 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn MAP Inference by MWSS on Perfect Graphs
Sep 26, 2013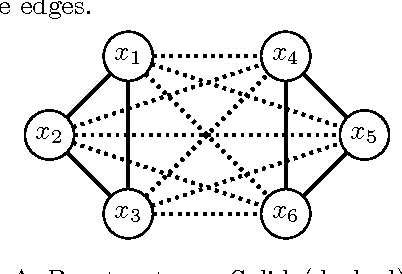
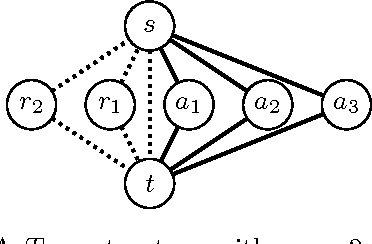
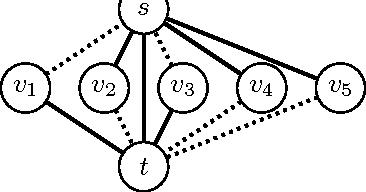
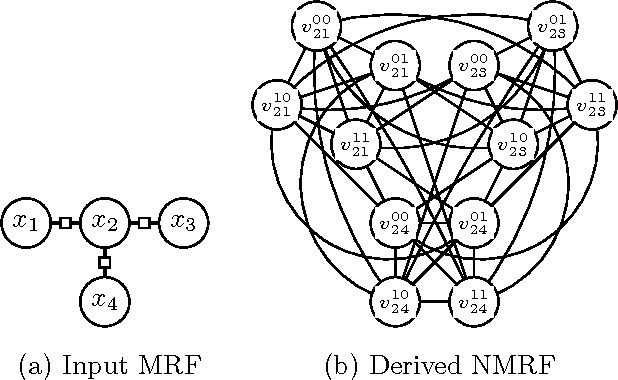
Finding the most likely (MAP) configuration of a Markov random field (MRF) is NP-hard in general. A promising, recent technique is to reduce the problem to finding a maximum weight stable set (MWSS) on a derived weighted graph, which if perfect, allows inference in polynomial time. We derive new results for this approach, including a general decomposition theorem for MRFs of any order and number of labels, extensions of results for binary pairwise models with submodular cost functions to higher order, and an exact characterization of which binary pairwise MRFs can be efficiently solved with this method. This defines the power of the approach on this class of models, improves our toolbox and expands the range of tractable models.
Feature Selection and Dualities in Maximum Entropy Discrimination
Jan 16, 2013
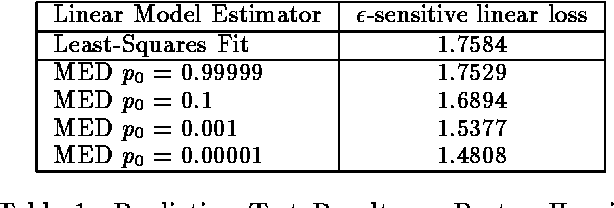

Incorporating feature selection into a classification or regression method often carries a number of advantages. In this paper we formalize feature selection specifically from a discriminative perspective of improving classification/regression accuracy. The feature selection method is developed as an extension to the recently proposed maximum entropy discrimination (MED) framework. We describe MED as a flexible (Bayesian) regularization approach that subsumes, e.g., support vector classification, regression and exponential family models. For brevity, we restrict ourselves primarily to feature selection in the context of linear classification/regression methods and demonstrate that the proposed approach indeed carries substantial improvements in practice. Moreover, we discuss and develop various extensions of feature selection, including the problem of dealing with example specific but unobserved degrees of freedom -- alignments or invariants.
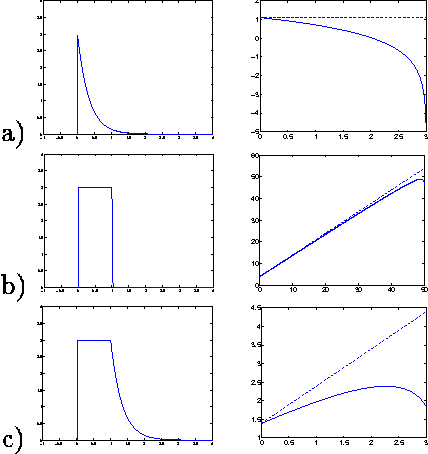
Dynamical Systems Trees
Jul 11, 2012
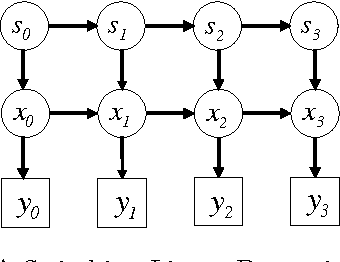
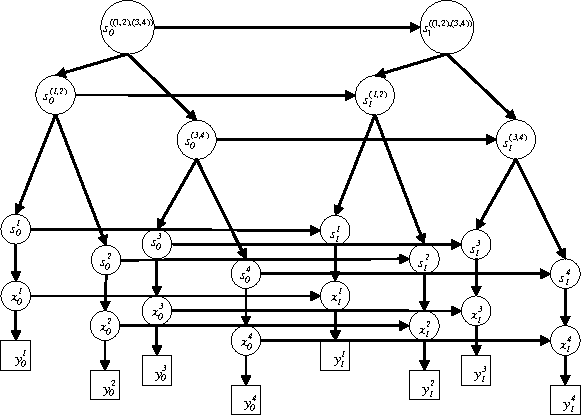
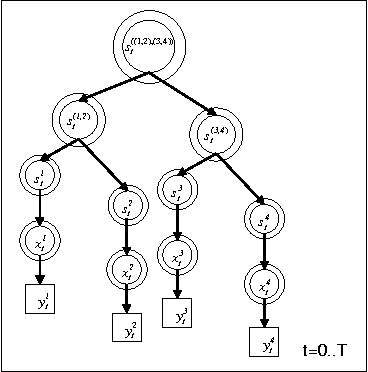
We propose dynamical systems trees (DSTs) as a flexible class of models for describing multiple processes that interact via a hierarchy of aggregating parent chains. DSTs extend Kalman filters, hidden Markov models and nonlinear dynamical systems to an interactive group scenario. Various individual processes interact as communities and sub-communities in a tree structure that is unrolled in time. To accommodate nonlinear temporal activity, each individual leaf process is modeled as a dynamical system containing discrete and/or continuous hidden states with discrete and/or Gaussian emissions. Subsequent higher level parent processes act like hidden Markov models and mediate the interaction between leaf processes or between other parent processes in the hierarchy. Aggregator chains are parents of child processes that they combine and mediate, yielding a compact overall parameterization. We provide tractable inference and learning algorithms for arbitrary DST topologies via an efficient structured mean-field algorithm. The diverse applicability of DSTs is demonstrated by experiments on gene expression data and by modeling group behavior in the setting of an American football game.
Bayesian Out-Trees
Jun 13, 2012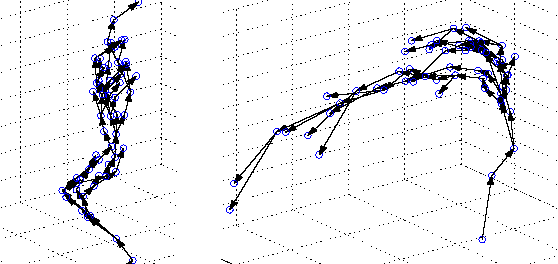
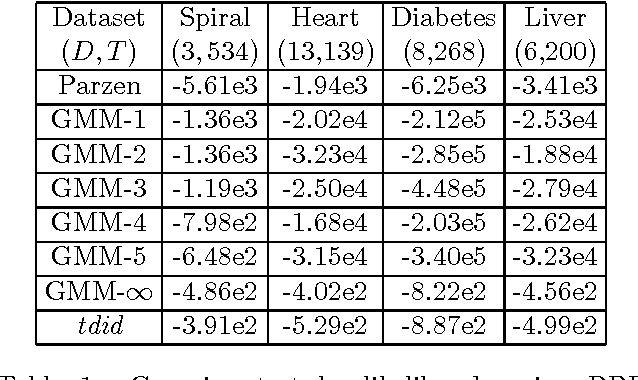
A Bayesian treatment of latent directed graph structure for non-iid data is provided where each child datum is sampled with a directed conditional dependence on a single unknown parent datum. The latent graph structure is assumed to lie in the family of directed out-tree graphs which leads to efficient Bayesian inference. The latent likelihood of the data and its gradients are computable in closed form via Tutte's directed matrix tree theorem using determinants and inverses of the out-Laplacian. This novel likelihood subsumes iid likelihood, is exchangeable and yields efficient unsupervised and semi-supervised learning algorithms. In addition to handling taxonomy and phylogenetic datasets the out-tree assumption performs surprisingly well as a semi-parametric density estimator on standard iid datasets. Experiments with unsupervised and semisupervised learning are shown on various UCI and taxonomy datasets.
MAP Estimation, Message Passing, and Perfect Graphs
May 09, 2012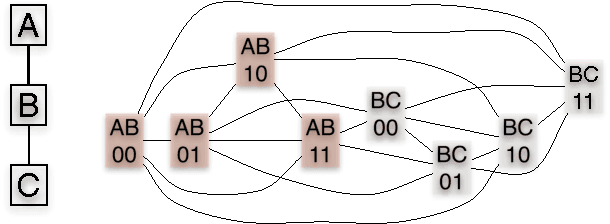
Efficiently finding the maximum a posteriori (MAP) configuration of a graphical model is an important problem which is often implemented using message passing algorithms. The optimality of such algorithms is only well established for singly-connected graphs and other limited settings. This article extends the set of graphs where MAP estimation is in P and where message passing recovers the exact solution to so-called perfect graphs. This result leverages recent progress in defining perfect graphs (the strong perfect graph theorem), linear programming relaxations of MAP estimation and recent convergent message passing schemes. The article converts graphical models into nand Markov random fields which are straightforward to relax into linear programs. Therein, integrality can be established in general by testing for graph perfection. This perfection test is performed efficiently using a polynomial time algorithm. Alternatively, known decomposition tools from perfect graph theory may be used to prove perfection for certain families of graphs. Thus, a general graph framework is provided for determining when MAP estimation in any graphical model is in P, has an integral linear programming relaxation and is exactly recoverable by message passing.