 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning segmentation from point trajectories
Jan 21, 2025We consider the problem of segmenting objects in videos based on their motion and no other forms of supervision. Prior work has often approached this problem by using the principle of common fate, namely the fact that the motion of points that belong to the same object is strongly correlated. However, most authors have only considered instantaneous motion from optical flow. In this work, we present a way to train a segmentation network using long-term point trajectories as a supervisory signal to complement optical flow. The key difficulty is that long-term motion, unlike instantaneous motion, is difficult to model -- any parametric approximation is unlikely to capture complex motion patterns over long periods of time. We instead draw inspiration from subspace clustering approaches, proposing a loss function that seeks to group the trajectories into low-rank matrices where the motion of object points can be approximately explained as a linear combination of other point tracks. Our method outperforms the prior art on motion-based segmentation, which shows the utility of long-term motion and the effectiveness of our formulation.
Diffusion Models for Zero-Shot Open-Vocabulary Segmentation
Jun 15, 2023



The variety of objects in the real world is nearly unlimited and is thus impossible to capture using models trained on a fixed set of categories. As a result, in recent years, open-vocabulary methods have attracted the interest of the community. This paper proposes a new method for zero-shot open-vocabulary segmentation. Prior work largely relies on contrastive training using image-text pairs, leveraging grouping mechanisms to learn image features that are both aligned with language and well-localised. This however can introduce ambiguity as the visual appearance of images with similar captions often varies. Instead, we leverage the generative properties of large-scale text-to-image diffusion models to sample a set of support images for a given textual category. This provides a distribution of appearances for a given text circumventing the ambiguity problem. We further propose a mechanism that considers the contextual background of the sampled images to better localise objects and segment the background directly. We show that our method can be used to ground several existing pre-trained self-supervised feature extractors in natural language and provide explainable predictions by mapping back to regions in the support set. Our proposal is training-free, relying on pre-trained components only, yet, shows strong performance on a range of open-vocabulary segmentation benchmarks, obtaining a lead of more than 10% on the Pascal VOC benchmark.
Guess What Moves: Unsupervised Video and Image Segmentation by Anticipating Motion
May 16, 2022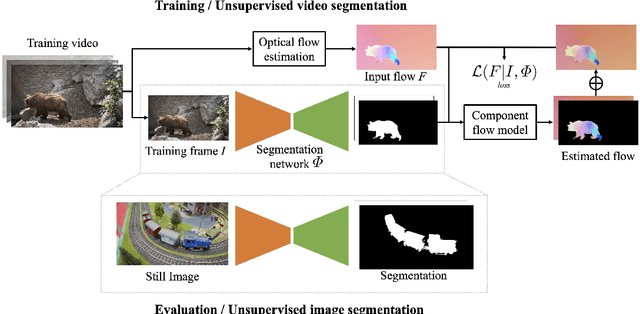
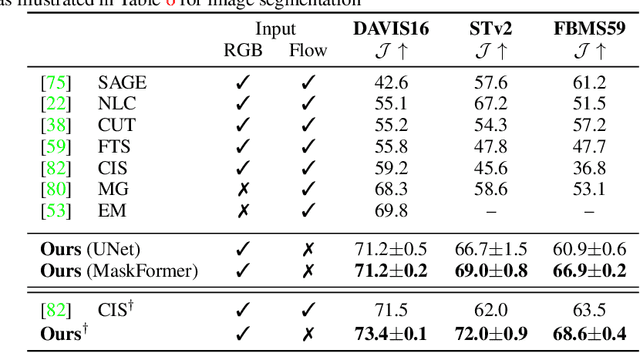

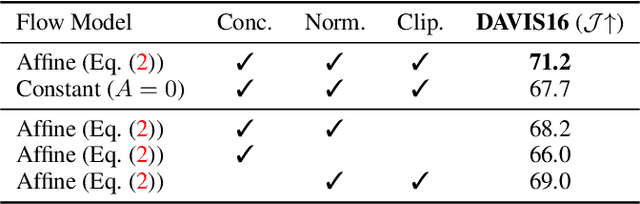
Motion, measured via optical flow, provides a powerful cue to discover and learn objects in images and videos. However, compared to using appearance, it has some blind spots, such as the fact that objects become invisible if they do not move. In this work, we propose an approach that combines the strengths of motion-based and appearance-based segmentation. We propose to supervise an image segmentation network, tasking it with predicting regions that are likely to contain simple motion patterns, and thus likely to correspond to objects. We apply this network in two modes. In the unsupervised video segmentation mode, the network is trained on a collection of unlabelled videos, using the learning process itself as an algorithm to segment these videos. In the unsupervised image segmentation model, the network is learned using videos and applied to segment independent still images. With this, we obtain strong empirical results in unsupervised video and image segmentation, significantly outperforming the state of the art on benchmarks such as DAVIS, sometimes with a $5\%$ IoU gap.
ClevrTex: A Texture-Rich Benchmark for Unsupervised Multi-Object Segmentation
Nov 19, 2021


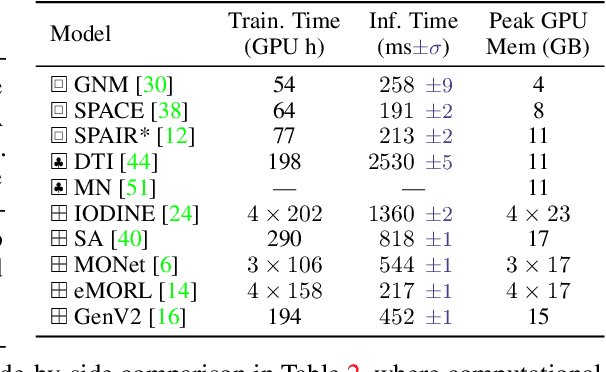
There has been a recent surge in methods that aim to decompose and segment scenes into multiple objects in an unsupervised manner, i.e., unsupervised multi-object segmentation. Performing such a task is a long-standing goal of computer vision, offering to unlock object-level reasoning without requiring dense annotations to train segmentation models. Despite significant progress, current models are developed and trained on visually simple scenes depicting mono-colored objects on plain backgrounds. The natural world, however, is visually complex with confounding aspects such as diverse textures and complicated lighting effects. In this study, we present a new benchmark called ClevrTex, designed as the next challenge to compare, evaluate and analyze algorithms. ClevrTex features synthetic scenes with diverse shapes, textures and photo-mapped materials, created using physically based rendering techniques. It includes 50k examples depicting 3-10 objects arranged on a background, created using a catalog of 60 materials, and a further test set featuring 10k images created using 25 different materials. We benchmark a large set of recent unsupervised multi-object segmentation models on ClevrTex and find all state-of-the-art approaches fail to learn good representations in the textured setting, despite impressive performance on simpler data. We also create variants of the ClevrTex dataset, controlling for different aspects of scene complexity, and probe current approaches for individual shortcomings. Dataset and code are available at https://www.robots.ox.ac.uk/~vgg/research/clevrtex.
Automatic Inference of Cross-modal Connection Topologies for X-CNNs
May 02, 2018
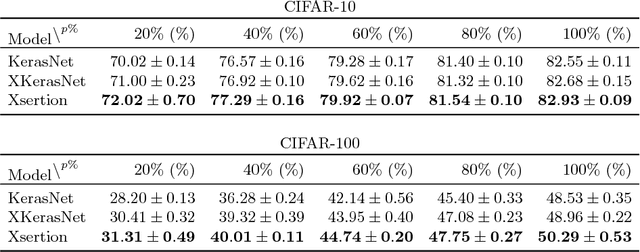
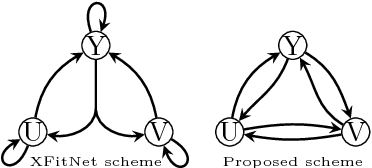
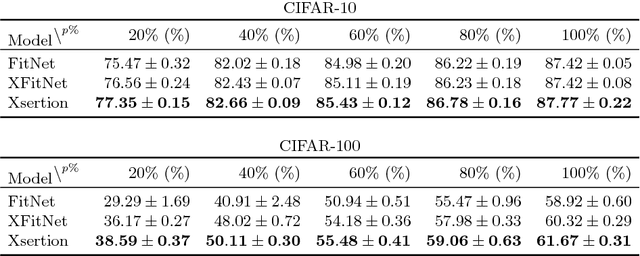
This paper introduces a way to learn cross-modal convolutional neural network (X-CNN) architectures from a base convolutional network (CNN) and the training data to reduce the design cost and enable applying cross-modal networks in sparse data environments. Two approaches for building X-CNNs are presented. The base approach learns the topology in a data-driven manner, by using measurements performed on the base CNN and supplied data. The iterative approach performs further optimisation of the topology through a combined learning procedure, simultaneously learning the topology and training the network. The approaches were evaluated agains examples of hand-designed X-CNNs and their base variants, showing superior performance and, in some cases, gaining an additional 9% of accuracy. From further considerations, we conclude that the presented methodology takes less time than any manual approach would, whilst also significantly reducing the design complexity. The application of the methods is fully automated and implemented in Xsertion library.
Cross-modal Recurrent Models for Weight Objective Prediction from Multimodal Time-series Data
Nov 29, 2017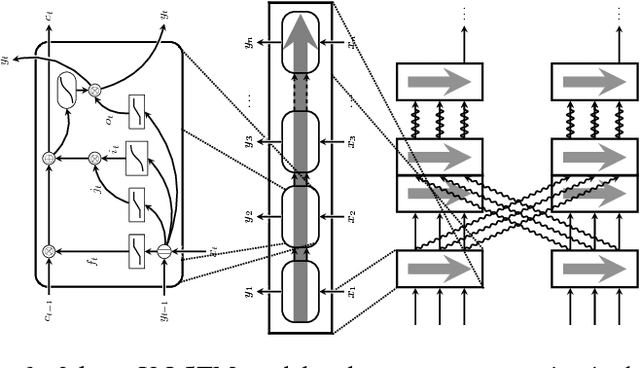
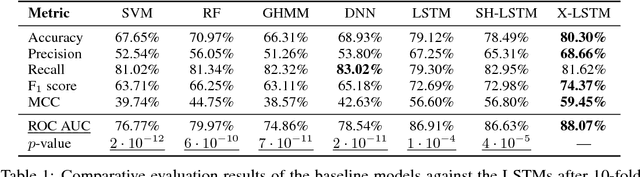
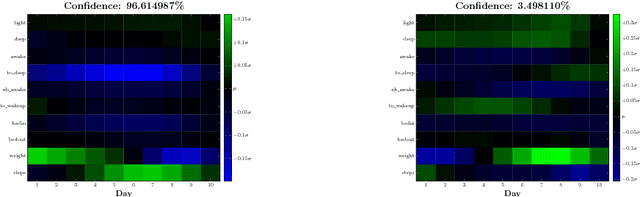

We analyse multimodal time-series data corresponding to weight, sleep and steps measurements. We focus on predicting whether a user will successfully achieve his/her weight objective. For this, we design several deep long short-term memory (LSTM) architectures, including a novel cross-modal LSTM (X-LSTM), and demonstrate their superiority over baseline approaches. The X-LSTM improves parameter efficiency by processing each modality separately and allowing for information flow between them by way of recurrent cross-connections. We present a general hyperparameter optimisation technique for X-LSTMs, which allows us to significantly improve on the LSTM and a prior state-of-the-art cross-modal approach, using a comparable number of parameters. Finally, we visualise the model's predictions, revealing implications about latent variables in this task.