 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Fine-Grained Speech Inpainting Forensics:A Dataset, Method, and Metric for Multi-Region Tampering Localization
May 04, 2026Recent advances in voice cloning and text-to-speech synthesis have made partial speech manipulation - where an adversary replaces a few words within an utterance to alter its meaning while preserving the speaker's identity - an increasingly realistic threat. Existing audio deepfake detection benchmarks focus on utterance-level binary classification or single-region tampering, leaving a critical gap in detecting and localizing multiple inpainted segments whose count is unknown a priori. We address this gap with three contributions. First, we introduce MIST (Multiregion Inpainting Speech Tampering), a large-scale multilingual dataset spanning 6 languages with 1-3 independently inpainted word-level segments per utterance, generated via LLM-guided semantic replacement and neural voice cloning, with fake content constituting only 2-7% of each utterance. Second, we propose ISA (Iterative Segment Analysis), a backbone-agnostic framework that performs coarse-to-fine sliding-window classification with gap-tolerant region proposal and boundary refinement to recover all tampered regions without prior knowledge of their count. Third, we define SF1@tau, a segment-level F1 metric based on temporal IoU matching that jointly evaluates region count accuracy and localization precision. Zero-shot evaluation reveals that partial inpainting at word granularity remains unsolved by existing deepfake detectors: utterance-level classifiers trained on fully synthesized speech assign near zero fake probability to MIST utterances where only 2-7% of content is manipulated. ISA consistently outperforms non-iterative baselines in this challenging setting, and the dataset, code, and evaluation toolkit are publicly released.
LiveNeRF: Efficient Face Replacement Through Neural Radiance Fields Integration
Nov 10, 2025Face replacement technology enables significant advancements in entertainment, education, and communication applications, including dubbing, virtual avatars, and cross-cultural content adaptation. Our LiveNeRF framework addresses critical limitations of existing methods by achieving real-time performance (33 FPS) with superior visual quality, enabling practical deployment in live streaming, video conferencing, and interactive media. The technology particularly benefits content creators, educators, and individuals with speech impairments through accessible avatar communication. While acknowledging potential misuse in unauthorized deepfake creation, we advocate for responsible deployment with user consent verification and integration with detection systems to ensure positive societal impact while minimizing risks.
S-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025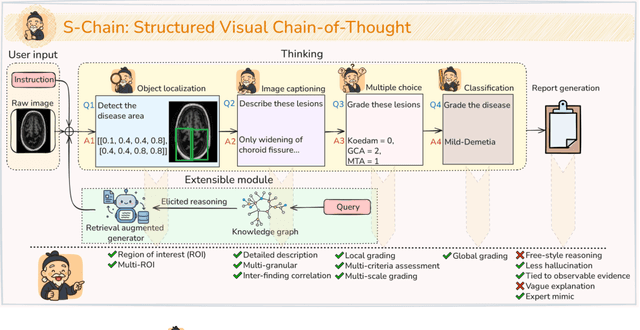
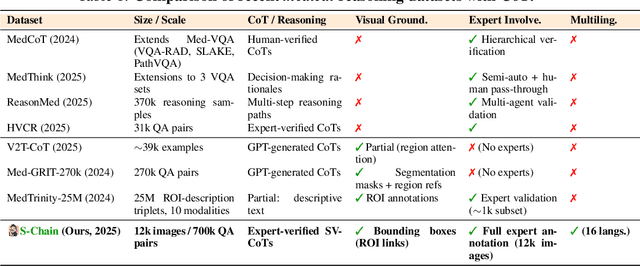
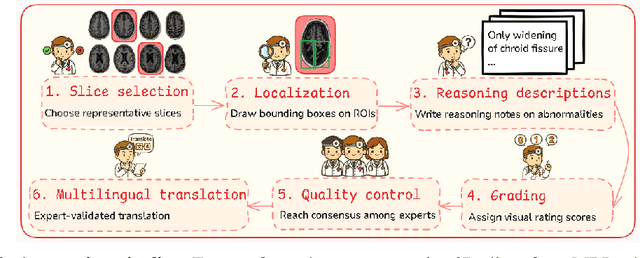
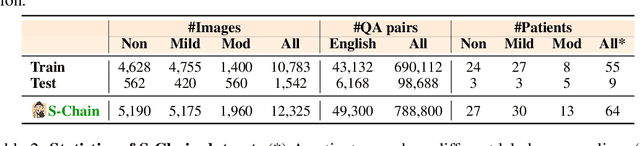
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
PromptGuard: An Orchestrated Prompting Framework for Principled Synthetic Text Generation for Vulnerable Populations using LLMs with Enhanced Safety, Fairness, and Controllability
Sep 10, 2025The proliferation of Large Language Models (LLMs) in real-world applications poses unprecedented risks of generating harmful, biased, or misleading information to vulnerable populations including LGBTQ+ individuals, single parents, and marginalized communities. While existing safety approaches rely on post-hoc filtering or generic alignment techniques, they fail to proactively prevent harmful outputs at the generation source. This paper introduces PromptGuard, a novel modular prompting framework with our breakthrough contribution: VulnGuard Prompt, a hybrid technique that prevents harmful information generation using real-world data-driven contrastive learning. VulnGuard integrates few-shot examples from curated GitHub repositories, ethical chain-of-thought reasoning, and adaptive role-prompting to create population-specific protective barriers. Our framework employs theoretical multi-objective optimization with formal proofs demonstrating 25-30% analytical harm reduction through entropy bounds and Pareto optimality. PromptGuard orchestrates six core modules: Input Classification, VulnGuard Prompting, Ethical Principles Integration, External Tool Interaction, Output Validation, and User-System Interaction, creating an intelligent expert system for real-time harm prevention. We provide comprehensive mathematical formalization including convergence proofs, vulnerability analysis using information theory, and theoretical validation framework using GitHub-sourced datasets, establishing mathematical foundations for systematic empirical research.