 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Causal Models with Active Interventions
Sep 06, 2021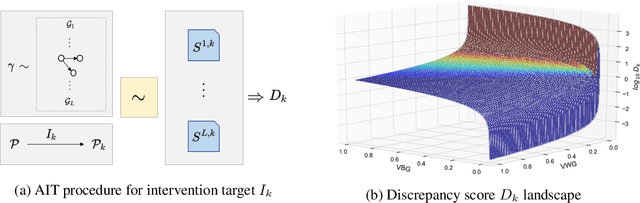
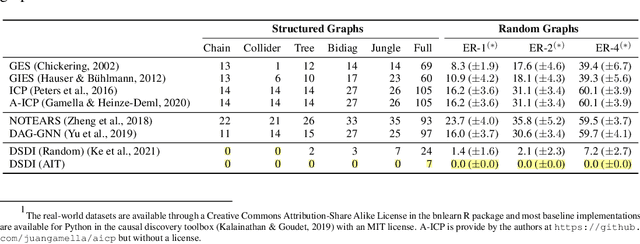
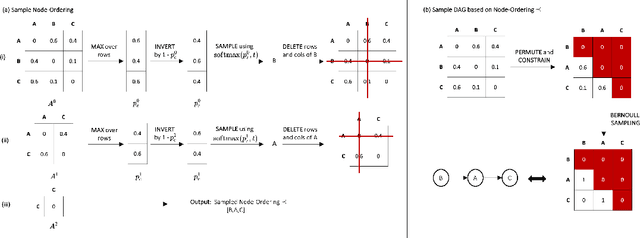
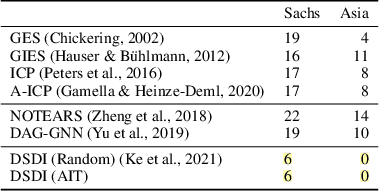
Discovering causal structures from data is a challenging inference problem of fundamental importance in all areas of science. The appealing scaling properties of neural networks have recently led to a surge of interest in differentiable neural network-based methods for learning causal structures from data. So far differentiable causal discovery has focused on static datasets of observational or interventional origin. In this work, we introduce an active intervention-targeting mechanism which enables a quick identification of the underlying causal structure of the data-generating process. Our method significantly reduces the required number of interactions compared with random intervention targeting and is applicable for both discrete and continuous optimization formulations of learning the underlying directed acyclic graph (DAG) from data. We examine the proposed method across a wide range of settings and demonstrate superior performance on multiple benchmarks from simulated to real-world data.
Discrete-Valued Neural Communication
Jul 10, 2021

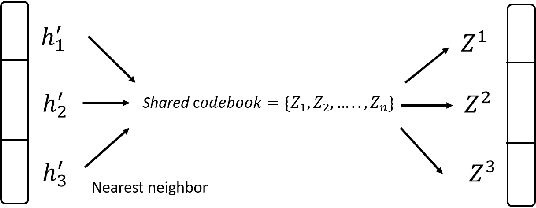
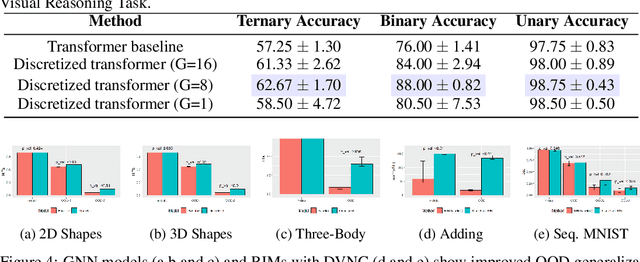
Deep learning has advanced from fully connected architectures to structured models organized into components, e.g., the transformer composed of positional elements, modular architectures divided into slots, and graph neural nets made up of nodes. In structured models, an interesting question is how to conduct dynamic and possibly sparse communication among the separate components. Here, we explore the hypothesis that restricting the transmitted information among components to discrete representations is a beneficial bottleneck. The motivating intuition is human language in which communication occurs through discrete symbols. Even though individuals have different understandings of what a "cat" is based on their specific experiences, the shared discrete token makes it possible for communication among individuals to be unimpeded by individual differences in internal representation. To discretize the values of concepts dynamically communicated among specialist components, we extend the quantization mechanism from the Vector-Quantized Variational Autoencoder to multi-headed discretization with shared codebooks and use it for discrete-valued neural communication (DVNC). Our experiments show that DVNC substantially improves systematic generalization in a variety of architectures -- transformers, modular architectures, and graph neural networks. We also show that the DVNC is robust to the choice of hyperparameters, making the method very useful in practice. Moreover, we establish a theoretical justification of our discretization process, proving that it has the ability to increase noise robustness and reduce the underlying dimensionality of the model.
Systematic Evaluation of Causal Discovery in Visual Model Based Reinforcement Learning
Jul 02, 2021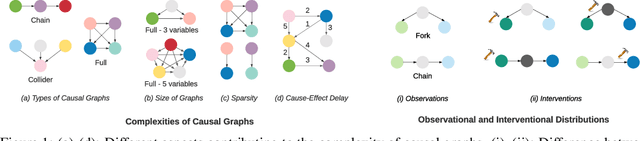
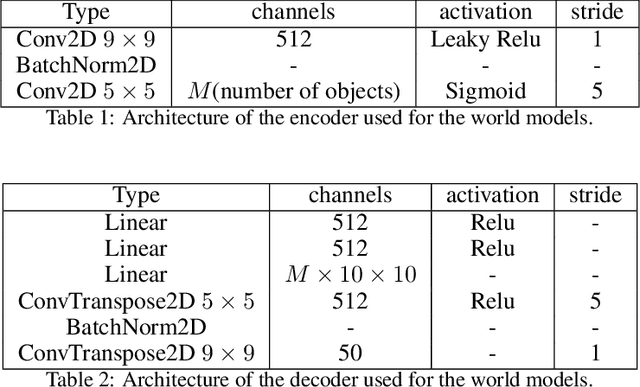
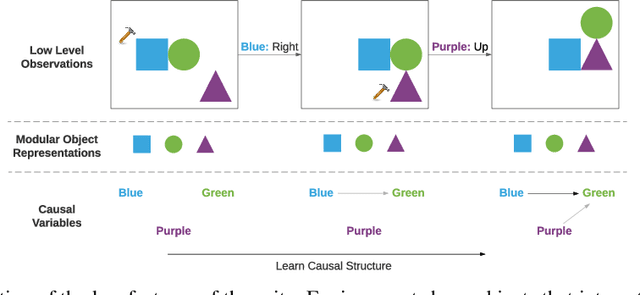
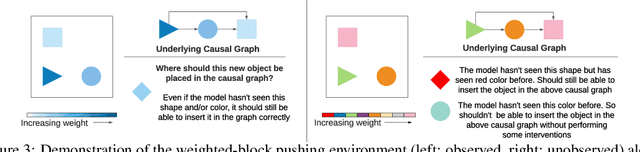
Inducing causal relationships from observations is a classic problem in machine learning. Most work in causality starts from the premise that the causal variables themselves are observed. However, for AI agents such as robots trying to make sense of their environment, the only observables are low-level variables like pixels in images. To generalize well, an agent must induce high-level variables, particularly those which are causal or are affected by causal variables. A central goal for AI and causality is thus the joint discovery of abstract representations and causal structure. However, we note that existing environments for studying causal induction are poorly suited for this objective because they have complicated task-specific causal graphs which are impossible to manipulate parametrically (e.g., number of nodes, sparsity, causal chain length, etc.). In this work, our goal is to facilitate research in learning representations of high-level variables as well as causal structures among them. In order to systematically probe the ability of methods to identify these variables and structures, we design a suite of benchmarking RL environments. We evaluate various representation learning algorithms from the literature and find that explicitly incorporating structure and modularity in models can help causal induction in model-based reinforcement learning.
Variational Causal Networks: Approximate Bayesian Inference over Causal Structures
Jun 14, 2021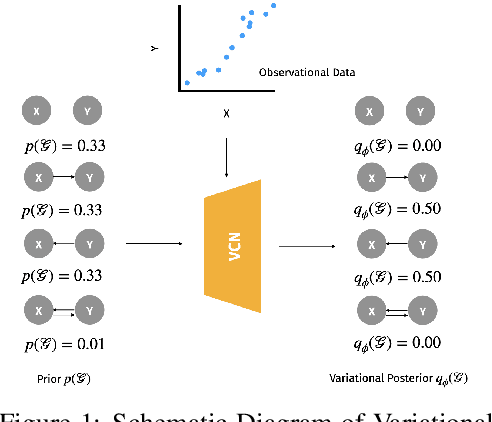
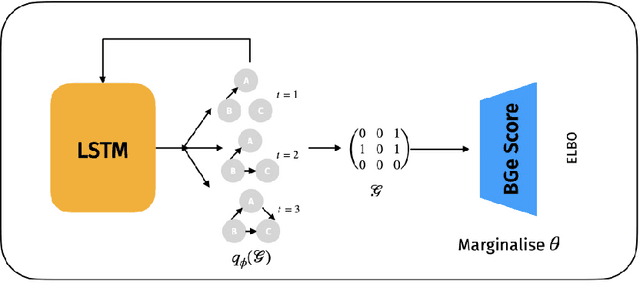
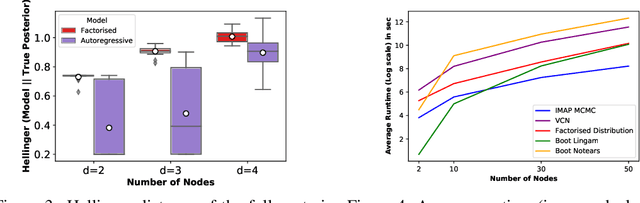
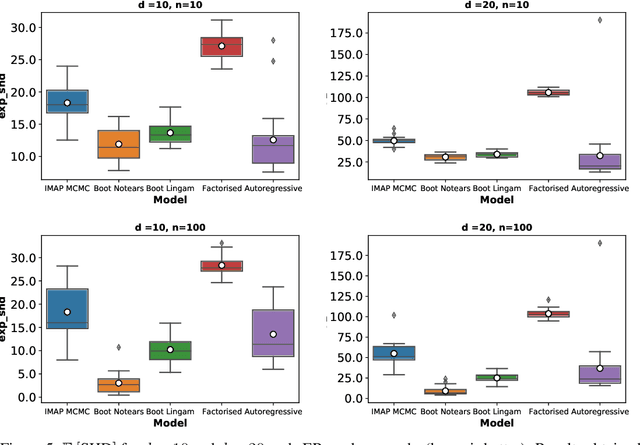
Learning the causal structure that underlies data is a crucial step towards robust real-world decision making. The majority of existing work in causal inference focuses on determining a single directed acyclic graph (DAG) or a Markov equivalence class thereof. However, a crucial aspect to acting intelligently upon the knowledge about causal structure which has been inferred from finite data demands reasoning about its uncertainty. For instance, planning interventions to find out more about the causal mechanisms that govern our data requires quantifying epistemic uncertainty over DAGs. While Bayesian causal inference allows to do so, the posterior over DAGs becomes intractable even for a small number of variables. Aiming to overcome this issue, we propose a form of variational inference over the graphs of Structural Causal Models (SCMs). To this end, we introduce a parametric variational family modelled by an autoregressive distribution over the space of discrete DAGs. Its number of parameters does not grow exponentially with the number of variables and can be tractably learned by maximising an Evidence Lower Bound (ELBO). In our experiments, we demonstrate that the proposed variational posterior is able to provide a good approximation of the true posterior.
Robust Representation Learning via Perceptual Similarity Metrics
Jun 11, 2021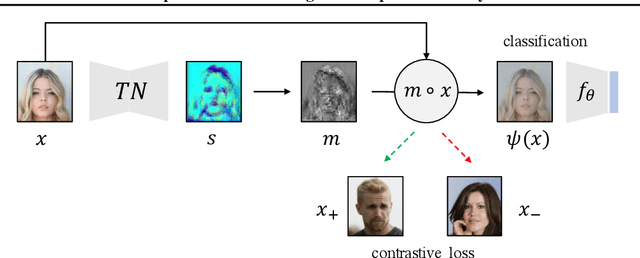
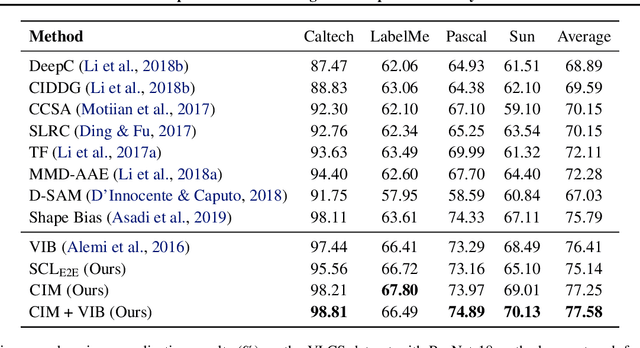
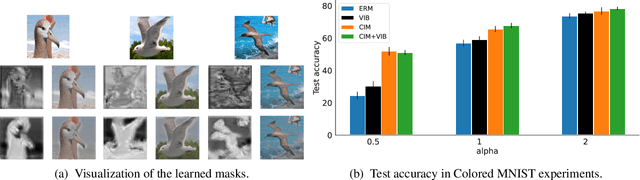
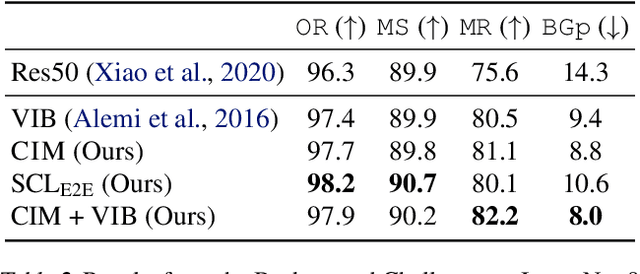
A fundamental challenge in artificial intelligence is learning useful representations of data that yield good performance on a downstream task, without overfitting to spurious input features. Extracting such task-relevant predictive information is particularly difficult for real-world datasets. In this work, we propose Contrastive Input Morphing (CIM), a representation learning framework that learns input-space transformations of the data to mitigate the effect of irrelevant input features on downstream performance. Our method leverages a perceptual similarity metric via a triplet loss to ensure that the transformation preserves task-relevant information.Empirically, we demonstrate the efficacy of our approach on tasks which typically suffer from the presence of spurious correlations: classification with nuisance information, out-of-distribution generalization, and preservation of subgroup accuracies. We additionally show that CIM is complementary to other mutual information-based representation learning techniques, and demonstrate that it improves the performance of variational information bottleneck (VIB) when used together.
Fast and Slow Learning of Recurrent Independent Mechanisms
May 19, 2021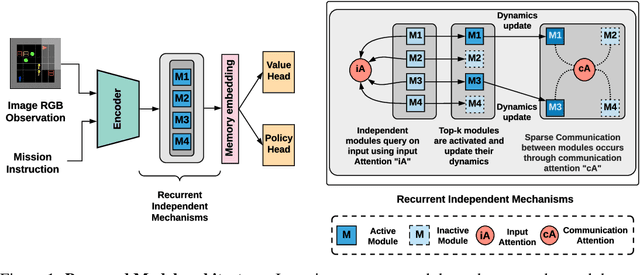

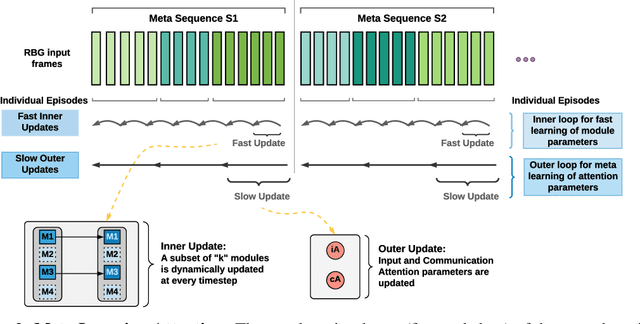
Decomposing knowledge into interchangeable pieces promises a generalization advantage when there are changes in distribution. A learning agent interacting with its environment is likely to be faced with situations requiring novel combinations of existing pieces of knowledge. We hypothesize that such a decomposition of knowledge is particularly relevant for being able to generalize in a systematic manner to out-of-distribution changes. To study these ideas, we propose a particular training framework in which we assume that the pieces of knowledge an agent needs and its reward function are stationary and can be re-used across tasks. An attention mechanism dynamically selects which modules can be adapted to the current task, and the parameters of the selected modules are allowed to change quickly as the learner is confronted with variations in what it experiences, while the parameters of the attention mechanisms act as stable, slowly changing, meta-parameters. We focus on pieces of knowledge captured by an ensemble of modules sparsely communicating with each other via a bottleneck of attention. We find that meta-learning the modular aspects of the proposed system greatly helps in achieving faster adaptation in a reinforcement learning setup involving navigation in a partially observed grid world with image-level input. We also find that reversing the role of parameters and meta-parameters does not work nearly as well, suggesting a particular role for fast adaptation of the dynamically selected modules.
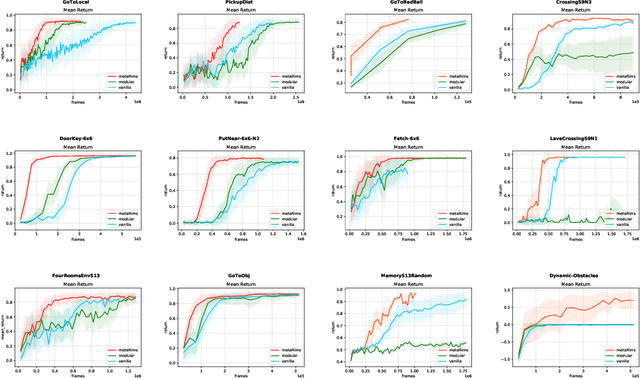
Neural Production Systems
Mar 02, 2021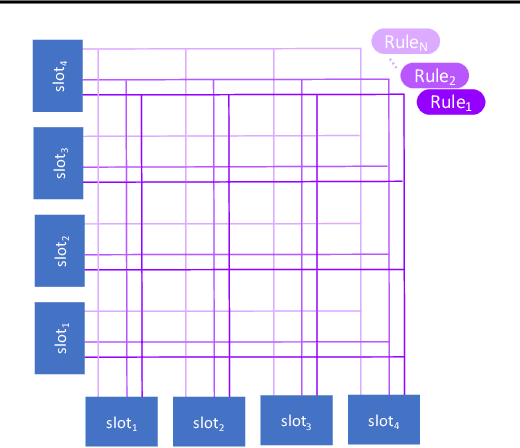

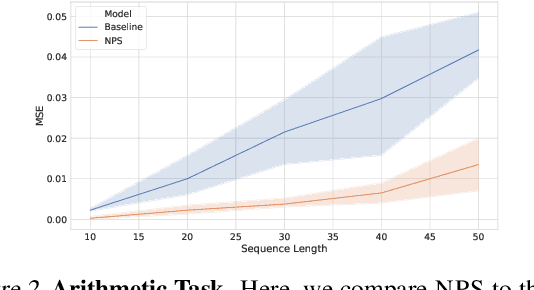
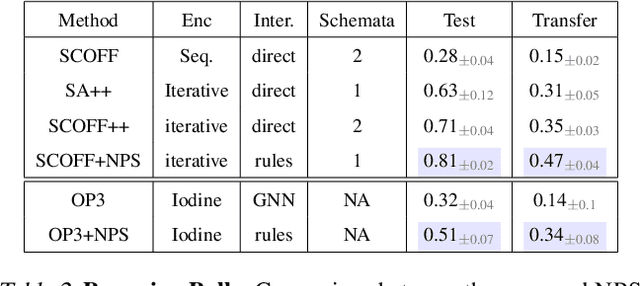
Visual environments are structured, consisting of distinct objects or entities. These entities have properties -- both visible and latent -- that determine the manner in which they interact with one another. To partition images into entities, deep-learning researchers have proposed structural inductive biases such as slot-based architectures. To model interactions among entities, equivariant graph neural nets (GNNs) are used, but these are not particularly well suited to the task for two reasons. First, GNNs do not predispose interactions to be sparse, as relationships among independent entities are likely to be. Second, GNNs do not factorize knowledge about interactions in an entity-conditional manner. As an alternative, we take inspiration from cognitive science and resurrect a classic approach, production systems, which consist of a set of rule templates that are applied by binding placeholder variables in the rules to specific entities. Rules are scored on their match to entities, and the best fitting rules are applied to update entity properties. In a series of experiments, we demonstrate that this architecture achieves a flexible, dynamic flow of control and serves to factorize entity-specific and rule-based information. This disentangling of knowledge achieves robust future-state prediction in rich visual environments, outperforming state-of-the-art methods using GNNs, and allows for the extrapolation from simple (few object) environments to more complex environments.
Coordination Among Neural Modules Through a Shared Global Workspace
Mar 01, 2021
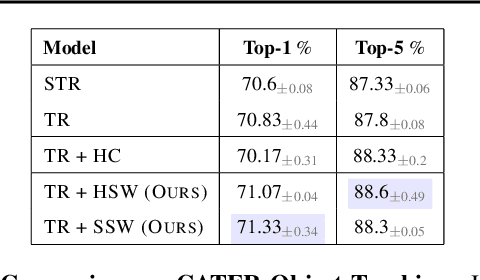
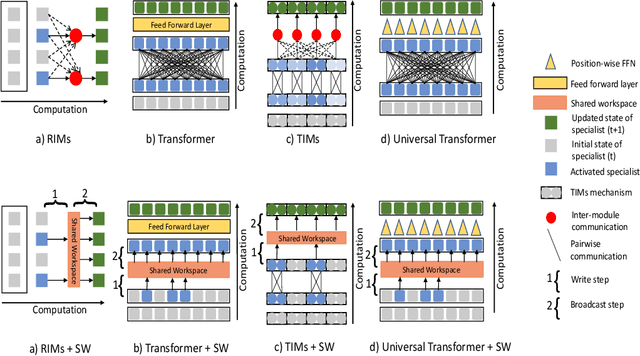
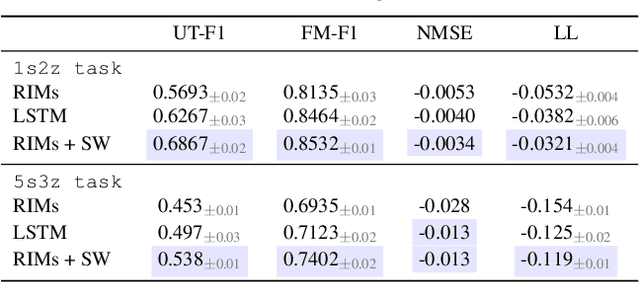
Deep learning has seen a movement away from representing examples with a monolithic hidden state towards a richly structured state. For example, Transformers segment by position, and object-centric architectures decompose images into entities. In all these architectures, interactions between different elements are modeled via pairwise interactions: Transformers make use of self-attention to incorporate information from other positions; object-centric architectures make use of graph neural networks to model interactions among entities. However, pairwise interactions may not achieve global coordination or a coherent, integrated representation that can be used for downstream tasks. In cognitive science, a global workspace architecture has been proposed in which functionally specialized components share information through a common, bandwidth-limited communication channel. We explore the use of such a communication channel in the context of deep learning for modeling the structure of complex environments. The proposed method includes a shared workspace through which communication among different specialist modules takes place but due to limits on the communication bandwidth, specialist modules must compete for access. We show that capacity limitations have a rational basis in that (1) they encourage specialization and compositionality and (2) they facilitate the synchronization of otherwise independent specialists.
Transformers with Competitive Ensembles of Independent Mechanisms
Feb 27, 2021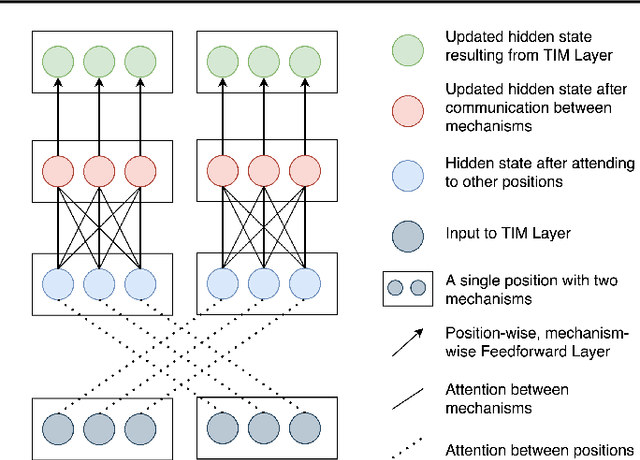
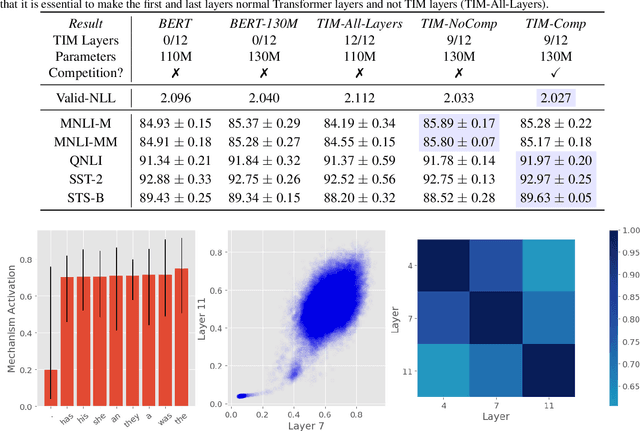
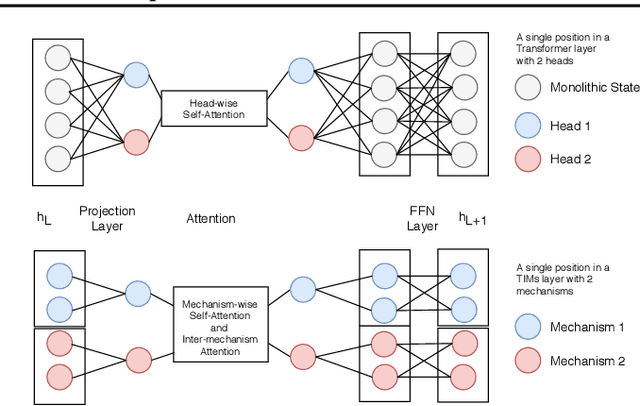
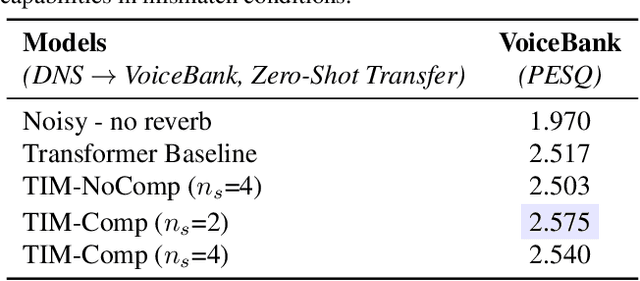
An important development in deep learning from the earliest MLPs has been a move towards architectures with structural inductive biases which enable the model to keep distinct sources of information and routes of processing well-separated. This structure is linked to the notion of independent mechanisms from the causality literature, in which a mechanism is able to retain the same processing as irrelevant aspects of the world are changed. For example, convnets enable separation over positions, while attention-based architectures (especially Transformers) learn which combination of positions to process dynamically. In this work we explore a way in which the Transformer architecture is deficient: it represents each position with a large monolithic hidden representation and a single set of parameters which are applied over the entire hidden representation. This potentially throws unrelated sources of information together, and limits the Transformer's ability to capture independent mechanisms. To address this, we propose Transformers with Independent Mechanisms (TIM), a new Transformer layer which divides the hidden representation and parameters into multiple mechanisms, which only exchange information through attention. Additionally, we propose a competition mechanism which encourages these mechanisms to specialize over time steps, and thus be more independent. We study TIM on a large-scale BERT model, on the Image Transformer, and on speech enhancement and find evidence for semantically meaningful specialization as well as improved performance.
Towards Causal Representation Learning
Feb 22, 2021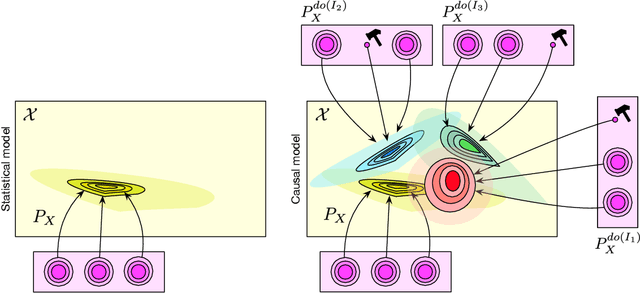
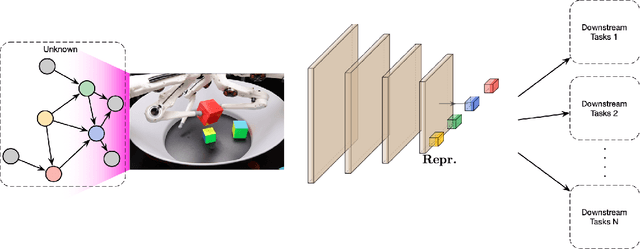
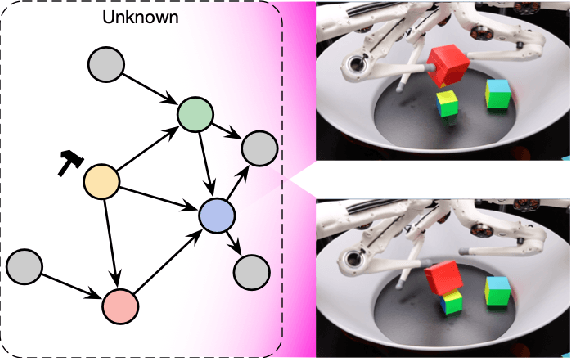

The two fields of machine learning and graphical causality arose and developed separately. However, there is now cross-pollination and increasing interest in both fields to benefit from the advances of the other. In the present paper, we review fundamental concepts of causal inference and relate them to crucial open problems of machine learning, including transfer and generalization, thereby assaying how causality can contribute to modern machine learning research. This also applies in the opposite direction: we note that most work in causality starts from the premise that the causal variables are given. A central problem for AI and causality is, thus, causal representation learning, the discovery of high-level causal variables from low-level observations. Finally, we delineate some implications of causality for machine learning and propose key research areas at the intersection of both communities.