 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Ray: Mechanical Search for an Occluded Object by Minimizing Support of Learned Occupancy Distributions
Apr 20, 2020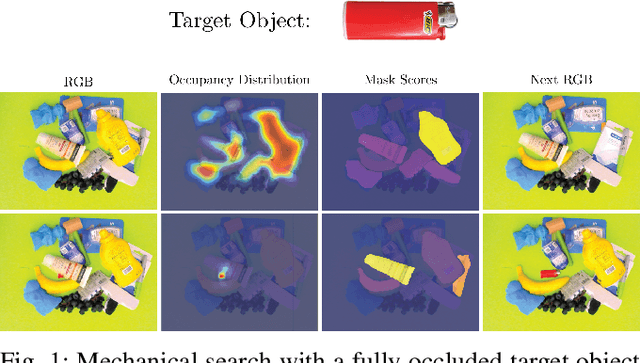
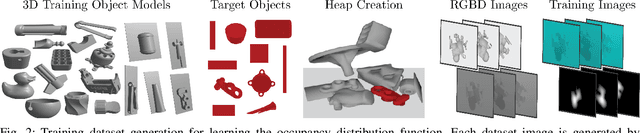
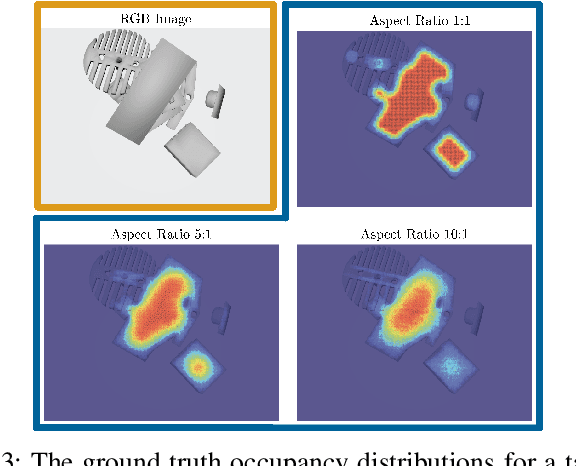
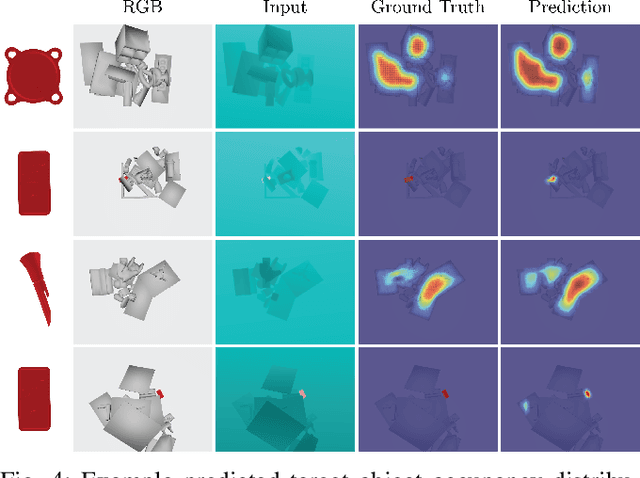
For applications in e-commerce, warehouses, healthcare, and home service, robots are often required to search through heaps of objects to grasp a specific target object. For mechanical search, we introduce X-Ray, an algorithm based on learned occupancy distributions. We train a neural network using a synthetic dataset of RGBD heap images labeled for a set of standard bounding box targets with varying aspect ratios. X-Ray minimizes support of the learned distribution as part of a mechanical search policy in both simulated and real environments. We benchmark these policies against two baseline policies on 1,000 heaps of 15 objects in simulation where the target object is partially or fully occluded. Results suggest that X-Ray is significantly more efficient, as it succeeds in extracting the target object 82% of the time, 15% more often than the best-performing baseline. Experiments on an ABB YuMi robot with 20 heaps of 25 household objects suggest that the learned policy transfers easily to a physical system, where it outperforms baseline policies by 15% in success rate with 17% fewer actions. Datasets, videos, and experiments are available at http://sites.google.com/berkeley.edu/x-ray .
Improving Semantic Segmentation through Spatio-Temporal Consistency Learned from Videos
Apr 11, 2020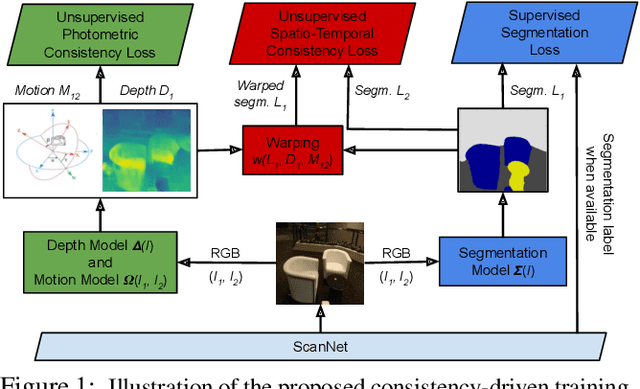

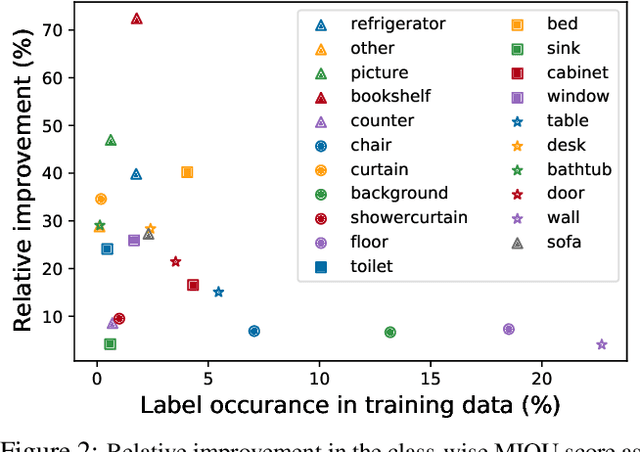
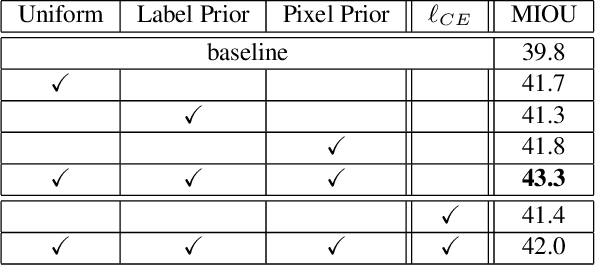
We leverage unsupervised learning of depth, egomotion, and camera intrinsics to improve the performance of single-image semantic segmentation, by enforcing 3D-geometric and temporal consistency of segmentation masks across video frames. The predicted depth, egomotion, and camera intrinsics are used to provide an additional supervision signal to the segmentation model, significantly enhancing its quality, or, alternatively, reducing the number of labels the segmentation model needs. Our experiments were performed on the ScanNet dataset.
Evolving Losses for Unsupervised Video Representation Learning
Feb 26, 2020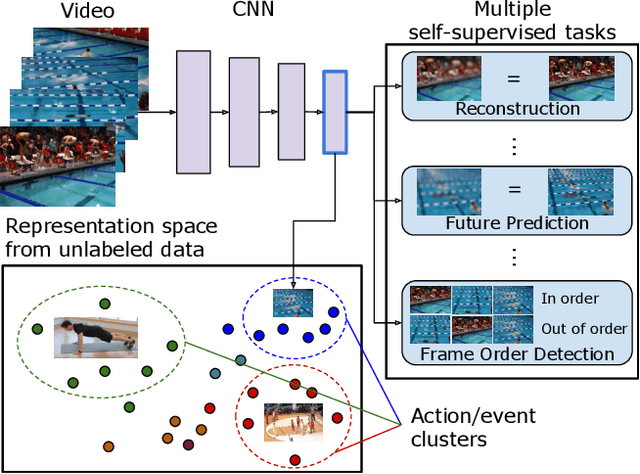
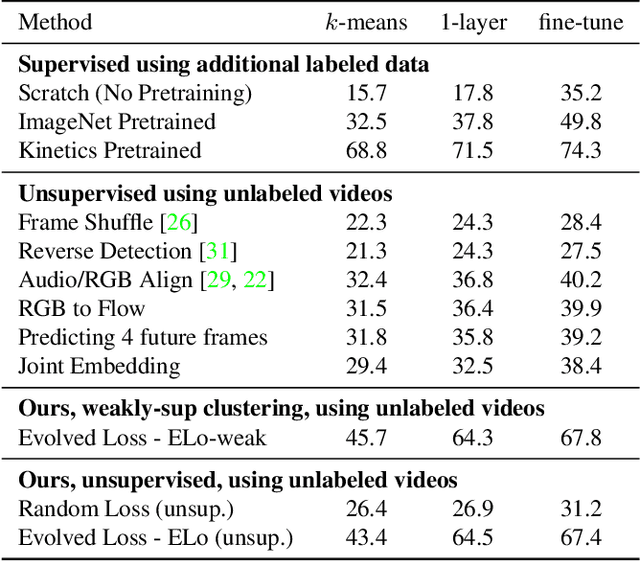
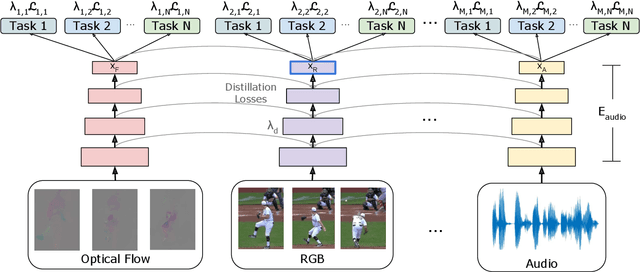
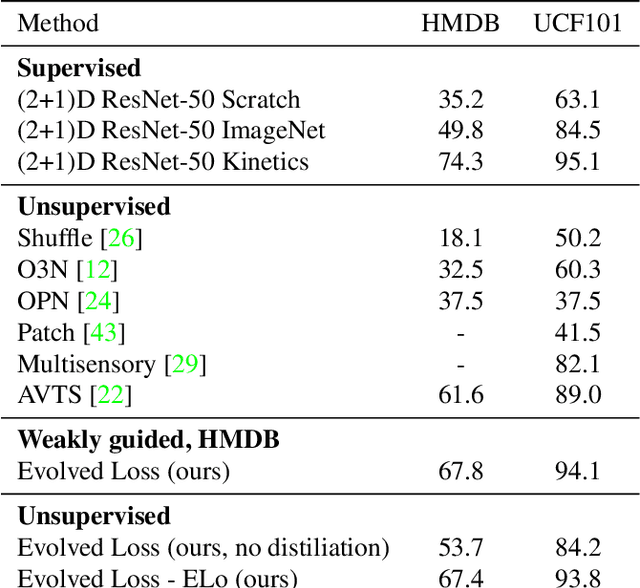
We present a new method to learn video representations from large-scale unlabeled video data. Ideally, this representation will be generic and transferable, directly usable for new tasks such as action recognition and zero or few-shot learning. We formulate unsupervised representation learning as a multi-modal, multi-task learning problem, where the representations are shared across different modalities via distillation. Further, we introduce the concept of loss function evolution by using an evolutionary search algorithm to automatically find optimal combination of loss functions capturing many (self-supervised) tasks and modalities. Thirdly, we propose an unsupervised representation evaluation metric using distribution matching to a large unlabeled dataset as a prior constraint, based on Zipf's law. This unsupervised constraint, which is not guided by any labeling, produces similar results to weakly-supervised, task-specific ones. The proposed unsupervised representation learning results in a single RGB network and outperforms previous methods. Notably, it is also more effective than several label-based methods (e.g., ImageNet), with the exception of large, fully labeled video datasets.
* arXiv admin note: text overlap with arXiv:1906.03248
SPIN: A High Speed, High Resolution Vision Dataset for Tracking and Action Recognition in Ping Pong
Dec 13, 2019
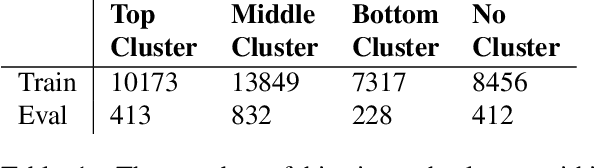
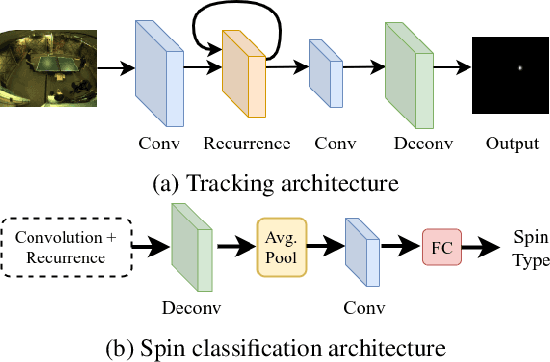
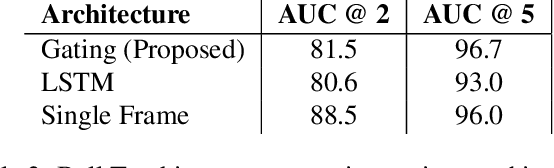
We introduce a new high resolution, high frame rate stereo video dataset, which we call SPIN, for tracking and action recognition in the game of ping pong. The corpus consists of ping pong play with three main annotation streams that can be used to learn tracking and action recognition models -- tracking of the ping pong ball and poses of humans in the videos and the spin of the ball being hit by humans. The training corpus consists of 53 hours of data with labels derived from previous models in a semi-supervised method. The testing corpus contains 1 hour of data with the same information, except that crowd compute was used to obtain human annotations of the ball position, from which ball spin has been derived. Along with the dataset we introduce several baseline models that were trained on this data. The models were specifically chosen to be able to perform inference at the same rate as the images are generated -- specifically 150 fps. We explore the advantages of multi-task training on this data, and also show interesting properties of ping pong ball trajectories that are derived from our observational data, rather than from prior physics models. To our knowledge this is the first large scale dataset of ping pong; we offer it to the community as a rich dataset that can be used for a large variety of machine learning and vision tasks such as tracking, pose estimation, semi-supervised and unsupervised learning and generative modeling.
KeyPose: Multi-view 3D Labeling and Keypoint Estimation for Transparent Objects
Dec 05, 2019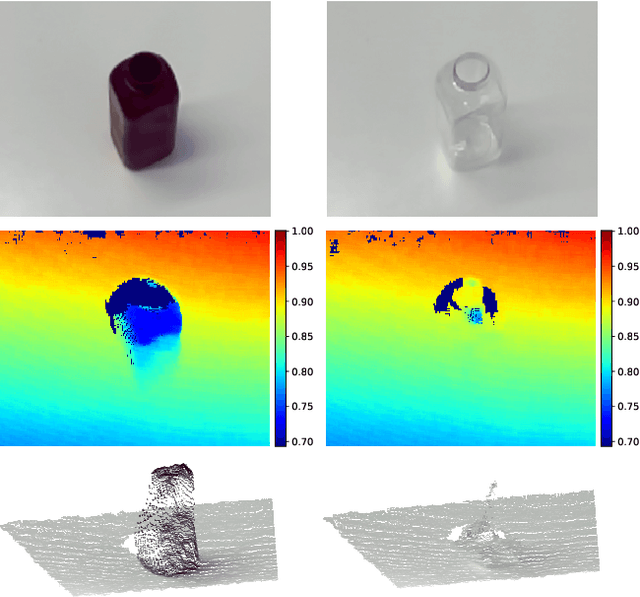

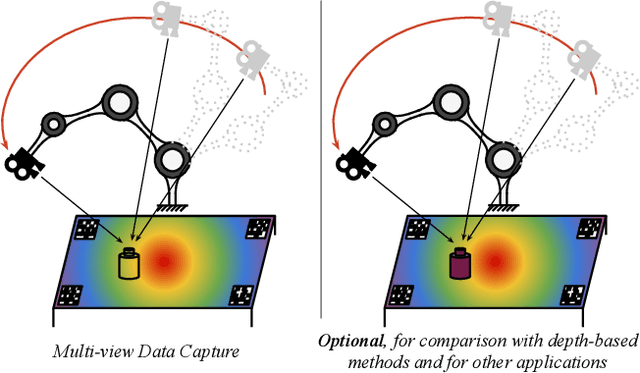
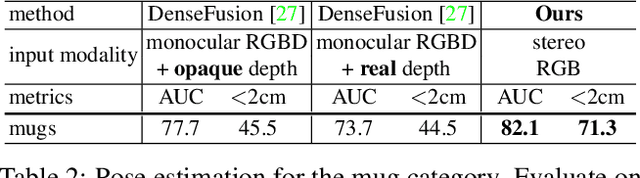
Estimating the 3D pose of desktop objects is crucial for applications such as robotic manipulation. Finding the depth of the object is an important part of this task, both for training and prediction, and is usually accomplished with a depth sensor or markers in a motion-capture system. For transparent or highly reflective objects, such methods are not feasible without impinging on the resultant image of the object. Hence, many existing methods restrict themselves to opaque, lambertian objects that give good returns from RGBD sensors. In this paper we address two problems: first, establish an easy method for capturing and labeling 3D keypoints on desktop objects with a stereo sensor (no special depth sensor required); and second, develop a deep method, called $KeyPose$, that learns to accurately predict 3D keypoints on objects, including challenging ones such as transparent objects. To showcase the performance of the method, we create and employ a dataset of 15 clear objects in 5 classes, with 48k 3D-keypoint labeled images. We train both instance and category models, and show generalization to new textures, poses, and objects. KeyPose surpasses state-of-the-art performance in 3D pose estimation on this dataset, sometimes by a wide margin, and even in cases where the competing method is provided with registered depth. We will release a public version of the data capture and labeling pipeline, the transparent object database, and the KeyPose training and evaluation code.
Tiny Video Networks
Oct 15, 2019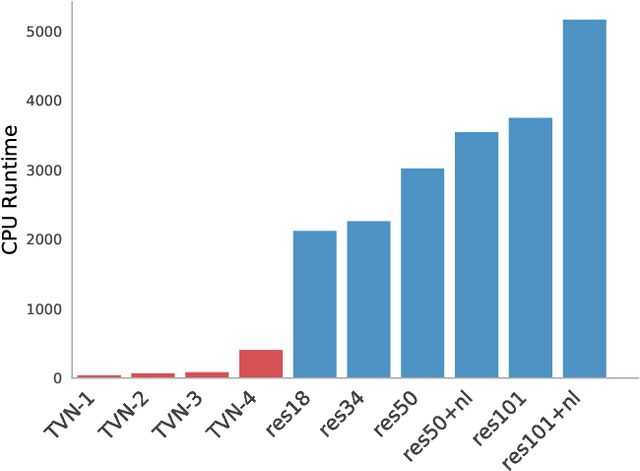
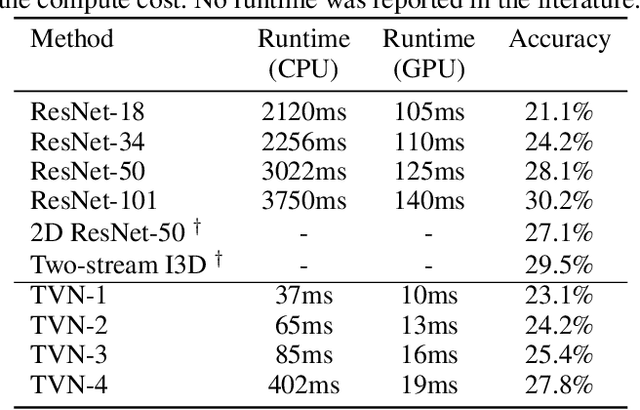
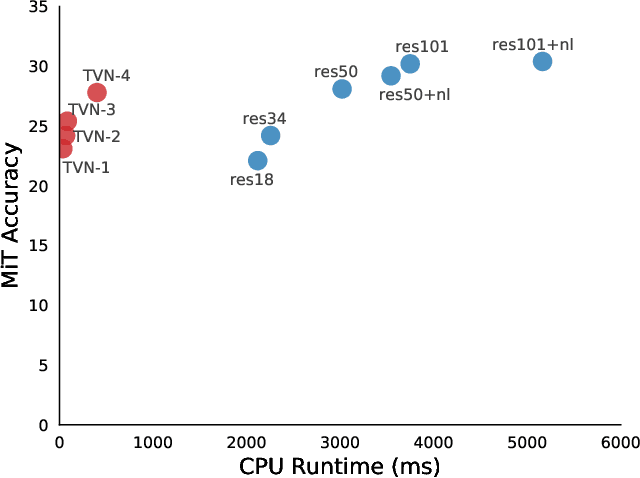

Video understanding is a challenging problem with great impact on the abilities of autonomous agents working in the real-world. Yet, solutions so far have been computationally intensive, with the fastest algorithms running for more than half a second per video snippet on powerful GPUs. We propose a novel idea on video architecture learning - Tiny Video Networks - which automatically designs highly efficient models for video understanding. The tiny video models run with competitive performance for as low as 37 milliseconds per video on a CPU and 10 milliseconds on a standard GPU.
Unsupervised Monocular Depth and Ego-motion Learning with Structure and Semantics
Jun 12, 2019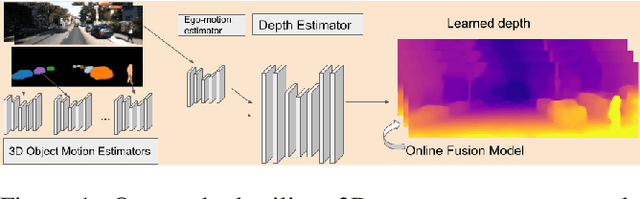
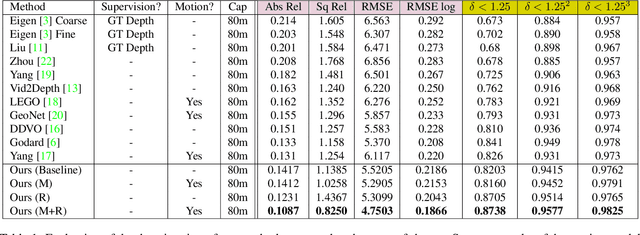

We present an approach which takes advantage of both structure and semantics for unsupervised monocular learning of depth and ego-motion. More specifically, we model the motion of individual objects and learn their 3D motion vector jointly with depth and ego-motion. We obtain more accurate results, especially for challenging dynamic scenes not addressed by previous approaches. This is an extended version of Casser et al. [AAAI'19]. Code and models have been open sourced at https://sites.google.com/corp/view/struct2depth.
Evolving Losses for Unlabeled Video Representation Learning
Jun 07, 2019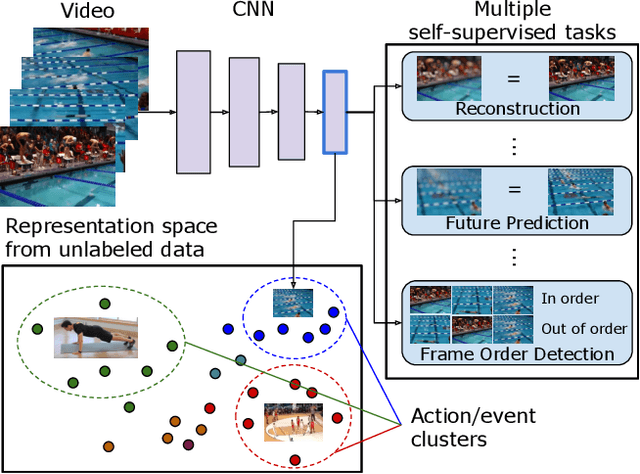
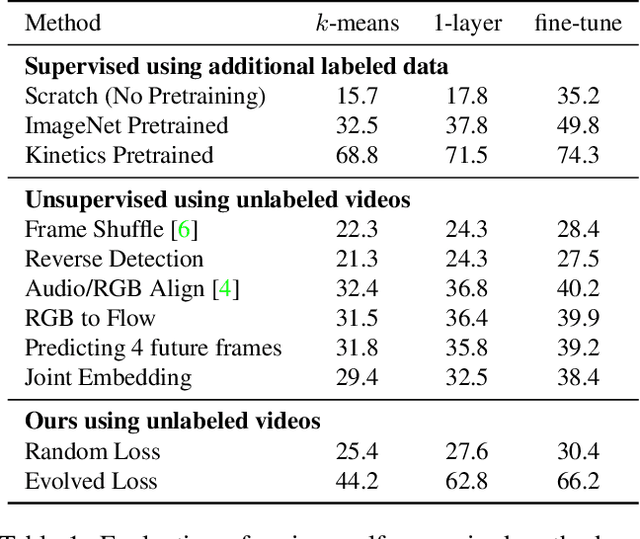
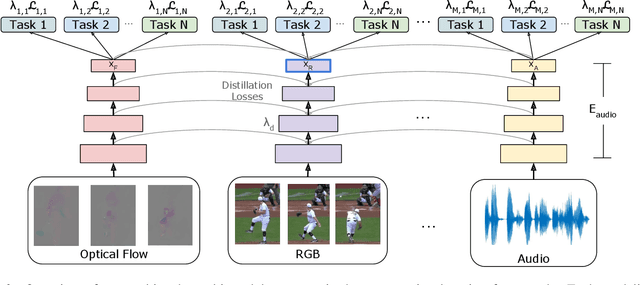
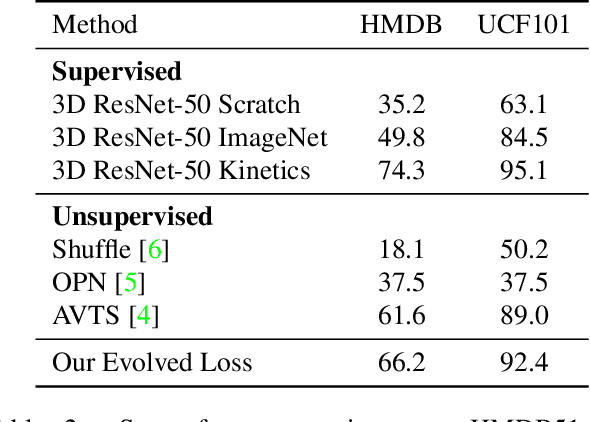
We present a new method to learn video representations from unlabeled data. Given large-scale unlabeled video data, the objective is to benefit from such data by learning a generic and transferable representation space that can be directly used for a new task such as zero/few-shot learning. We formulate our unsupervised representation learning as a multi-modal, multi-task learning problem, where the representations are also shared across different modalities via distillation. Further, we also introduce the concept of finding a better loss function to train such multi-task multi-modal representation space using an evolutionary algorithm; our method automatically searches over different combinations of loss functions capturing multiple (self-supervised) tasks and modalities. Our formulation allows for the distillation of audio, optical flow and temporal information into a single, RGB-based convolutional neural network. We also compare the effects of using additional unlabeled video data and evaluate our representation learning on standard public video datasets.
AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures
May 30, 2019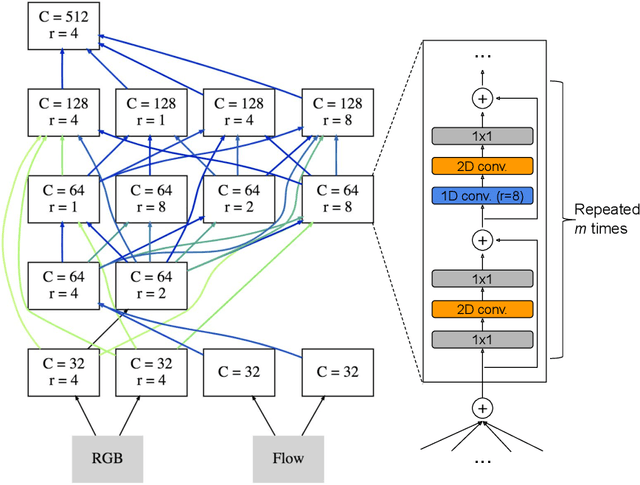
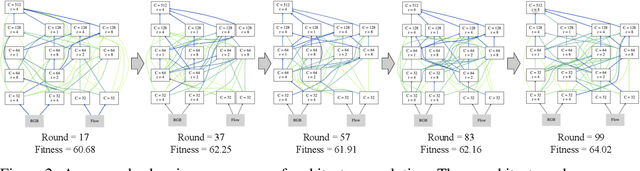
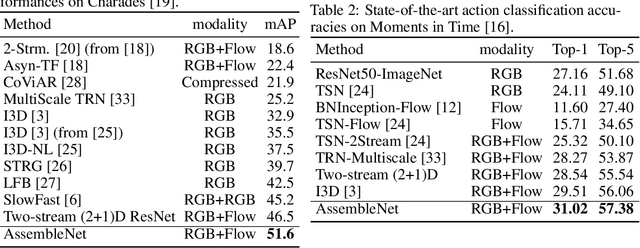
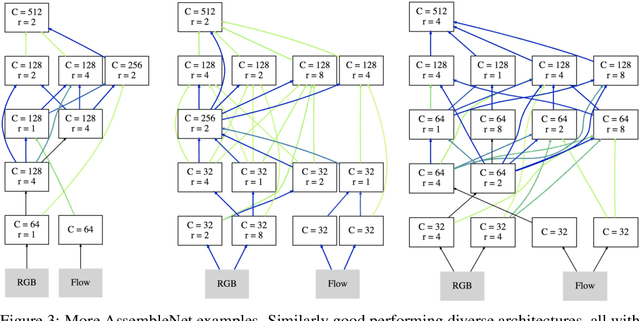
Learning to represent videos is a very challenging task both algorithmically and computationally. Standard video CNN architectures have been designed by directly extending architectures devised for image understanding to a third dimension (using a limited number of space-time modules such as 3D convolutions) or by introducing a handcrafted two-stream design to capture both appearance and motion in videos. We interpret a video CNN as a collection of multi-stream space-time convolutional blocks connected to each other, and propose the approach of automatically finding neural architectures with better connectivity for video understanding. This is done by evolving a population of overly-connected architectures guided by connection weight learning. Architectures combining representations that abstract different input types (i.e., RGB and optical flow) at multiple temporal resolutions are searched for, allowing different types or sources of information to interact with each other. Our method, referred to as AssembleNet, outperforms prior approaches on public video datasets, in some cases by a great margin.
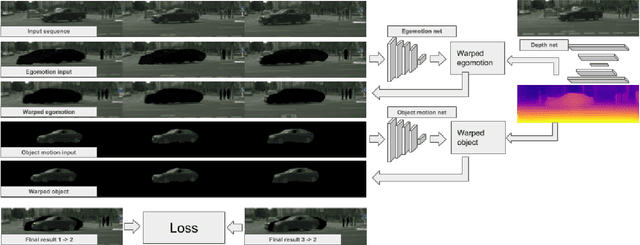
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras
Apr 10, 2019
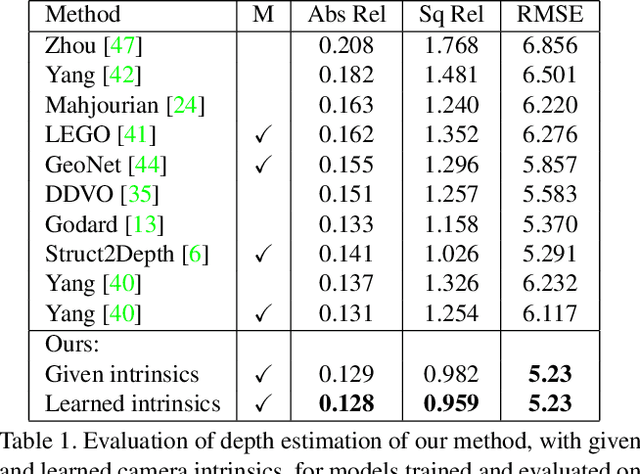
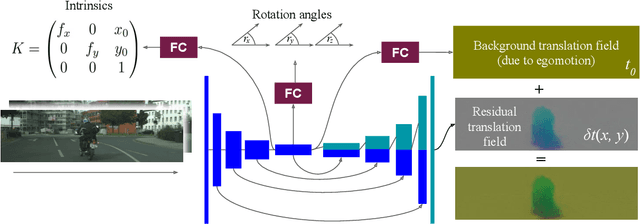
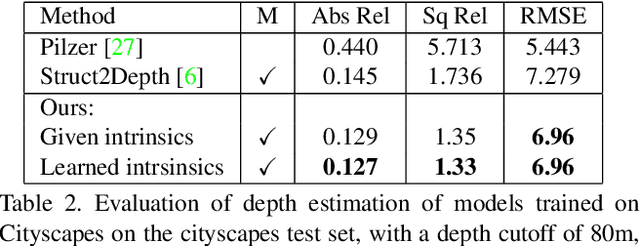
We present a novel method for simultaneous learning of depth, egomotion, object motion, and camera intrinsics from monocular videos, using only consistency across neighboring video frames as supervision signal. Similarly to prior work, our method learns by applying differentiable warping to frames and comparing the result to adjacent ones, but it provides several improvements: We address occlusions geometrically and differentiably, directly using the depth maps as predicted during training. We introduce randomized layer normalization, a novel powerful regularizer, and we account for object motion relative to the scene. To the best of our knowledge, our work is the first to learn the camera intrinsic parameters, including lens distortion, from video in an unsupervised manner, thereby allowing us to extract accurate depth and motion from arbitrary videos of unknown origin at scale. We evaluate our results on the Cityscapes, KITTI and EuRoC datasets, establishing new state of the art on depth prediction and odometry, and demonstrate qualitatively that depth prediction can be learned from a collection of YouTube videos.