Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clustering Approach to Learn Sparsely-Used Overcomplete Dictionaries
Paper and Code
Jul 07, 2014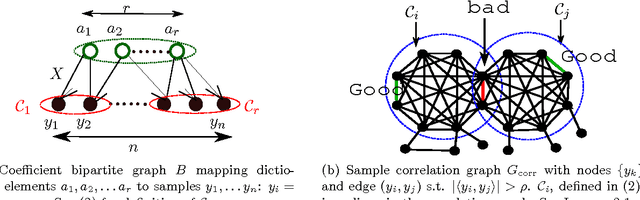
We consider the problem of learning overcomplete dictionaries in the context of sparse coding, where each sample selects a sparse subset of dictionary elements. Our main result is a strategy to approximately recover the unknown dictionary using an efficient algorithm. Our algorithm is a clustering-style procedure, where each cluster is used to estimate a dictionary element. The resulting solution can often be further cleaned up to obtain a high accuracy estimate, and we provide one simple scenario where $\ell_1$-regularized regression can be used for such a second stage.
* Part of this work appears in COLT 2014
View paper on