 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn Parameterized Classification Networks for Scalable Input Images
Jul 13, 2020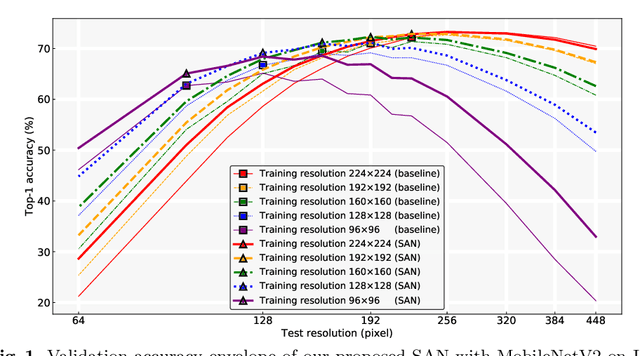
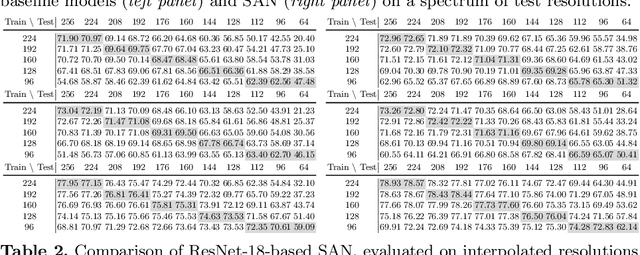
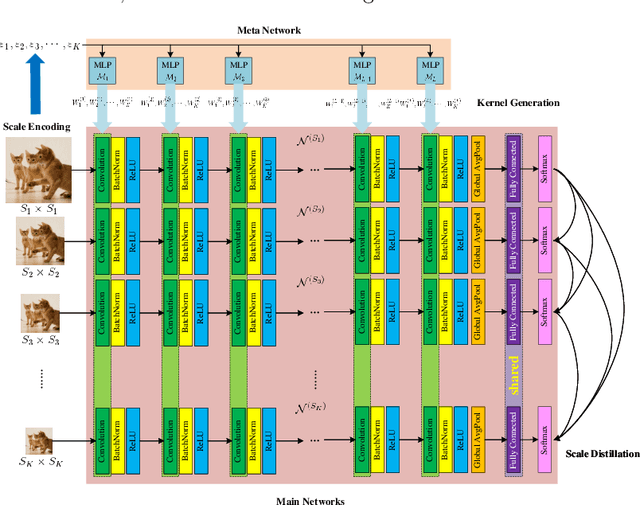

Convolutional Neural Networks (CNNs) do not have a predictable recognition behavior with respect to the input resolution change. This prevents the feasibility of deployment on different input image resolutions for a specific model. To achieve efficient and flexible image classification at runtime, we employ meta learners to generate convolutional weights of main networks for various input scales and maintain privatized Batch Normalization layers per scale. For improved training performance, we further utilize knowledge distillation on the fly over model predictions based on different input resolutions. The learned meta network could dynamically parameterize main networks to act on input images of arbitrary size with consistently better accuracy compared to individually trained models. Extensive experiments on the ImageNet demonstrate that our method achieves an improved accuracy-efficiency trade-off during the adaptive inference process. By switching executable input resolutions, our method could satisfy the requirement of fast adaption in different resource-constrained environments. Code and models are available at https://github.com/d-li14/SAN.
Learning Two-View Correspondences and Geometry Using Order-Aware Network
Aug 14, 2019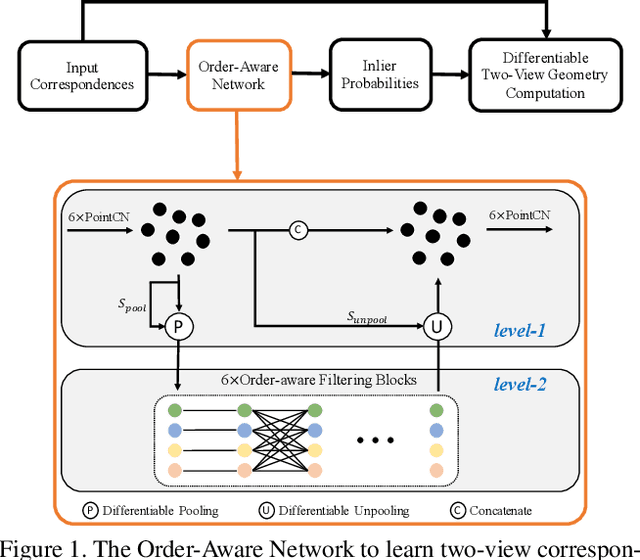
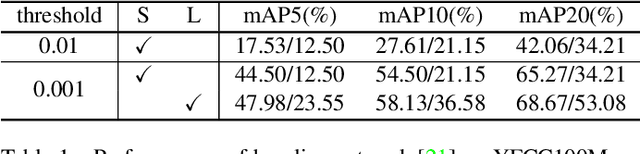
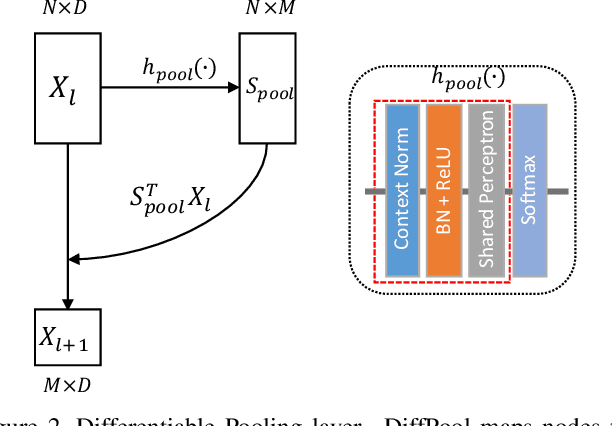
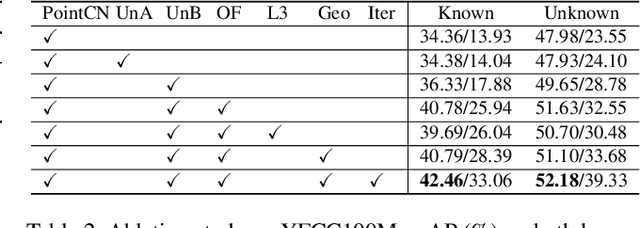
Establishing correspondences between two images requires both local and global spatial context. Given putative correspondences of feature points in two views, in this paper, we propose Order-Aware Network, which infers the probabilities of correspondences being inliers and regresses the relative pose encoded by the essential matrix. Specifically, this proposed network is built hierarchically and comprises three novel operations. First, to capture the local context of sparse correspondences, the network clusters unordered input correspondences by learning a soft assignment matrix. These clusters are in a canonical order and invariant to input permutations. Next, the clusters are spatially correlated to form the global context of correspondences. After that, the context-encoded clusters are recovered back to the original size through a proposed upsampling operator. We intensively experiment on both outdoor and indoor datasets. The accuracy of the two-view geometry and correspondences are significantly improved over the state-of-the-arts. Code will be available at https://github.com/zjhthu/OANet.git.
HBONet: Harmonious Bottleneck on Two Orthogonal Dimensions
Aug 11, 2019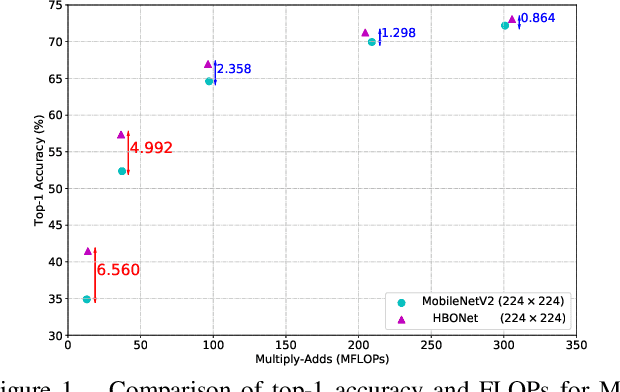
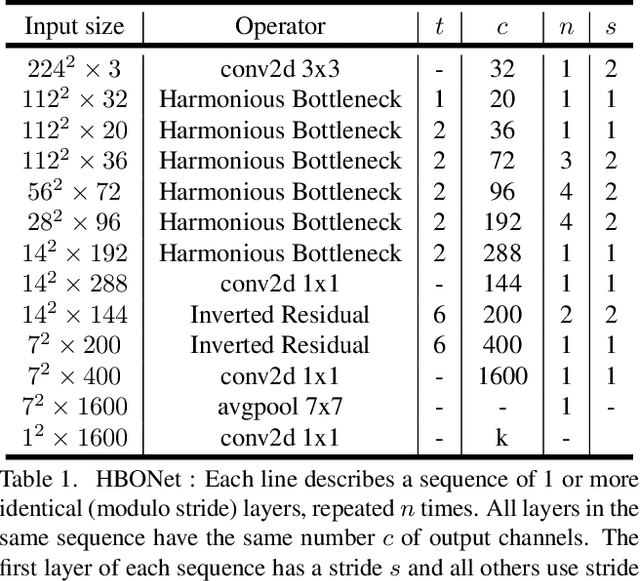
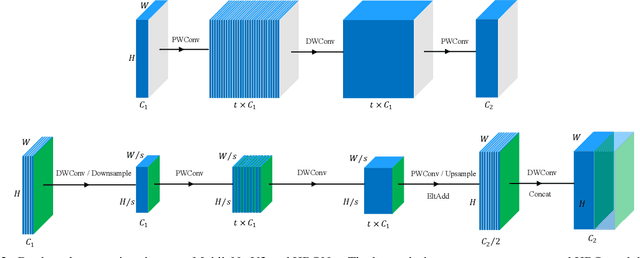
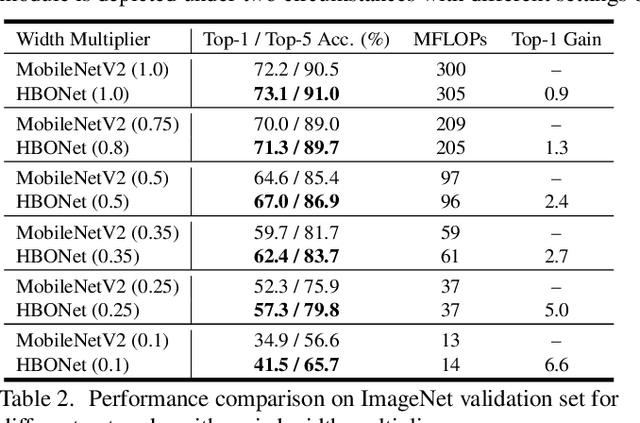
MobileNets, a class of top-performing convolutional neural network architectures in terms of accuracy and efficiency trade-off, are increasingly used in many resourceaware vision applications. In this paper, we present Harmonious Bottleneck on two Orthogonal dimensions (HBO), a novel architecture unit, specially tailored to boost the accuracy of extremely lightweight MobileNets at the level of less than 40 MFLOPs. Unlike existing bottleneck designs that mainly focus on exploring the interdependencies among the channels of either groupwise or depthwise convolutional features, our HBO improves bottleneck representation while maintaining similar complexity via jointly encoding the feature interdependencies across both spatial and channel dimensions. It has two reciprocal components, namely spatial contraction-expansion and channel expansion-contraction, nested in a bilaterally symmetric structure. The combination of two interdependent transformations performing on orthogonal dimensions of feature maps enhances the representation and generalization ability of our proposed module, guaranteeing compelling performance with limited computational resource and power. By replacing the original bottlenecks in MobileNetV2 backbone with HBO modules, we construct HBONets which are evaluated on ImageNet classification, PASCAL VOC object detection and Market-1501 person re-identification. Extensive experiments show that with the severe constraint of computational budget our models outperform MobileNetV2 counterparts by remarkable margins of at most 6.6%, 6.3% and 5.0% on the above benchmarks respectively. Code and pretrained models are available at https://github.com/d-li14/HBONet.
Efficient Semantic Scene Completion Network with Spatial Group Convolution
Jul 11, 2019

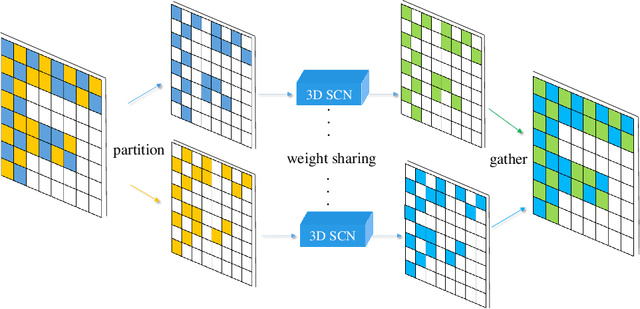
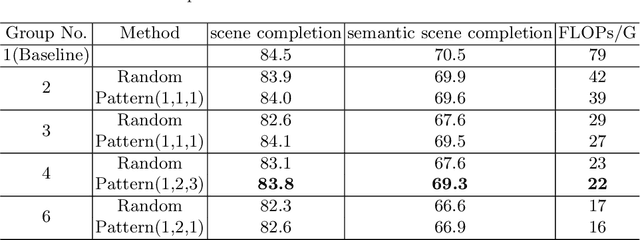
We introduce Spatial Group Convolution (SGC) for accelerating the computation of 3D dense prediction tasks. SGC is orthogonal to group convolution, which works on spatial dimensions rather than feature channel dimension. It divides input voxels into different groups, then conducts 3D sparse convolution on these separated groups. As only valid voxels are considered when performing convolution, computation can be significantly reduced with a slight loss of accuracy. The proposed operations are validated on semantic scene completion task, which aims to predict a complete 3D volume with semantic labels from a single depth image. With SGC, we further present an efficient 3D sparse convolutional network, which harnesses a multiscale architecture and a coarse-to-fine prediction strategy. Evaluations are conducted on the SUNCG dataset, achieving state-of-the-art performance and fast speed. Code is available at https://github.com/zjhthu/SGC-Release.git
Deeply-supervised Knowledge Synergy
Jun 04, 2019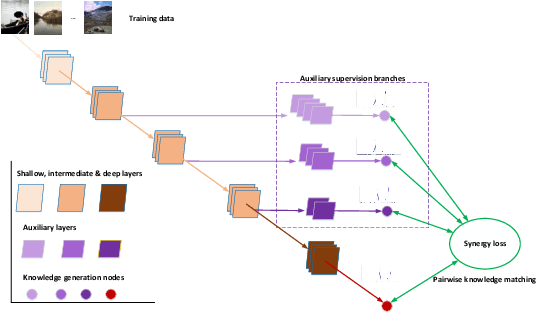
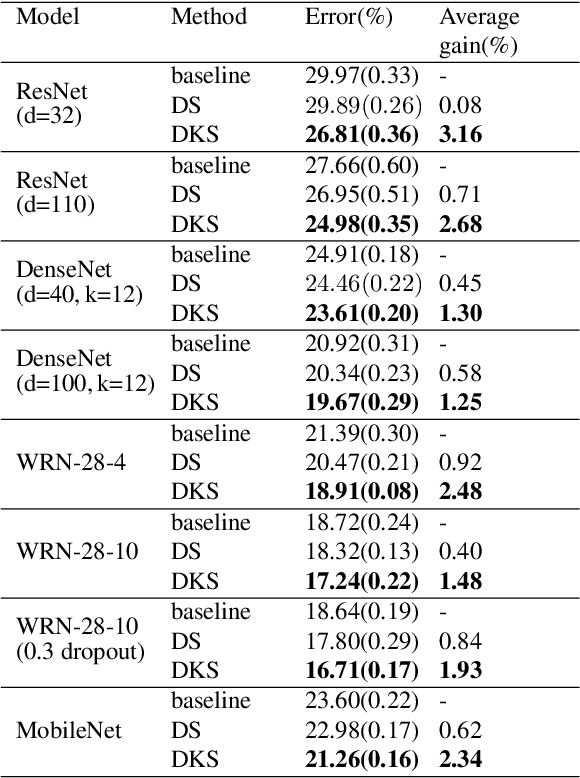
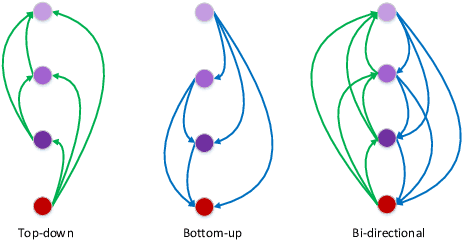
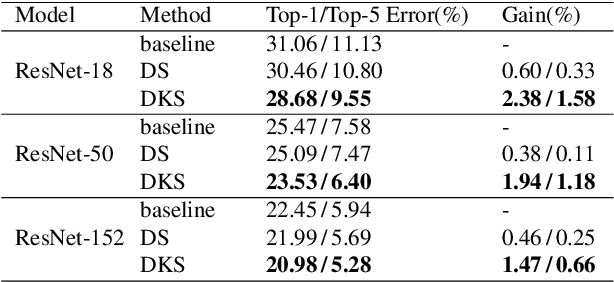
Convolutional Neural Networks (CNNs) have become deeper and more complicated compared with the pioneering AlexNet. However, current prevailing training scheme follows the previous way of adding supervision to the last layer of the network only and propagating error information up layer-by-layer. In this paper, we propose Deeply-supervised Knowledge Synergy (DKS), a new method aiming to train CNNs with improved generalization ability for image classification tasks without introducing extra computational cost during inference. Inspired by the deeply-supervised learning scheme, we first append auxiliary supervision branches on top of certain intermediate network layers. While properly using auxiliary supervision can improve model accuracy to some degree, we go one step further to explore the possibility of utilizing the probabilistic knowledge dynamically learnt by the classifiers connected to the backbone network as a new regularization to improve the training. A novel synergy loss, which considers pairwise knowledge matching among all supervision branches, is presented. Intriguingly, it enables dense pairwise knowledge matching operations in both top-down and bottom-up directions at each training iteration, resembling a dynamic synergy process for the same task. We evaluate DKS on image classification datasets using state-of-the-art CNN architectures, and show that the models trained with it are consistently better than the corresponding counterparts. For instance, on the ImageNet classification benchmark, our ResNet-152 model outperforms the baseline model with a 1.47% margin in Top-1 accuracy. Code is available at https://github.com/sundw2014/DKS.
A Closed-form Solution to Universal Style Transfer
Jun 03, 2019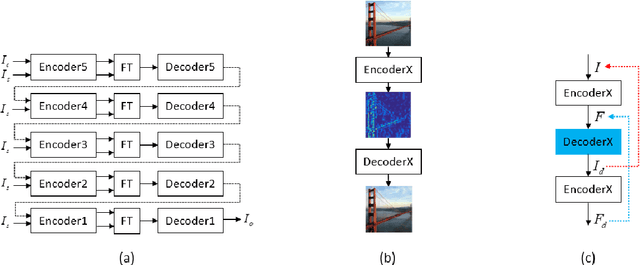

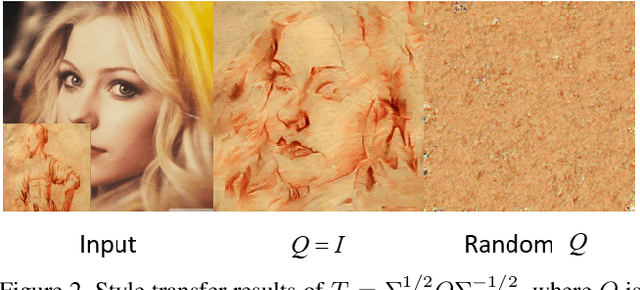
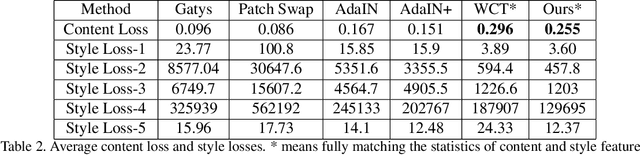
Universal style transfer tries to explicitly minimize the losses in feature space, thus it does not require training on any pre-defined styles. It usually uses different layers of VGG network as the encoders and trains several decoders to invert the features into images. Therefore, the effect of style transfer is achieved by feature transform. Although plenty of methods have been proposed, a theoretical analysis of feature transform is still missing. In this paper, we first propose a novel interpretation by treating it as the optimal transport problem. Then, we demonstrate the relations of our formulation with former works like Adaptive Instance Normalization (AdaIN) and Whitening and Coloring Transform (WCT). Finally, we derive a closed-form solution under our formulation by additionally considering the content loss of Gatys. Comparatively, our solution can preserve better structure and achieve visually pleasing results. It is simple yet effective and we demonstrate the advantages both quantitatively and qualitatively. Besides, we hope our theoretical analysis can inspire future works in neural style transfer.
RON: Reverse Connection with Objectness Prior Networks for Object Detection
Jul 06, 2017
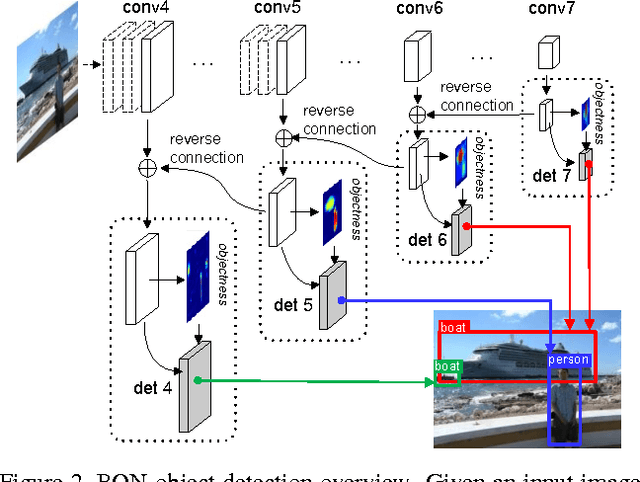
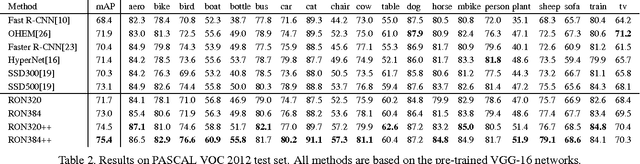
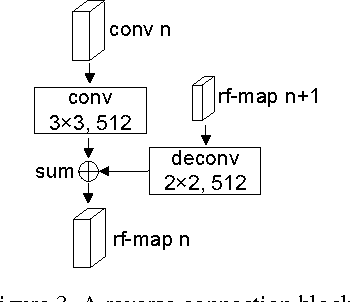
We present RON, an efficient and effective framework for generic object detection. Our motivation is to smartly associate the best of the region-based (e.g., Faster R-CNN) and region-free (e.g., SSD) methodologies. Under fully convolutional architecture, RON mainly focuses on two fundamental problems: (a) multi-scale object localization and (b) negative sample mining. To address (a), we design the reverse connection, which enables the network to detect objects on multi-levels of CNNs. To deal with (b), we propose the objectness prior to significantly reduce the searching space of objects. We optimize the reverse connection, objectness prior and object detector jointly by a multi-task loss function, thus RON can directly predict final detection results from all locations of various feature maps. Extensive experiments on the challenging PASCAL VOC 2007, PASCAL VOC 2012 and MS COCO benchmarks demonstrate the competitive performance of RON. Specifically, with VGG-16 and low resolution 384X384 input size, the network gets 81.3% mAP on PASCAL VOC 2007, 80.7% mAP on PASCAL VOC 2012 datasets. Its superiority increases when datasets become larger and more difficult, as demonstrated by the results on the MS COCO dataset. With 1.5G GPU memory at test phase, the speed of the network is 15 FPS, 3X faster than the Faster R-CNN counterpart.
Physics Inspired Optimization on Semantic Transfer Features: An Alternative Method for Room Layout Estimation
Jul 03, 2017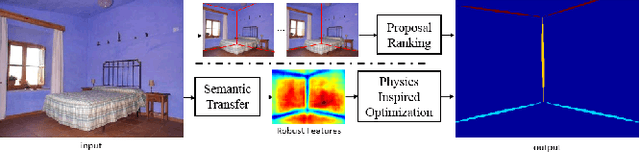
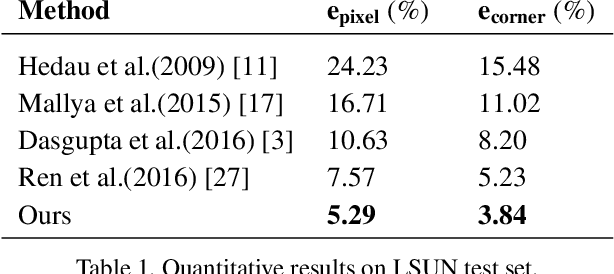
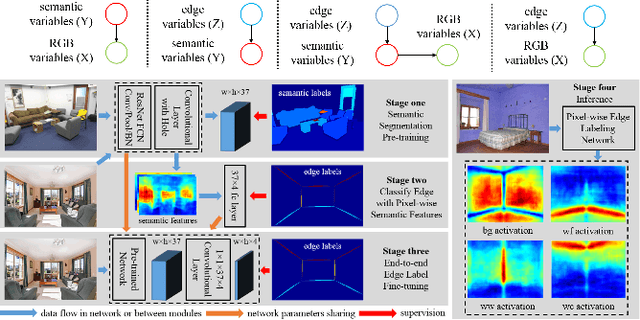
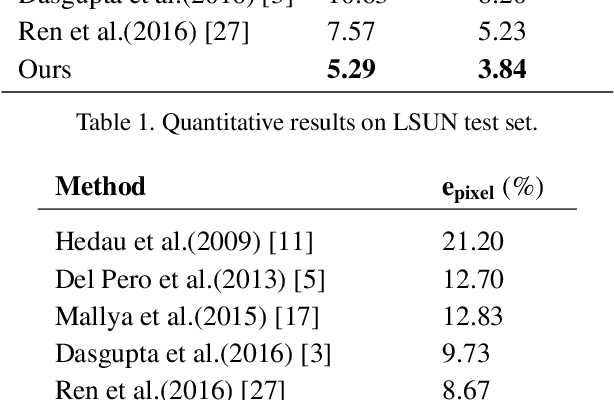
In this paper, we propose an alternative method to estimate room layouts of cluttered indoor scenes. This method enjoys the benefits of two novel techniques. The first one is semantic transfer (ST), which is: (1) a formulation to integrate the relationship between scene clutter and room layout into convolutional neural networks; (2) an architecture that can be end-to-end trained; (3) a practical strategy to initialize weights for very deep networks under unbalanced training data distribution. ST allows us to extract highly robust features under various circumstances, and in order to address the computation redundance hidden in these features we develop a principled and efficient inference scheme named physics inspired optimization (PIO). PIO's basic idea is to formulate some phenomena observed in ST features into mechanics concepts. Evaluations on public datasets LSUN and Hedau show that the proposed method is more accurate than state-of-the-art methods.
Network Sketching: Exploiting Binary Structure in Deep CNNs
Jun 07, 2017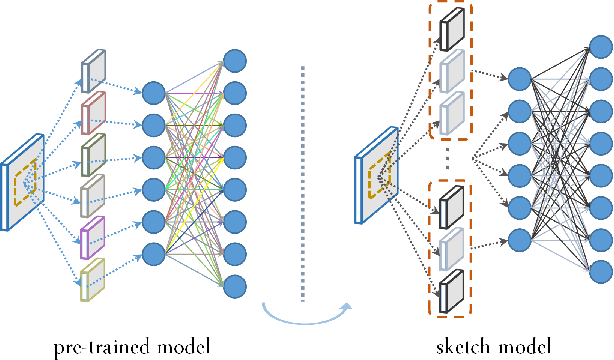
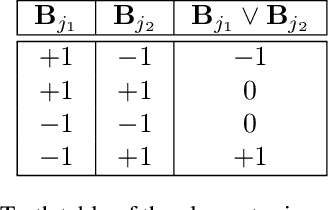
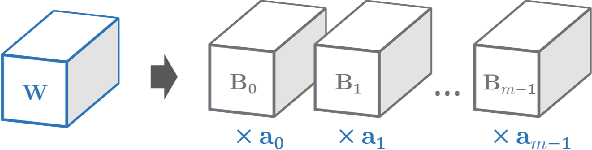
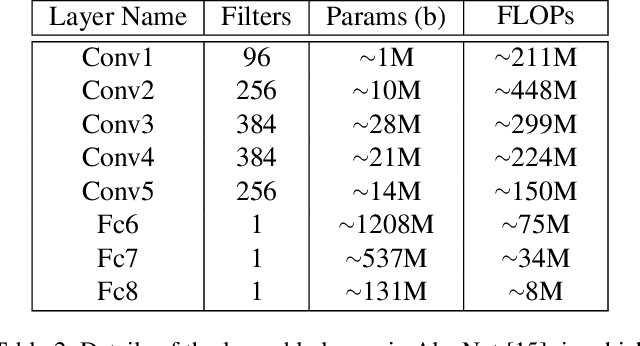
Convolutional neural networks (CNNs) with deep architectures have substantially advanced the state-of-the-art in computer vision tasks. However, deep networks are typically resource-intensive and thus difficult to be deployed on mobile devices. Recently, CNNs with binary weights have shown compelling efficiency to the community, whereas the accuracy of such models is usually unsatisfactory in practice. In this paper, we introduce network sketching as a novel technique of pursuing binary-weight CNNs, targeting at more faithful inference and better trade-off for practical applications. Our basic idea is to exploit binary structure directly in pre-trained filter banks and produce binary-weight models via tensor expansion. The whole process can be treated as a coarse-to-fine model approximation, akin to the pencil drawing steps of outlining and shading. To further speedup the generated models, namely the sketches, we also propose an associative implementation of binary tensor convolutions. Experimental results demonstrate that a proper sketch of AlexNet (or ResNet) outperforms the existing binary-weight models by large margins on the ImageNet large scale classification task, while the committed memory for network parameters only exceeds a little.
Dynamic Network Surgery for Efficient DNNs
Nov 10, 2016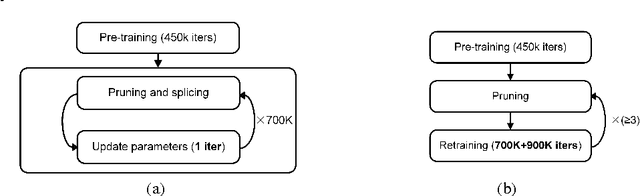
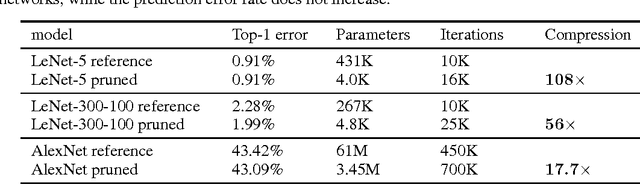
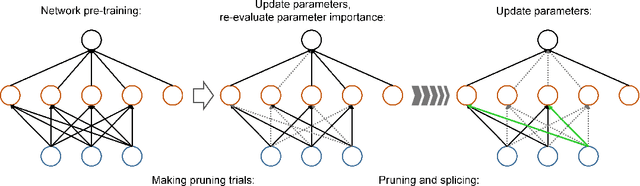
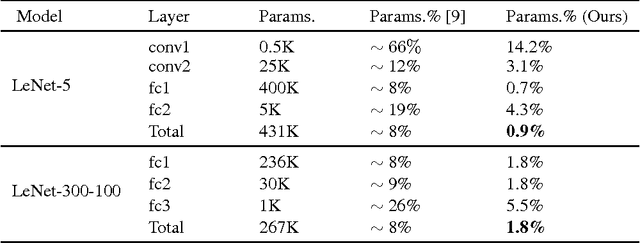
Deep learning has become a ubiquitous technology to improve machine intelligence. However, most of the existing deep models are structurally very complex, making them difficult to be deployed on the mobile platforms with limited computational power. In this paper, we propose a novel network compression method called dynamic network surgery, which can remarkably reduce the network complexity by making on-the-fly connection pruning. Unlike the previous methods which accomplish this task in a greedy way, we properly incorporate connection splicing into the whole process to avoid incorrect pruning and make it as a continual network maintenance. The effectiveness of our method is proved with experiments. Without any accuracy loss, our method can efficiently compress the number of parameters in LeNet-5 and AlexNet by a factor of $\bm{108}\times$ and $\bm{17.7}\times$ respectively, proving that it outperforms the recent pruning method by considerable margins. Code and some models are available at https://github.com/yiwenguo/Dynamic-Network-Surgery.