 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Transformers For Spinal Cancer Detection and Radiological Grading
Jun 27, 2022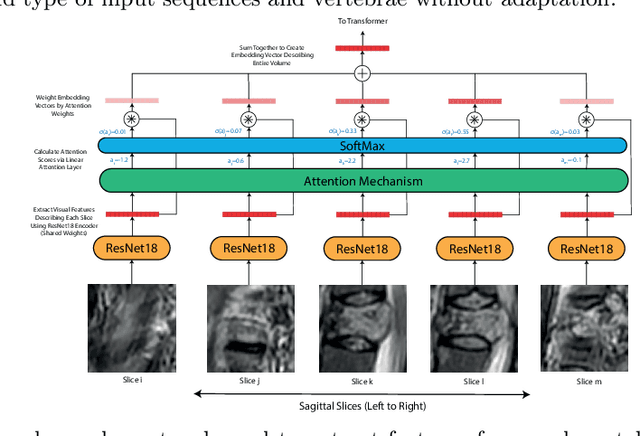

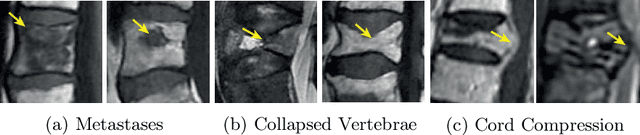
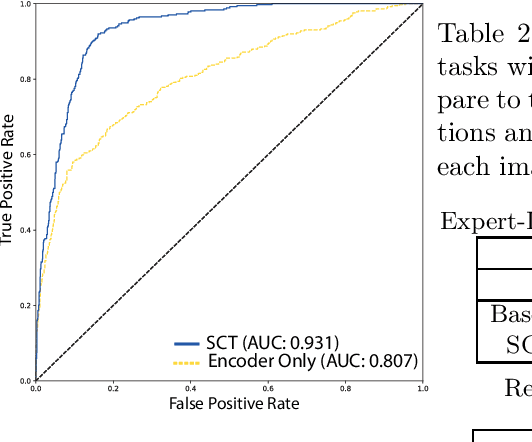
This paper proposes a novel transformer-based model architecture for medical imaging problems involving analysis of vertebrae. It considers two applications of such models in MR images: (a) detection of spinal metastases and the related conditions of vertebral fractures and metastatic cord compression, (b) radiological grading of common degenerative changes in intervertebral discs. Our contributions are as follows: (i) We propose a Spinal Context Transformer (SCT), a deep-learning architecture suited for the analysis of repeated anatomical structures in medical imaging such as vertebral bodies (VBs). Unlike previous related methods, SCT considers all VBs as viewed in all available image modalities together, making predictions for each based on context from the rest of the spinal column and all available imaging modalities. (ii) We apply the architecture to a novel and important task: detecting spinal metastases and the related conditions of cord compression and vertebral fractures/collapse from multi-series spinal MR scans. This is done using annotations extracted from free-text radiological reports as opposed to bespoke annotation. However, the resulting model shows strong agreement with vertebral-level bespoke radiologist annotations on the test set. (iii) We also apply SCT to an existing problem: radiological grading of inter-vertebral discs (IVDs) in lumbar MR scans for common degenerative changes.We show that by considering the context of vertebral bodies in the image, SCT improves the accuracy for several gradings compared to previously published model.
A CLIP-Hitchhiker's Guide to Long Video Retrieval
May 17, 2022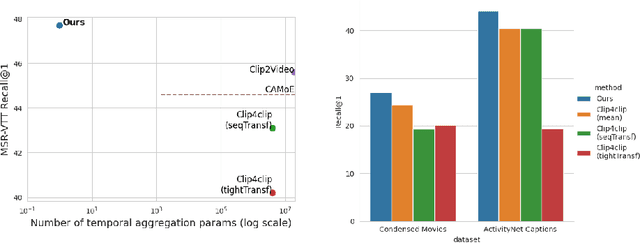

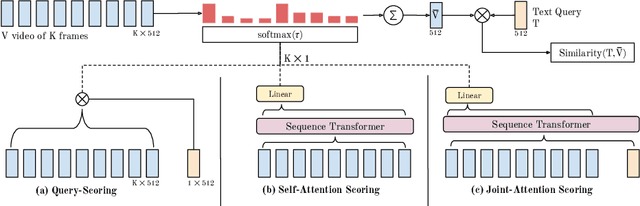
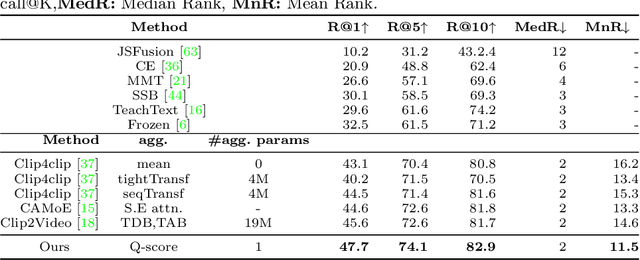
Our goal in this paper is the adaptation of image-text models for long video retrieval. Recent works have demonstrated state-of-the-art performance in video retrieval by adopting CLIP, effectively hitchhiking on the image-text representation for video tasks. However, there has been limited success in learning temporal aggregation that outperform mean-pooling the image-level representations extracted per frame by CLIP. We find that the simple yet effective baseline of weighted-mean of frame embeddings via query-scoring is a significant improvement above all prior temporal modelling attempts and mean-pooling. In doing so, we provide an improved baseline for others to compare to and demonstrate state-of-the-art performance of this simple baseline on a suite of long video retrieval benchmarks.
Scaling up sign spotting through sign language dictionaries
May 09, 2022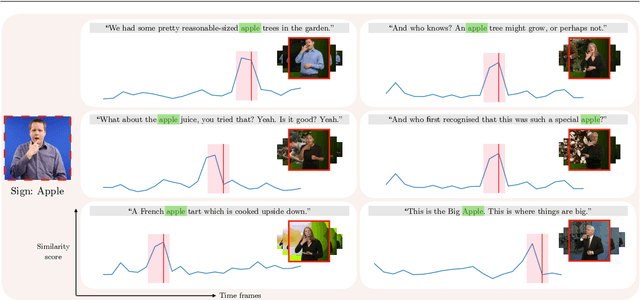
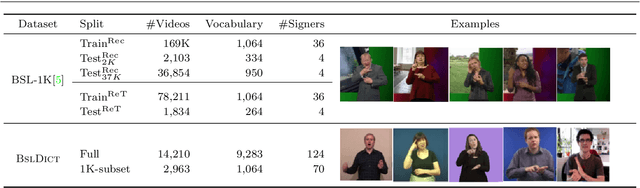
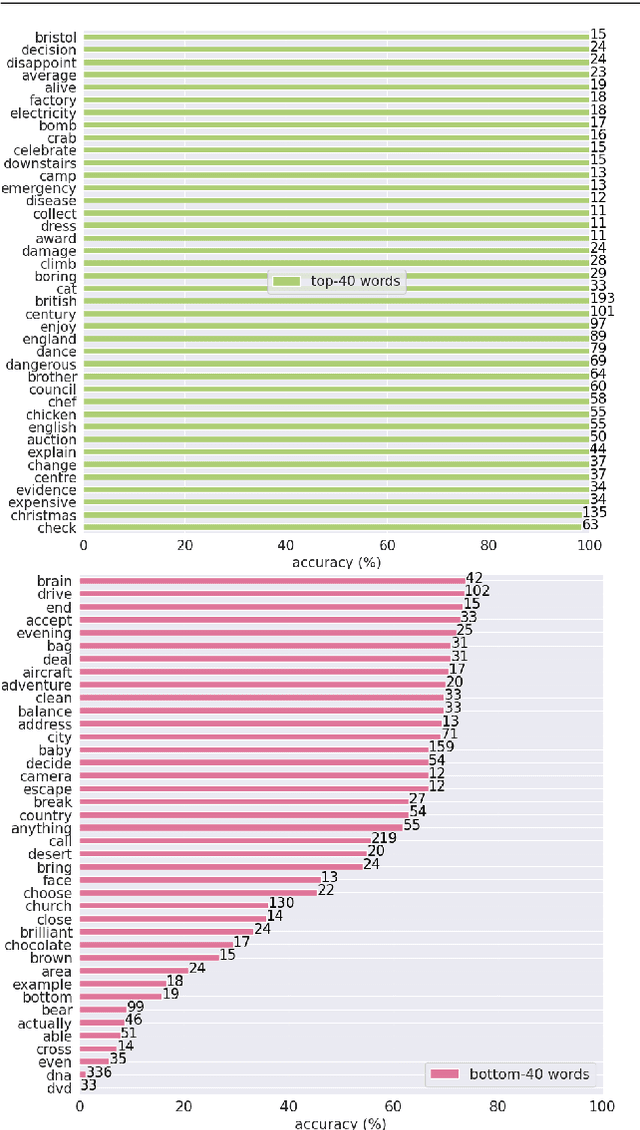
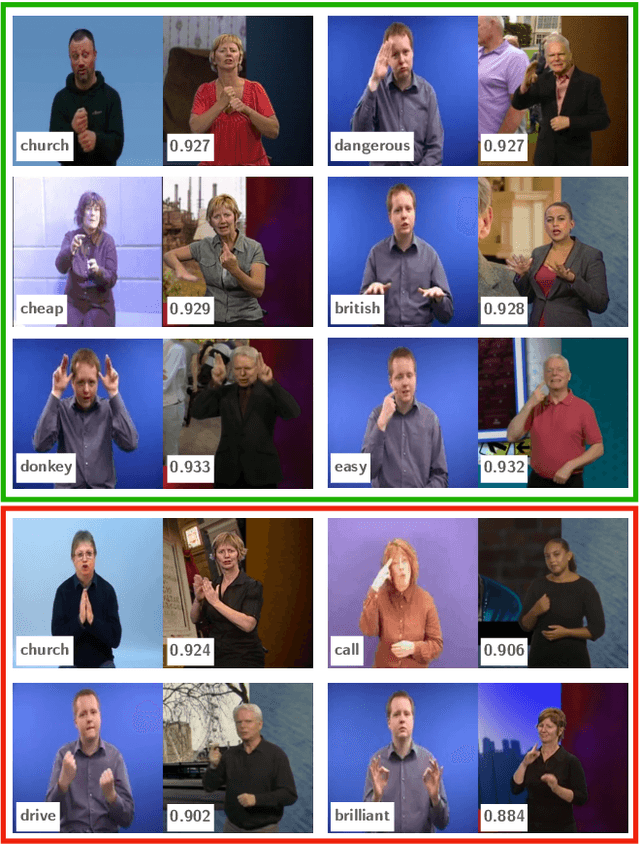
The focus of this work is $\textit{sign spotting}$ - given a video of an isolated sign, our task is to identify $\textit{whether}$ and $\textit{where}$ it has been signed in a continuous, co-articulated sign language video. To achieve this sign spotting task, we train a model using multiple types of available supervision by: (1) $\textit{watching}$ existing footage which is sparsely labelled using mouthing cues; (2) $\textit{reading}$ associated subtitles (readily available translations of the signed content) which provide additional $\textit{weak-supervision}$; (3) $\textit{looking up}$ words (for which no co-articulated labelled examples are available) in visual sign language dictionaries to enable novel sign spotting. These three tasks are integrated into a unified learning framework using the principles of Noise Contrastive Estimation and Multiple Instance Learning. We validate the effectiveness of our approach on low-shot sign spotting benchmarks. In addition, we contribute a machine-readable British Sign Language (BSL) dictionary dataset of isolated signs, BSLDict, to facilitate study of this task. The dataset, models and code are available at our project page.
* Appears in: 2022 International Journal of Computer Vision (IJCV). 25 pages. arXiv admin note: substantial text overlap with arXiv:2010.04002
SpineNetV2: Automated Detection, Labelling and Radiological Grading Of Clinical MR Scans
May 03, 2022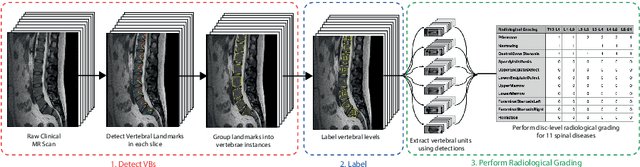
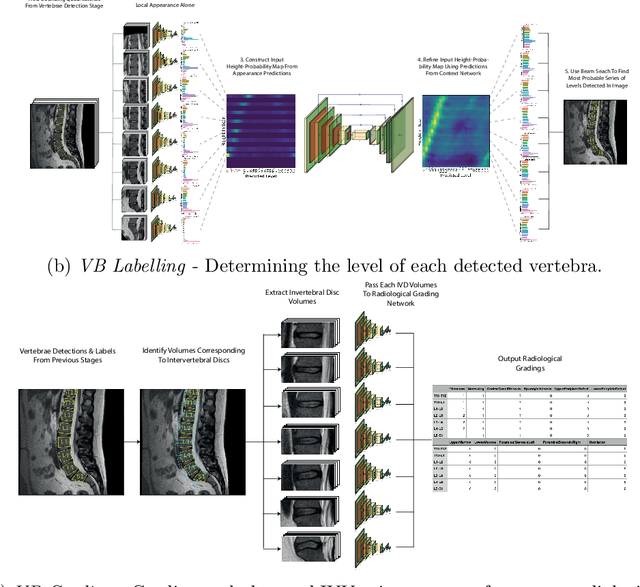
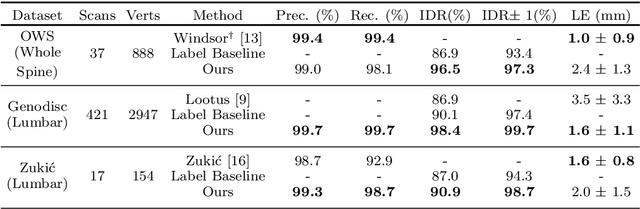
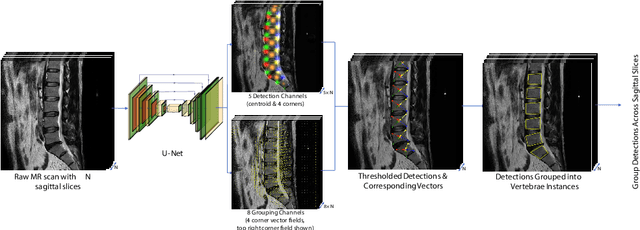
This technical report presents SpineNetV2, an automated tool which: (i) detects and labels vertebral bodies in clinical spinal magnetic resonance (MR) scans across a range of commonly used sequences; and (ii) performs radiological grading of lumbar intervertebral discs in T2-weighted scans for a range of common degenerative changes. SpineNetV2 improves over the original SpineNet software in two ways: (1) The vertebral body detection stage is significantly faster, more accurate and works across a range of fields-of-view (as opposed to just lumbar scans). (2) Radiological grading adopts a more powerful architecture, adding several new grading schemes without loss in performance. A demo of the software is available at the project website: http://zeus.robots.ox.ac.uk/spinenet2/.
Flamingo: a Visual Language Model for Few-Shot Learning
Apr 29, 2022
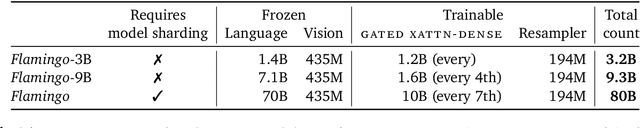
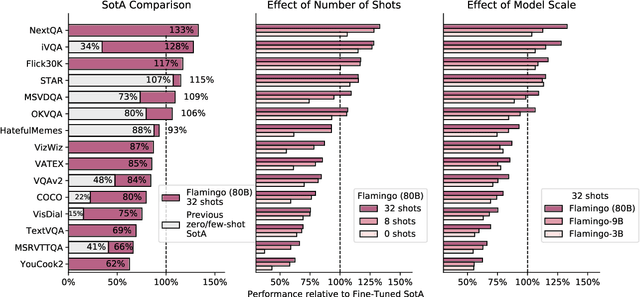
Building models that can be rapidly adapted to numerous tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. Flamingo models include key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities. We perform a thorough evaluation of the proposed Flamingo models, exploring and measuring their ability to rapidly adapt to a variety of image and video understanding benchmarks. These include open-ended tasks such as visual question-answering, where the model is prompted with a question which it has to answer, captioning tasks, which evaluate the ability to describe a scene or an event, and close-ended tasks such as multiple choice visual question-answering. For tasks lying anywhere on this spectrum, we demonstrate that a single Flamingo model can achieve a new state of the art for few-shot learning, simply by prompting the model with task-specific examples. On many of these benchmarks, Flamingo actually surpasses the performance of models that are fine-tuned on thousands of times more task-specific data.
Temporal Alignment Networks for Long-term Video
Apr 06, 2022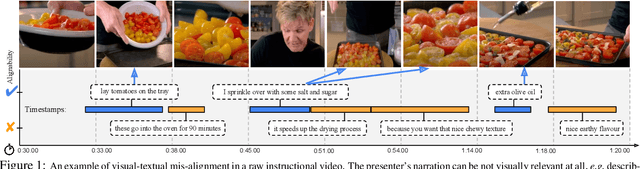
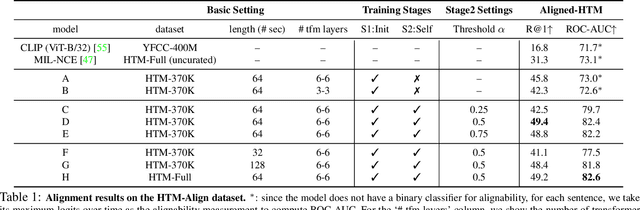
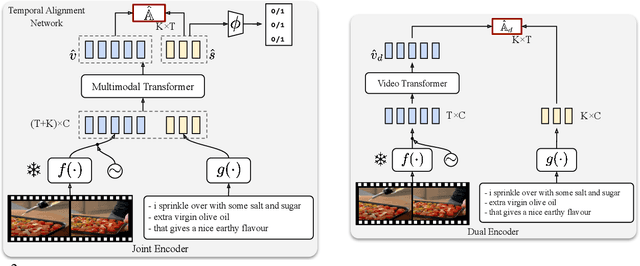
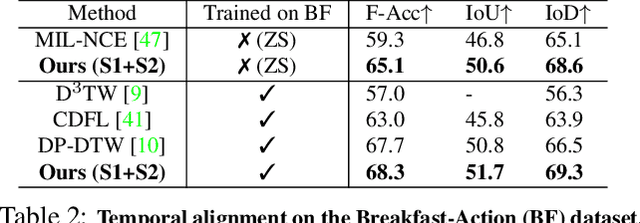
The objective of this paper is a temporal alignment network that ingests long term video sequences, and associated text sentences, in order to: (1) determine if a sentence is alignable with the video; and (2) if it is alignable, then determine its alignment. The challenge is to train such networks from large-scale datasets, such as HowTo100M, where the associated text sentences have significant noise, and are only weakly aligned when relevant. Apart from proposing the alignment network, we also make four contributions: (i) we describe a novel co-training method that enables to denoise and train on raw instructional videos without using manual annotation, despite the considerable noise; (ii) to benchmark the alignment performance, we manually curate a 10-hour subset of HowTo100M, totalling 80 videos, with sparse temporal descriptions. Our proposed model, trained on HowTo100M, outperforms strong baselines (CLIP, MIL-NCE) on this alignment dataset by a significant margin; (iii) we apply the trained model in the zero-shot settings to multiple downstream video understanding tasks and achieve state-of-the-art results, including text-video retrieval on YouCook2, and weakly supervised video action segmentation on Breakfast-Action; (iv) we use the automatically aligned HowTo100M annotations for end-to-end finetuning of the backbone model, and obtain improved performance on downstream action recognition tasks.
Object discovery and representation networks
Mar 16, 2022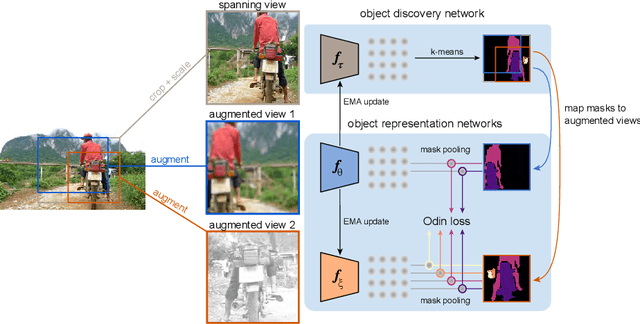
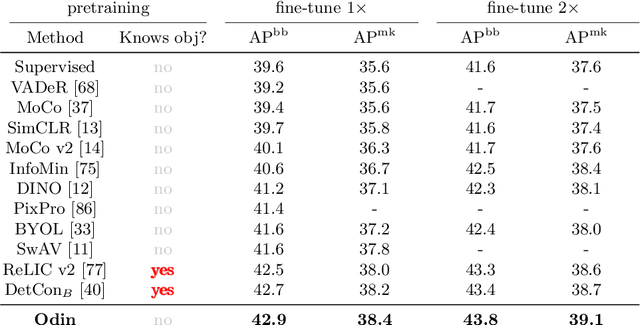
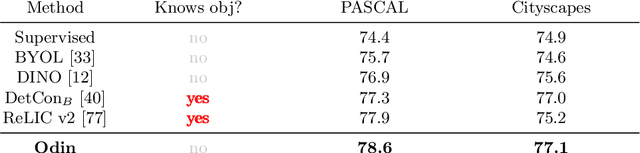

The promise of self-supervised learning (SSL) is to leverage large amounts of unlabeled data to solve complex tasks. While there has been excellent progress with simple, image-level learning, recent methods have shown the advantage of including knowledge of image structure. However, by introducing hand-crafted image segmentations to define regions of interest, or specialized augmentation strategies, these methods sacrifice the simplicity and generality that makes SSL so powerful. Instead, we propose a self-supervised learning paradigm that discovers the structure encoded in these priors by itself. Our method, Odin, couples object discovery and representation networks to discover meaningful image segmentations without any supervision. The resulting learning paradigm is simpler, less brittle, and more general, and achieves state-of-the-art transfer learning results for object detection and instance segmentation on COCO, and semantic segmentation on PASCAL and Cityscapes, while strongly surpassing supervised pre-training for video segmentation on DAVIS.
Hierarchical Perceiver
Feb 22, 2022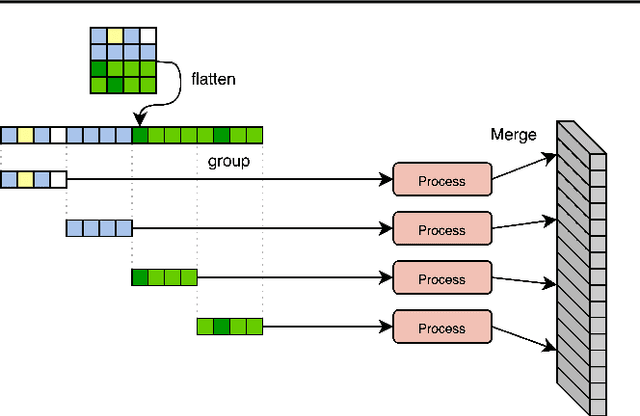

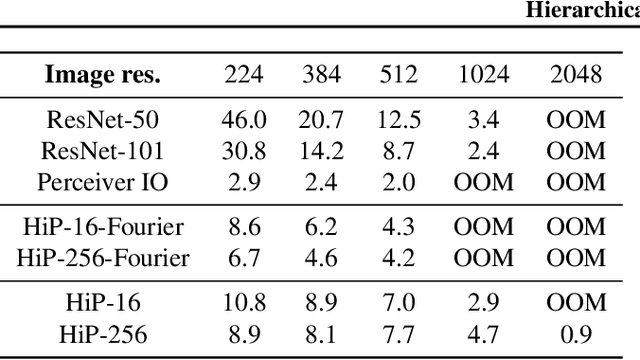

General perception systems such as Perceivers can process arbitrary modalities in any combination and are able to handle up to a few hundred thousand inputs. They achieve this generality by exclusively using global attention operations. This however hinders them from scaling up to the inputs sizes required to process raw high-resolution images or video. In this paper, we show that some degree of locality can be introduced back into these models, greatly improving their efficiency while preserving their generality. To scale them further, we introduce a self-supervised approach that enables learning dense low-dimensional positional embeddings for very large signals. We call the resulting model a Hierarchical Perceiver (HiP). HiP retains the ability to process arbitrary modalities, but now at higher-resolution and without any specialized preprocessing, improving over flat Perceivers in both efficiency and accuracy on the ImageNet, Audioset and PASCAL VOC datasets.
VoxSRC 2021: The Third VoxCeleb Speaker Recognition Challenge
Jan 12, 2022
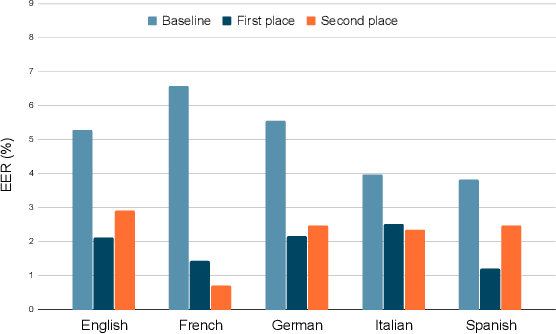
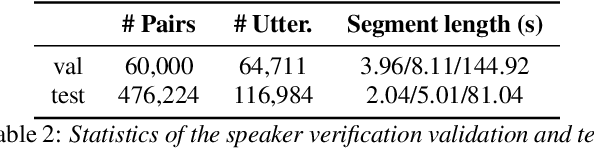
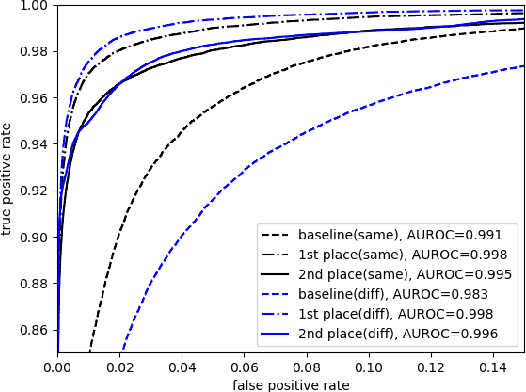
The third instalment of the VoxCeleb Speaker Recognition Challenge was held in conjunction with Interspeech 2021. The aim of this challenge was to assess how well current speaker recognition technology is able to diarise and recognise speakers in unconstrained or `in the wild' data. The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a virtual public challenge and workshop held at Interspeech 2021. This paper outlines the challenge, and describes the baselines, methods and results. We conclude with a discussion on the new multi-lingual focus of VoxSRC 2021, and on the progression of the challenge since the previous two editions.
Generalized Category Discovery
Jan 07, 2022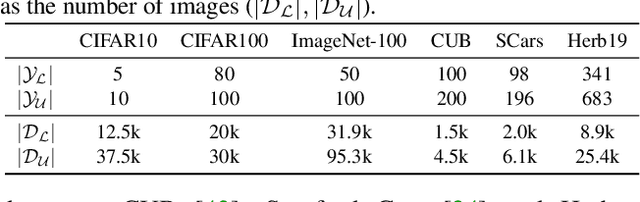
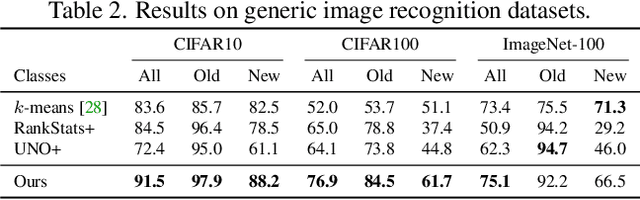

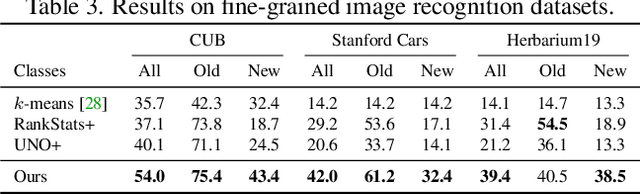
In this paper, we consider a highly general image recognition setting wherein, given a labelled and unlabelled set of images, the task is to categorize all images in the unlabelled set. Here, the unlabelled images may come from labelled classes or from novel ones. Existing recognition methods are not able to deal with this setting, because they make several restrictive assumptions, such as the unlabelled instances only coming from known - or unknown - classes and the number of unknown classes being known a-priori. We address the more unconstrained setting, naming it 'Generalized Category Discovery', and challenge all these assumptions. We first establish strong baselines by taking state-of-the-art algorithms from novel category discovery and adapting them for this task. Next, we propose the use of vision transformers with contrastive representation learning for this open world setting. We then introduce a simple yet effective semi-supervised $k$-means method to cluster the unlabelled data into seen and unseen classes automatically, substantially outperforming the baselines. Finally, we also propose a new approach to estimate the number of classes in the unlabelled data. We thoroughly evaluate our approach on public datasets for generic object classification including CIFAR10, CIFAR100 and ImageNet-100, and for fine-grained visual recognition including CUB, Stanford Cars and Herbarium19, benchmarking on this new setting to foster future research.