 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFineVLA: Multimodal Reasoning-Aware Generalist Robotic Policies via Teacher-Guided Fine-Tuning
Apr 20, 2026Vision-Language-Action (VLA) models have gained much attention from the research community thanks to their strength in translating multimodal observations with linguistic instructions into desired robotic actions. Despite their advancements, VLAs often overlook explicit reasoning and learn the functional input-action mappings, omitting crucial logical steps, which are especially pronounced in interpretability and generalization for complex, long-horizon manipulation tasks. In this work, we propose ReFineVLA, a multimodal reasoning-aware framework that fine-tunes VLAs with teacher-guided reasons. We first augment robotic datasets with reasoning rationales generated by an expert teacher model, guiding VLA models to learn to reason about their actions. Then, we fine-tune pre-trained VLAs with the reasoning-enriched datasets with ReFineVLA, while maintaining the underlying generalization abilities and boosting reasoning capabilities. We also conduct attention map visualization to analyze the alignment among visual observation, linguistic prompts, and to-be-executed actions of ReFineVLA, reflecting the model is ability to focus on relevant tasks and actions. Through this additional step, we explore that ReFineVLA-trained models exhibit a meaningful agreement between vision-language and action domains, highlighting the enhanced multimodal understanding and generalization. Evaluated across a suite of simulated manipulation benchmarks on SimplerEnv with both WidowX and Google Robot tasks, ReFineVLA achieves state-of-the-art performance, in success rate over the second-best method on the both the WidowX benchmark and Google Robot Tasks.
Mitigating Reward Over-optimization in Direct Alignment Algorithms with Importance Sampling
Jun 11, 2025Direct Alignment Algorithms (DAAs) such as Direct Preference Optimization (DPO) have emerged as alternatives to the standard Reinforcement Learning from Human Feedback (RLHF) for aligning large language models (LLMs) with human values. However, these methods are more susceptible to over-optimization, in which the model drifts away from the reference policy, leading to degraded performance as training progresses. This paper proposes a novel importance-sampling approach to mitigate the over-optimization problem of offline DAAs. This approach, called (IS-DAAs), multiplies the DAA objective with an importance ratio that accounts for the reference policy distribution. IS-DAAs additionally avoid the high variance issue associated with importance sampling by clipping the importance ratio to a maximum value. Our extensive experiments demonstrate that IS-DAAs can effectively mitigate over-optimization, especially under low regularization strength, and achieve better performance than other methods designed to address this problem. Our implementations are provided publicly at this link.
EPEM: Efficient Parameter Estimation for Multiple Class Monotone Missing Data
Sep 23, 2020
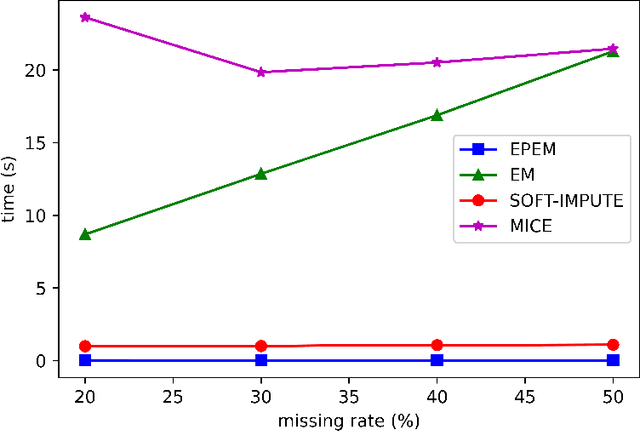

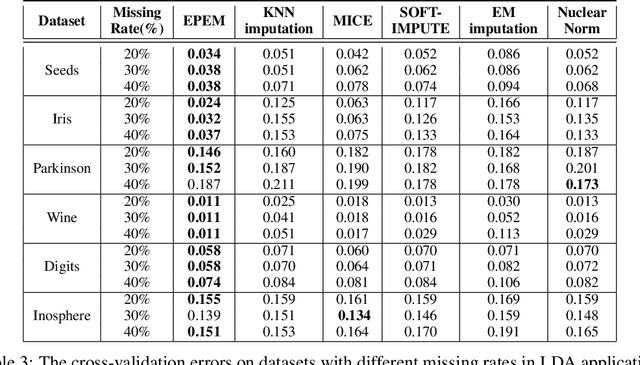
The problem of monotone missing data has been broadly studied during the last two decades and has many applications in different fields such as bioinformatics or statistics. Commonly used imputation techniques require multiple iterations through the data before yielding convergence. Moreover, those approaches may introduce extra noises and biases to the subsequent modeling. In this work, we derive exact formulas and propose a novel algorithm to compute the maximum likelihood estimators (MLEs) of a multiple class, monotone missing dataset when all the covariance matrices of all categories are assumed to be equal, namely EPEM. We then illustrate an application of our proposed methods in Linear Discriminant Analysis (LDA). As the computation is exact, our EPEM algorithm does not require multiple iterations through the data as other imputation approaches, thus promising to handle much less time-consuming than other methods. This effectiveness was validated by empirical results when EPEM reduced the error rates significantly and required a short computation time compared to several imputation-based approaches. We also release all codes and data of our experiments in one GitHub repository to contribute to the research community related to this problem.