 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSinkhorn Flow: A Continuous-Time Framework for Understanding and Generalizing the Sinkhorn Algorithm
Nov 28, 2023Many problems in machine learning can be formulated as solving entropy-regularized optimal transport on the space of probability measures. The canonical approach involves the Sinkhorn iterates, renowned for their rich mathematical properties. Recently, the Sinkhorn algorithm has been recast within the mirror descent framework, thus benefiting from classical optimization theory insights. Here, we build upon this result by introducing a continuous-time analogue of the Sinkhorn algorithm. This perspective allows us to derive novel variants of Sinkhorn schemes that are robust to noise and bias. Moreover, our continuous-time dynamics not only generalize but also offer a unified perspective on several recently discovered dynamics in machine learning and mathematics, such as the "Wasserstein mirror flow" of (Deb et al. 2023) or the "mean-field Schr\"odinger equation" of (Claisse et al. 2023).
Data-Efficient Task Generalization via Probabilistic Model-based Meta Reinforcement Learning
Nov 13, 2023



We introduce PACOH-RL, a novel model-based Meta-Reinforcement Learning (Meta-RL) algorithm designed to efficiently adapt control policies to changing dynamics. PACOH-RL meta-learns priors for the dynamics model, allowing swift adaptation to new dynamics with minimal interaction data. Existing Meta-RL methods require abundant meta-learning data, limiting their applicability in settings such as robotics, where data is costly to obtain. To address this, PACOH-RL incorporates regularization and epistemic uncertainty quantification in both the meta-learning and task adaptation stages. When facing new dynamics, we use these uncertainty estimates to effectively guide exploration and data collection. Overall, this enables positive transfer, even when access to data from prior tasks or dynamic settings is severely limited. Our experiment results demonstrate that PACOH-RL outperforms model-based RL and model-based Meta-RL baselines in adapting to new dynamic conditions. Finally, on a real robotic car, we showcase the potential for efficient RL policy adaptation in diverse, data-scarce conditions.
Likelihood Ratio Confidence Sets for Sequential Decision Making
Nov 08, 2023



Certifiable, adaptive uncertainty estimates for unknown quantities are an essential ingredient of sequential decision-making algorithms. Standard approaches rely on problem-dependent concentration results and are limited to a specific combination of parameterization, noise family, and estimator. In this paper, we revisit the likelihood-based inference principle and propose to use likelihood ratios to construct any-time valid confidence sequences without requiring specialized treatment in each application scenario. Our method is especially suitable for problems with well-specified likelihoods, and the resulting sets always maintain the prescribed coverage in a model-agnostic manner. The size of the sets depends on a choice of estimator sequence in the likelihood ratio. We discuss how to provably choose the best sequence of estimators and shed light on connections to online convex optimization with algorithms such as Follow-the-Regularized-Leader. To counteract the initially large bias of the estimators, we propose a reweighting scheme that also opens up deployment in non-parametric settings such as RKHS function classes. We provide a non-asymptotic analysis of the likelihood ratio confidence sets size for generalized linear models, using insights from convex duality and online learning. We showcase the practical strength of our method on generalized linear bandit problems, survival analysis, and bandits with various additive noise distributions.
Riemannian stochastic optimization methods avoid strict saddle points
Nov 04, 2023

Many modern machine learning applications - from online principal component analysis to covariance matrix identification and dictionary learning - can be formulated as minimization problems on Riemannian manifolds, and are typically solved with a Riemannian stochastic gradient method (or some variant thereof). However, in many cases of interest, the resulting minimization problem is not geodesically convex, so the convergence of the chosen solver to a desirable solution - i.e., a local minimizer - is by no means guaranteed. In this paper, we study precisely this question, that is, whether stochastic Riemannian optimization algorithms are guaranteed to avoid saddle points with probability 1. For generality, we study a family of retraction-based methods which, in addition to having a potentially much lower per-iteration cost relative to Riemannian gradient descent, include other widely used algorithms, such as natural policy gradient methods and mirror descent in ordinary convex spaces. In this general setting, we show that, under mild assumptions for the ambient manifold and the oracle providing gradient information, the policies under study avoid strict saddle points / submanifolds with probability 1, from any initial condition. This result provides an important sanity check for the use of gradient methods on manifolds as it shows that, almost always, the limit state of a stochastic Riemannian algorithm can only be a local minimizer.
Efficient Exploration in Continuous-time Model-based Reinforcement Learning
Oct 30, 2023



Reinforcement learning algorithms typically consider discrete-time dynamics, even though the underlying systems are often continuous in time. In this paper, we introduce a model-based reinforcement learning algorithm that represents continuous-time dynamics using nonlinear ordinary differential equations (ODEs). We capture epistemic uncertainty using well-calibrated probabilistic models, and use the optimistic principle for exploration. Our regret bounds surface the importance of the measurement selection strategy(MSS), since in continuous time we not only must decide how to explore, but also when to observe the underlying system. Our analysis demonstrates that the regret is sublinear when modeling ODEs with Gaussian Processes (GP) for common choices of MSS, such as equidistant sampling. Additionally, we propose an adaptive, data-dependent, practical MSS that, when combined with GP dynamics, also achieves sublinear regret with significantly fewer samples. We showcase the benefits of continuous-time modeling over its discrete-time counterpart, as well as our proposed adaptive MSS over standard baselines, on several applications.
Implicit Manifold Gaussian Process Regression
Oct 30, 2023

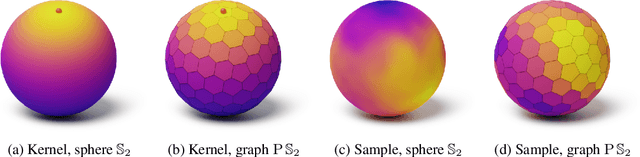
Gaussian process regression is widely used because of its ability to provide well-calibrated uncertainty estimates and handle small or sparse datasets. However, it struggles with high-dimensional data. One possible way to scale this technique to higher dimensions is to leverage the implicit low-dimensional manifold upon which the data actually lies, as postulated by the manifold hypothesis. Prior work ordinarily requires the manifold structure to be explicitly provided though, i.e. given by a mesh or be known to be one of the well-known manifolds like the sphere. In contrast, in this paper we propose a Gaussian process regression technique capable of inferring implicit structure directly from data (labeled and unlabeled) in a fully differentiable way. For the resulting model, we discuss its convergence to the Mat\'ern Gaussian process on the assumed manifold. Our technique scales up to hundreds of thousands of data points, and may improve the predictive performance and calibration of the standard Gaussian process regression in high-dimensional~settings.
Intrinsic Gaussian Vector Fields on Manifolds
Oct 28, 2023



Various applications ranging from robotics to climate science require modeling signals on non-Euclidean domains, such as the sphere. Gaussian process models on manifolds have recently been proposed for such tasks, in particular when uncertainty quantification is needed. In the manifold setting, vector-valued signals can behave very differently from scalar-valued ones, with much of the progress so far focused on modeling the latter. The former, however, are crucial for many applications, such as modeling wind speeds or force fields of unknown dynamical systems. In this paper, we propose novel Gaussian process models for vector-valued signals on manifolds that are intrinsically defined and account for the geometry of the space in consideration. We provide computational primitives needed to deploy the resulting Hodge-Mat\'ern Gaussian vector fields on the two-dimensional sphere and the hypertori. Further, we highlight two generalization directions: discrete two-dimensional meshes and "ideal" manifolds like hyperspheres, Lie groups, and homogeneous spaces. Finally, we show that our Gaussian vector fields constitute considerably more refined inductive biases than the extrinsic fields proposed before.
Contextual Stochastic Bilevel Optimization
Oct 27, 2023



We introduce contextual stochastic bilevel optimization (CSBO) -- a stochastic bilevel optimization framework with the lower-level problem minimizing an expectation conditioned on some contextual information and the upper-level decision variable. This framework extends classical stochastic bilevel optimization when the lower-level decision maker responds optimally not only to the decision of the upper-level decision maker but also to some side information and when there are multiple or even infinite many followers. It captures important applications such as meta-learning, personalized federated learning, end-to-end learning, and Wasserstein distributionally robust optimization with side information (WDRO-SI). Due to the presence of contextual information, existing single-loop methods for classical stochastic bilevel optimization are unable to converge. To overcome this challenge, we introduce an efficient double-loop gradient method based on the Multilevel Monte-Carlo (MLMC) technique and establish its sample and computational complexities. When specialized to stochastic nonconvex optimization, our method matches existing lower bounds. For meta-learning, the complexity of our method does not depend on the number of tasks. Numerical experiments further validate our theoretical results.
Causal Modeling with Stationary Diffusions
Oct 26, 2023We develop a novel approach towards causal inference. Rather than structural equations over a causal graph, we learn stochastic differential equations (SDEs) whose stationary densities model a system's behavior under interventions. These stationary diffusion models do not require the formalism of causal graphs, let alone the common assumption of acyclicity. We show that in several cases, they generalize to unseen interventions on their variables, often better than classical approaches. Our inference method is based on a new theoretical result that expresses a stationarity condition on the diffusion's generator in a reproducing kernel Hilbert space. The resulting kernel deviation from stationarity (KDS) is an objective function of independent interest.
DockGame: Cooperative Games for Multimeric Rigid Protein Docking
Oct 09, 2023Protein interactions and assembly formation are fundamental to most biological processes. Predicting the assembly structure from constituent proteins -- referred to as the protein docking task -- is thus a crucial step in protein design applications. Most traditional and deep learning methods for docking have focused mainly on binary docking, following either a search-based, regression-based, or generative modeling paradigm. In this paper, we focus on the less-studied multimeric (i.e., two or more proteins) docking problem. We introduce DockGame, a novel game-theoretic framework for docking -- we view protein docking as a cooperative game between proteins, where the final assembly structure(s) constitute stable equilibria w.r.t. the underlying game potential. Since we do not have access to the true potential, we consider two approaches - i) learning a surrogate game potential guided by physics-based energy functions and computing equilibria by simultaneous gradient updates, and ii) sampling from the Gibbs distribution of the true potential by learning a diffusion generative model over the action spaces (rotations and translations) of all proteins. Empirically, on the Docking Benchmark 5.5 (DB5.5) dataset, DockGame has much faster runtimes than traditional docking methods, can generate multiple plausible assembly structures, and achieves comparable performance to existing binary docking baselines, despite solving the harder task of coordinating multiple protein chains.