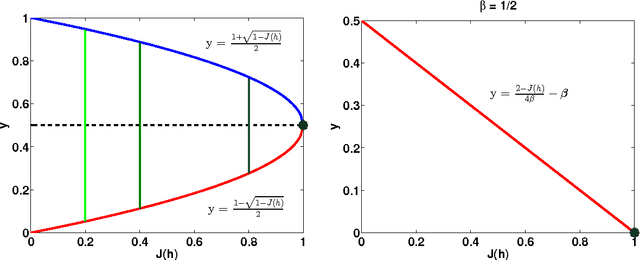
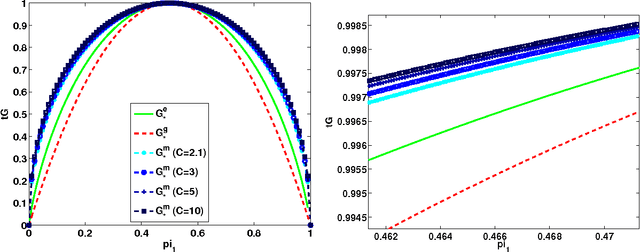
We analyze the performance of the top-down multiclass classification algorithm for decision tree learning called LOMtree, recently proposed in the literature Choromanska and Langford (2014) for solving efficiently classification problems with very large number of classes. The algorithm online optimizes the objective function which simultaneously controls the depth of the tree and its statistical accuracy. We prove important properties of this objective and explore its connection to three well-known entropy-based decision tree objectives, i.e. Shannon entropy, Gini-entropy and its modified version, for which instead online optimization schemes were not yet developed. We show, via boosting-type guarantees, that maximizing the considered objective leads also to the reduction of all of these entropy-based objectives. The bounds we obtain critically depend on the strong-concavity properties of the entropy-based criteria, where the mildest dependence on the number of classes (only logarithmic) corresponds to the Shannon entropy.
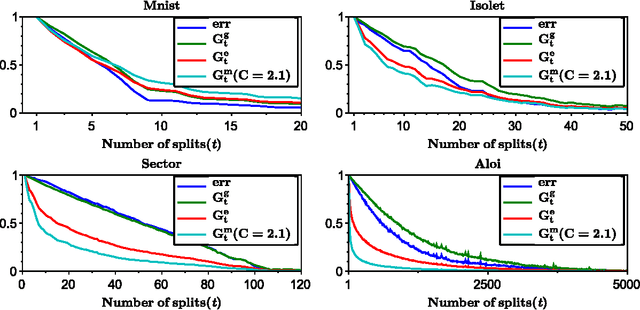
Logarithmic Time Online Multiclass prediction
Nov 14, 2015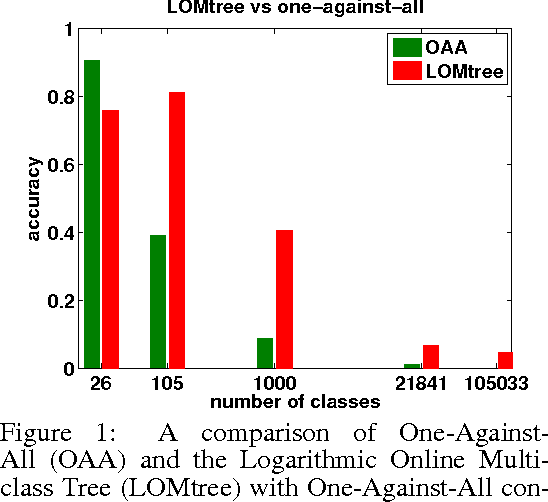


We study the problem of multiclass classification with an extremely large number of classes (k), with the goal of obtaining train and test time complexity logarithmic in the number of classes. We develop top-down tree construction approaches for constructing logarithmic depth trees. On the theoretical front, we formulate a new objective function, which is optimized at each node of the tree and creates dynamic partitions of the data which are both pure (in terms of class labels) and balanced. We demonstrate that under favorable conditions, we can construct logarithmic depth trees that have leaves with low label entropy. However, the objective function at the nodes is challenging to optimize computationally. We address the empirical problem with a new online decision tree construction procedure. Experiments demonstrate that this online algorithm quickly achieves improvement in test error compared to more common logarithmic training time approaches, which makes it a plausible method in computationally constrained large-k applications.
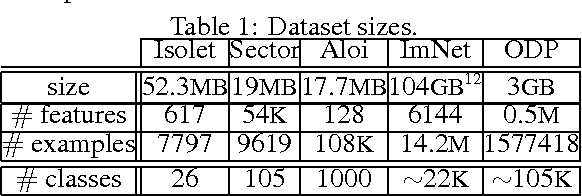
Deep learning with Elastic Averaging SGD
Oct 25, 2015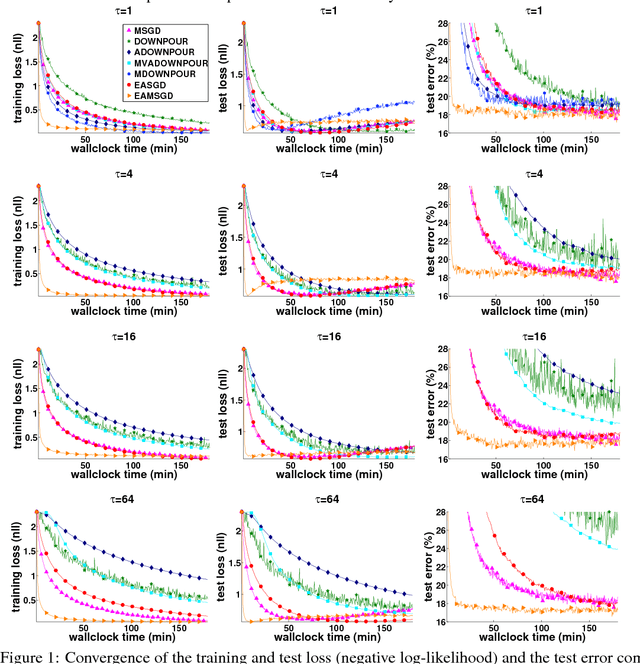

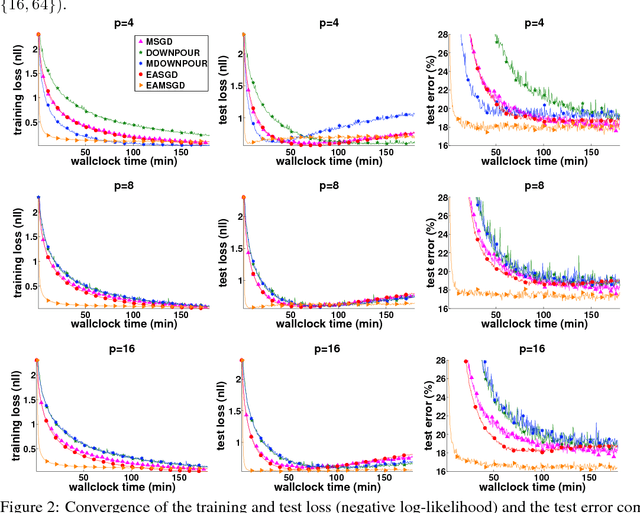
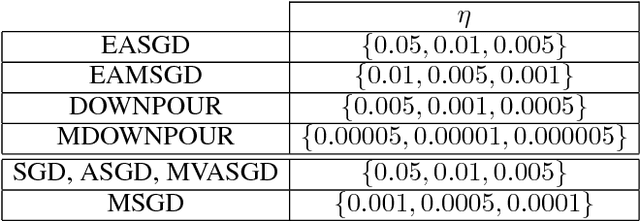
We study the problem of stochastic optimization for deep learning in the parallel computing environment under communication constraints. A new algorithm is proposed in this setting where the communication and coordination of work among concurrent processes (local workers), is based on an elastic force which links the parameters they compute with a center variable stored by the parameter server (master). The algorithm enables the local workers to perform more exploration, i.e. the algorithm allows the local variables to fluctuate further from the center variable by reducing the amount of communication between local workers and the master. We empirically demonstrate that in the deep learning setting, due to the existence of many local optima, allowing more exploration can lead to the improved performance. We propose synchronous and asynchronous variants of the new algorithm. We provide the stability analysis of the asynchronous variant in the round-robin scheme and compare it with the more common parallelized method ADMM. We show that the stability of EASGD is guaranteed when a simple stability condition is satisfied, which is not the case for ADMM. We additionally propose the momentum-based version of our algorithm that can be applied in both synchronous and asynchronous settings. Asynchronous variant of the algorithm is applied to train convolutional neural networks for image classification on the CIFAR and ImageNet datasets. Experiments demonstrate that the new algorithm accelerates the training of deep architectures compared to DOWNPOUR and other common baseline approaches and furthermore is very communication efficient.
Differentially- and non-differentially-private random decision trees
Feb 05, 2015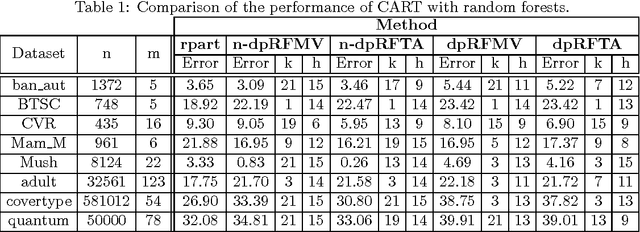
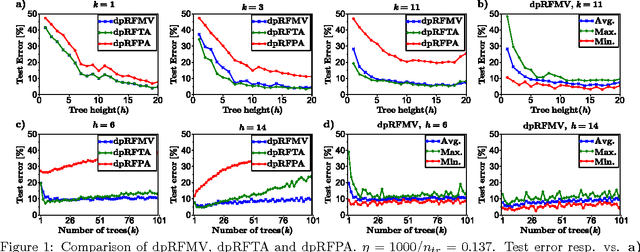
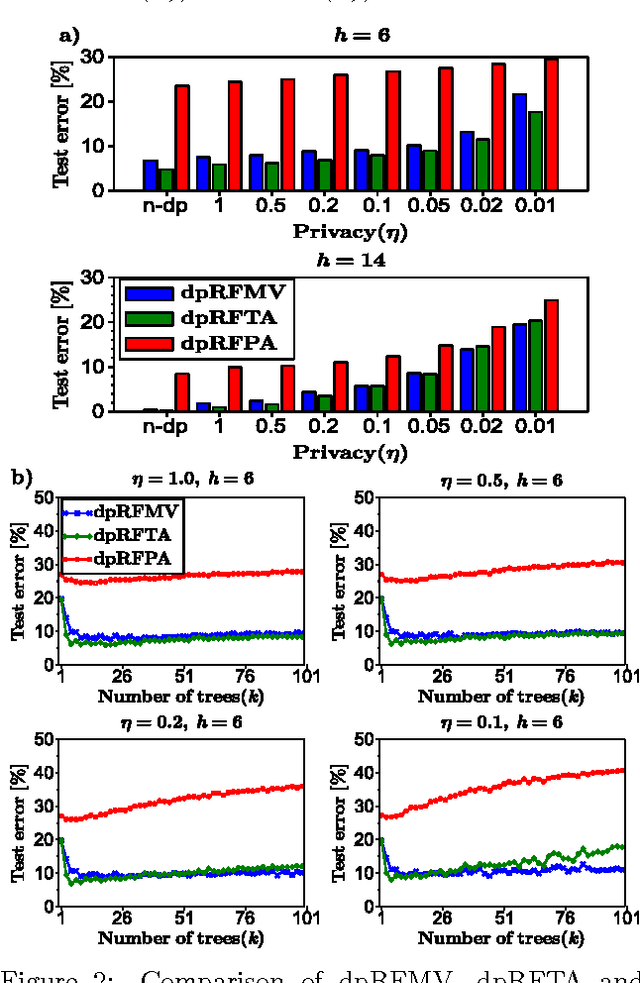
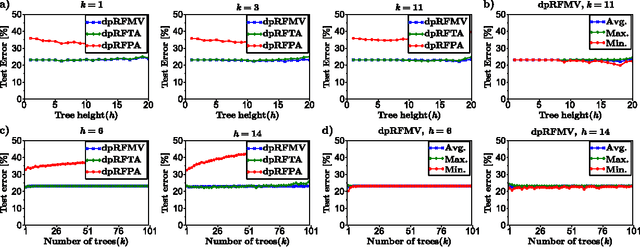
We consider supervised learning with random decision trees, where the tree construction is completely random. The method is popularly used and works well in practice despite the simplicity of the setting, but its statistical mechanism is not yet well-understood. In this paper we provide strong theoretical guarantees regarding learning with random decision trees. We analyze and compare three different variants of the algorithm that have minimal memory requirements: majority voting, threshold averaging and probabilistic averaging. The random structure of the tree enables us to adapt these methods to a differentially-private setting thus we also propose differentially-private versions of all three schemes. We give upper-bounds on the generalization error and mathematically explain how the accuracy depends on the number of random decision trees. Furthermore, we prove that only logarithmic (in the size of the dataset) number of independently selected random decision trees suffice to correctly classify most of the data, even when differential-privacy guarantees must be maintained. We empirically show that majority voting and threshold averaging give the best accuracy, also for conservative users requiring high privacy guarantees. Furthermore, we demonstrate that a simple majority voting rule is an especially good candidate for the differentially-private classifier since it is much less sensitive to the choice of forest parameters than other methods.
The Loss Surfaces of Multilayer Networks
Jan 21, 2015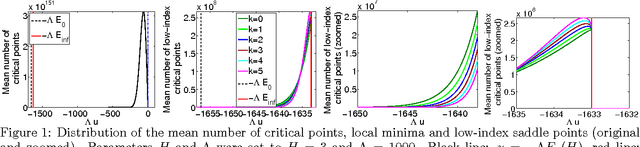

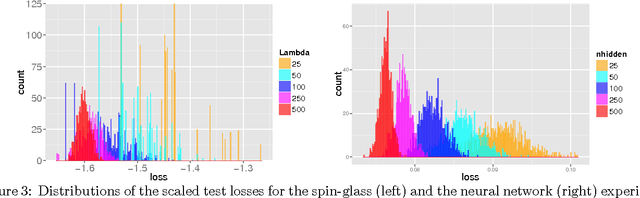
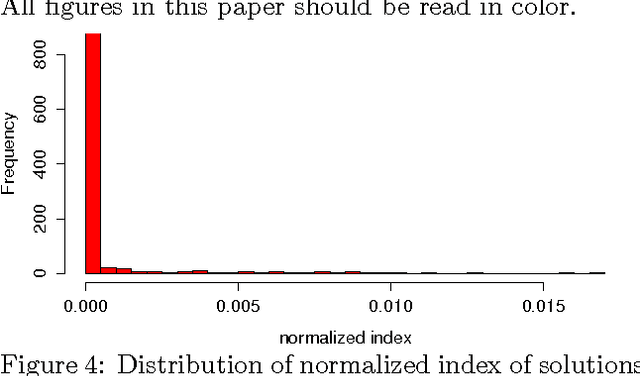
We study the connection between the highly non-convex loss function of a simple model of the fully-connected feed-forward neural network and the Hamiltonian of the spherical spin-glass model under the assumptions of: i) variable independence, ii) redundancy in network parametrization, and iii) uniformity. These assumptions enable us to explain the complexity of the fully decoupled neural network through the prism of the results from random matrix theory. We show that for large-size decoupled networks the lowest critical values of the random loss function form a layered structure and they are located in a well-defined band lower-bounded by the global minimum. The number of local minima outside that band diminishes exponentially with the size of the network. We empirically verify that the mathematical model exhibits similar behavior as the computer simulations, despite the presence of high dependencies in real networks. We conjecture that both simulated annealing and SGD converge to the band of low critical points, and that all critical points found there are local minima of high quality measured by the test error. This emphasizes a major difference between large- and small-size networks where for the latter poor quality local minima have non-zero probability of being recovered. Finally, we prove that recovering the global minimum becomes harder as the network size increases and that it is in practice irrelevant as global minimum often leads to overfitting.
Notes on using Determinantal Point Processes for Clustering with Applications to Text Clustering
Oct 26, 2014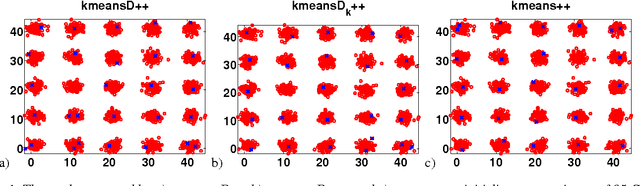
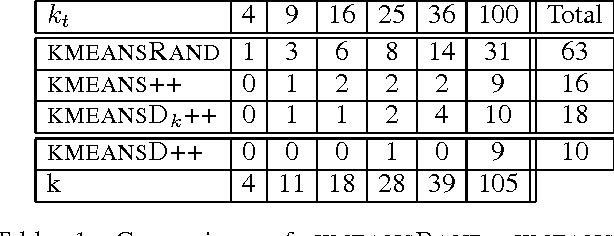
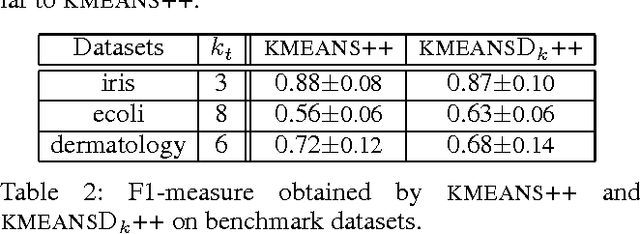
In this paper, we compare three initialization schemes for the KMEANS clustering algorithm: 1) random initialization (KMEANSRAND), 2) KMEANS++, and 3) KMEANSD++. Both KMEANSRAND and KMEANS++ have a major that the value of k needs to be set by the user of the algorithms. (Kang 2013) recently proposed a novel use of determinantal point processes for sampling the initial centroids for the KMEANS algorithm (we call it KMEANSD++). They, however, do not provide any evaluation establishing that KMEANSD++ is better than other algorithms. In this paper, we show that the performance of KMEANSD++ is comparable to KMEANS++ (both of which are better than KMEANSRAND) with KMEANSD++ having an additional that it can automatically approximate the value of k.