 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Dialogue State Tracking via Cross-Task Transfer
Sep 10, 2021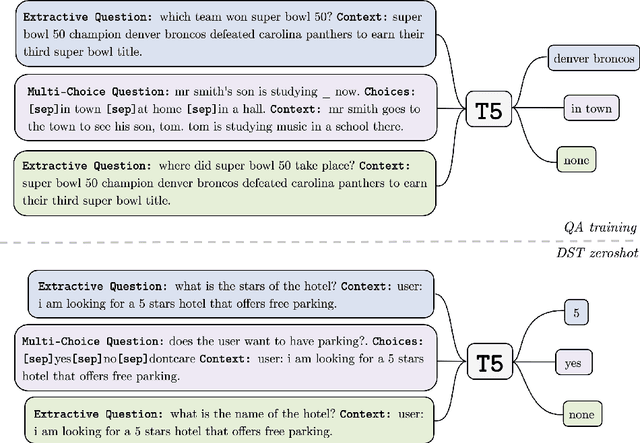
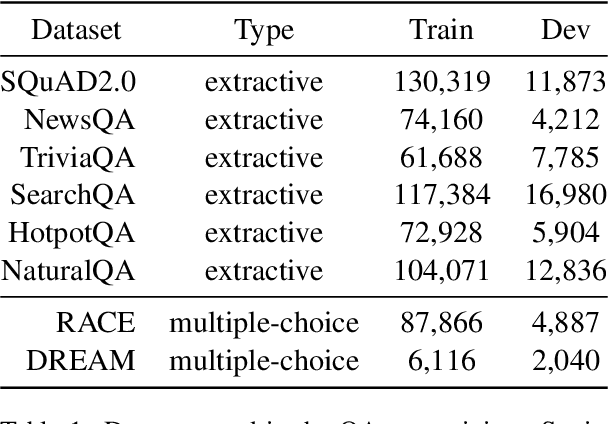
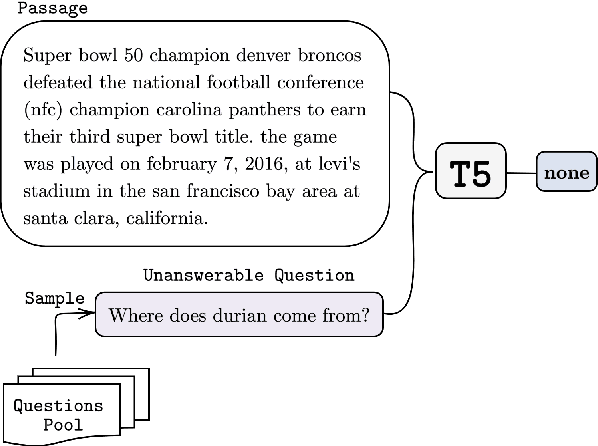
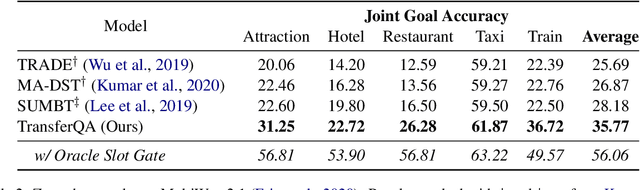
Zero-shot transfer learning for dialogue state tracking (DST) enables us to handle a variety of task-oriented dialogue domains without the expense of collecting in-domain data. In this work, we propose to transfer the \textit{cross-task} knowledge from general question answering (QA) corpora for the zero-shot DST task. Specifically, we propose TransferQA, a transferable generative QA model that seamlessly combines extractive QA and multi-choice QA via a text-to-text transformer framework, and tracks both categorical slots and non-categorical slots in DST. In addition, we introduce two effective ways to construct unanswerable questions, namely, negative question sampling and context truncation, which enable our model to handle "none" value slots in the zero-shot DST setting. The extensive experiments show that our approaches substantially improve the existing zero-shot and few-shot results on MultiWoz. Moreover, compared to the fully trained baseline on the Schema-Guided Dialogue dataset, our approach shows better generalization ability in unseen domains.
Taming the Beast: Learning to Control Neural Conversational Models
Aug 24, 2021
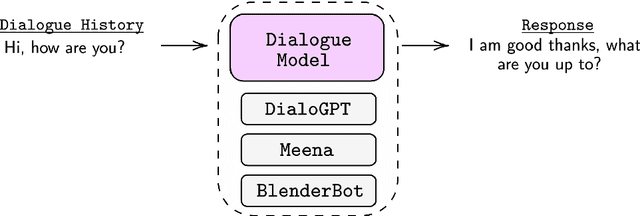
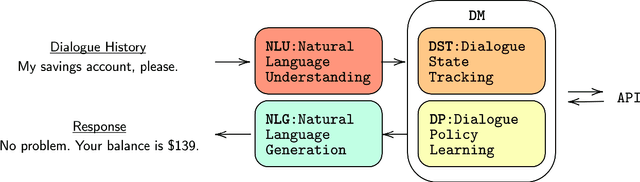
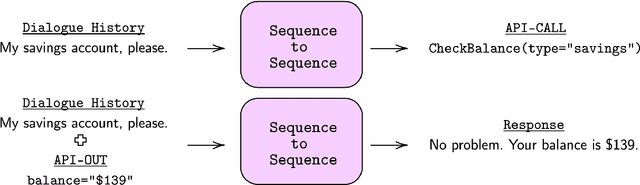
This thesis investigates the controllability of deep learning-based, end-to-end, generative dialogue systems in both task-oriented and chit-chat scenarios. In particular, we study the different aspects of controlling generative dialogue systems, including controlling styles and topics and continuously adding and combining dialogue skills. In the three decades since the first dialogue system was commercialized, the basic architecture of such systems has remained substantially unchanged, consisting of four pipelined basic components, namely, natural language understanding (NLU), dialogue state tracking (DST), a dialogue manager (DM) and natural language generation (NLG). The dialogue manager, which is the critical component of the modularized system, controls the response content and style. This module is usually programmed by rules and is designed to be highly controllable and easily extendable. With the emergence of powerful "deep learning" architectures, end-to-end generative dialogue systems have been proposed to optimize overall system performance and simplify training. However, these systems cannot be easily controlled and extended as the modularized dialogue manager can. This is because a single neural system is used, which is usually a large pre-trained language model (e.g., GPT-2), and thus it is hard to surgically change desirable attributes (e.g., style, topics, etc.). More importantly, uncontrollable dialogue systems can generate offensive and even toxic responses. Therefore, in this thesis, we study controllable methods for end-to-end generative dialogue systems in task-oriented and chit-chat scenarios. Throughout the chapters, we describe 1) how to control the style and topics of chit-chat models, 2) how to continuously control and extend task-oriented dialogue systems, and 3) how to compose and control multi-skill dialogue models.
Assessing Political Prudence of Open-domain Chatbots
Jun 11, 2021

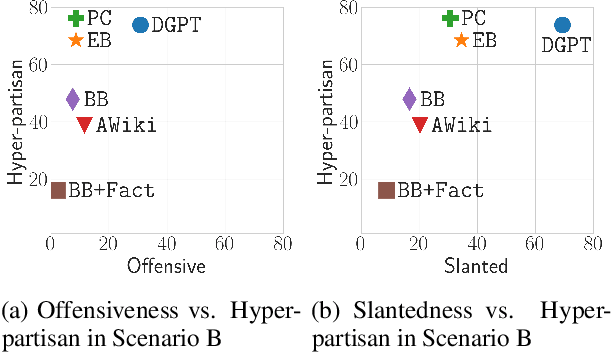
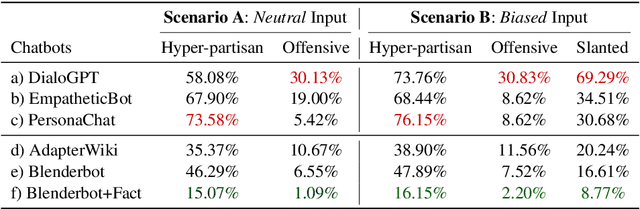
Politically sensitive topics are still a challenge for open-domain chatbots. However, dealing with politically sensitive content in a responsible, non-partisan, and safe behavior way is integral for these chatbots. Currently, the main approach to handling political sensitivity is by simply changing such a topic when it is detected. This is safe but evasive and results in a chatbot that is less engaging. In this work, as a first step towards a politically safe chatbot, we propose a group of metrics for assessing their political prudence. We then conduct political prudence analysis of various chatbots and discuss their behavior from multiple angles through our automatic metric and human evaluation metrics. The testsets and codebase are released to promote research in this area.
CAiRE in DialDoc21: Data Augmentation for Information-Seeking Dialogue System
Jun 08, 2021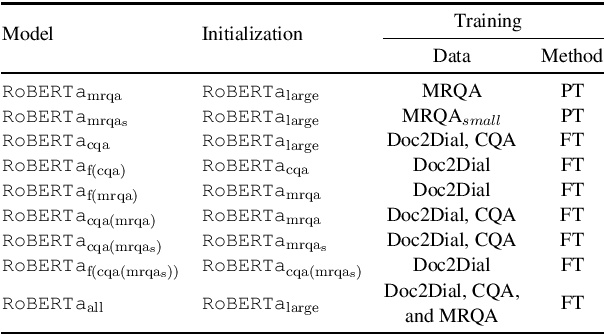
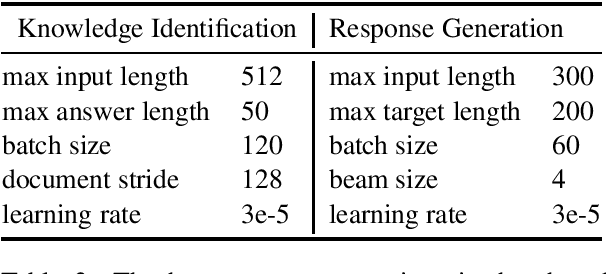
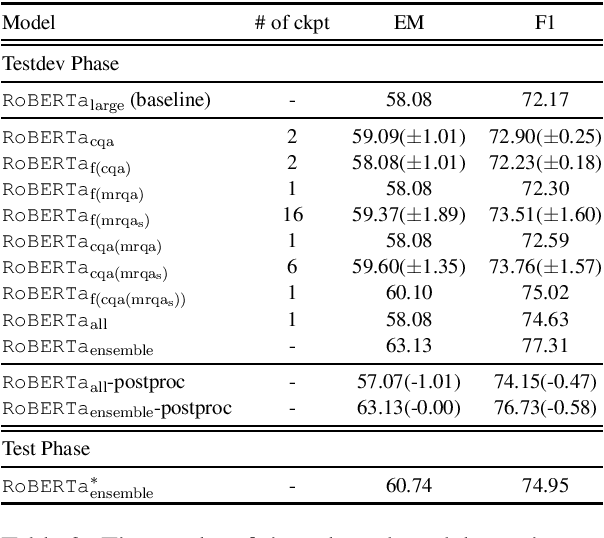
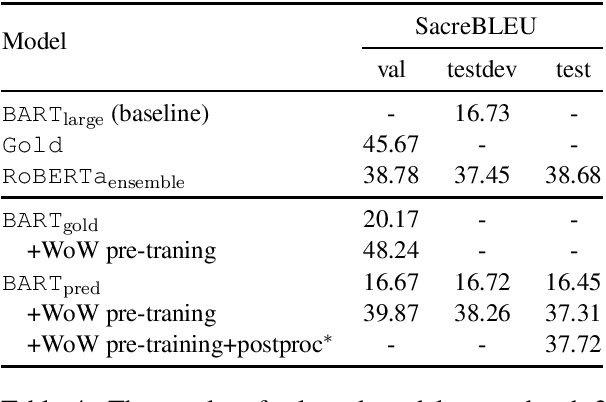
Information-seeking dialogue systems, including knowledge identification and response generation, aim to respond to users with fluent, coherent, and informative responses based on users' needs, which. To tackle this challenge, we utilize data augmentation methods and several training techniques with the pre-trained language models to learn a general pattern of the task and thus achieve promising performance. In DialDoc21 competition, our system achieved 74.95 F1 score and 60.74 Exact Match score in subtask 1, and 37.72 SacreBLEU score in subtask 2. Empirical analysis is provided to explain the effectiveness of our approaches.
BiToD: A Bilingual Multi-Domain Dataset For Task-Oriented Dialogue Modeling
Jun 05, 2021
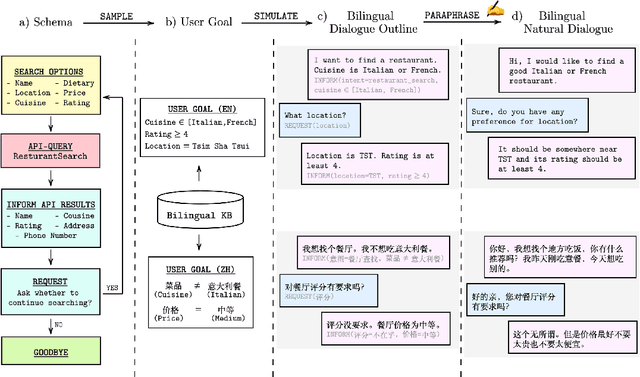
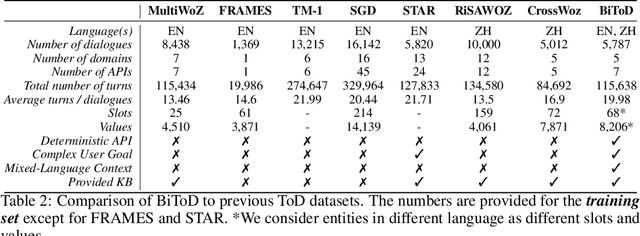
Task-oriented dialogue (ToD) benchmarks provide an important avenue to measure progress and develop better conversational agents. However, existing datasets for end-to-end ToD modeling are limited to a single language, hindering the development of robust end-to-end ToD systems for multilingual countries and regions. Here we introduce BiToD, the first bilingual multi-domain dataset for end-to-end task-oriented dialogue modeling. BiToD contains over 7k multi-domain dialogues (144k utterances) with a large and realistic bilingual knowledge base. It serves as an effective benchmark for evaluating bilingual ToD systems and cross-lingual transfer learning approaches. We provide state-of-the-art baselines under three evaluation settings (monolingual, bilingual, and cross-lingual). The analysis of our baselines in different settings highlights 1) the effectiveness of training a bilingual ToD system compared to two independent monolingual ToD systems, and 2) the potential of leveraging a bilingual knowledge base and cross-lingual transfer learning to improve the system performance under low resource condition.
QAConv: Question Answering on Informative Conversations
May 14, 2021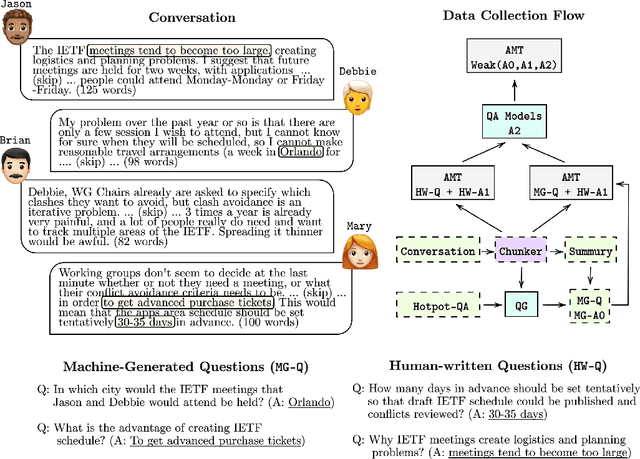
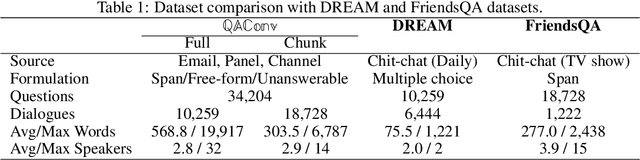
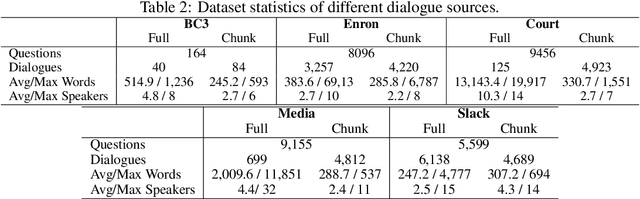
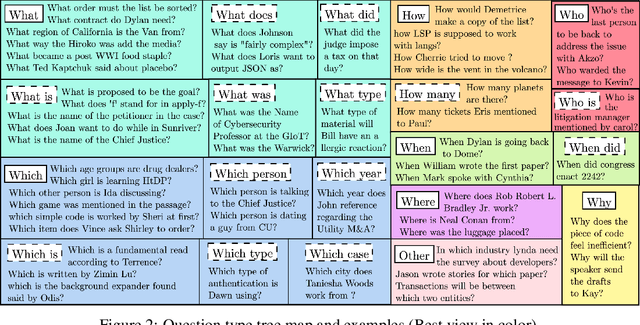
This paper introduces QAConv, a new question answering (QA) dataset that uses conversations as a knowledge source. We focus on informative conversations including business emails, panel discussions, and work channels. Unlike open-domain and task-oriented dialogues, these conversations are usually long, complex, asynchronous, and involve strong domain knowledge. In total, we collect 34,204 QA pairs, including span-based, free-form, and unanswerable questions, from 10,259 selected conversations with both human-written and machine-generated questions. We segment long conversations into chunks, and use a question generator and dialogue summarizer as auxiliary tools to collect multi-hop questions. The dataset has two testing scenarios, chunk mode and full mode, depending on whether the grounded chunk is provided or retrieved from a large conversational pool. Experimental results show that state-of-the-art QA systems trained on existing QA datasets have limited zero-shot ability and tend to predict our questions as unanswerable. Fine-tuning such systems on our corpus can achieve significant improvement up to 23.6% and 13.6% in both chunk mode and full mode, respectively.
Retrieval-Free Knowledge-Grounded Dialogue Response Generation with Adapters
May 13, 2021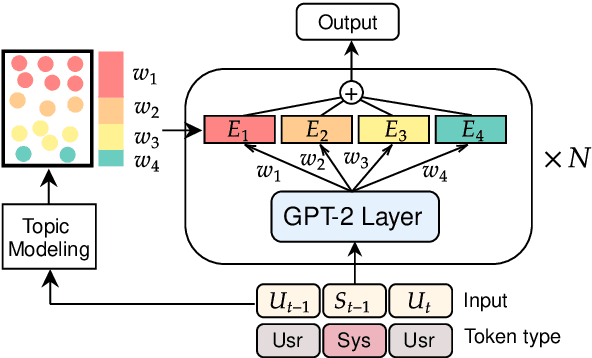
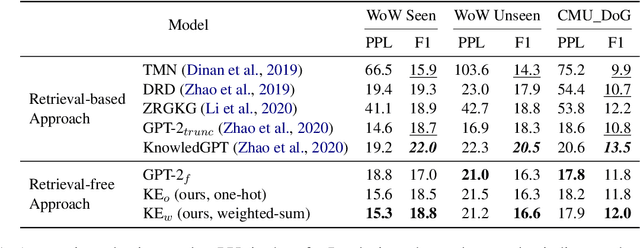
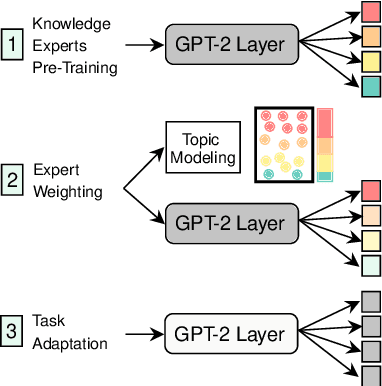

To diversify and enrich generated dialogue responses, knowledge-grounded dialogue has been investigated in recent years. Despite the success of the existing methods, they mainly follow the paradigm of retrieving the relevant sentences over a large corpus and augment the dialogues with explicit extra information, which is time- and resource-consuming. In this paper, we propose KnowExpert, an end-to-end framework to bypass the retrieval process by injecting prior knowledge into the pre-trained language models with lightweight adapters. To the best of our knowledge, this is the first attempt to tackle this task relying solely on a generation-based approach. Experimental results show that KnowExpert performs comparably with the retrieval-based baselines, demonstrating the potential of our proposed direction.
Leveraging Slot Descriptions for Zero-Shot Cross-Domain Dialogue State Tracking
May 10, 2021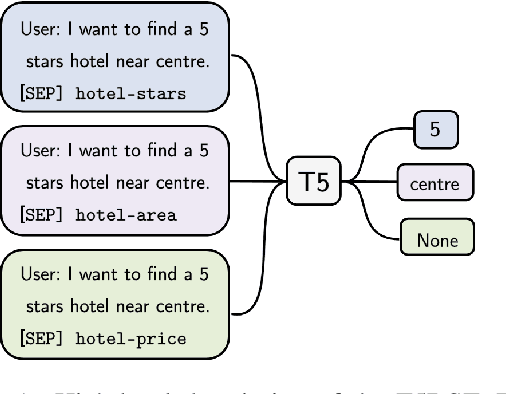

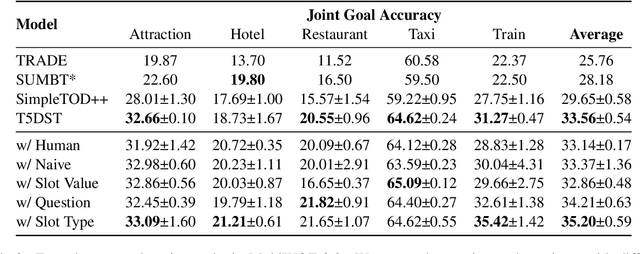
Zero-shot cross-domain dialogue state tracking (DST) enables us to handle task-oriented dialogue in unseen domains without the expense of collecting in-domain data. In this paper, we propose a slot description enhanced generative approach for zero-shot cross-domain DST. Specifically, our model first encodes dialogue context and slots with a pre-trained self-attentive encoder, and generates slot values in an auto-regressive manner. In addition, we incorporate Slot Type Informed Descriptions that capture the shared information across slots to facilitate cross-domain knowledge transfer. Experimental results on the MultiWOZ dataset show that our proposed method significantly improves existing state-of-the-art results in the zero-shot cross-domain setting.
Dynamically Addressing Unseen Rumor via Continual Learning
Apr 18, 2021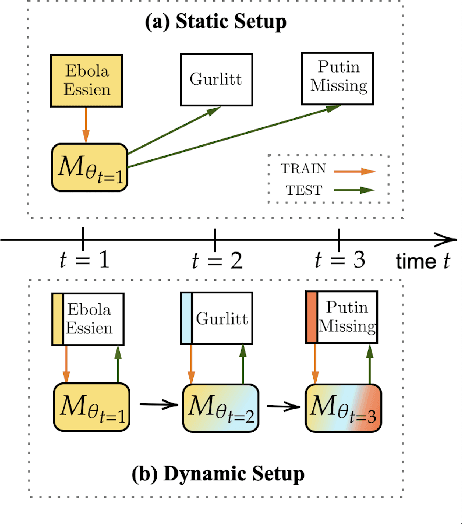
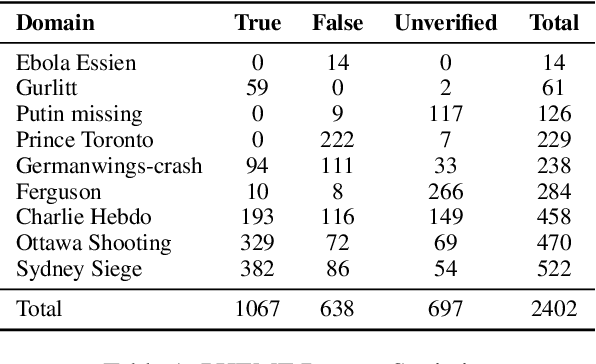
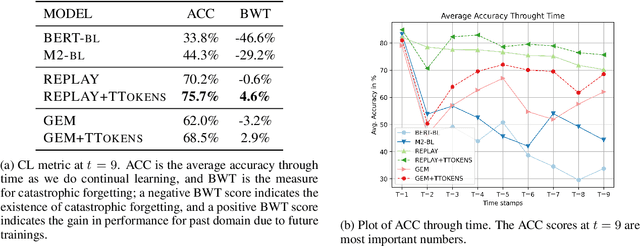
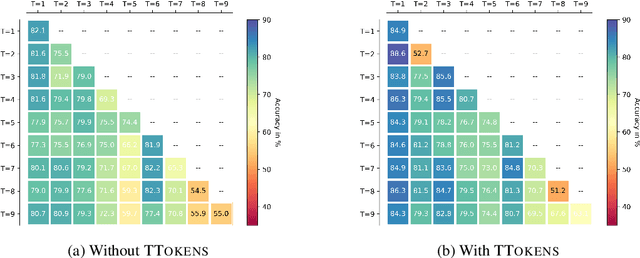
Rumors are often associated with newly emerging events, thus, an ability to deal with unseen rumors is crucial for a rumor veracity classification model. Previous works address this issue by improving the model's generalizability, with an assumption that the model will stay unchanged even after the new outbreak of an event. In this work, we propose an alternative solution to continuously update the model in accordance with the dynamics of rumor domain creations. The biggest technical challenge associated with this new approach is the catastrophic forgetting of previous learnings due to new learnings. We adopt continual learning strategies that control the new learnings to avoid catastrophic forgetting and propose an additional strategy that can jointly be used to strengthen the forgetting alleviation.
Neural Path Hunter: Reducing Hallucination in Dialogue Systems via Path Grounding
Apr 17, 2021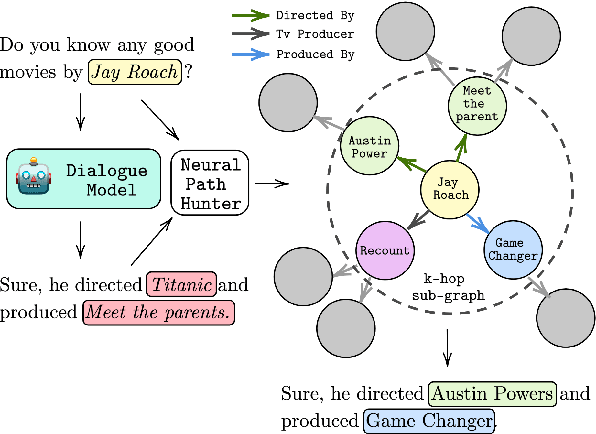
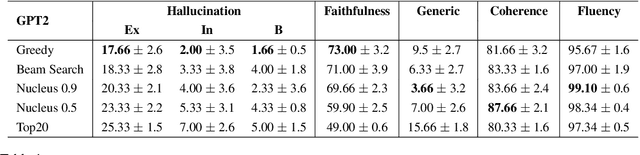
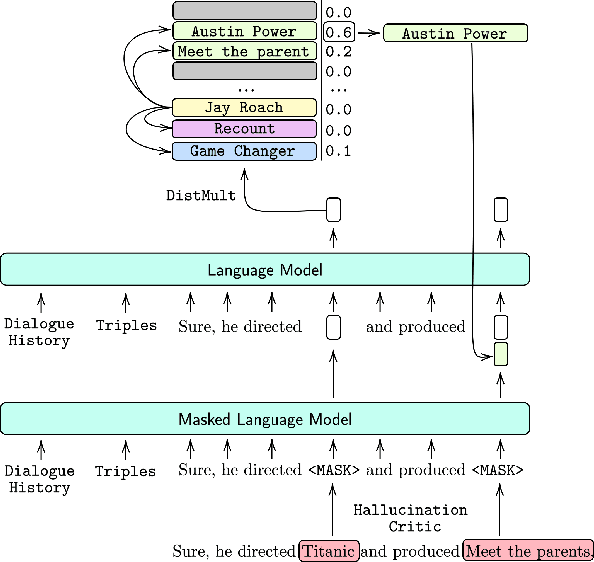
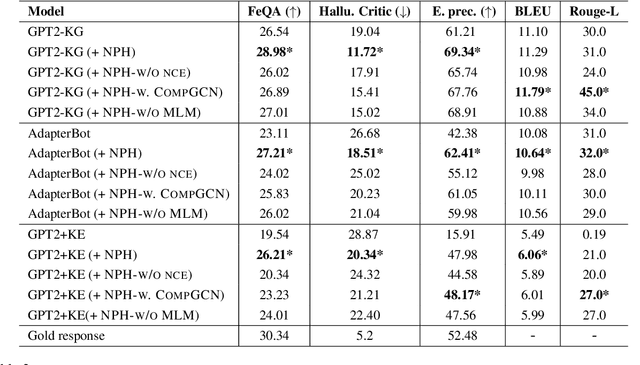
Dialogue systems powered by large pre-trained language models (LM) exhibit an innate ability to deliver fluent and natural-looking responses. Despite their impressive generation performance, these models can often generate factually incorrect statements impeding their widespread adoption. In this paper, we focus on the task of improving the faithfulness -- and thus reduce hallucination -- of Neural Dialogue Systems to known facts supplied by a Knowledge Graph (KG). We propose Neural Path Hunter which follows a generate-then-refine strategy whereby a generated response is amended using the k-hop subgraph of a KG. Neural Path Hunter leverages a separate token-level fact critic to identify plausible sources of hallucination followed by a refinement stage consisting of a chain of two neural LM's that retrieves correct entities by crafting a query signal that is propagated over the k-hop subgraph. Our proposed model can easily be applied to any dialogue generated responses without retraining the model. We empirically validate our proposed approach on the OpenDialKG dataset against a suite of metrics and report a relative improvement of faithfulness over GPT2 dialogue responses by 8.4%.