 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Open corpus of the Veps and Karelian languages: overview and applications
Jun 08, 2022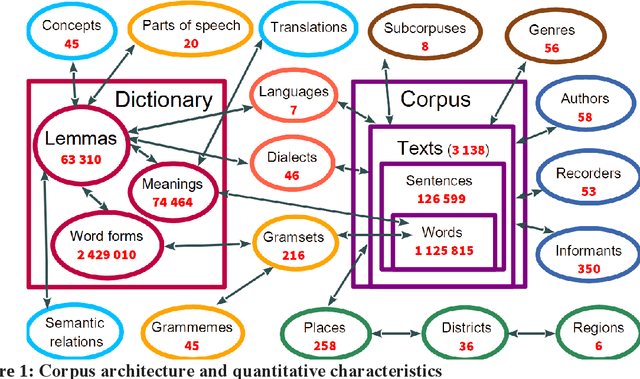
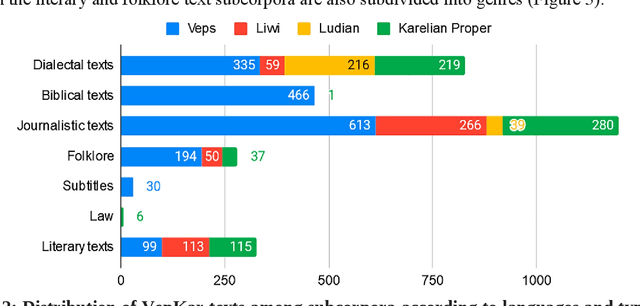
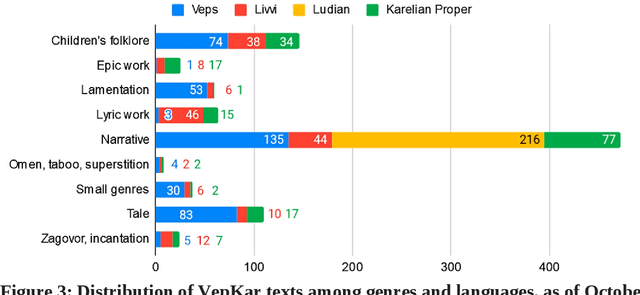
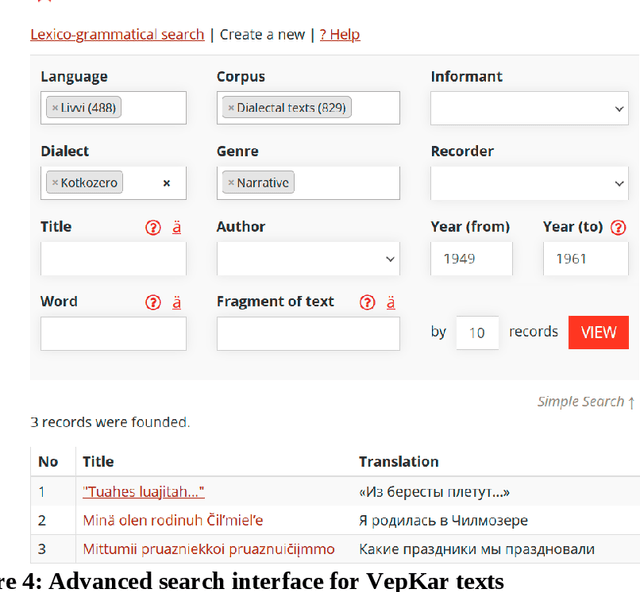
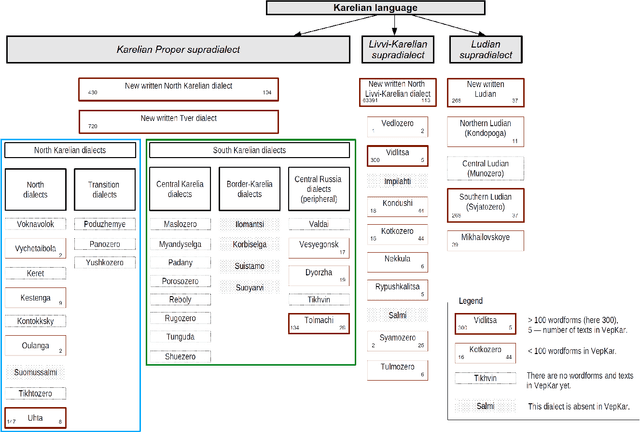
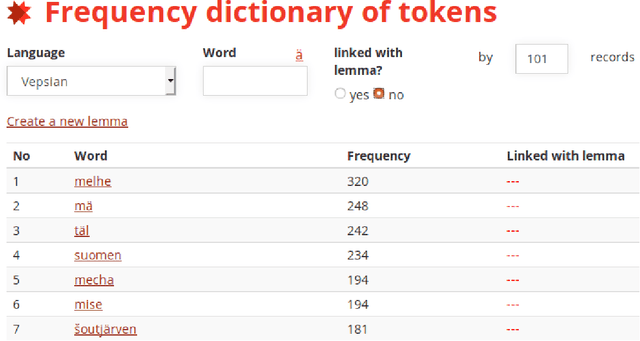
A growing priority in the study of Baltic-Finnic languages of the Republic of Karelia has been the methods and tools of corpus linguistics. Since 2016, linguists, mathematicians, and programmers at the Karelian Research Centre have been working with the Open Corpus of the Veps and Karelian Languages (VepKar), which is an extension of the Veps Corpus created in 2009. The VepKar corpus comprises texts in Karelian and Veps, multifunctional dictionaries linked to them, and software with an advanced system of search using various criteria of the texts (language, genre, etc.) and numerous linguistic categories (lexical and grammatical search in texts was implemented thanks to the generator of word forms that we created earlier). A corpus of 3000 texts was compiled, texts were uploaded and marked up, the system for classifying texts into languages, dialects, types and genres was introduced, and the word-form generator was created. Future plans include developing a speech module for working with audio recordings and a syntactic tagging module using morphological analysis outputs. Owing to continuous functional advancements in the corpus manager and ongoing VepKar enrichment with new material and text markup, users can handle a wide range of scientific and applied tasks. In creating the universal national VepKar corpus, its developers and managers strive to preserve and exhibit as fully as possible the state of the Veps and Karelian languages in the 19th-21st centuries.
* 9 pages, 9 figures, published in the journal
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
LowResourceEval-2019: a shared task on morphological analysis for low-resource languages
Jan 30, 2020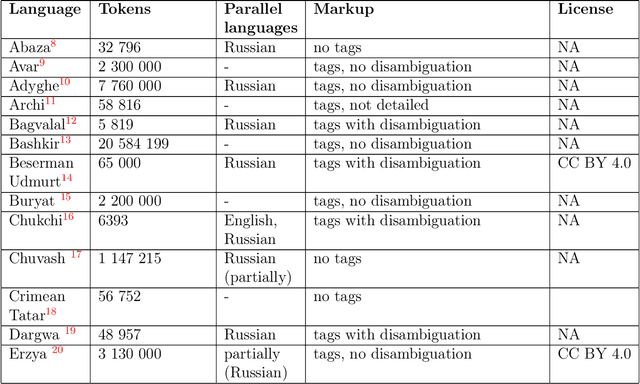
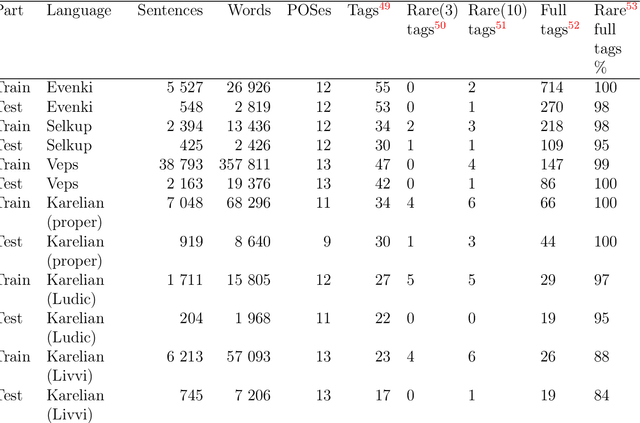
The paper describes the results of the first shared task on morphological analysis for the languages of Russia, namely, Evenki, Karelian, Selkup, and Veps. For the languages in question, only small-sized corpora are available. The tasks include morphological analysis, word form generation and morpheme segmentation. Four teams participated in the shared task. Most of them use machine-learning approaches, outperforming the existing rule-based ones. The article describes the datasets prepared for the shared tasks and contains analysis of the participants' solutions. Language corpora having different formats were transformed into CONLL-U format. The universal format makes the datasets comparable to other language corpura and facilitates using them in other NLP tasks.
* 16 pages, 4 tables, 2 figures, published in the conference proceeding