 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Fine-Grained Categorization and Domain-Specific Transfer Learning
Jun 16, 2018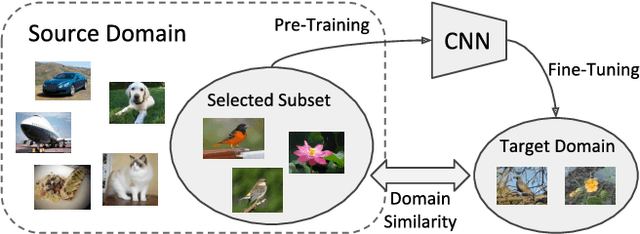

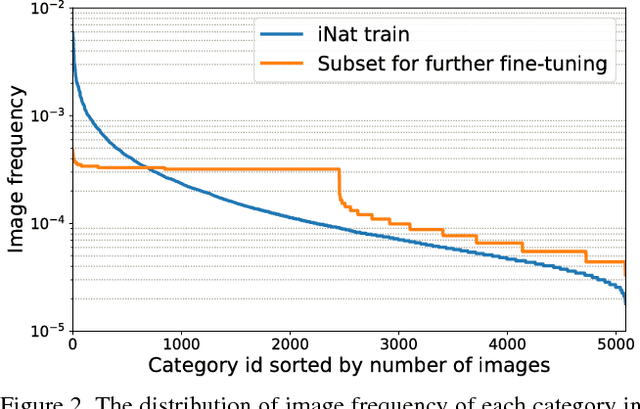
Transferring the knowledge learned from large scale datasets (e.g., ImageNet) via fine-tuning offers an effective solution for domain-specific fine-grained visual categorization (FGVC) tasks (e.g., recognizing bird species or car make and model). In such scenarios, data annotation often calls for specialized domain knowledge and thus is difficult to scale. In this work, we first tackle a problem in large scale FGVC. Our method won first place in iNaturalist 2017 large scale species classification challenge. Central to the success of our approach is a training scheme that uses higher image resolution and deals with the long-tailed distribution of training data. Next, we study transfer learning via fine-tuning from large scale datasets to small scale, domain-specific FGVC datasets. We propose a measure to estimate domain similarity via Earth Mover's Distance and demonstrate that transfer learning benefits from pre-training on a source domain that is similar to the target domain by this measure. Our proposed transfer learning outperforms ImageNet pre-training and obtains state-of-the-art results on multiple commonly used FGVC datasets.
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Apr 02, 2018

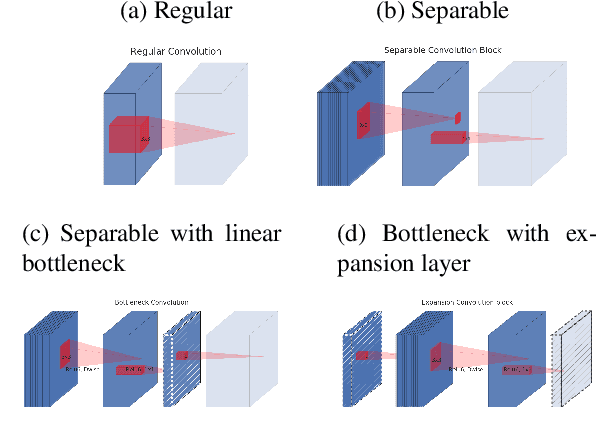
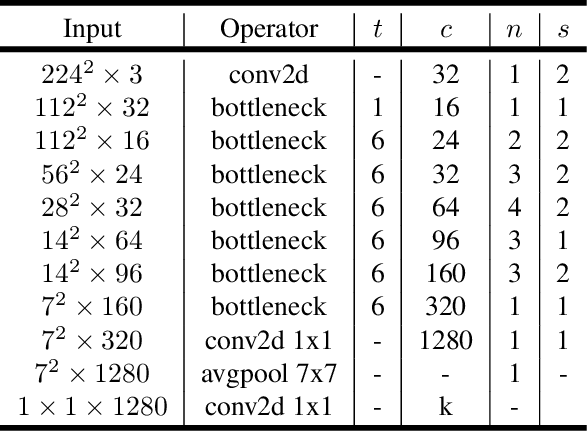
In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3. The MobileNetV2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input an MobileNetV2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on Imagenet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as the number of parameters
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
Dec 15, 2017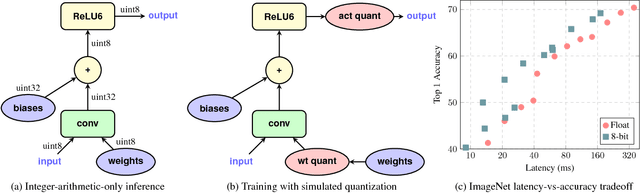

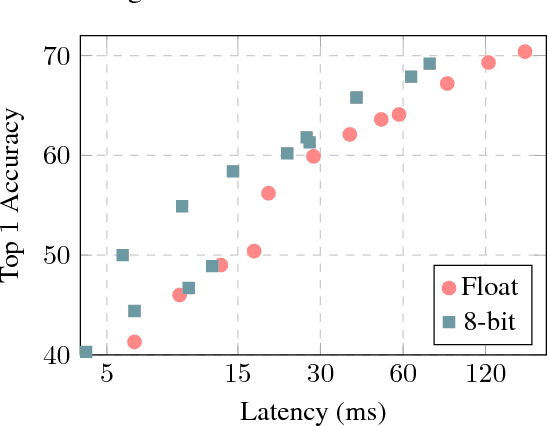
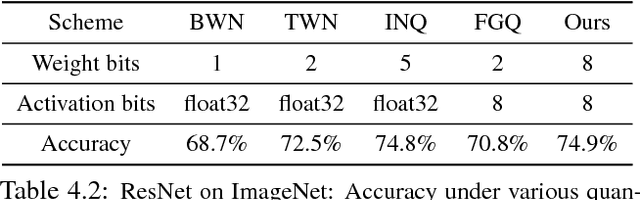
The rising popularity of intelligent mobile devices and the daunting computational cost of deep learning-based models call for efficient and accurate on-device inference schemes. We propose a quantization scheme that allows inference to be carried out using integer-only arithmetic, which can be implemented more efficiently than floating point inference on commonly available integer-only hardware. We also co-design a training procedure to preserve end-to-end model accuracy post quantization. As a result, the proposed quantization scheme improves the tradeoff between accuracy and on-device latency. The improvements are significant even on MobileNets, a model family known for run-time efficiency, and are demonstrated in ImageNet classification and COCO detection on popular CPUs.
The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition
Oct 18, 2016
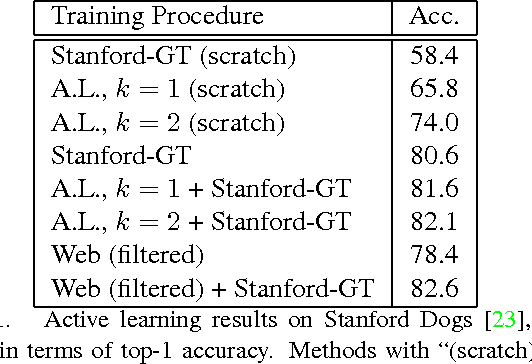

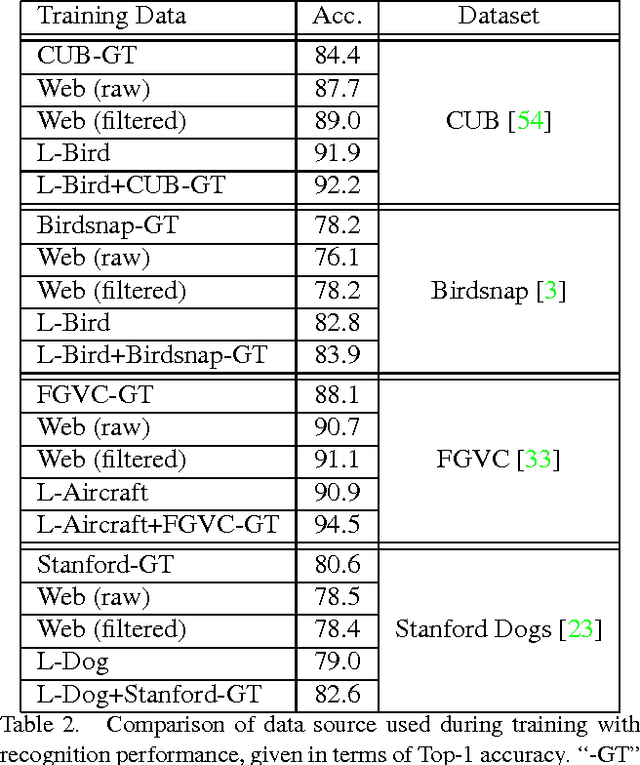
Current approaches for fine-grained recognition do the following: First, recruit experts to annotate a dataset of images, optionally also collecting more structured data in the form of part annotations and bounding boxes. Second, train a model utilizing this data. Toward the goal of solving fine-grained recognition, we introduce an alternative approach, leveraging free, noisy data from the web and simple, generic methods of recognition. This approach has benefits in both performance and scalability. We demonstrate its efficacy on four fine-grained datasets, greatly exceeding existing state of the art without the manual collection of even a single label, and furthermore show first results at scaling to more than 10,000 fine-grained categories. Quantitatively, we achieve top-1 accuracies of 92.3% on CUB-200-2011, 85.4% on Birdsnap, 93.4% on FGVC-Aircraft, and 80.8% on Stanford Dogs without using their annotated training sets. We compare our approach to an active learning approach for expanding fine-grained datasets.
Dynamical Systems Trees
Jul 11, 2012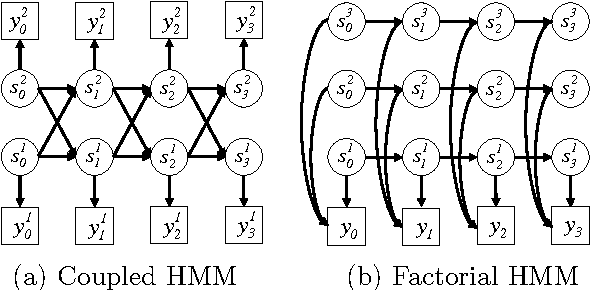
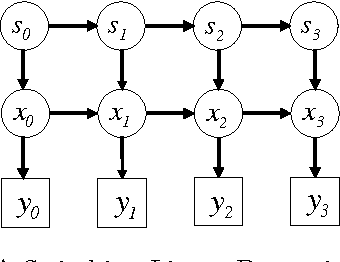
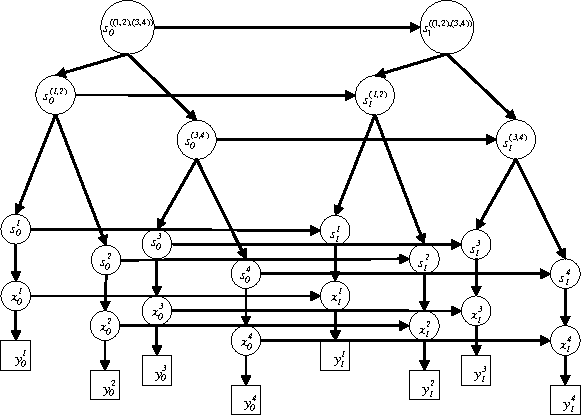
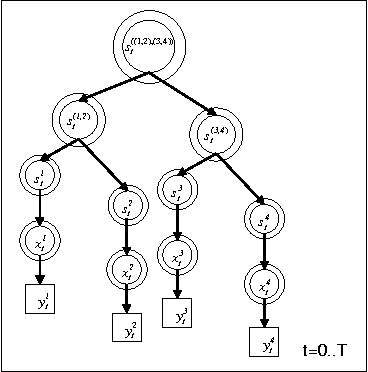
We propose dynamical systems trees (DSTs) as a flexible class of models for describing multiple processes that interact via a hierarchy of aggregating parent chains. DSTs extend Kalman filters, hidden Markov models and nonlinear dynamical systems to an interactive group scenario. Various individual processes interact as communities and sub-communities in a tree structure that is unrolled in time. To accommodate nonlinear temporal activity, each individual leaf process is modeled as a dynamical system containing discrete and/or continuous hidden states with discrete and/or Gaussian emissions. Subsequent higher level parent processes act like hidden Markov models and mediate the interaction between leaf processes or between other parent processes in the hierarchy. Aggregator chains are parents of child processes that they combine and mediate, yielding a compact overall parameterization. We provide tractable inference and learning algorithms for arbitrary DST topologies via an efficient structured mean-field algorithm. The diverse applicability of DSTs is demonstrated by experiments on gene expression data and by modeling group behavior in the setting of an American football game.