 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo as I mean, not as I say: Sequence Loss Training for Spoken Language Understanding
Feb 12, 2021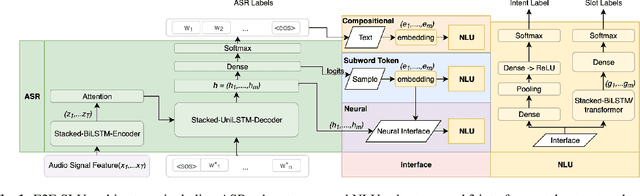
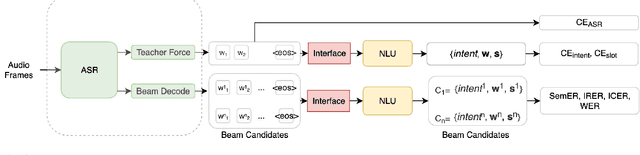
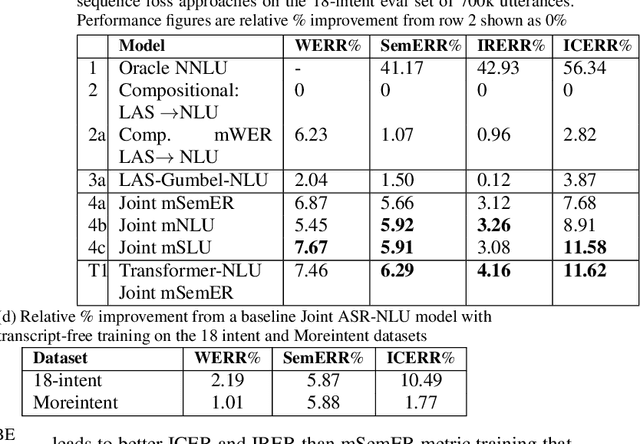
Spoken language understanding (SLU) systems extract transcriptions, as well as semantics of intent or named entities from speech, and are essential components of voice activated systems. SLU models, which either directly extract semantics from audio or are composed of pipelined automatic speech recognition (ASR) and natural language understanding (NLU) models, are typically trained via differentiable cross-entropy losses, even when the relevant performance metrics of interest are word or semantic error rates. In this work, we propose non-differentiable sequence losses based on SLU metrics as a proxy for semantic error and use the REINFORCE trick to train ASR and SLU models with this loss. We show that custom sequence loss training is the state-of-the-art on open SLU datasets and leads to 6% relative improvement in both ASR and NLU performance metrics on large proprietary datasets. We also demonstrate how the semantic sequence loss training paradigm can be used to update ASR and SLU models without transcripts, using semantic feedback alone.
Multi-task Language Modeling for Improving Speech Recognition of Rare Words
Nov 25, 2020

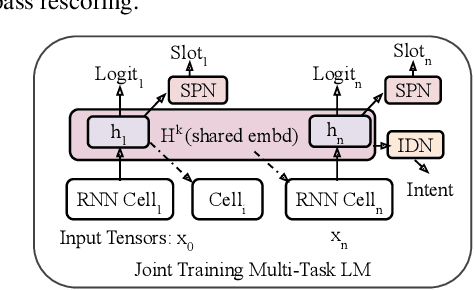
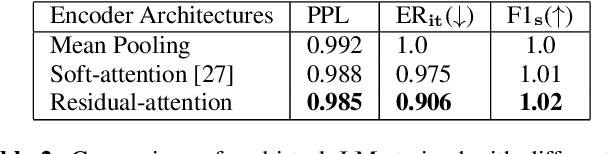
End-to-end automatic speech recognition (ASR) systems are increasingly popular due to their relative architectural simplicity and competitive performance. However, even though the average accuracy of these systems may be high, the performance on rare content words often lags behind hybrid ASR systems. To address this problem, second-pass rescoring is often applied. In this paper, we propose a second-pass system with multi-task learning, utilizing semantic targets (such as intent and slot prediction) to improve speech recognition performance. We show that our rescoring model with trained with these additional tasks outperforms the baseline rescoring model, trained with only the language modeling task, by 1.4% on a general test and by 2.6% on a rare word test set in term of word-error-rate relative (WERR).
Speech To Semantics: Improve ASR and NLU Jointly via All-Neural Interfaces
Aug 14, 2020
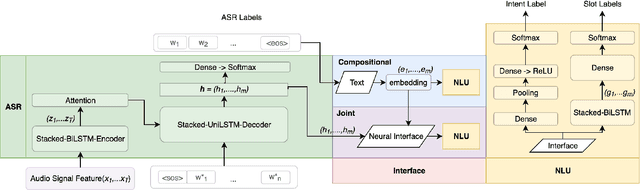
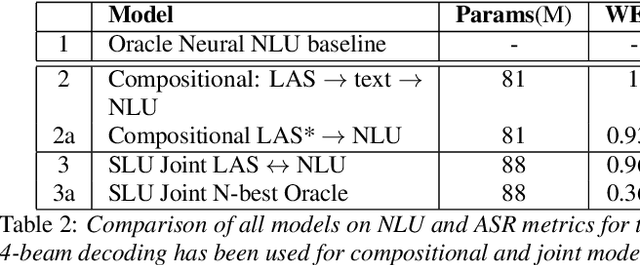
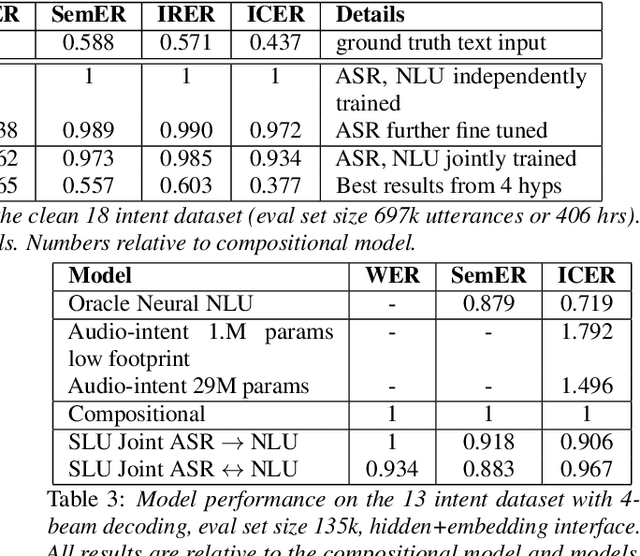
We consider the problem of spoken language understanding (SLU) of extracting natural language intents and associated slot arguments or named entities from speech that is primarily directed at voice assistants. Such a system subsumes both automatic speech recognition (ASR) as well as natural language understanding (NLU). An end-to-end joint SLU model can be built to a required specification opening up the opportunity to deploy on hardware constrained scenarios like devices enabling voice assistants to work offline, in a privacy preserving manner, whilst also reducing server costs. We first present models that extract utterance intent directly from speech without intermediate text output. We then present a compositional model, which generates the transcript using the Listen Attend Spell ASR system and then extracts interpretation using a neural NLU model. Finally, we contrast these methods to a jointly trained end-to-end joint SLU model, consisting of ASR and NLU subsystems which are connected by a neural network based interface instead of text, that produces transcripts as well as NLU interpretation. We show that the jointly trained model shows improvements to ASR incorporating semantic information from NLU and also improves NLU by exposing it to ASR confusion encoded in the hidden layer.
Scalable Multi Corpora Neural Language Models for ASR
Jul 02, 2019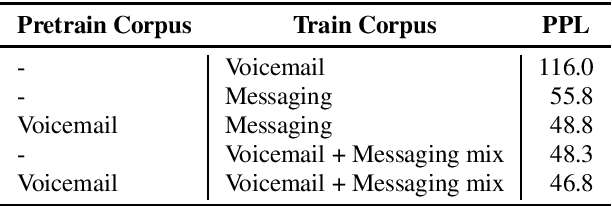


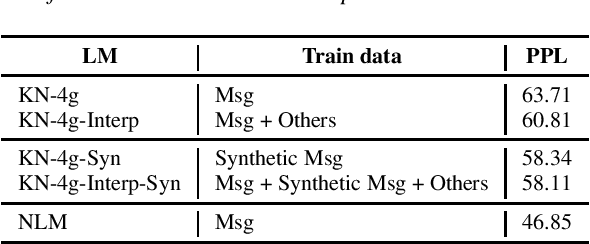
Neural language models (NLM) have been shown to outperform conventional n-gram language models by a substantial margin in Automatic Speech Recognition (ASR) and other tasks. There are, however, a number of challenges that need to be addressed for an NLM to be used in a practical large-scale ASR system. In this paper, we present solutions to some of the challenges, including training NLM from heterogenous corpora, limiting latency impact and handling personalized bias in the second-pass rescorer. Overall, we show that we can achieve a 6.2% relative WER reduction using neural LM in a second-pass n-best rescoring framework with a minimal increase in latency.
Improving noise robustness of automatic speech recognition via parallel data and teacher-student learning
Jan 11, 2019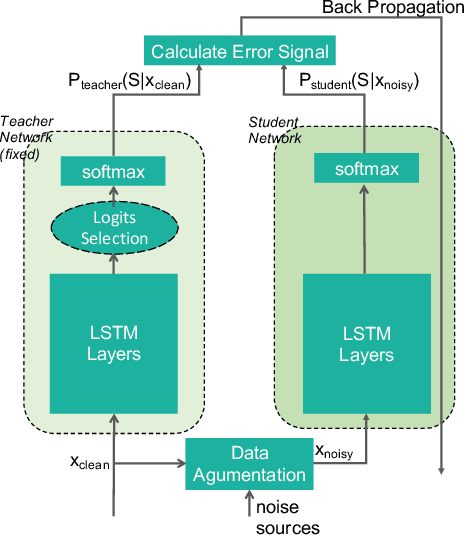
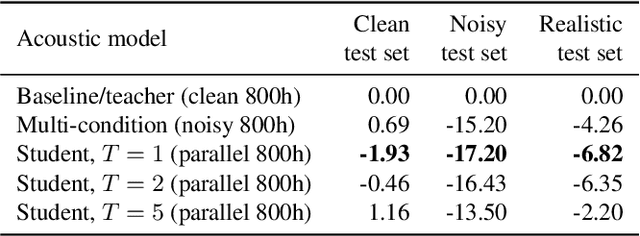
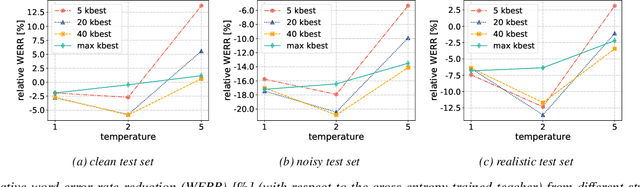
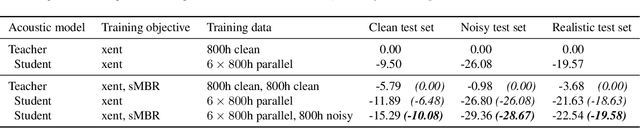
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the k highest values to prevent wrong emphasis of knowledge from the teacher and to reduce bandwidth needed for transferring data. We incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained models apart from cross entropy trained ones. The best sequence trained student model yields relative word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively comparing to a sequence trained teacher.
Data Augmentation for Robust Keyword Spotting under Playback Interference
Aug 01, 2018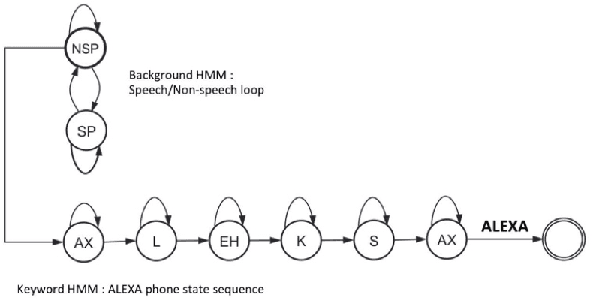
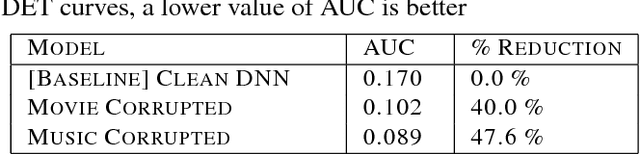
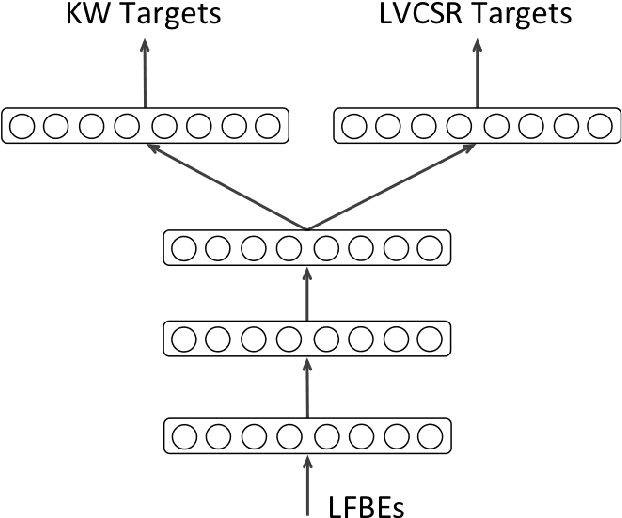
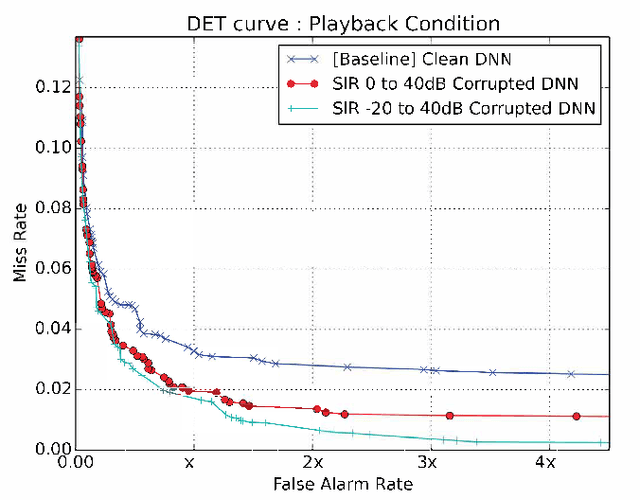
Accurate on-device keyword spotting (KWS) with low false accept and false reject rate is crucial to customer experience for far-field voice control of conversational agents. It is particularly challenging to maintain low false reject rate in real world conditions where there is (a) ambient noise from external sources such as TV, household appliances, or other speech that is not directed at the device (b) imperfect cancellation of the audio playback from the device, resulting in residual echo, after being processed by the Acoustic Echo Cancellation (AEC) system. In this paper, we propose a data augmentation strategy to improve keyword spotting performance under these challenging conditions. The training set audio is artificially corrupted by mixing in music and TV/movie audio, at different signal to interference ratios. Our results show that we get around 30-45% relative reduction in false reject rates, at a range of false alarm rates, under audio playback from such devices.
Contextual Language Model Adaptation for Conversational Agents
Jul 31, 2018
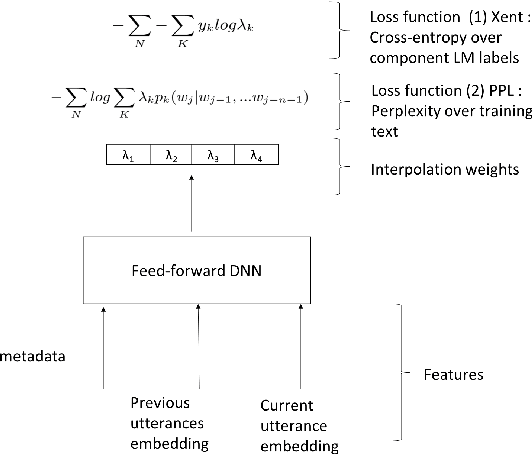
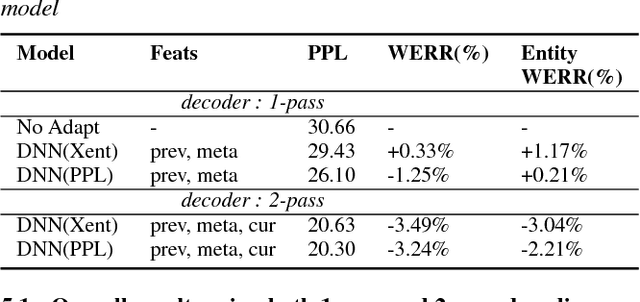
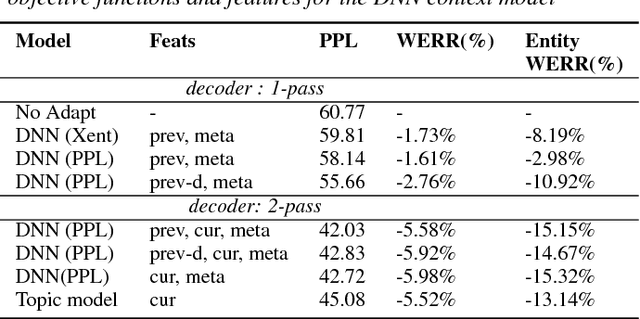
Statistical language models (LM) play a key role in Automatic Speech Recognition (ASR) systems used by conversational agents. These ASR systems should provide a high accuracy under a variety of speaking styles, domains, vocabulary and argots. In this paper, we present a DNN-based method to adapt the LM to each user-agent interaction based on generalized contextual information, by predicting an optimal, context-dependent set of LM interpolation weights. We show that this framework for contextual adaptation provides accuracy improvements under different possible mixture LM partitions that are relevant for both (1) Goal-oriented conversational agents where it's natural to partition the data by the requested application and for (2) Non-goal oriented conversational agents where the data can be partitioned using topic labels that come from predictions of a topic classifier. We obtain a relative WER improvement of 3% with a 1-pass decoding strategy and 6% in a 2-pass decoding framework, over an unadapted model. We also show up to a 15% relative improvement in recognizing named entities which is of significant value for conversational ASR systems.
On Evaluating and Comparing Conversational Agents
Jan 11, 2018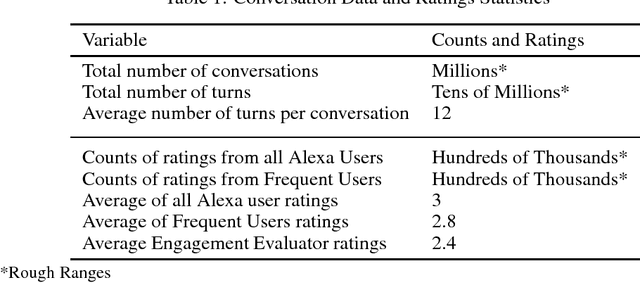
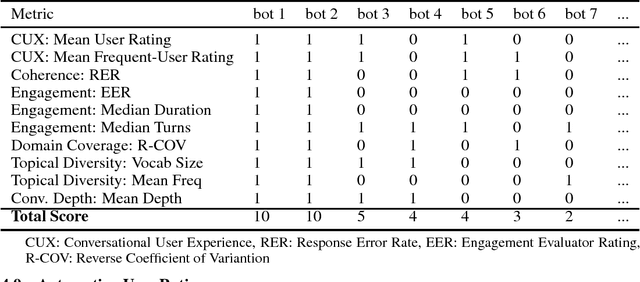
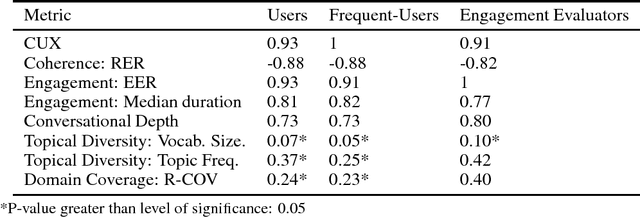

Conversational agents are exploding in popularity. However, much work remains in the area of non goal-oriented conversations, despite significant growth in research interest over recent years. To advance the state of the art in conversational AI, Amazon launched the Alexa Prize, a 2.5-million dollar university competition where sixteen selected university teams built conversational agents to deliver the best social conversational experience. Alexa Prize provided the academic community with the unique opportunity to perform research with a live system used by millions of users. The subjectivity associated with evaluating conversations is key element underlying the challenge of building non-goal oriented dialogue systems. In this paper, we propose a comprehensive evaluation strategy with multiple metrics designed to reduce subjectivity by selecting metrics which correlate well with human judgement. The proposed metrics provide granular analysis of the conversational agents, which is not captured in human ratings. We show that these metrics can be used as a reasonable proxy for human judgment. We provide a mechanism to unify the metrics for selecting the top performing agents, which has also been applied throughout the Alexa Prize competition. To our knowledge, to date it is the largest setting for evaluating agents with millions of conversations and hundreds of thousands of ratings from users. We believe that this work is a step towards an automatic evaluation process for conversational AIs.
* 10 pages, 5 tables. NIPS 2017 Conversational AI workshop. http://alborz-geramifard.com/workshops/nips17-Conversational-AI/Main.html
Topic-based Evaluation for Conversational Bots
Jan 11, 2018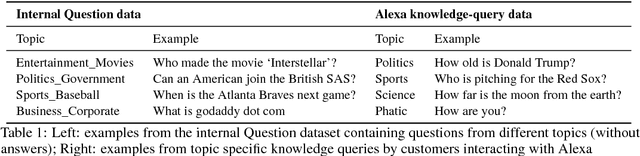
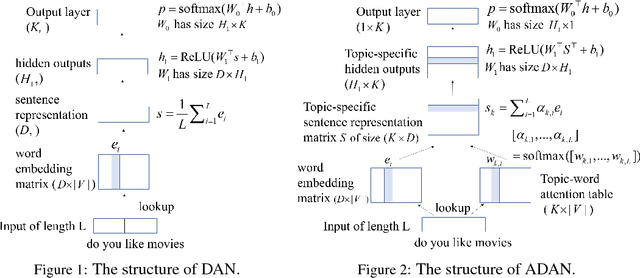

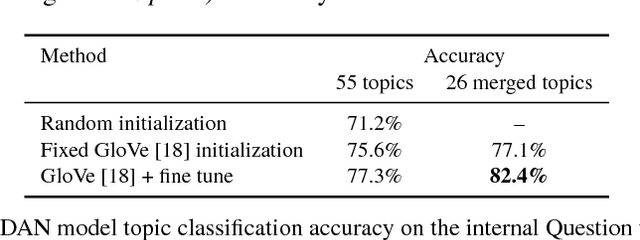
Dialog evaluation is a challenging problem, especially for non task-oriented dialogs where conversational success is not well-defined. We propose to evaluate dialog quality using topic-based metrics that describe the ability of a conversational bot to sustain coherent and engaging conversations on a topic, and the diversity of topics that a bot can handle. To detect conversation topics per utterance, we adopt Deep Average Networks (DAN) and train a topic classifier on a variety of question and query data categorized into multiple topics. We propose a novel extension to DAN by adding a topic-word attention table that allows the system to jointly capture topic keywords in an utterance and perform topic classification. We compare our proposed topic based metrics with the ratings provided by users and show that our metrics both correlate with and complement human judgment. Our analysis is performed on tens of thousands of real human-bot dialogs from the Alexa Prize competition and highlights user expectations for conversational bots.
* 10 Pages, 2 figures, 9 tables. NIPS 2017 Conversational AI workshop paper. http://alborz-geramifard.com/workshops/nips17-Conversational-AI/Main.html
Max-Pooling Loss Training of Long Short-Term Memory Networks for Small-Footprint Keyword Spotting
May 05, 2017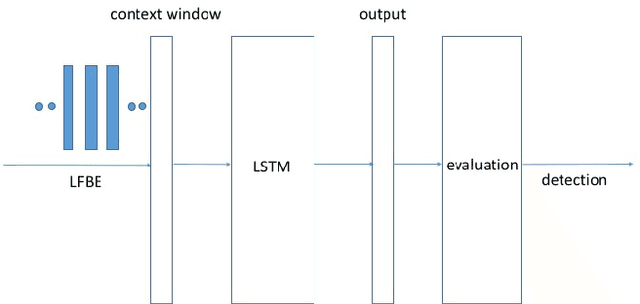

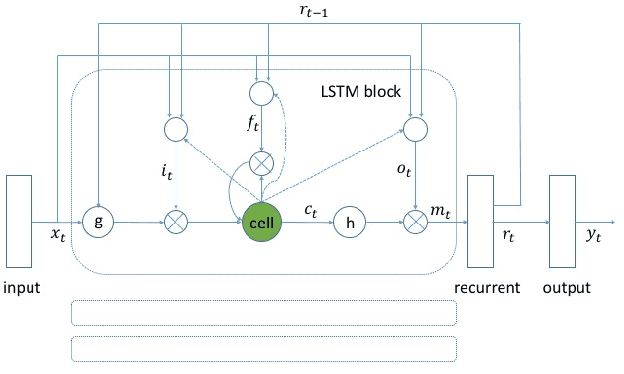
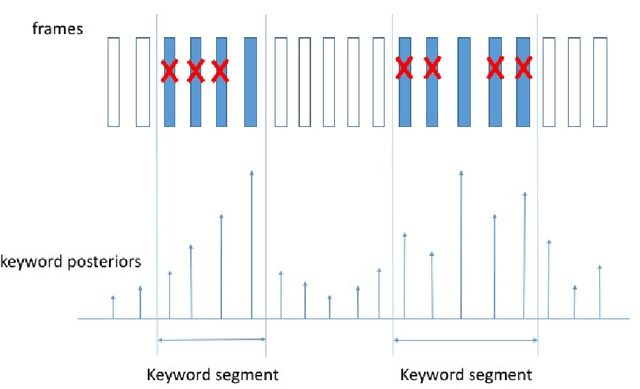
We propose a max-pooling based loss function for training Long Short-Term Memory (LSTM) networks for small-footprint keyword spotting (KWS), with low CPU, memory, and latency requirements. The max-pooling loss training can be further guided by initializing with a cross-entropy loss trained network. A posterior smoothing based evaluation approach is employed to measure keyword spotting performance. Our experimental results show that LSTM models trained using cross-entropy loss or max-pooling loss outperform a cross-entropy loss trained baseline feed-forward Deep Neural Network (DNN). In addition, max-pooling loss trained LSTM with randomly initialized network performs better compared to cross-entropy loss trained LSTM. Finally, the max-pooling loss trained LSTM initialized with a cross-entropy pre-trained network shows the best performance, which yields $67.6\%$ relative reduction compared to baseline feed-forward DNN in Area Under the Curve (AUC) measure.