 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Open corpus of the Veps and Karelian languages: overview and applications
Jun 08, 2022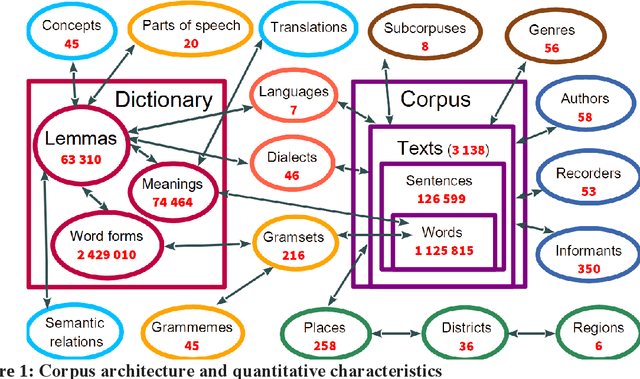
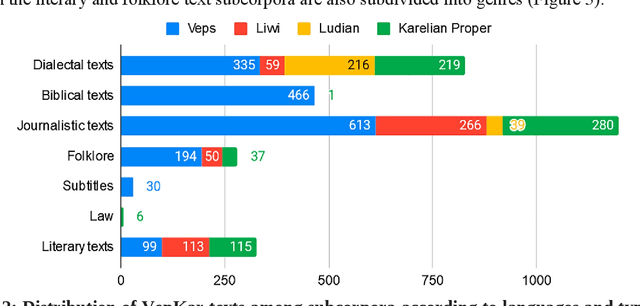
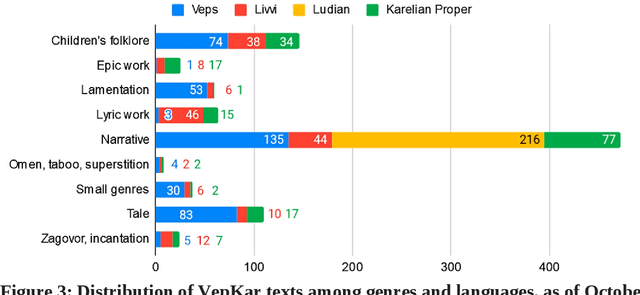
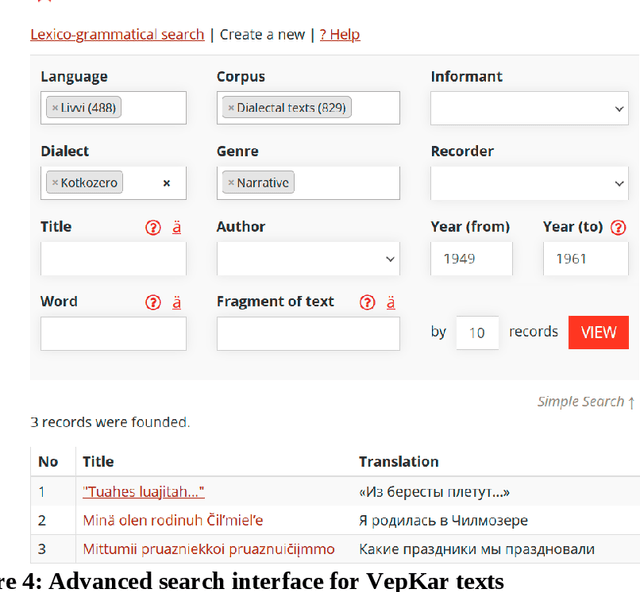
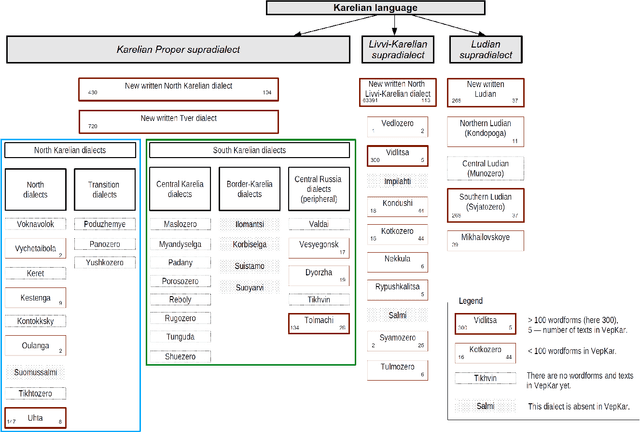
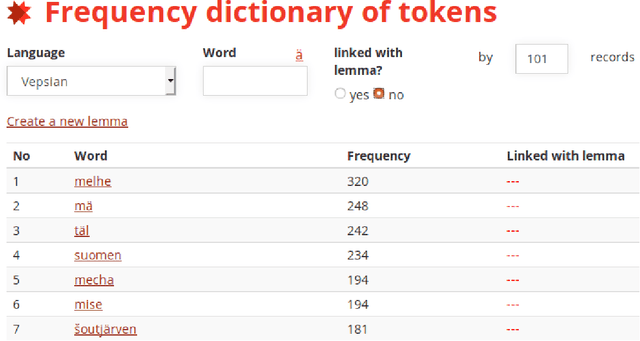
A growing priority in the study of Baltic-Finnic languages of the Republic of Karelia has been the methods and tools of corpus linguistics. Since 2016, linguists, mathematicians, and programmers at the Karelian Research Centre have been working with the Open Corpus of the Veps and Karelian Languages (VepKar), which is an extension of the Veps Corpus created in 2009. The VepKar corpus comprises texts in Karelian and Veps, multifunctional dictionaries linked to them, and software with an advanced system of search using various criteria of the texts (language, genre, etc.) and numerous linguistic categories (lexical and grammatical search in texts was implemented thanks to the generator of word forms that we created earlier). A corpus of 3000 texts was compiled, texts were uploaded and marked up, the system for classifying texts into languages, dialects, types and genres was introduced, and the word-form generator was created. Future plans include developing a speech module for working with audio recordings and a syntactic tagging module using morphological analysis outputs. Owing to continuous functional advancements in the corpus manager and ongoing VepKar enrichment with new material and text markup, users can handle a wide range of scientific and applied tasks. In creating the universal national VepKar corpus, its developers and managers strive to preserve and exhibit as fully as possible the state of the Veps and Karelian languages in the 19th-21st centuries.
* 9 pages, 9 figures, published in the journal
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Part of speech and gramset tagging algorithms for unknown words based on morphological dictionaries of the Veps and Karelian languages
Mar 22, 2021
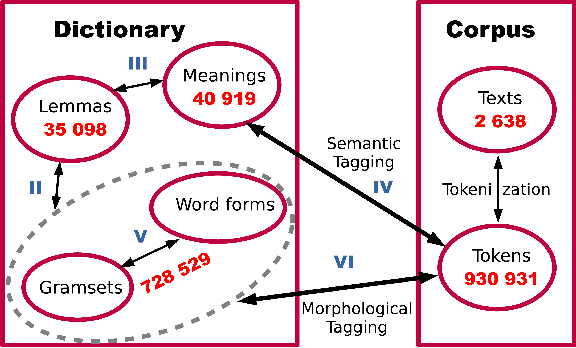

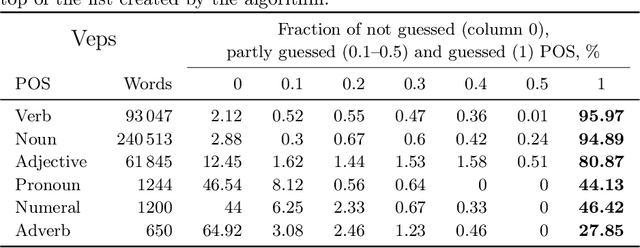
This research devoted to the low-resource Veps and Karelian languages. Algorithms for assigning part of speech tags to words and grammatical properties to words are presented in the article. These algorithms use our morphological dictionaries, where the lemma, part of speech and a set of grammatical features (gramset) are known for each word form. The algorithms are based on the analogy hypothesis that words with the same suffixes are likely to have the same inflectional models, the same part of speech and gramset. The accuracy of these algorithms were evaluated and compared. 313 thousand Vepsian and 66 thousand Karelian words were used to verify the accuracy of these algorithms. The special functions were designed to assess the quality of results of the developed algorithms. 92.4% of Vepsian words and 86.8% of Karelian words were assigned a correct part of speech by the developed algorithm. 95.3% of Vepsian words and 90.7% of Karelian words were assigned a correct gramset by our algorithm. Morphological and semantic tagging of texts, which are closely related and inseparable in our corpus processes, are described in the paper.
SIGMORPHON 2020 Shared Task 0: Typologically Diverse Morphological Inflection
Jul 14, 2020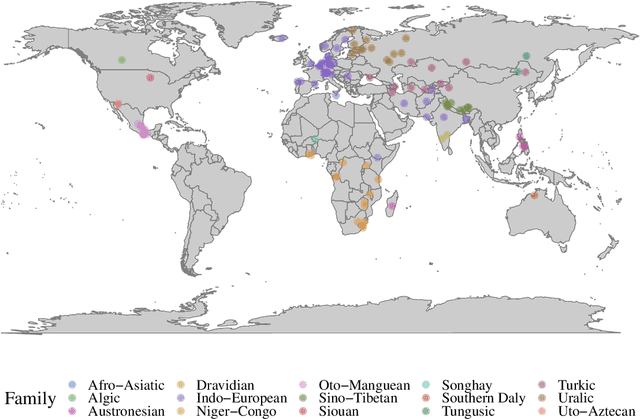
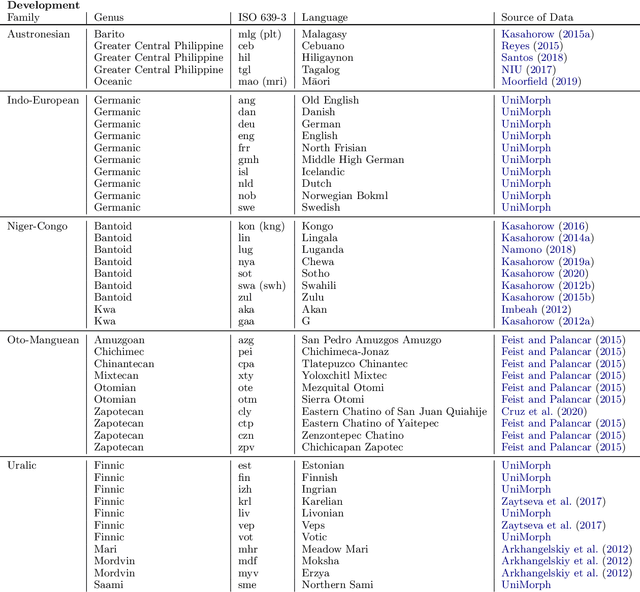
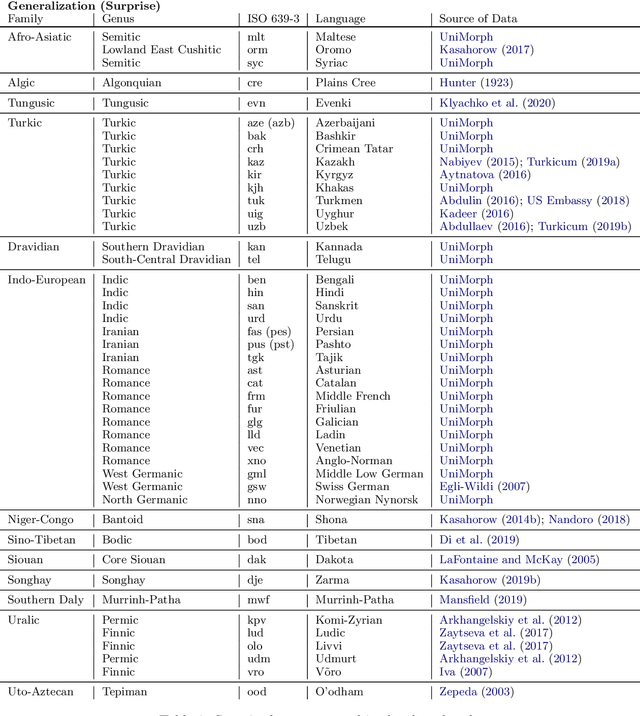
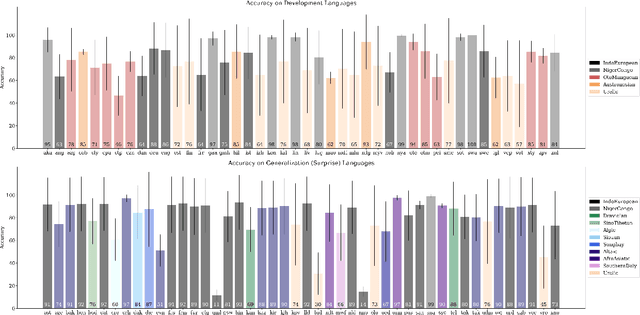
A broad goal in natural language processing (NLP) is to develop a system that has the capacity to process any natural language. Most systems, however, are developed using data from just one language such as English. The SIGMORPHON 2020 shared task on morphological reinflection aims to investigate systems' ability to generalize across typologically distinct languages, many of which are low resource. Systems were developed using data from 45 languages and just 5 language families, fine-tuned with data from an additional 45 languages and 10 language families (13 in total), and evaluated on all 90 languages. A total of 22 systems (19 neural) from 10 teams were submitted to the task. All four winning systems were neural (two monolingual transformers and two massively multilingual RNN-based models with gated attention). Most teams demonstrate utility of data hallucination and augmentation, ensembles, and multilingual training for low-resource languages. Non-neural learners and manually designed grammars showed competitive and even superior performance on some languages (such as Ingrian, Tajik, Tagalog, Zarma, Lingala), especially with very limited data. Some language families (Afro-Asiatic, Niger-Congo, Turkic) were relatively easy for most systems and achieved over 90% mean accuracy while others were more challenging.
LowResourceEval-2019: a shared task on morphological analysis for low-resource languages
Jan 30, 2020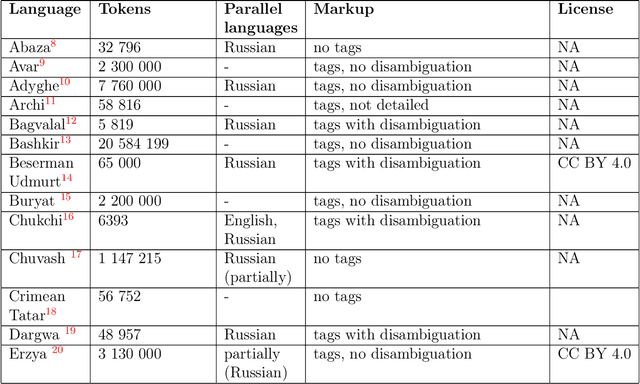
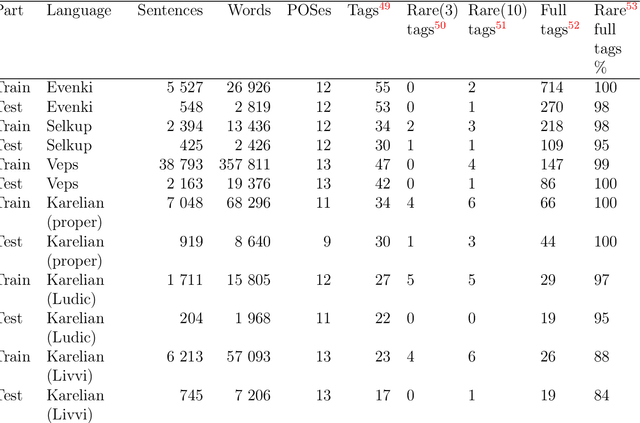
The paper describes the results of the first shared task on morphological analysis for the languages of Russia, namely, Evenki, Karelian, Selkup, and Veps. For the languages in question, only small-sized corpora are available. The tasks include morphological analysis, word form generation and morpheme segmentation. Four teams participated in the shared task. Most of them use machine-learning approaches, outperforming the existing rule-based ones. The article describes the datasets prepared for the shared tasks and contains analysis of the participants' solutions. Language corpora having different formats were transformed into CONLL-U format. The universal format makes the datasets comparable to other language corpura and facilitates using them in other NLP tasks.
* 16 pages, 4 tables, 2 figures, published in the conference proceeding
WSD algorithm based on a new method of vector-word contexts proximity calculation via epsilon-filtration
Jun 18, 2018
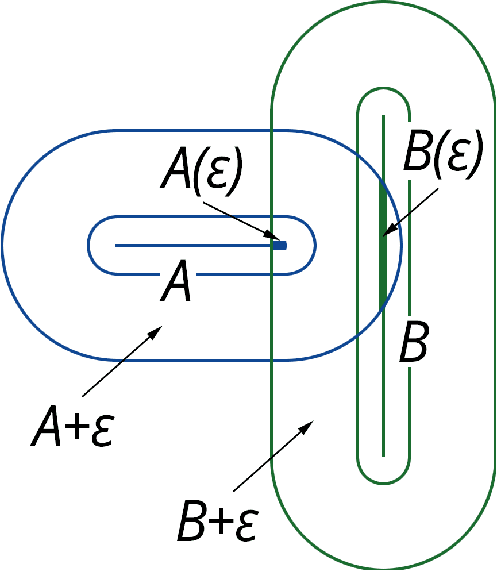

The problem of word sense disambiguation (WSD) is considered in the article. Given a set of synonyms (synsets) and sentences with these synonyms. It is necessary to select the meaning of the word in the sentence automatically. 1285 sentences were tagged by experts, namely, one of the dictionary meanings was selected by experts for target words. To solve the WSD-problem, an algorithm based on a new method of vector-word contexts proximity calculation is proposed. In order to achieve higher accuracy, a preliminary epsilon-filtering of words is performed, both in the sentence and in the set of synonyms. An extensive program of experiments was carried out. Four algorithms are implemented, including a new algorithm. Experiments have shown that in a number of cases the new algorithm shows better results. The developed software and the tagged corpus have an open license and are available online. Wiktionary and Wikisource are used. A brief description of this work can be viewed in slides (https://goo.gl/9ak6Gt). Video lecture in Russian on this research is available online (https://youtu.be/-DLmRkepf58).
* 15 pages, 1 table, 15 figures, accepted in the journal Transactions of Karelian Research Centre of the Russian Academy of Sciences
Calculated attributes of synonym sets
Mar 05, 2018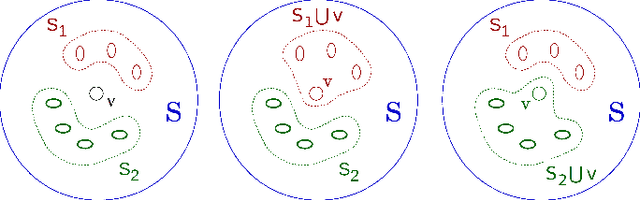
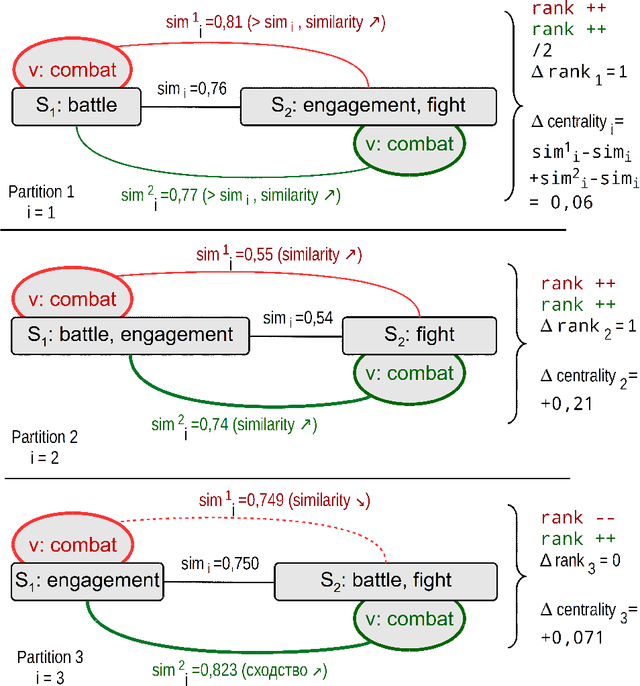
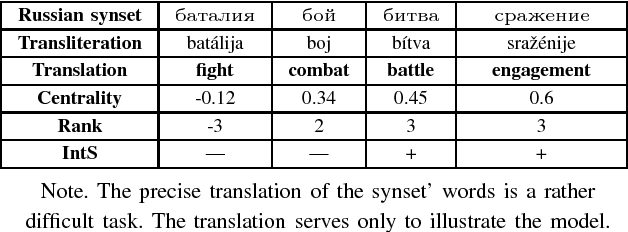

The goal of formalization, proposed in this paper, is to bring together, as near as possible, the theoretic linguistic problem of synonym conception and the computer linguistic methods based generally on empirical intuitive unjustified factors. Using the word vector representation we have proposed the geometric approach to mathematical modeling of synonym set (synset). The word embedding is based on the neural networks (Skip-gram, CBOW), developed and realized as word2vec program by T. Mikolov. The standard cosine similarity is used as the distance between word-vectors. Several geometric characteristics of the synset words are introduced: the interior of synset, the synset word rank and centrality. These notions are intended to select the most significant synset words, i.e. the words which senses are the nearest to the sense of a synset. Some experiments with proposed notions, based on RusVectores resources, are represented. A brief description of this work can be viewed in slides https://goo.gl/K82Fei
Ontology-Based Users & Requests Clustering in Customer Service Management System
May 27, 2005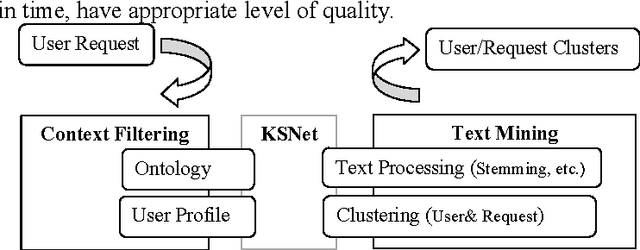
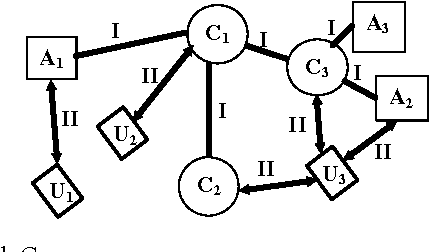
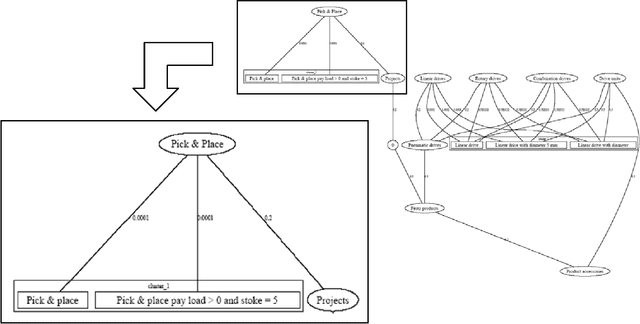
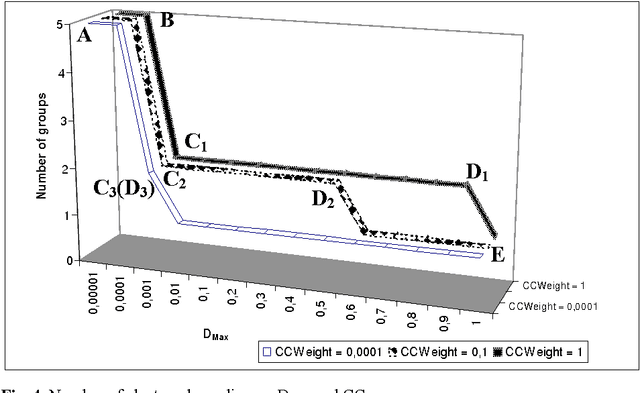
Customer Service Management is one of major business activities to better serve company customers through the introduction of reliable processes and procedures. Today this kind of activities is implemented through e-services to directly involve customers into business processes. Traditionally Customer Service Management involves application of data mining techniques to discover usage patterns from the company knowledge memory. Hence grouping of customers/requests to clusters is one of major technique to improve the level of company customization. The goal of this paper is to present an efficient for implementation approach for clustering users and their requests. The approach uses ontology as knowledge representation model to improve the semantic interoperability between units of the company and customers. Some fragments of the approach tested in an industrial company are also presented in the paper.
* 15 pages, 4 figures, published in Lecture Notes in Computer Science