 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparsely Used Overcomplete Dictionaries via Alternating Minimization
Jul 28, 2014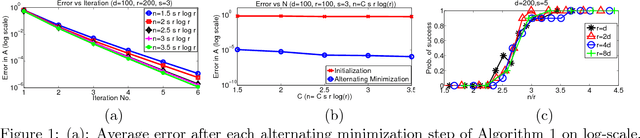
We consider the problem of sparse coding, where each sample consists of a sparse linear combination of a set of dictionary atoms, and the task is to learn both the dictionary elements and the mixing coefficients. Alternating minimization is a popular heuristic for sparse coding, where the dictionary and the coefficients are estimated in alternate steps, keeping the other fixed. Typically, the coefficients are estimated via $\ell_1$ minimization, keeping the dictionary fixed, and the dictionary is estimated through least squares, keeping the coefficients fixed. In this paper, we establish local linear convergence for this variant of alternating minimization and establish that the basin of attraction for the global optimum (corresponding to the true dictionary and the coefficients) is $\order{1/s^2}$, where $s$ is the sparsity level in each sample and the dictionary satisfies RIP. Combined with the recent results of approximate dictionary estimation, this yields provable guarantees for exact recovery of both the dictionary elements and the coefficients, when the dictionary elements are incoherent.
A Clustering Approach to Learn Sparsely-Used Overcomplete Dictionaries
Jul 07, 2014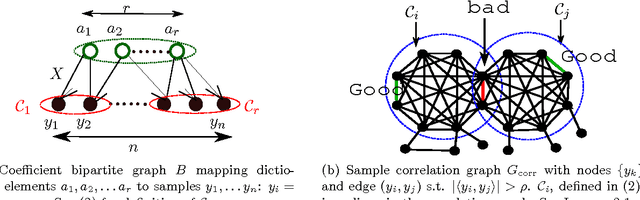
We consider the problem of learning overcomplete dictionaries in the context of sparse coding, where each sample selects a sparse subset of dictionary elements. Our main result is a strategy to approximately recover the unknown dictionary using an efficient algorithm. Our algorithm is a clustering-style procedure, where each cluster is used to estimate a dictionary element. The resulting solution can often be further cleaned up to obtain a high accuracy estimate, and we provide one simple scenario where $\ell_1$-regularized regression can be used for such a second stage.
High-Dimensional Covariance Decomposition into Sparse Markov and Independence Models
Dec 14, 2013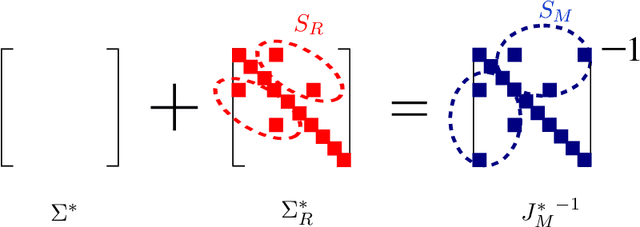
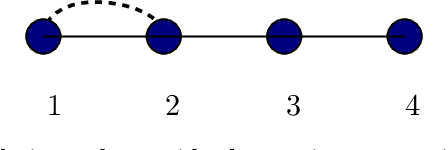
Fitting high-dimensional data involves a delicate tradeoff between faithful representation and the use of sparse models. Too often, sparsity assumptions on the fitted model are too restrictive to provide a faithful representation of the observed data. In this paper, we present a novel framework incorporating sparsity in different domains.We decompose the observed covariance matrix into a sparse Gaussian Markov model (with a sparse precision matrix) and a sparse independence model (with a sparse covariance matrix). Our framework incorporates sparse covariance and sparse precision estimation as special cases and thus introduces a richer class of high-dimensional models. We characterize sufficient conditions for identifiability of the two models, \viz Markov and independence models. We propose an efficient decomposition method based on a modification of the popular $\ell_1$-penalized maximum-likelihood estimator ($\ell_1$-MLE). We establish that our estimator is consistent in both the domains, i.e., it successfully recovers the supports of both Markov and independence models, when the number of samples $n$ scales as $n = \Omega(d^2 \log p)$, where $p$ is the number of variables and $d$ is the maximum node degree in the Markov model. Our experiments validate these results and also demonstrate that our models have better inference accuracy under simple algorithms such as loopy belief propagation.
Nonparametric Estimation of Multi-View Latent Variable Models
Dec 08, 2013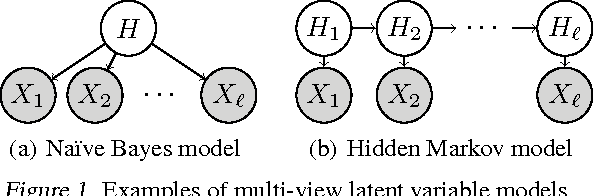
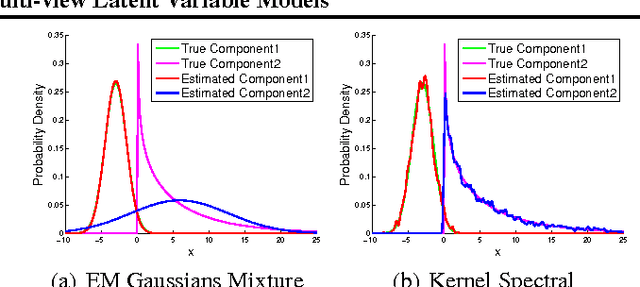
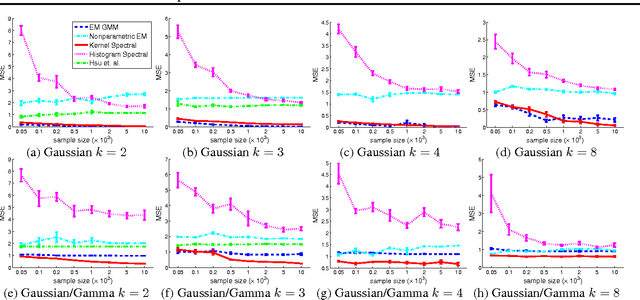
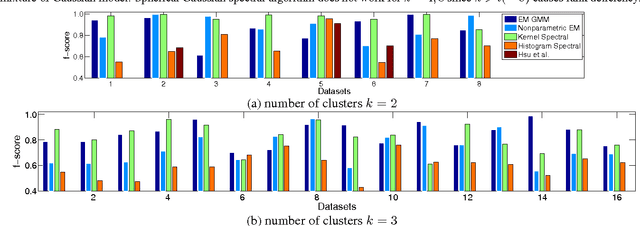
Spectral methods have greatly advanced the estimation of latent variable models, generating a sequence of novel and efficient algorithms with strong theoretical guarantees. However, current spectral algorithms are largely restricted to mixtures of discrete or Gaussian distributions. In this paper, we propose a kernel method for learning multi-view latent variable models, allowing each mixture component to be nonparametric. The key idea of the method is to embed the joint distribution of a multi-view latent variable into a reproducing kernel Hilbert space, and then the latent parameters are recovered using a robust tensor power method. We establish that the sample complexity for the proposed method is quadratic in the number of latent components and is a low order polynomial in the other relevant parameters. Thus, our non-parametric tensor approach to learning latent variable models enjoys good sample and computational efficiencies. Moreover, the non-parametric tensor power method compares favorably to EM algorithm and other existing spectral algorithms in our experiments.
When are Overcomplete Topic Models Identifiable? Uniqueness of Tensor Tucker Decompositions with Structured Sparsity
Aug 13, 2013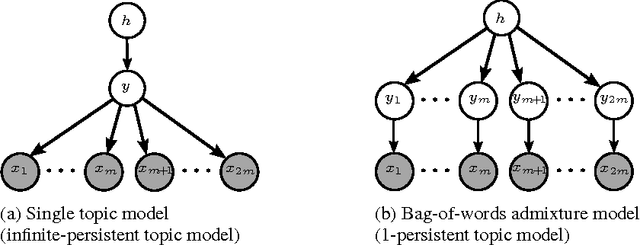
Overcomplete latent representations have been very popular for unsupervised feature learning in recent years. In this paper, we specify which overcomplete models can be identified given observable moments of a certain order. We consider probabilistic admixture or topic models in the overcomplete regime, where the number of latent topics can greatly exceed the size of the observed word vocabulary. While general overcomplete topic models are not identifiable, we establish generic identifiability under a constraint, referred to as topic persistence. Our sufficient conditions for identifiability involve a novel set of "higher order" expansion conditions on the topic-word matrix or the population structure of the model. This set of higher-order expansion conditions allow for overcomplete models, and require the existence of a perfect matching from latent topics to higher order observed words. We establish that random structured topic models are identifiable w.h.p. in the overcomplete regime. Our identifiability results allows for general (non-degenerate) distributions for modeling the topic proportions, and thus, we can handle arbitrarily correlated topics in our framework. Our identifiability results imply uniqueness of a class of tensor decompositions with structured sparsity which is contained in the class of Tucker decompositions, but is more general than the Candecomp/Parafac (CP) decomposition.
Learning Topic Models and Latent Bayesian Networks Under Expansion Constraints
May 24, 2013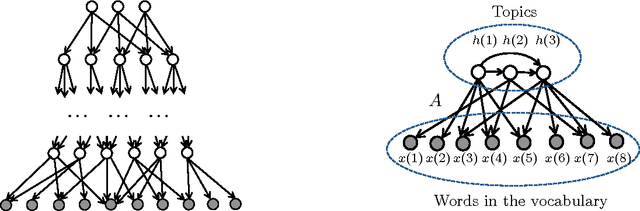

Unsupervised estimation of latent variable models is a fundamental problem central to numerous applications of machine learning and statistics. This work presents a principled approach for estimating broad classes of such models, including probabilistic topic models and latent linear Bayesian networks, using only second-order observed moments. The sufficient conditions for identifiability of these models are primarily based on weak expansion constraints on the topic-word matrix, for topic models, and on the directed acyclic graph, for Bayesian networks. Because no assumptions are made on the distribution among the latent variables, the approach can handle arbitrary correlations among the topics or latent factors. In addition, a tractable learning method via $\ell_1$ optimization is proposed and studied in numerical experiments.
Learning loopy graphical models with latent variables: Efficient methods and guarantees
Apr 22, 2013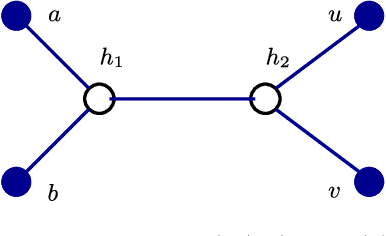
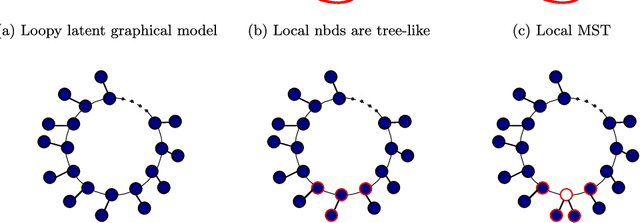

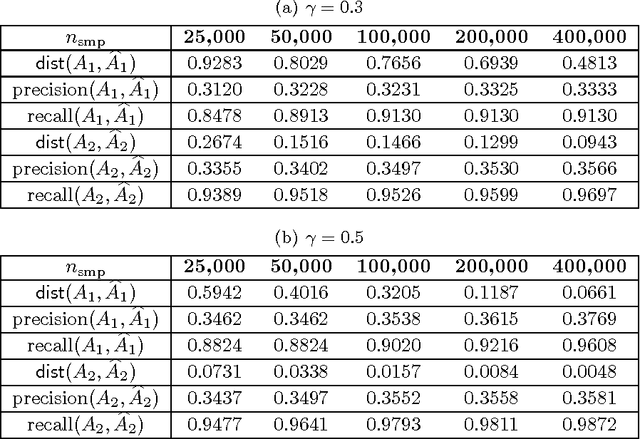
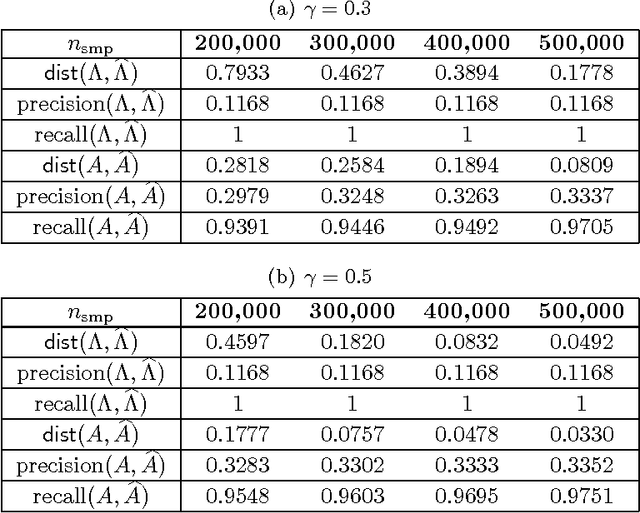
The problem of structure estimation in graphical models with latent variables is considered. We characterize conditions for tractable graph estimation and develop efficient methods with provable guarantees. We consider models where the underlying Markov graph is locally tree-like, and the model is in the regime of correlation decay. For the special case of the Ising model, the number of samples $n$ required for structural consistency of our method scales as $n=\Omega(\theta_{\min}^{-\delta\eta(\eta+1)-2}\log p)$, where p is the number of variables, $\theta_{\min}$ is the minimum edge potential, $\delta$ is the depth (i.e., distance from a hidden node to the nearest observed nodes), and $\eta$ is a parameter which depends on the bounds on node and edge potentials in the Ising model. Necessary conditions for structural consistency under any algorithm are derived and our method nearly matches the lower bound on sample requirements. Further, the proposed method is practical to implement and provides flexibility to control the number of latent variables and the cycle lengths in the output graph.
* Published in at http://dx.doi.org/10.1214/12-AOS1070 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
A Spectral Algorithm for Latent Dirichlet Allocation
Jan 17, 2013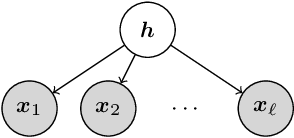
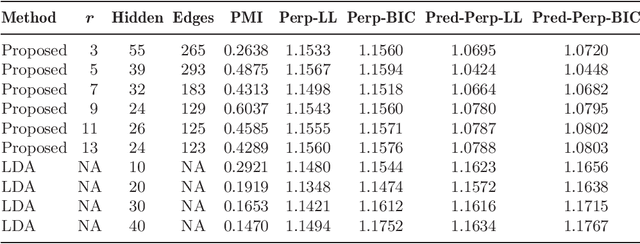
The problem of topic modeling can be seen as a generalization of the clustering problem, in that it posits that observations are generated due to multiple latent factors (e.g., the words in each document are generated as a mixture of several active topics, as opposed to just one). This increased representational power comes at the cost of a more challenging unsupervised learning problem of estimating the topic probability vectors (the distributions over words for each topic), when only the words are observed and the corresponding topics are hidden. We provide a simple and efficient learning procedure that is guaranteed to recover the parameters for a wide class of mixture models, including the popular latent Dirichlet allocation (LDA) model. For LDA, the procedure correctly recovers both the topic probability vectors and the prior over the topics, using only trigram statistics (i.e., third order moments, which may be estimated with documents containing just three words). The method, termed Excess Correlation Analysis (ECA), is based on a spectral decomposition of low order moments (third and fourth order) via two singular value decompositions (SVDs). Moreover, the algorithm is scalable since the SVD operations are carried out on $k\times k$ matrices, where $k$ is the number of latent factors (e.g. the number of topics), rather than in the $d$-dimensional observed space (typically $d \gg k$).
A Method of Moments for Mixture Models and Hidden Markov Models
Sep 05, 2012
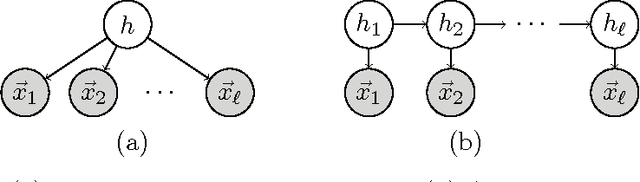

Mixture models are a fundamental tool in applied statistics and machine learning for treating data taken from multiple subpopulations. The current practice for estimating the parameters of such models relies on local search heuristics (e.g., the EM algorithm) which are prone to failure, and existing consistent methods are unfavorable due to their high computational and sample complexity which typically scale exponentially with the number of mixture components. This work develops an efficient method of moments approach to parameter estimation for a broad class of high-dimensional mixture models with many components, including multi-view mixtures of Gaussians (such as mixtures of axis-aligned Gaussians) and hidden Markov models. The new method leads to rigorous unsupervised learning results for mixture models that were not achieved by previous works; and, because of its simplicity, it offers a viable alternative to EM for practical deployment.
High-dimensional structure estimation in Ising models: Local separation criterion
Aug 20, 2012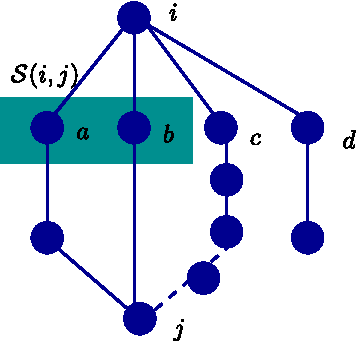
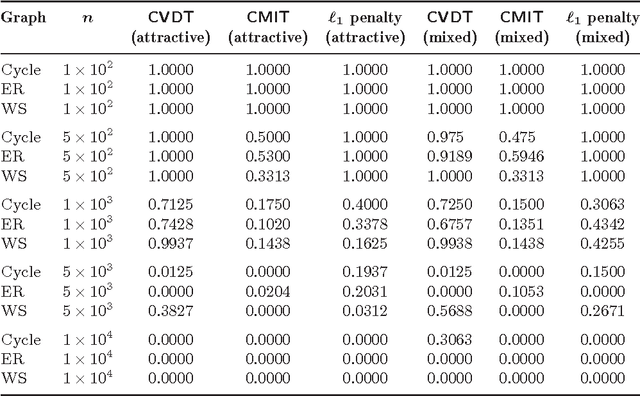
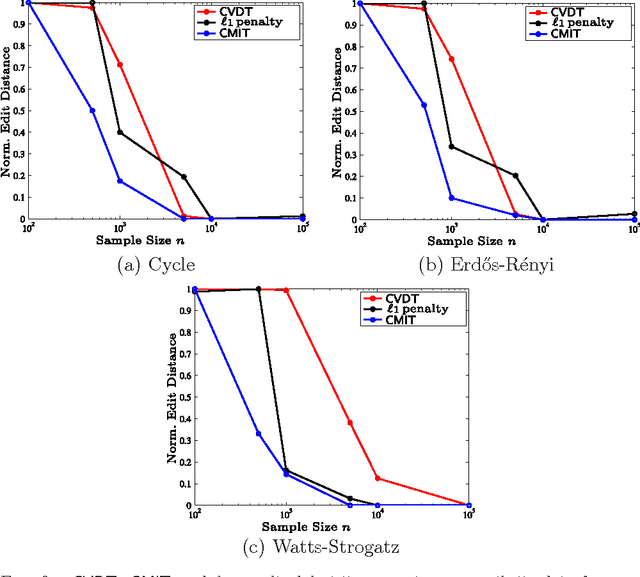
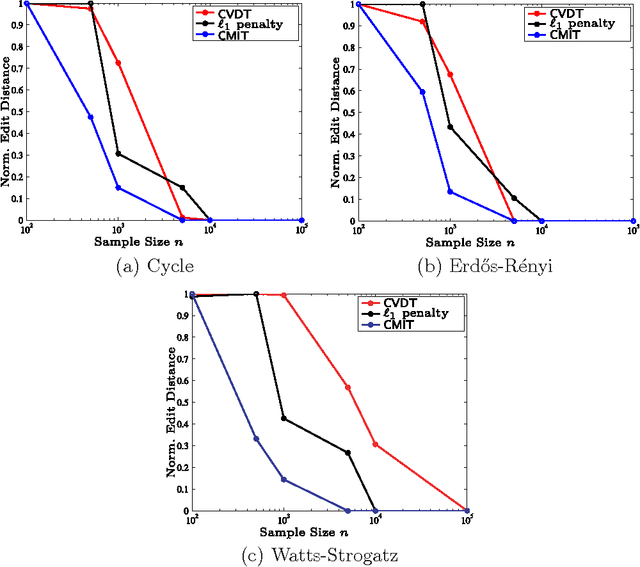
We consider the problem of high-dimensional Ising (graphical) model selection. We propose a simple algorithm for structure estimation based on the thresholding of the empirical conditional variation distances. We introduce a novel criterion for tractable graph families, where this method is efficient, based on the presence of sparse local separators between node pairs in the underlying graph. For such graphs, the proposed algorithm has a sample complexity of $n=\Omega(J_{\min}^{-2}\log p)$, where $p$ is the number of variables, and $J_{\min}$ is the minimum (absolute) edge potential in the model. We also establish nonasymptotic necessary and sufficient conditions for structure estimation.
* Published in at http://dx.doi.org/10.1214/12-AOS1009 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)