 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Knowledge Distillation Really Work?
Jun 10, 2021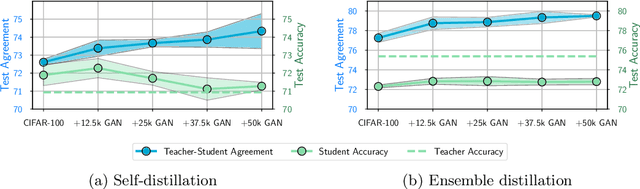
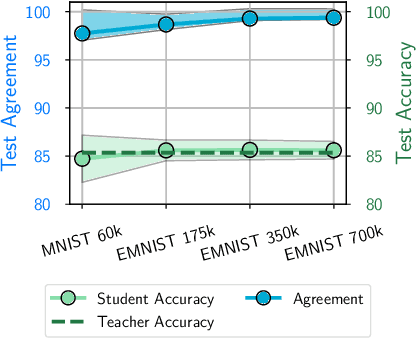

Knowledge distillation is a popular technique for training a small student network to emulate a larger teacher model, such as an ensemble of networks. We show that while knowledge distillation can improve student generalization, it does not typically work as it is commonly understood: there often remains a surprisingly large discrepancy between the predictive distributions of the teacher and the student, even in cases when the student has the capacity to perfectly match the teacher. We identify difficulties in optimization as a key reason for why the student is unable to match the teacher. We also show how the details of the dataset used for distillation play a role in how closely the student matches the teacher -- and that more closely matching the teacher paradoxically does not always lead to better student generalization.
What Are Bayesian Neural Network Posteriors Really Like?
Apr 29, 2021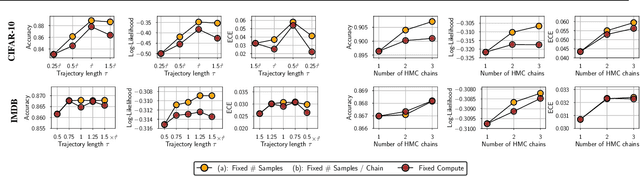
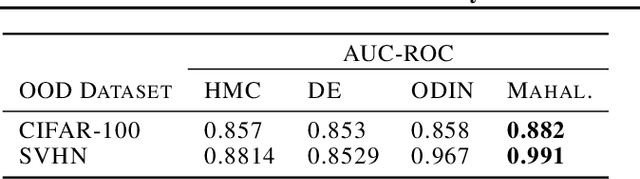
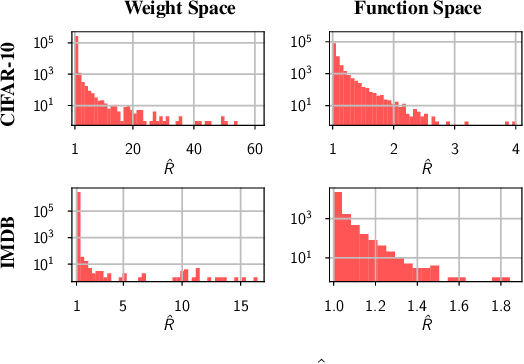
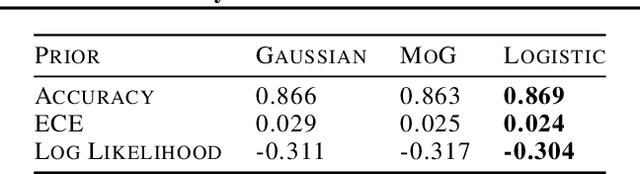
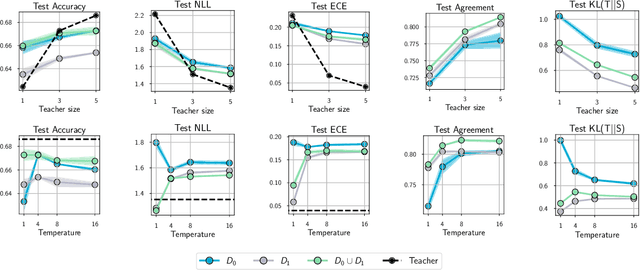
The posterior over Bayesian neural network (BNN) parameters is extremely high-dimensional and non-convex. For computational reasons, researchers approximate this posterior using inexpensive mini-batch methods such as mean-field variational inference or stochastic-gradient Markov chain Monte Carlo (SGMCMC). To investigate foundational questions in Bayesian deep learning, we instead use full-batch Hamiltonian Monte Carlo (HMC) on modern architectures. We show that (1) BNNs can achieve significant performance gains over standard training and deep ensembles; (2) a single long HMC chain can provide a comparable representation of the posterior to multiple shorter chains; (3) in contrast to recent studies, we find posterior tempering is not needed for near-optimal performance, with little evidence for a "cold posterior" effect, which we show is largely an artifact of data augmentation; (4) BMA performance is robust to the choice of prior scale, and relatively similar for diagonal Gaussian, mixture of Gaussian, and logistic priors; (5) Bayesian neural networks show surprisingly poor generalization under domain shift; (6) while cheaper alternatives such as deep ensembles and SGMCMC methods can provide good generalization, they provide distinct predictive distributions from HMC. Notably, deep ensemble predictive distributions are similarly close to HMC as standard SGLD, and closer than standard variational inference.
A Practical Method for Constructing Equivariant Multilayer Perceptrons for Arbitrary Matrix Groups
Apr 19, 2021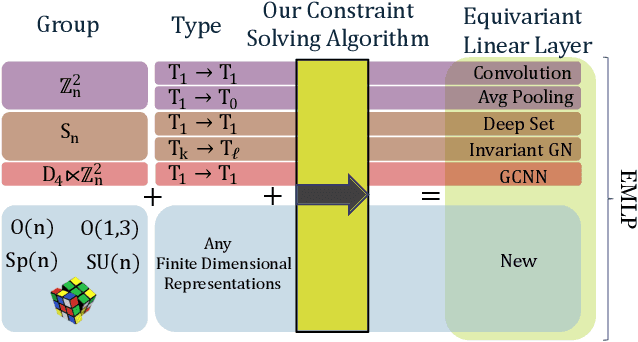

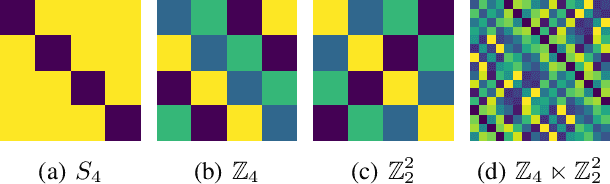

Symmetries and equivariance are fundamental to the generalization of neural networks on domains such as images, graphs, and point clouds. Existing work has primarily focused on a small number of groups, such as the translation, rotation, and permutation groups. In this work we provide a completely general algorithm for solving for the equivariant layers of matrix groups. In addition to recovering solutions from other works as special cases, we construct multilayer perceptrons equivariant to multiple groups that have never been tackled before, including $\mathrm{O}(1,3)$, $\mathrm{O}(5)$, $\mathrm{Sp}(n)$, and the Rubik's cube group. Our approach outperforms non-equivariant baselines, with applications to particle physics and dynamical systems. We release our software library to enable researchers to construct equivariant layers for arbitrary matrix groups.
Kernel Interpolation for Scalable Online Gaussian Processes
Mar 02, 2021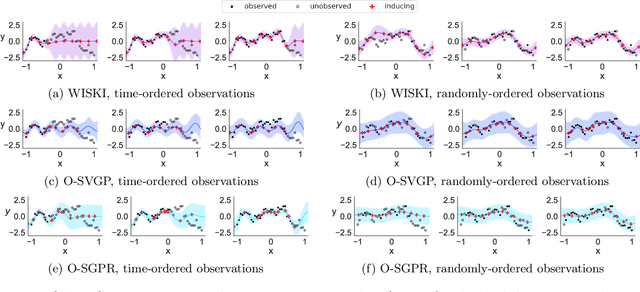
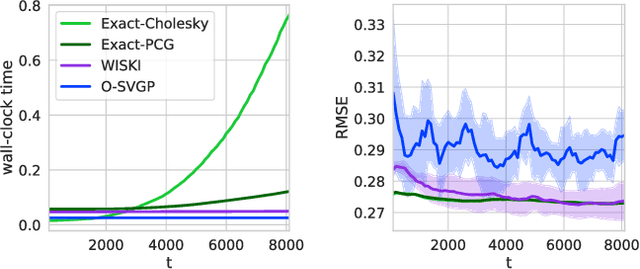
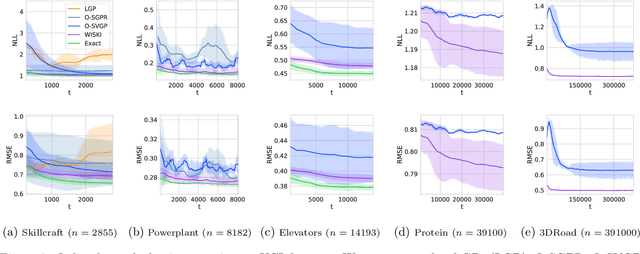
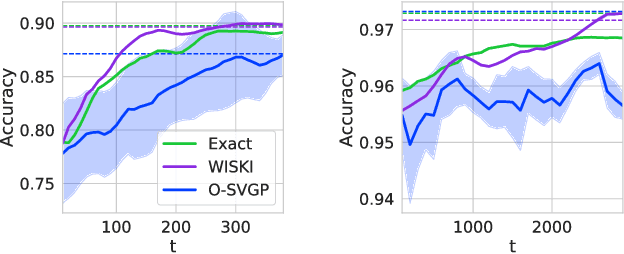
Gaussian processes (GPs) provide a gold standard for performance in online settings, such as sample-efficient control and black box optimization, where we need to update a posterior distribution as we acquire data in a sequential fashion. However, updating a GP posterior to accommodate even a single new observation after having observed $n$ points incurs at least $O(n)$ computations in the exact setting. We show how to use structured kernel interpolation to efficiently recycle computations for constant-time $O(1)$ online updates with respect to the number of points $n$, while retaining exact inference. We demonstrate the promise of our approach in a range of online regression and classification settings, Bayesian optimization, and active sampling to reduce error in malaria incidence forecasting. Code is available at https://github.com/wjmaddox/online_gp.
Fast Adaptation with Linearized Neural Networks
Mar 02, 2021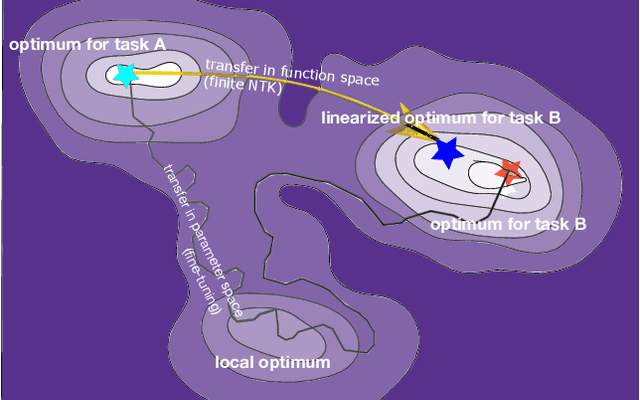

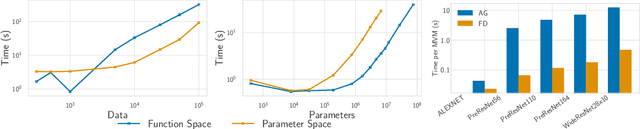
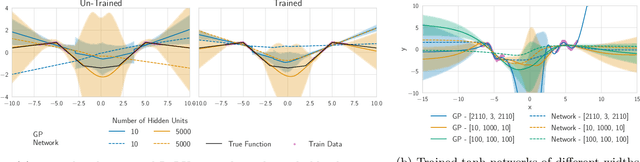
The inductive biases of trained neural networks are difficult to understand and, consequently, to adapt to new settings. We study the inductive biases of linearizations of neural networks, which we show to be surprisingly good summaries of the full network functions. Inspired by this finding, we propose a technique for embedding these inductive biases into Gaussian processes through a kernel designed from the Jacobian of the network. In this setting, domain adaptation takes the form of interpretable posterior inference, with accompanying uncertainty estimation. This inference is analytic and free of local optima issues found in standard techniques such as fine-tuning neural network weights to a new task. We develop significant computational speed-ups based on matrix multiplies, including a novel implementation for scalable Fisher vector products. Our experiments on both image classification and regression demonstrate the promise and convenience of this framework for transfer learning, compared to neural network fine-tuning. Code is available at https://github.com/amzn/xfer/tree/master/finite_ntk.
Loss Surface Simplexes for Mode Connecting Volumes and Fast Ensembling
Feb 25, 2021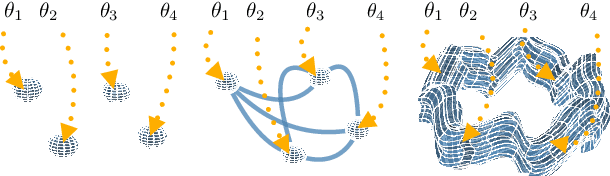
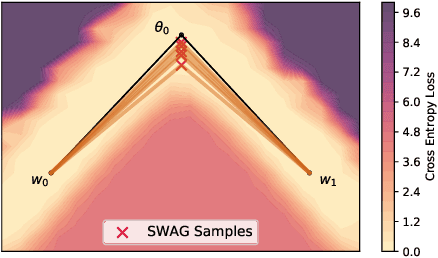
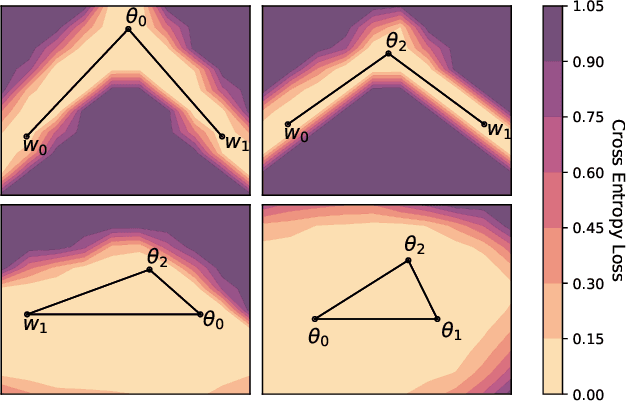
With a better understanding of the loss surfaces for multilayer networks, we can build more robust and accurate training procedures. Recently it was discovered that independently trained SGD solutions can be connected along one-dimensional paths of near-constant training loss. In this paper, we show that there are mode-connecting simplicial complexes that form multi-dimensional manifolds of low loss, connecting many independently trained models. Inspired by this discovery, we show how to efficiently build simplicial complexes for fast ensembling, outperforming independently trained deep ensembles in accuracy, calibration, and robustness to dataset shift. Notably, our approach only requires a few training epochs to discover a low-loss simplex, starting from a pre-trained solution. Code is available at https://github.com/g-benton/loss-surface-simplexes.
Simplifying Hamiltonian and Lagrangian Neural Networks via Explicit Constraints
Oct 26, 2020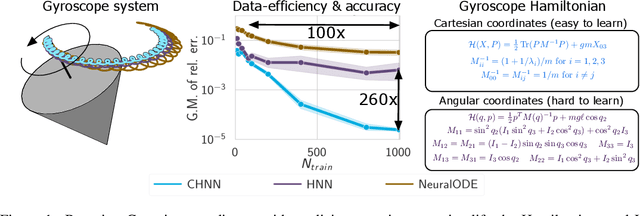


Reasoning about the physical world requires models that are endowed with the right inductive biases to learn the underlying dynamics. Recent works improve generalization for predicting trajectories by learning the Hamiltonian or Lagrangian of a system rather than the differential equations directly. While these methods encode the constraints of the systems using generalized coordinates, we show that embedding the system into Cartesian coordinates and enforcing the constraints explicitly with Lagrange multipliers dramatically simplifies the learning problem. We introduce a series of challenging chaotic and extended-body systems, including systems with N-pendulums, spring coupling, magnetic fields, rigid rotors, and gyroscopes, to push the limits of current approaches. Our experiments show that Cartesian coordinates with explicit constraints lead to a 100x improvement in accuracy and data efficiency.
Learning Invariances in Neural Networks
Oct 22, 2020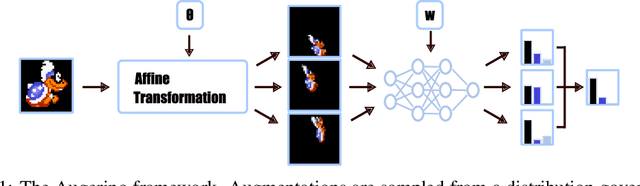

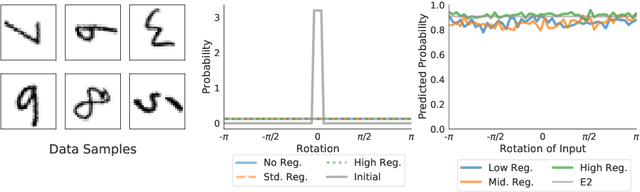

Invariances to translations have imbued convolutional neural networks with powerful generalization properties. However, we often do not know a priori what invariances are present in the data, or to what extent a model should be invariant to a given symmetry group. We show how to \emph{learn} invariances and equivariances by parameterizing a distribution over augmentations and optimizing the training loss simultaneously with respect to the network parameters and augmentation parameters. With this simple procedure we can recover the correct set and extent of invariances on image classification, regression, segmentation, and molecular property prediction from a large space of augmentations, on training data alone.
On the model-based stochastic value gradient for continuous reinforcement learning
Aug 28, 2020

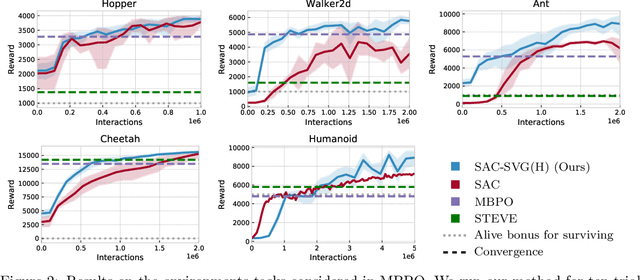
Model-based reinforcement learning approaches add explicit domain knowledge to agents in hopes of improving the sample-efficiency in comparison to model-free agents. However, in practice model-based methods are unable to achieve the same asymptotic performance on challenging continuous control tasks due to the complexity of learning and controlling an explicit world model. In this paper we investigate the stochastic value gradient (SVG), which is a well-known family of methods for controlling continuous systems which includes model-based approaches that distill a model-based value expansion into a model-free policy. We consider a variant of the model-based SVG that scales to larger systems and uses 1) an entropy regularization to help with exploration, 2) a learned deterministic world model to improve the short-horizon value estimate, and 3) a learned model-free value estimate after the model's rollout. This SVG variation captures the model-free soft actor-critic method as an instance when the model rollout horizon is zero, and otherwise uses short-horizon model rollouts to improve the value estimate for the policy update. We surpass the asymptotic performance of other model-based methods on the proprioceptive MuJoCo locomotion tasks from the OpenAI gym, including a humanoid. We notably achieve these results with a simple deterministic world model without requiring an ensemble.
Improving GAN Training with Probability Ratio Clipping and Sample Reweighting
Jun 30, 2020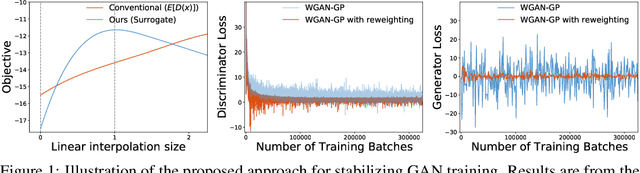


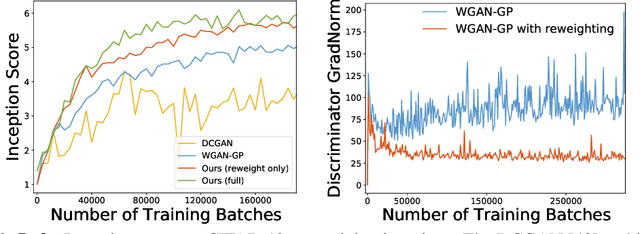
Despite success on a wide range of problems related to vision, generative adversarial networks (GANs) can suffer from inferior performance due to unstable training, especially for text generation. We propose a new variational GAN training framework which enjoys superior training stability. Our approach is inspired by a connection of GANs and reinforcement learning under a variational perspective. The connection leads to (1) probability ratio clipping that regularizes generator training to prevent excessively large updates, and (2) a sample re-weighting mechanism that stabilizes discriminator training by downplaying bad-quality fake samples. We provide theoretical analysis on the convergence of our approach. By plugging the training approach in diverse state-of-the-art GAN architectures, we obtain significantly improved performance over a range of tasks, including text generation, text style transfer, and image generation.