 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipschitz bounds for integral kernels
Apr 03, 2026Feature maps associated with positive definite kernels play a central role in kernel methods and learning theory, where regularity properties such as Lipschitz continuity are closely related to robustness and stability guarantees. Despite their importance, explicit characterizations of the Lipschitz constant of kernel feature maps are available only in a limited number of cases. In this paper, we study the Lipschitz regularity of feature maps associated with integral kernels under differentiability assumptions. We first provide sufficient conditions ensuring Lipschitz continuity and derive explicit formulas for the corresponding Lipschitz constants. We then identify a condition under which the feature map fails to be Lipschitz continuous and apply these results to several important classes of kernels. For infinite width two-layer neural network with isotropic Gaussian weight distributions, we show that the Lipschitz constant of the associated kernel can be expressed as the supremum of a two-dimensional integral, leading to an explicit characterization for the Gaussian kernel and the ReLU random neural network kernel. We also study continuous and shift-invariant kernels such as Gaussian, Laplace, and Matérn kernels, which admit an interpretation as neural network with cosine activation function. In this setting, we prove that the feature map is Lipschitz continuous if and only if the weight distribution has a finite second-order moment, and we then derive its Lipschitz constant. Finally, we raise an open question concerning the asymptotic behavior of the convergence of the Lipschitz constant in finite width neural networks. Numerical experiments are provided to support this behavior.
Feature Representation Transferring to Lightweight Models via Perception Coherence
May 10, 2025



In this paper, we propose a method for transferring feature representation to lightweight student models from larger teacher models. We mathematically define a new notion called \textit{perception coherence}. Based on this notion, we propose a loss function, which takes into account the dissimilarities between data points in feature space through their ranking. At a high level, by minimizing this loss function, the student model learns to mimic how the teacher model \textit{perceives} inputs. More precisely, our method is motivated by the fact that the representational capacity of the student model is weaker than the teacher model. Hence, we aim to develop a new method allowing for a better relaxation. This means that, the student model does not need to preserve the absolute geometry of the teacher one, while preserving global coherence through dissimilarity ranking. Our theoretical insights provide a probabilistic perspective on the process of feature representation transfer. Our experiments results show that our method outperforms or achieves on-par performance compared to strong baseline methods for representation transferring.
Convolutional Rectangular Attention Module
Mar 13, 2025



In this paper, we introduce a novel spatial attention module, that can be integrated to any convolutional network. This module guides the model to pay attention to the most discriminative part of an image. This enables the model to attain a better performance by an end-to-end training. In standard approaches, a spatial attention map is generated in a position-wise fashion. We observe that this results in very irregular boundaries. This could make it difficult to generalize to new samples. In our method, the attention region is constrained to be rectangular. This rectangle is parametrized by only 5 parameters, allowing for a better stability and generalization to new samples. In our experiments, our method systematically outperforms the position-wise counterpart. Thus, this provides us a novel useful spatial attention mechanism for convolutional models. Besides, our module also provides the interpretability concerning the ``where to look" question, as it helps to know the part of the input on which the model focuses to produce the prediction.
Large Margin Discriminative Loss for Classification
May 28, 2024



In this paper, we introduce a novel discriminative loss function with large margin in the context of Deep Learning. This loss boosts the discriminative power of neural nets, represented by intra-class compactness and inter-class separability. On the one hand, the class compactness is ensured by close distance of samples of the same class to each other. On the other hand, the inter-class separability is boosted by a margin loss that ensures the minimum distance of each class to its closest boundary. All the terms in our loss have an explicit meaning, giving a direct view of the feature space obtained. We analyze mathematically the relation between compactness and margin term, giving a guideline about the impact of the hyper-parameters on the learned features. Moreover, we also analyze properties of the gradient of the loss with respect to the parameters of the neural net. Based on this, we design a strategy called partial momentum updating that enjoys simultaneously stability and consistency in training. Furthermore, we also investigate generalization errors to have better theoretical insights. Our loss function systematically boosts the test accuracy of models compared to the standard softmax loss in our experiments.
Local convergence of min-max algorithms to differentiable equilibrium on Riemannian manifold
May 22, 2024We study min-max algorithms to solve zero-sum differentiable games on Riemannian manifold. The notions of differentiable Stackelberg equilibrium and differentiable Nash equilibrium in Euclidean space are generalized to Riemannian manifold, through an intrinsic definition which does not depend on the choice of local coordinate chart of manifold. We then provide sufficient conditions for the local convergence of the deterministic simultaneous algorithms $\tau$-GDA and $\tau$-SGA near such equilibrium, using a general methodology based on spectral analysis. These algorithms are extended with stochastic gradients and applied to the training of Wasserstein GAN. The discriminator of GAN is constructed from Lipschitz-continuous functions based on Stiefel manifold. We show numerically how the insights obtained from the local convergence analysis may lead to an improvement of GAN models.
Combining Statistical Depth and Fermat Distance for Uncertainty Quantification
Apr 12, 2024



We measure the Out-of-domain uncertainty in the prediction of Neural Networks using a statistical notion called ``Lens Depth'' (LD) combined with Fermat Distance, which is able to capture precisely the ``depth'' of a point with respect to a distribution in feature space, without any assumption about the form of distribution. Our method has no trainable parameter. The method is applicable to any classification model as it is applied directly in feature space at test time and does not intervene in training process. As such, it does not impact the performance of the original model. The proposed method gives excellent qualitative result on toy datasets and can give competitive or better uncertainty estimation on standard deep learning datasets compared to strong baseline methods.
Generalized Rectifier Wavelet Covariance Models For Texture Synthesis
Mar 14, 2022
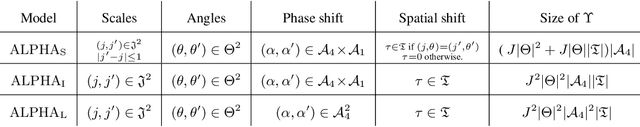
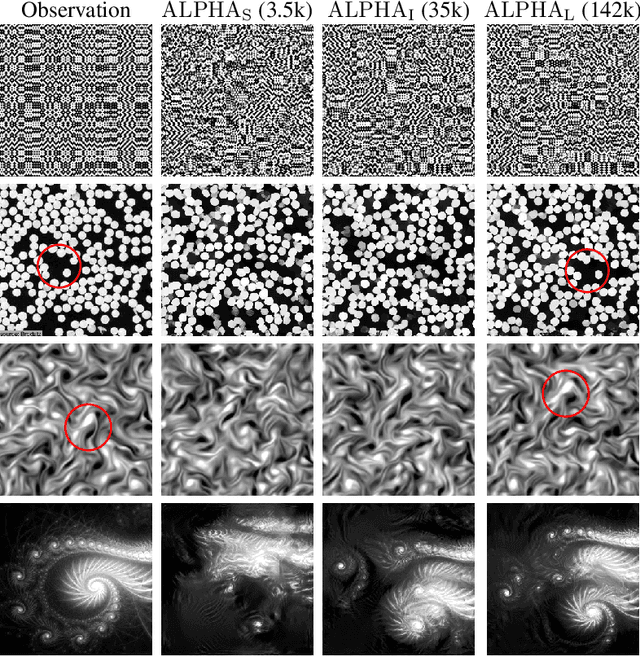

State-of-the-art maximum entropy models for texture synthesis are built from statistics relying on image representations defined by convolutional neural networks (CNN). Such representations capture rich structures in texture images, outperforming wavelet-based representations in this regard. However, conversely to neural networks, wavelets offer meaningful representations, as they are known to detect structures at multiple scales (e.g. edges) in images. In this work, we propose a family of statistics built upon non-linear wavelet based representations, that can be viewed as a particular instance of a one-layer CNN, using a generalized rectifier non-linearity. These statistics significantly improve the visual quality of previous classical wavelet-based models, and allow one to produce syntheses of similar quality to state-of-the-art models, on both gray-scale and color textures.
On the Nash equilibrium of moment-matching GANs for stationary Gaussian processes
Mar 14, 2022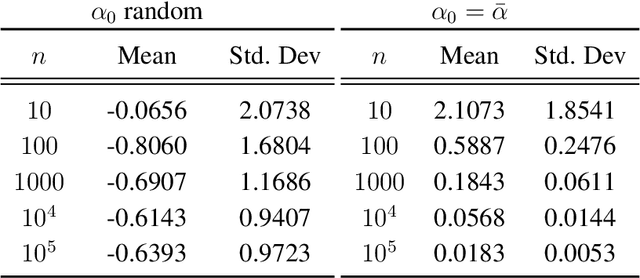
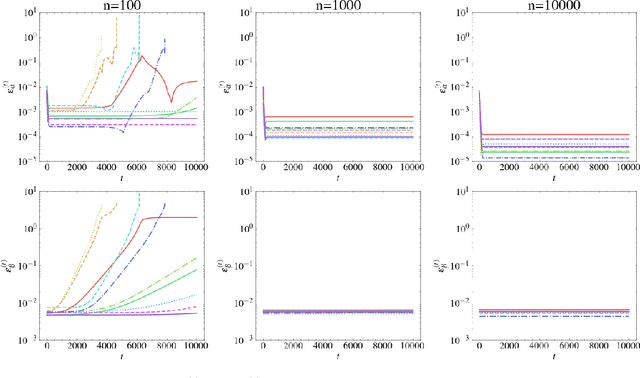
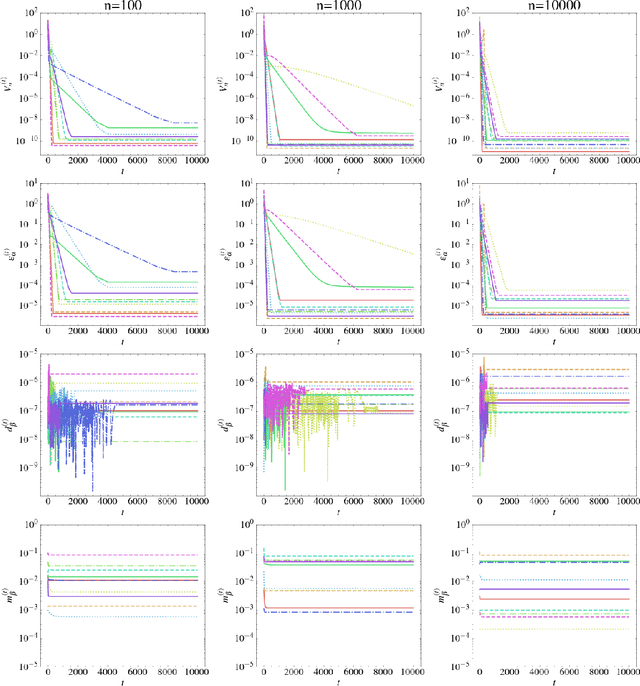
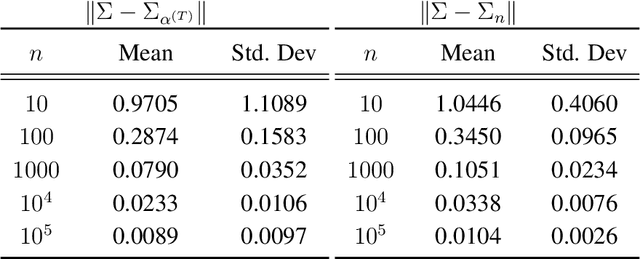
Generative Adversarial Networks (GANs) learn an implicit generative model from data samples through a two-player game. In this paper, we study the existence of Nash equilibrium of the game which is consistent as the number of data samples grows to infinity. In a realizable setting where the goal is to estimate the ground-truth generator of a stationary Gaussian process, we show that the existence of consistent Nash equilibrium depends crucially on the choice of the discriminator family. The discriminator defined from second-order statistical moments can result in non-existence of Nash equilibrium, existence of consistent non-Nash equilibrium, or existence and uniqueness of consistent Nash equilibrium, depending on whether symmetry properties of the generator family are respected. We further study the local stability and global convergence of gradient descent-ascent methods towards consistent equilibrium.
On the Relationships between Transform-Learning NMF and Joint-Diagonalization
Dec 10, 2021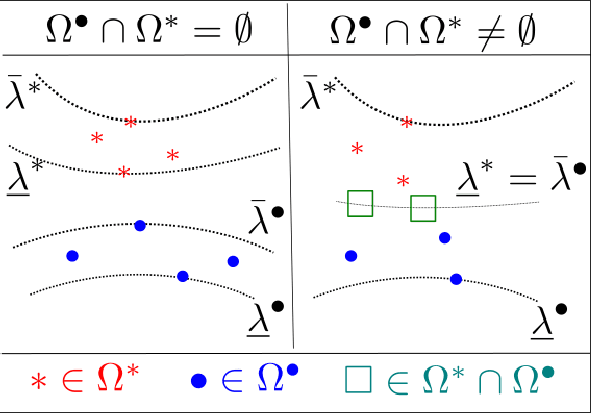
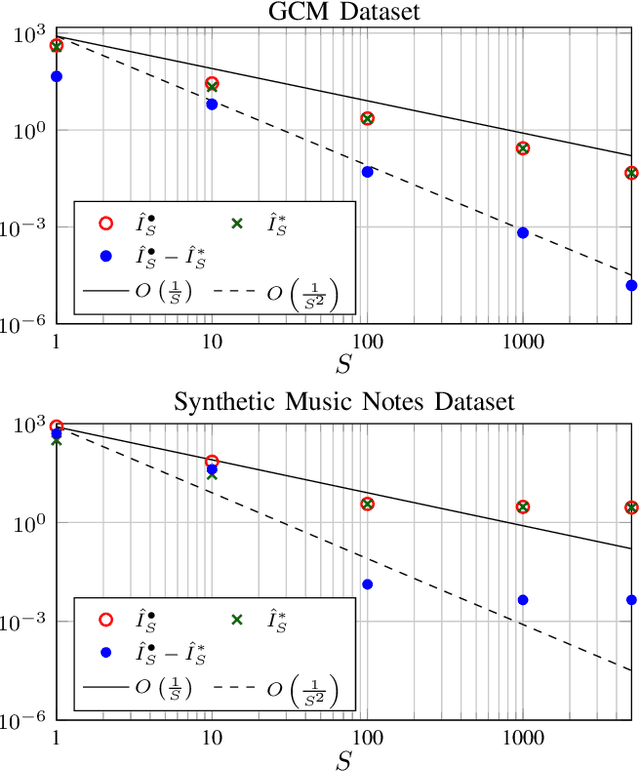
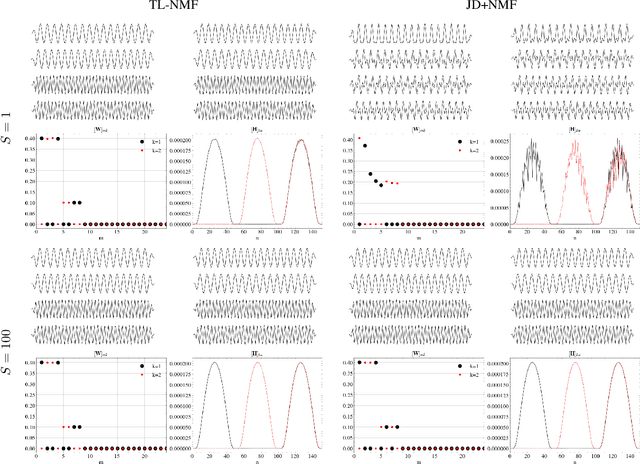
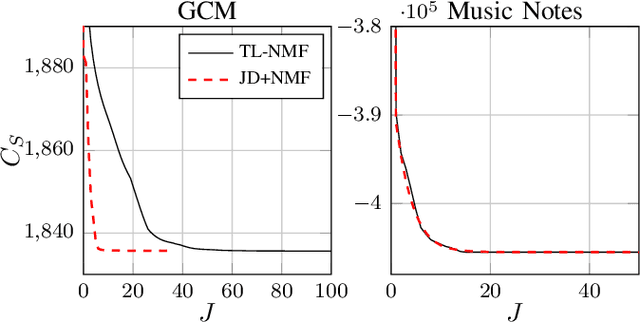
Non-negative matrix factorization with transform learning (TL-NMF) is a recent idea that aims at learning data representations suited to NMF. In this work, we relate TL-NMF to the classical matrix joint-diagonalization (JD) problem. We show that, when the number of data realizations is sufficiently large, TL-NMF can be replaced by a two-step approach -- termed as JD+NMF -- that estimates the transform through JD, prior to NMF computation. In contrast, we found that when the number of data realizations is limited, not only is JD+NMF no longer equivalent to TL-NMF, but the inherent low-rank constraint of TL-NMF turns out to be an essential ingredient to learn meaningful transforms for NMF.
Particle gradient descent model for point process generation
Oct 27, 2020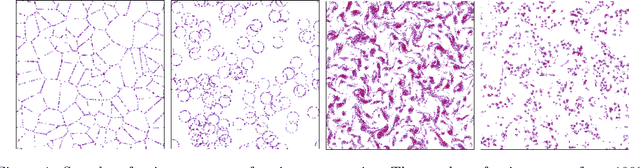


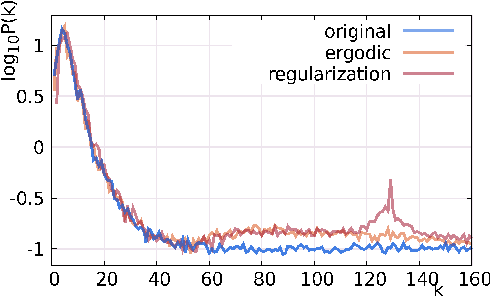
This paper introduces a generative model for planar point processes in a square window, built upon a single realization of a stationary, ergodic point process observed in this window. Inspired by recent advances in gradient descent methods for maximum entropy models, we propose a method to generate similar point patterns by jointly moving particles of an initial Poisson configuration towards a target counting measure. The target measure is generated via a deterministic gradient descent algorithm, so as to match a set of statistics of the given, observed realization. Our statistics are estimators of the multi-scale wavelet phase harmonic covariance, recently proposed in image modeling. They allow one to capture geometric structures through multi-scale interactions between wavelet coefficients. Both our statistics and the gradient descent algorithm scale better with the number of observed points than the classical k-nearest neighbour distances previously used in generative models for point processes, based on the rejection sampling or simulated-annealing. The overall quality of our model is evaluated on point processes with various geometric structures through spectral and topological data analysis.