 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Approaches for Extending Neural Architectures to Function Spaces for Operator Learning
Jun 12, 2025A wide range of scientific problems, such as those described by continuous-time dynamical systems and partial differential equations (PDEs), are naturally formulated on function spaces. While function spaces are typically infinite-dimensional, deep learning has predominantly advanced through applications in computer vision and natural language processing that focus on mappings between finite-dimensional spaces. Such fundamental disparities in the nature of the data have limited neural networks from achieving a comparable level of success in scientific applications as seen in other fields. Neural operators are a principled way to generalize neural networks to mappings between function spaces, offering a pathway to replicate deep learning's transformative impact on scientific problems. For instance, neural operators can learn solution operators for entire classes of PDEs, e.g., physical systems with different boundary conditions, coefficient functions, and geometries. A key factor in deep learning's success has been the careful engineering of neural architectures through extensive empirical testing. Translating these neural architectures into neural operators allows operator learning to enjoy these same empirical optimizations. However, prior neural operator architectures have often been introduced as standalone models, not directly derived as extensions of existing neural network architectures. In this paper, we identify and distill the key principles for constructing practical implementations of mappings between infinite-dimensional function spaces. Using these principles, we propose a recipe for converting several popular neural architectures into neural operators with minimal modifications. This paper aims to guide practitioners through this process and details the steps to make neural operators work in practice. Our code can be found at https://github.com/neuraloperator/NNs-to-NOs
NOBLE -- Neural Operator with Biologically-informed Latent Embeddings to Capture Experimental Variability in Biological Neuron Models
Jun 05, 2025Characterizing the diverse computational properties of human neurons via multimodal electrophysiological, transcriptomic, and morphological data provides the foundation for constructing and validating bio-realistic neuron models that can advance our understanding of fundamental mechanisms underlying brain function. However, current modeling approaches remain constrained by the limited availability and intrinsic variability of experimental neuronal data. To capture variability, ensembles of deterministic models are often used, but are difficult to scale as model generation requires repeating computationally expensive optimization for each neuron. While deep learning is becoming increasingly relevant in this space, it fails to capture the full biophysical complexity of neurons, their nonlinear voltage dynamics, and variability. To address these shortcomings, we introduce NOBLE, a neural operator framework that learns a mapping from a continuous frequency-modulated embedding of interpretable neuron features to the somatic voltage response induced by current injection. Trained on data generated from biophysically realistic neuron models, NOBLE predicts distributions of neural dynamics accounting for the intrinsic experimental variability. Unlike conventional bio-realistic neuron models, interpolating within the embedding space offers models whose dynamics are consistent with experimentally observed responses. NOBLE is the first scaled-up deep learning framework validated on real experimental data, enabling efficient generation of synthetic neurons that exhibit trial-to-trial variability and achieve a $4200\times$ speedup over numerical solvers. To this end, NOBLE captures fundamental neural properties, opening the door to a better understanding of cellular composition and computations, neuromorphic architectures, large-scale brain circuits, and general neuroAI applications.
R-KV: Redundancy-aware KV Cache Compression for Training-Free Reasoning Models Acceleration
May 30, 2025Reasoning models have demonstrated impressive performance in self-reflection and chain-of-thought reasoning. However, they often produce excessively long outputs, leading to prohibitively large key-value (KV) caches during inference. While chain-of-thought inference significantly improves performance on complex reasoning tasks, it can also lead to reasoning failures when deployed with existing KV cache compression approaches. To address this, we propose Redundancy-aware KV Cache Compression for Reasoning models (R-KV), a novel method specifically targeting redundant tokens in reasoning models. Our method preserves nearly 100% of the full KV cache performance using only 10% of the KV cache, substantially outperforming existing KV cache baselines, which reach only 60% of the performance. Remarkably, R-KV even achieves 105% of full KV cache performance with 16% of the KV cache. This KV-cache reduction also leads to a 90% memory saving and a 6.6X throughput over standard chain-of-thought reasoning inference. Experimental results show that R-KV consistently outperforms existing KV cache compression baselines across two mathematical reasoning datasets.
EquiReg: Equivariance Regularized Diffusion for Inverse Problems
May 29, 2025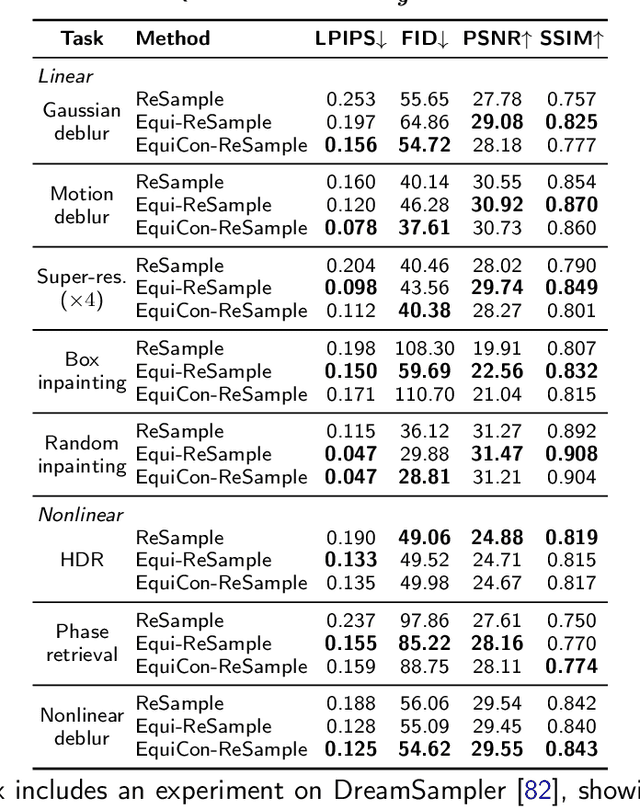
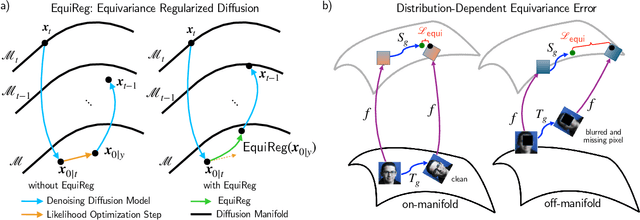
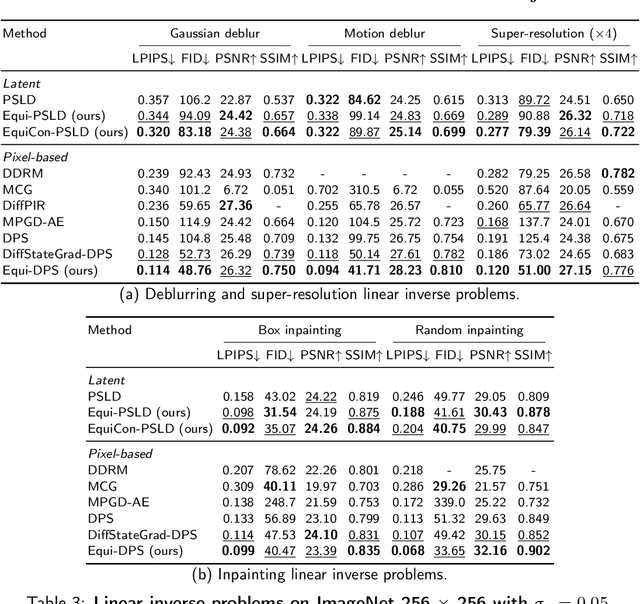
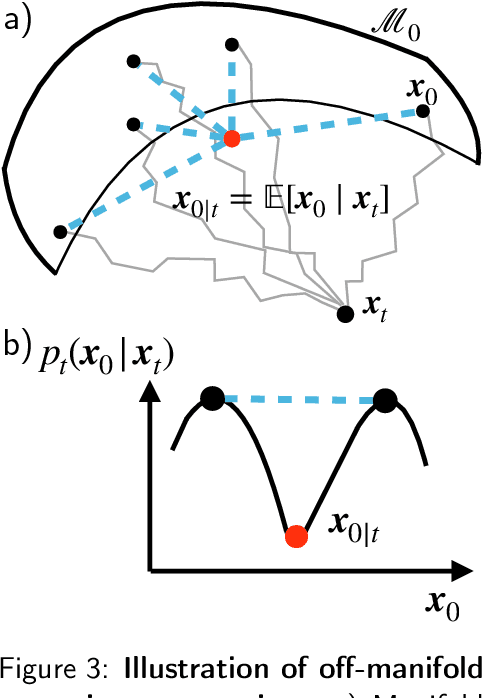
Diffusion models represent the state-of-the-art for solving inverse problems such as image restoration tasks. In the Bayesian framework, diffusion-based inverse solvers incorporate a likelihood term to guide the prior sampling process, generating data consistent with the posterior distribution. However, due to the intractability of the likelihood term, many current methods rely on isotropic Gaussian approximations, which lead to deviations from the data manifold and result in inconsistent, unstable reconstructions. We propose Equivariance Regularized (EquiReg) diffusion, a general framework for regularizing posterior sampling in diffusion-based inverse problem solvers. EquiReg enhances reconstructions by reweighting diffusion trajectories and penalizing those that deviate from the data manifold. We define a new distribution-dependent equivariance error, empirically identify functions that exhibit low error for on-manifold samples and higher error for off-manifold samples, and leverage these functions to regularize the diffusion sampling process. When applied to a variety of solvers, EquiReg outperforms state-of-the-art diffusion models in both linear and nonlinear image restoration tasks, as well as in reconstructing partial differential equations.
Guided Diffusion Sampling on Function Spaces with Applications to PDEs
May 22, 2025We propose a general framework for conditional sampling in PDE-based inverse problems, targeting the recovery of whole solutions from extremely sparse or noisy measurements. This is accomplished by a function-space diffusion model and plug-and-play guidance for conditioning. Our method first trains an unconditional discretization-agnostic denoising model using neural operator architectures. At inference, we refine the samples to satisfy sparse observation data via a gradient-based guidance mechanism. Through rigorous mathematical analysis, we extend Tweedie's formula to infinite-dimensional Hilbert spaces, providing the theoretical foundation for our posterior sampling approach. Our method (FunDPS) accurately captures posterior distributions in function spaces under minimal supervision and severe data scarcity. Across five PDE tasks with only 3% observation, our method achieves an average 32% accuracy improvement over state-of-the-art fixed-resolution diffusion baselines while reducing sampling steps by 4x. Furthermore, multi-resolution fine-tuning ensures strong cross-resolution generalizability. To the best of our knowledge, this is the first diffusion-based framework to operate independently of discretization, offering a practical and flexible solution for forward and inverse problems in the context of PDEs. Code is available at https://github.com/neuraloperator/FunDPS
HiPerRAG: High-Performance Retrieval Augmented Generation for Scientific Insights
May 07, 2025The volume of scientific literature is growing exponentially, leading to underutilized discoveries, duplicated efforts, and limited cross-disciplinary collaboration. Retrieval Augmented Generation (RAG) offers a way to assist scientists by improving the factuality of Large Language Models (LLMs) in processing this influx of information. However, scaling RAG to handle millions of articles introduces significant challenges, including the high computational costs associated with parsing documents and embedding scientific knowledge, as well as the algorithmic complexity of aligning these representations with the nuanced semantics of scientific content. To address these issues, we introduce HiPerRAG, a RAG workflow powered by high performance computing (HPC) to index and retrieve knowledge from more than 3.6 million scientific articles. At its core are Oreo, a high-throughput model for multimodal document parsing, and ColTrast, a query-aware encoder fine-tuning algorithm that enhances retrieval accuracy by using contrastive learning and late-interaction techniques. HiPerRAG delivers robust performance on existing scientific question answering benchmarks and two new benchmarks introduced in this work, achieving 90% accuracy on SciQ and 76% on PubMedQA-outperforming both domain-specific models like PubMedGPT and commercial LLMs such as GPT-4. Scaling to thousands of GPUs on the Polaris, Sunspot, and Frontier supercomputers, HiPerRAG delivers million document-scale RAG workflows for unifying scientific knowledge and fostering interdisciplinary innovation.
MOM: Memory-Efficient Offloaded Mini-Sequence Inference for Long Context Language Models
Apr 16, 2025Long-context language models exhibit impressive performance but remain challenging to deploy due to high GPU memory demands during inference. We propose Memory-efficient Offloaded Mini-sequence Inference (MOM), a method that partitions critical layers into smaller "mini-sequences" and integrates seamlessly with KV cache offloading. Experiments on various Llama, Qwen, and Mistral models demonstrate that MOM reduces peak memory usage by over 50\% on average. On Meta-Llama-3.2-8B, MOM extends the maximum context length from 155k to 455k tokens on a single A100 80GB GPU, while keeping outputs identical and not compromising accuracy. MOM also maintains highly competitive throughput due to minimal computational overhead and efficient last-layer processing. Compared to traditional chunked prefill methods, MOM achieves a 35\% greater context length extension. More importantly, our method drastically reduces prefill memory consumption, eliminating it as the longstanding dominant memory bottleneck during inference. This breakthrough fundamentally changes research priorities, redirecting future efforts from prefill-stage optimizations to improving decode-stage residual KV cache efficiency.
Enabling Automatic Differentiation with Mollified Graph Neural Operators
Apr 11, 2025Physics-informed neural operators offer a powerful framework for learning solution operators of partial differential equations (PDEs) by combining data and physics losses. However, these physics losses rely on derivatives. Computing these derivatives remains challenging, with spectral and finite difference methods introducing approximation errors due to finite resolution. Here, we propose the mollified graph neural operator (mGNO), the first method to leverage automatic differentiation and compute \emph{exact} gradients on arbitrary geometries. This enhancement enables efficient training on irregular grids and varying geometries while allowing seamless evaluation of physics losses at randomly sampled points for improved generalization. For a PDE example on regular grids, mGNO paired with autograd reduced the L2 relative data error by 20x compared to finite differences, although training was slower. It can also solve PDEs on unstructured point clouds seamlessly, using physics losses only, at resolutions vastly lower than those needed for finite differences to be accurate enough. On these unstructured point clouds, mGNO leads to errors that are consistently 2 orders of magnitude lower than machine learning baselines (Meta-PDE) for comparable runtimes, and also delivers speedups from 1 to 3 orders of magnitude compared to the numerical solver for similar accuracy. mGNOs can also be used to solve inverse design and shape optimization problems on complex geometries.
Fourier Neural Operator based surrogates for $CO_2$ storage in realistic geologies
Mar 14, 2025



This study aims to develop surrogate models for accelerating decision making processes associated with carbon capture and storage (CCS) technologies. Selection of sub-surface $CO_2$ storage sites often necessitates expensive and involved simulations of $CO_2$ flow fields. Here, we develop a Fourier Neural Operator (FNO) based model for real-time, high-resolution simulation of $CO_2$ plume migration. The model is trained on a comprehensive dataset generated from realistic subsurface parameters and offers $O(10^5)$ computational acceleration with minimal sacrifice in prediction accuracy. We also explore super-resolution experiments to improve the computational cost of training the FNO based models. Additionally, we present various strategies for improving the reliability of predictions from the model, which is crucial while assessing actual geological sites. This novel framework, based on NVIDIA's Modulus library, will allow rapid screening of sites for CCS. The discussed workflows and strategies can be applied to other energy solutions like geothermal reservoir modeling and hydrogen storage. Our work scales scientific machine learning models to realistic 3D systems that are more consistent with real-life subsurface aquifers/reservoirs, paving the way for next-generation digital twins for subsurface CCS applications.
LeanProgress: Guiding Search for Neural Theorem Proving via Proof Progress Prediction
Feb 25, 2025Mathematical reasoning remains a significant challenge for Large Language Models (LLMs) due to hallucinations. When combined with formal proof assistants like Lean, these hallucinations can be eliminated through rigorous verification, making theorem proving reliable. However, even with formal verification, LLMs still struggle with long proofs and complex mathematical formalizations. While Lean with LLMs offers valuable assistance with retrieving lemmas, generating tactics, or even complete proofs, it lacks a crucial capability: providing a sense of proof progress. This limitation particularly impacts the overall development efficiency in large formalization projects. We introduce LeanProgress, a method that predicts the progress in the proof. Training and evaluating our models made on a large corpus of Lean proofs from Lean Workbook Plus and Mathlib4 and how many steps remain to complete it, we employ data preprocessing and balancing techniques to handle the skewed distribution of proof lengths. Our experiments show that LeanProgress achieves an overall prediction accuracy of 75.1\% in predicting the amount of progress and, hence, the remaining number of steps. When integrated into a best-first search framework using Reprover, our method shows a 3.8\% improvement on Mathlib4 compared to baseline performances of 41.2\%, particularly for longer proofs. These results demonstrate how proof progress prediction can enhance both automated and interactive theorem proving, enabling users to make more informed decisions about proof strategies.