 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack on Track: Bundle Adjustment for Dynamic Scene Reconstruction
Apr 20, 2025Traditional SLAM systems, which rely on bundle adjustment, struggle with highly dynamic scenes commonly found in casual videos. Such videos entangle the motion of dynamic elements, undermining the assumption of static environments required by traditional systems. Existing techniques either filter out dynamic elements or model their motion independently. However, the former often results in incomplete reconstructions, whereas the latter can lead to inconsistent motion estimates. Taking a novel approach, this work leverages a 3D point tracker to separate the camera-induced motion from the observed motion of dynamic objects. By considering only the camera-induced component, bundle adjustment can operate reliably on all scene elements as a result. We further ensure depth consistency across video frames with lightweight post-processing based on scale maps. Our framework combines the core of traditional SLAM -- bundle adjustment -- with a robust learning-based 3D tracker front-end. Integrating motion decomposition, bundle adjustment and depth refinement, our unified framework, BA-Track, accurately tracks the camera motion and produces temporally coherent and scale-consistent dense reconstructions, accommodating both static and dynamic elements. Our experiments on challenging datasets reveal significant improvements in camera pose estimation and 3D reconstruction accuracy.
Geo4D: Leveraging Video Generators for Geometric 4D Scene Reconstruction
Apr 10, 2025We introduce Geo4D, a method to repurpose video diffusion models for monocular 3D reconstruction of dynamic scenes. By leveraging the strong dynamic prior captured by such video models, Geo4D can be trained using only synthetic data while generalizing well to real data in a zero-shot manner. Geo4D predicts several complementary geometric modalities, namely point, depth, and ray maps. It uses a new multi-modal alignment algorithm to align and fuse these modalities, as well as multiple sliding windows, at inference time, thus obtaining robust and accurate 4D reconstruction of long videos. Extensive experiments across multiple benchmarks show that Geo4D significantly surpasses state-of-the-art video depth estimation methods, including recent methods such as MonST3R, which are also designed to handle dynamic scenes.
DSO: Aligning 3D Generators with Simulation Feedback for Physical Soundness
Mar 28, 2025Most 3D object generators focus on aesthetic quality, often neglecting physical constraints necessary in applications. One such constraint is that the 3D object should be self-supporting, i.e., remains balanced under gravity. Prior approaches to generating stable 3D objects used differentiable physics simulators to optimize geometry at test-time, which is slow, unstable, and prone to local optima. Inspired by the literature on aligning generative models to external feedback, we propose Direct Simulation Optimization (DSO), a framework to use the feedback from a (non-differentiable) simulator to increase the likelihood that the 3D generator outputs stable 3D objects directly. We construct a dataset of 3D objects labeled with a stability score obtained from the physics simulator. We can then fine-tune the 3D generator using the stability score as the alignment metric, via direct preference optimization (DPO) or direct reward optimization (DRO), a novel objective, which we introduce, to align diffusion models without requiring pairwise preferences. Our experiments show that the fine-tuned feed-forward generator, using either DPO or DRO objective, is much faster and more likely to produce stable objects than test-time optimization. Notably, the DSO framework works even without any ground-truth 3D objects for training, allowing the 3D generator to self-improve by automatically collecting simulation feedback on its own outputs.
Tracktention: Leveraging Point Tracking to Attend Videos Faster and Better
Mar 25, 2025Temporal consistency is critical in video prediction to ensure that outputs are coherent and free of artifacts. Traditional methods, such as temporal attention and 3D convolution, may struggle with significant object motion and may not capture long-range temporal dependencies in dynamic scenes. To address this gap, we propose the Tracktention Layer, a novel architectural component that explicitly integrates motion information using point tracks, i.e., sequences of corresponding points across frames. By incorporating these motion cues, the Tracktention Layer enhances temporal alignment and effectively handles complex object motions, maintaining consistent feature representations over time. Our approach is computationally efficient and can be seamlessly integrated into existing models, such as Vision Transformers, with minimal modification. It can be used to upgrade image-only models to state-of-the-art video ones, sometimes outperforming models natively designed for video prediction. We demonstrate this on video depth prediction and video colorization, where models augmented with the Tracktention Layer exhibit significantly improved temporal consistency compared to baselines.
SynCity: Training-Free Generation of 3D Worlds
Mar 20, 2025We address the challenge of generating 3D worlds from textual descriptions. We propose SynCity, a training- and optimization-free approach, which leverages the geometric precision of pre-trained 3D generative models and the artistic versatility of 2D image generators to create large, high-quality 3D spaces. While most 3D generative models are object-centric and cannot generate large-scale worlds, we show how 3D and 2D generators can be combined to generate ever-expanding scenes. Through a tile-based approach, we allow fine-grained control over the layout and the appearance of scenes. The world is generated tile-by-tile, and each new tile is generated within its world-context and then fused with the scene. SynCity generates compelling and immersive scenes that are rich in detail and diversity.
Dynamic Point Maps: A Versatile Representation for Dynamic 3D Reconstruction
Mar 20, 2025

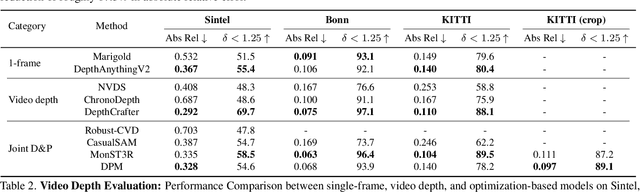

DUSt3R has recently shown that one can reduce many tasks in multi-view geometry, including estimating camera intrinsics and extrinsics, reconstructing the scene in 3D, and establishing image correspondences, to the prediction of a pair of viewpoint-invariant point maps, i.e., pixel-aligned point clouds defined in a common reference frame. This formulation is elegant and powerful, but unable to tackle dynamic scenes. To address this challenge, we introduce the concept of Dynamic Point Maps (DPM), extending standard point maps to support 4D tasks such as motion segmentation, scene flow estimation, 3D object tracking, and 2D correspondence. Our key intuition is that, when time is introduced, there are several possible spatial and time references that can be used to define the point maps. We identify a minimal subset of such combinations that can be regressed by a network to solve the sub tasks mentioned above. We train a DPM predictor on a mixture of synthetic and real data and evaluate it across diverse benchmarks for video depth prediction, dynamic point cloud reconstruction, 3D scene flow and object pose tracking, achieving state-of-the-art performance. Code, models and additional results are available at https://www.robots.ox.ac.uk/~vgg/research/dynamic-point-maps/.
Amodal3R: Amodal 3D Reconstruction from Occluded 2D Images
Mar 17, 2025Most image-based 3D object reconstructors assume that objects are fully visible, ignoring occlusions that commonly occur in real-world scenarios. In this paper, we introduce Amodal3R, a conditional 3D generative model designed to reconstruct 3D objects from partial observations. We start from a "foundation" 3D generative model and extend it to recover plausible 3D geometry and appearance from occluded objects. We introduce a mask-weighted multi-head cross-attention mechanism followed by an occlusion-aware attention layer that explicitly leverages occlusion priors to guide the reconstruction process. We demonstrate that, by training solely on synthetic data, Amodal3R learns to recover full 3D objects even in the presence of occlusions in real scenes. It substantially outperforms existing methods that independently perform 2D amodal completion followed by 3D reconstruction, thereby establishing a new benchmark for occlusion-aware 3D reconstruction.
VGGT: Visual Geometry Grounded Transformer
Mar 14, 2025



We present VGGT, a feed-forward neural network that directly infers all key 3D attributes of a scene, including camera parameters, point maps, depth maps, and 3D point tracks, from one, a few, or hundreds of its views. This approach is a step forward in 3D computer vision, where models have typically been constrained to and specialized for single tasks. It is also simple and efficient, reconstructing images in under one second, and still outperforming alternatives that require post-processing with visual geometry optimization techniques. The network achieves state-of-the-art results in multiple 3D tasks, including camera parameter estimation, multi-view depth estimation, dense point cloud reconstruction, and 3D point tracking. We also show that using pretrained VGGT as a feature backbone significantly enhances downstream tasks, such as non-rigid point tracking and feed-forward novel view synthesis. Code and models are publicly available at https://github.com/facebookresearch/vggt.
Twinner: Shining Light on Digital Twins in a Few Snaps
Mar 11, 2025



We present the first large reconstruction model, Twinner, capable of recovering a scene's illumination as well as an object's geometry and material properties from only a few posed images. Twinner is based on the Large Reconstruction Model and innovates in three key ways: 1) We introduce a memory-efficient voxel-grid transformer whose memory scales only quadratically with the size of the voxel grid. 2) To deal with scarcity of high-quality ground-truth PBR-shaded models, we introduce a large fully-synthetic dataset of procedurally-generated PBR-textured objects lit with varied illumination. 3) To narrow the synthetic-to-real gap, we finetune the model on real life datasets by means of a differentiable physically-based shading model, eschewing the need for ground-truth illumination or material properties which are challenging to obtain in real life. We demonstrate the efficacy of our model on the real life StanfordORB benchmark where, given few input views, we achieve reconstruction quality significantly superior to existing feedforward reconstruction networks, and comparable to significantly slower per-scene optimization methods.
Learning segmentation from point trajectories
Jan 21, 2025We consider the problem of segmenting objects in videos based on their motion and no other forms of supervision. Prior work has often approached this problem by using the principle of common fate, namely the fact that the motion of points that belong to the same object is strongly correlated. However, most authors have only considered instantaneous motion from optical flow. In this work, we present a way to train a segmentation network using long-term point trajectories as a supervisory signal to complement optical flow. The key difficulty is that long-term motion, unlike instantaneous motion, is difficult to model -- any parametric approximation is unlikely to capture complex motion patterns over long periods of time. We instead draw inspiration from subspace clustering approaches, proposing a loss function that seeks to group the trajectories into low-rank matrices where the motion of object points can be approximately explained as a linear combination of other point tracks. Our method outperforms the prior art on motion-based segmentation, which shows the utility of long-term motion and the effectiveness of our formulation.