 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOVE: Learning Deformable 3D Objects by Watching Videos
Jul 22, 2021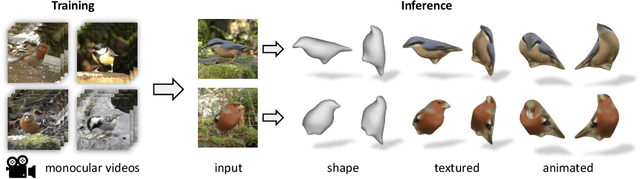
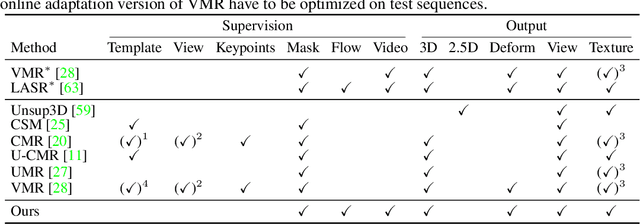
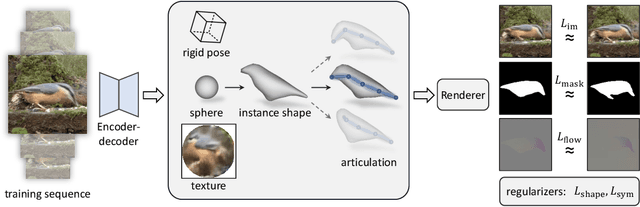
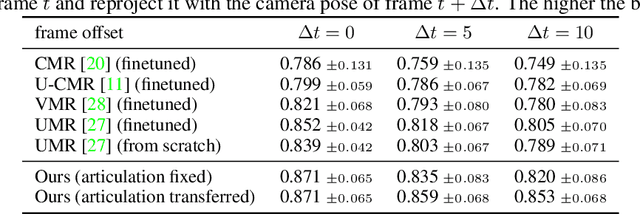
Learning deformable 3D objects from 2D images is an extremely ill-posed problem. Existing methods rely on explicit supervision to establish multi-view correspondences, such as template shape models and keypoint annotations, which restricts their applicability on objects "in the wild". In this paper, we propose to use monocular videos, which naturally provide correspondences across time, allowing us to learn 3D shapes of deformable object categories without explicit keypoints or template shapes. Specifically, we present DOVE, which learns to predict 3D canonical shape, deformation, viewpoint and texture from a single 2D image of a bird, given a bird video collection as well as automatically obtained silhouettes and optical flows as training data. Our method reconstructs temporally consistent 3D shape and deformation, which allows us to animate and re-render the bird from arbitrary viewpoints from a single image.
AutoNovel: Automatically Discovering and Learning Novel Visual Categories
Jun 29, 2021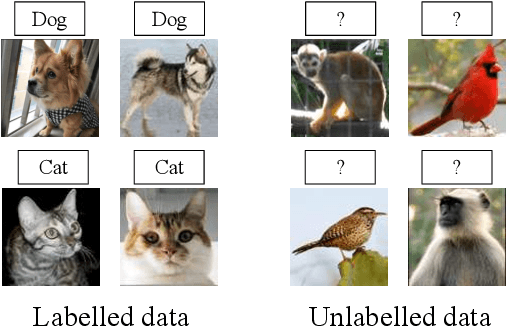
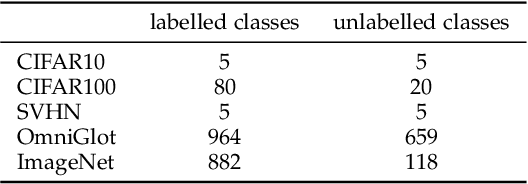

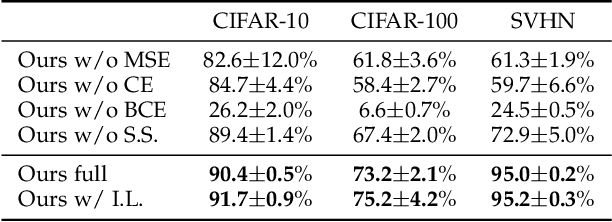
We tackle the problem of discovering novel classes in an image collection given labelled examples of other classes. We present a new approach called AutoNovel to address this problem by combining three ideas: (1) we suggest that the common approach of bootstrapping an image representation using the labelled data only introduces an unwanted bias, and that this can be avoided by using self-supervised learning to train the representation from scratch on the union of labelled and unlabelled data; (2) we use ranking statistics to transfer the model's knowledge of the labelled classes to the problem of clustering the unlabelled images; and, (3) we train the data representation by optimizing a joint objective function on the labelled and unlabelled subsets of the data, improving both the supervised classification of the labelled data, and the clustering of the unlabelled data. Moreover, we propose a method to estimate the number of classes for the case where the number of new categories is not known a priori. We evaluate AutoNovel on standard classification benchmarks and substantially outperform current methods for novel category discovery. In addition, we also show that AutoNovel can be used for fully unsupervised image clustering, achieving promising results.
Discovering Relationships between Object Categories via Universal Canonical Maps
Jun 17, 2021



We tackle the problem of learning the geometry of multiple categories of deformable objects jointly. Recent work has shown that it is possible to learn a unified dense pose predictor for several categories of related objects. However, training such models requires to initialize inter-category correspondences by hand. This is suboptimal and the resulting models fail to maintain correct correspondences as individual categories are learned. In this paper, we show that improved correspondences can be learned automatically as a natural byproduct of learning category-specific dense pose predictors. To do this, we express correspondences between different categories and between images and categories using a unified embedding. Then, we use the latter to enforce two constraints: symmetric inter-category cycle consistency and a new asymmetric image-to-category cycle consistency. Without any manual annotations for the inter-category correspondences, we obtain state-of-the-art alignment results, outperforming dedicated methods for matching 3D shapes. Moreover, the new model is also better at the task of dense pose prediction than prior work.
NeuroMorph: Unsupervised Shape Interpolation and Correspondence in One Go
Jun 17, 2021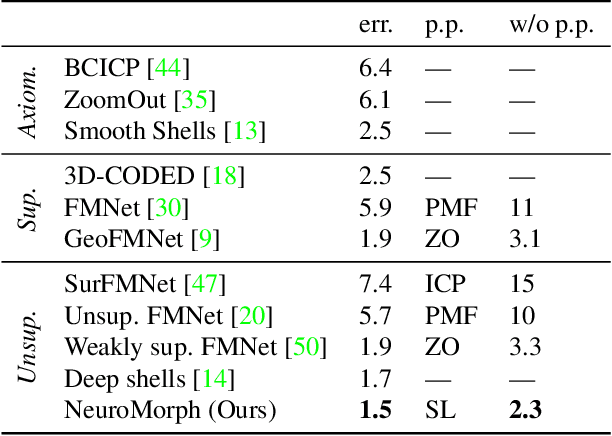
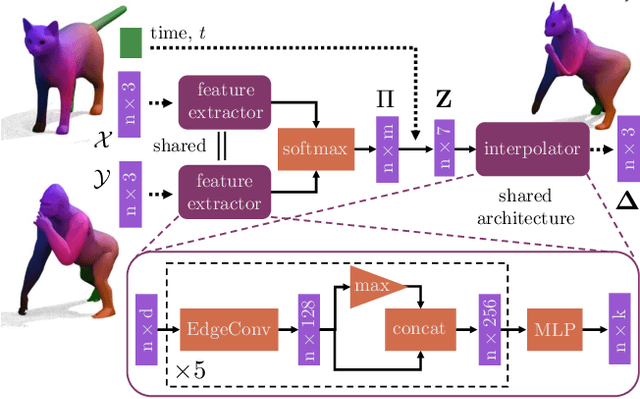
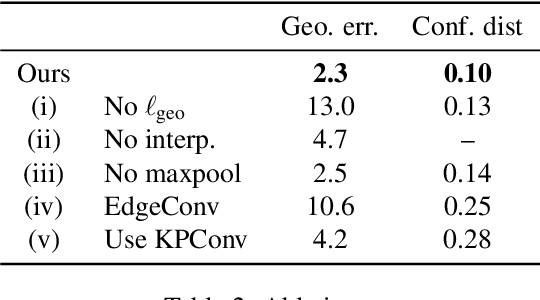
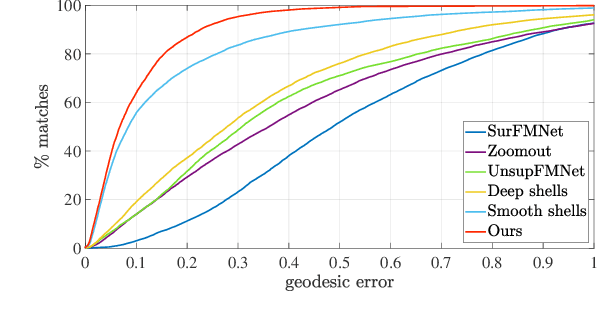
We present NeuroMorph, a new neural network architecture that takes as input two 3D shapes and produces in one go, i.e. in a single feed forward pass, a smooth interpolation and point-to-point correspondences between them. The interpolation, expressed as a deformation field, changes the pose of the source shape to resemble the target, but leaves the object identity unchanged. NeuroMorph uses an elegant architecture combining graph convolutions with global feature pooling to extract local features. During training, the model is incentivized to create realistic deformations by approximating geodesics on the underlying shape space manifold. This strong geometric prior allows to train our model end-to-end and in a fully unsupervised manner without requiring any manual correspondence annotations. NeuroMorph works well for a large variety of input shapes, including non-isometric pairs from different object categories. It obtains state-of-the-art results for both shape correspondence and interpolation tasks, matching or surpassing the performance of recent unsupervised and supervised methods on multiple benchmarks.
Predicting Unreliable Predictions by Shattering a Neural Network
Jun 15, 2021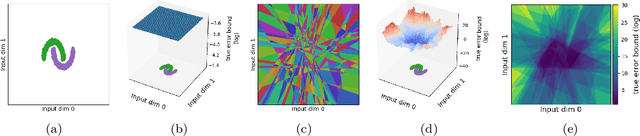
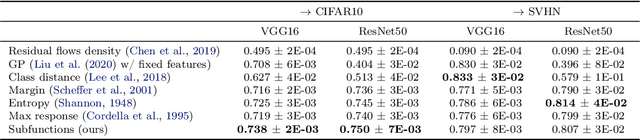
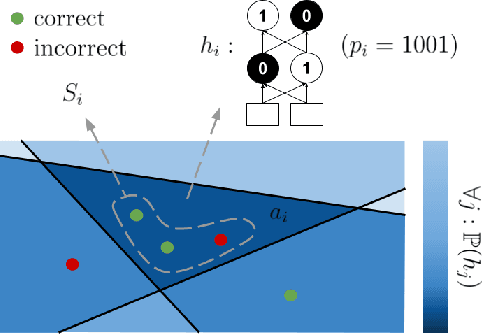

Piecewise linear neural networks can be split into subfunctions, each with its own activation pattern, domain, and empirical error. Empirical error for the full network can be written as an expectation over empirical error of subfunctions. Constructing a generalization bound on subfunction empirical error indicates that the more densely a subfunction is surrounded by training samples in representation space, the more reliable its predictions are. Further, it suggests that models with fewer activation regions generalize better, and models that abstract knowledge to a greater degree generalize better, all else equal. We propose not only a theoretical framework to reason about subfunction error bounds but also a pragmatic way of approximately evaluating it, which we apply to predicting which samples the network will not successfully generalize to. We test our method on detection of misclassification and out-of-distribution samples, finding that it performs competitively in both cases. In short, some network activation patterns are associated with higher reliability than others, and these can be identified using subfunction error bounds.
Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers
Jun 09, 2021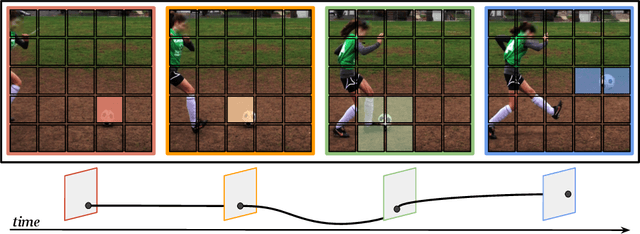

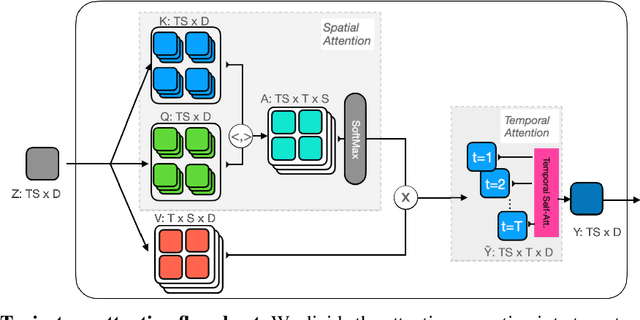
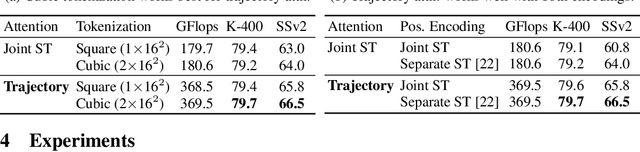
In video transformers, the time dimension is often treated in the same way as the two spatial dimensions. However, in a scene where objects or the camera may move, a physical point imaged at one location in frame $t$ may be entirely unrelated to what is found at that location in frame $t+k$. These temporal correspondences should be modeled to facilitate learning about dynamic scenes. To this end, we propose a new drop-in block for video transformers -- trajectory attention -- that aggregates information along implicitly determined motion paths. We additionally propose a new method to address the quadratic dependence of computation and memory on the input size, which is particularly important for high resolution or long videos. While these ideas are useful in a range of settings, we apply them to the specific task of video action recognition with a transformer model and obtain state-of-the-art results on the Kinetics, Something--Something V2, and Epic-Kitchens datasets. Code and models are available at: https://github.com/facebookresearch/Motionformer
Moving SLAM: Fully Unsupervised Deep Learning in Non-Rigid Scenes
Jun 01, 2021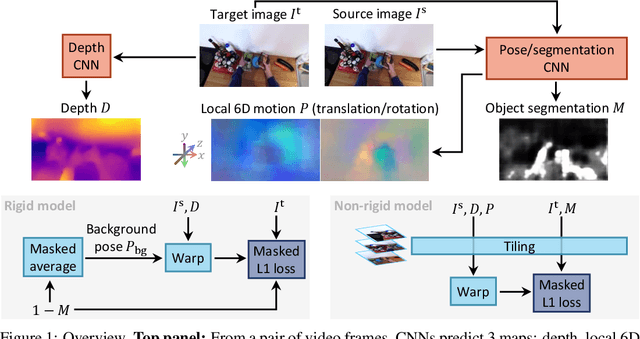
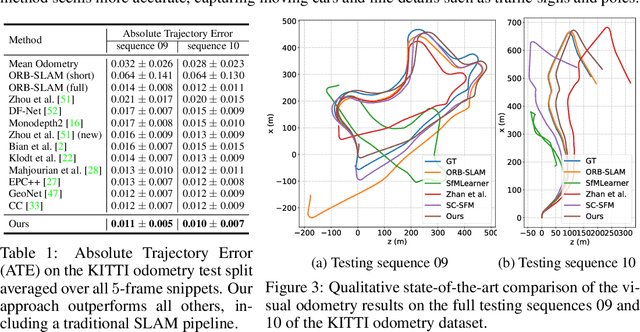
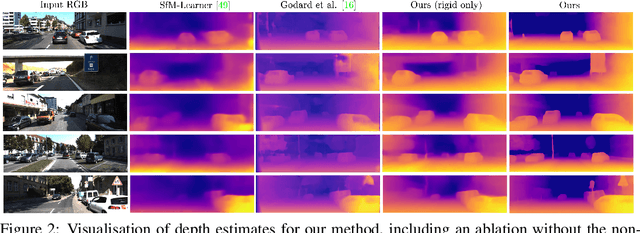
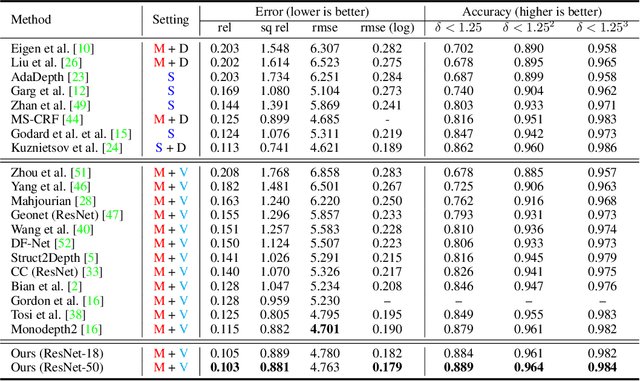
We propose a method to train deep networks to decompose videos into 3D geometry (camera and depth), moving objects, and their motions, with no supervision. We build on the idea of view synthesis, which uses classical camera geometry to re-render a source image from a different point-of-view, specified by a predicted relative pose and depth map. By minimizing the error between the synthetic image and the corresponding real image in a video, the deep network that predicts pose and depth can be trained completely unsupervised. However, the view synthesis equations rely on a strong assumption: that objects do not move. This rigid-world assumption limits the predictive power, and rules out learning about objects automatically. We propose a simple solution: minimize the error on small regions of the image instead. While the scene as a whole may be non-rigid, it is always possible to find small regions that are approximately rigid, such as inside a moving object. Our network can then predict different poses for each region, in a sliding window from a learned dense pose map. This represents a significantly richer model, including 6D object motions, with little additional complexity. We achieve very competitive performance on unsupervised odometry and depth prediction on KITTI. We also demonstrate new capabilities on EPIC-Kitchens, a challenging dataset of indoor videos, where there is no ground truth information for depth, odometry, object segmentation or motion. Yet all are recovered automatically by our method.
Finding an Unsupervised Image Segmenter in Each of Your Deep Generative Models
May 17, 2021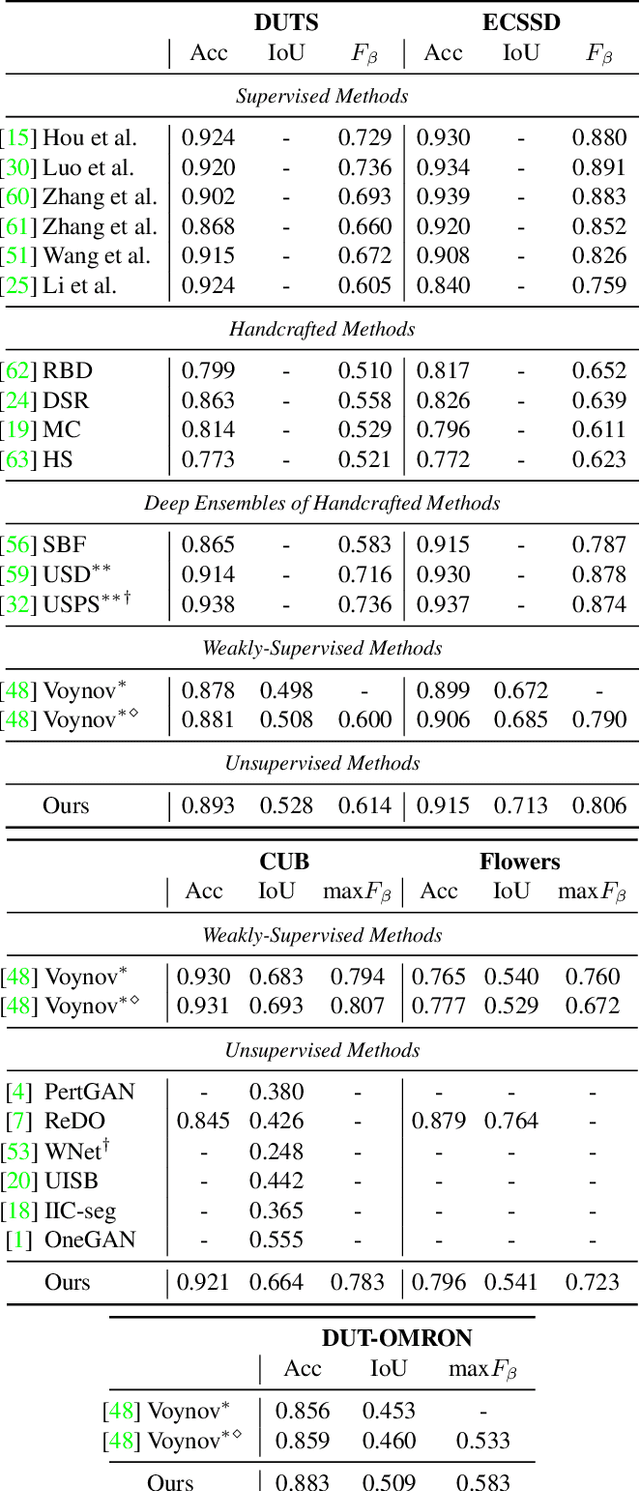
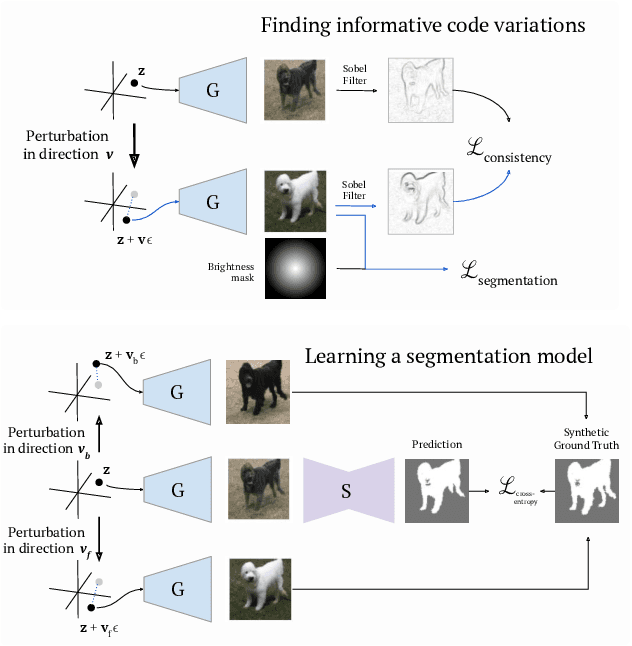
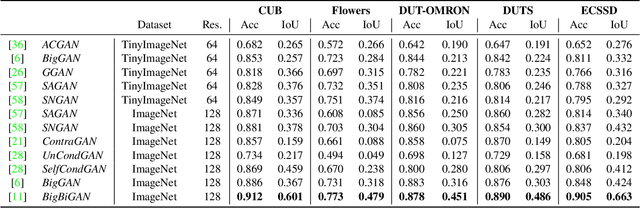

Recent research has shown that numerous human-interpretable directions exist in the latent space of GANs. In this paper, we develop an automatic procedure for finding directions that lead to foreground-background image separation, and we use these directions to train an image segmentation model without human supervision. Our method is generator-agnostic, producing strong segmentation results with a wide range of different GAN architectures. Furthermore, by leveraging GANs pretrained on large datasets such as ImageNet, we are able to segment images from a range of domains without further training or finetuning. Evaluating our method on image segmentation benchmarks, we compare favorably to prior work while using neither human supervision nor access to the training data. Broadly, our results demonstrate that automatically extracting foreground-background structure from pretrained deep generative models can serve as a remarkably effective substitute for human supervision.
Self-supervised object detection from audio-visual correspondence
Apr 13, 2021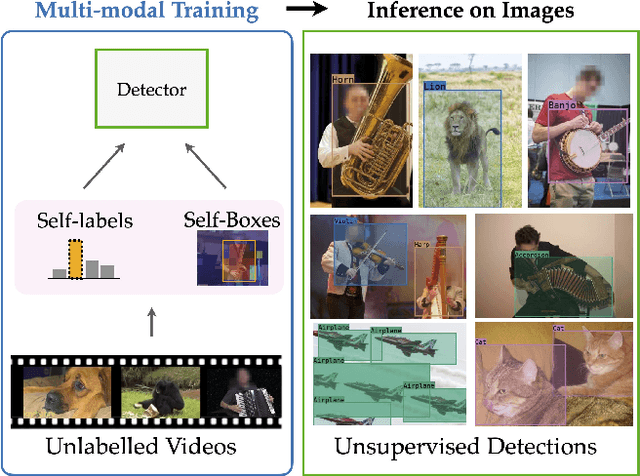
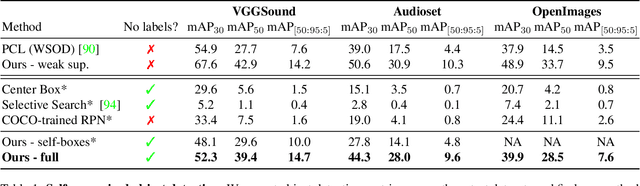
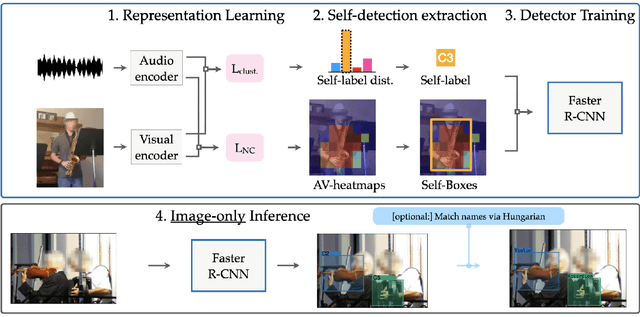
We tackle the problem of learning object detectors without supervision. Differently from weakly-supervised object detection, we do not assume image-level class labels. Instead, we extract a supervisory signal from audio-visual data, using the audio component to "teach" the object detector. While this problem is related to sound source localisation, it is considerably harder because the detector must classify the objects by type, enumerate each instance of the object, and do so even when the object is silent. We tackle this problem by first designing a self-supervised framework with a contrastive objective that jointly learns to classify and localise objects. Then, without using any supervision, we simply use these self-supervised labels and boxes to train an image-based object detector. With this, we outperform previous unsupervised and weakly-supervised detectors for the task of object detection and sound source localization. We also show that we can align this detector to ground-truth classes with as little as one label per pseudo-class, and show how our method can learn to detect generic objects that go beyond instruments, such as airplanes and cats.
Localizing Visual Sounds the Hard Way
Apr 06, 2021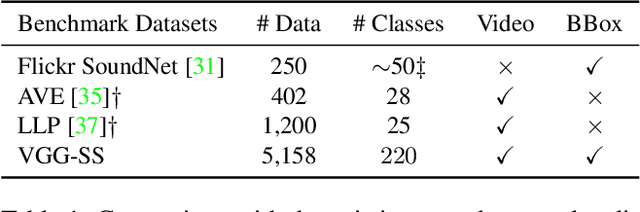
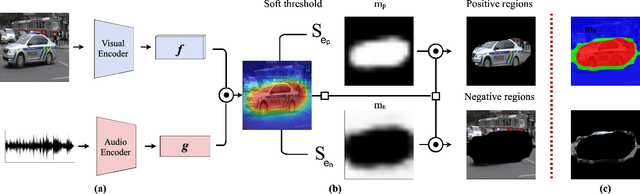

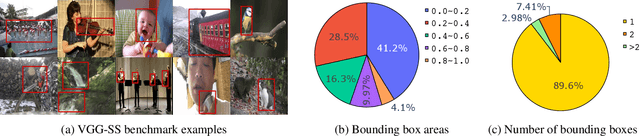
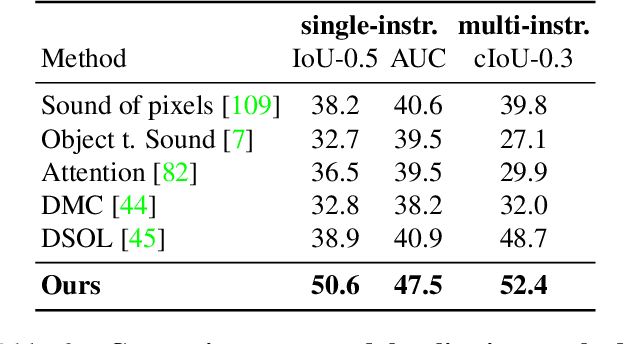
The objective of this work is to localize sound sources that are visible in a video without using manual annotations. Our key technical contribution is to show that, by training the network to explicitly discriminate challenging image fragments, even for images that do contain the object emitting the sound, we can significantly boost the localization performance. We do so elegantly by introducing a mechanism to mine hard samples and add them to a contrastive learning formulation automatically. We show that our algorithm achieves state-of-the-art performance on the popular Flickr SoundNet dataset. Furthermore, we introduce the VGG-Sound Source (VGG-SS) benchmark, a new set of annotations for the recently-introduced VGG-Sound dataset, where the sound sources visible in each video clip are explicitly marked with bounding box annotations. This dataset is 20 times larger than analogous existing ones, contains 5K videos spanning over 200 categories, and, differently from Flickr SoundNet, is video-based. On VGG-SS, we also show that our algorithm achieves state-of-the-art performance against several baselines.