 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecaying momentum helps neural network training
Oct 11, 2019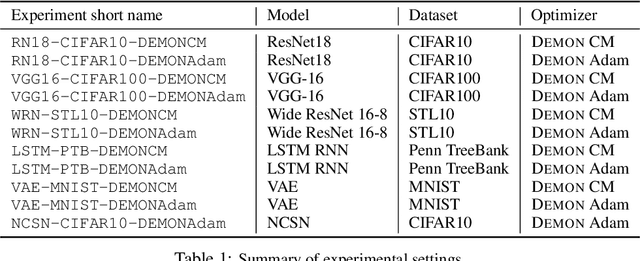

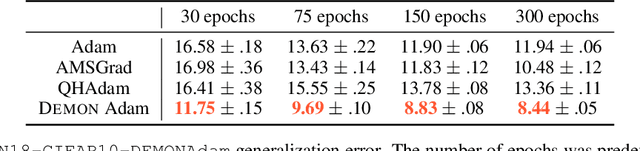
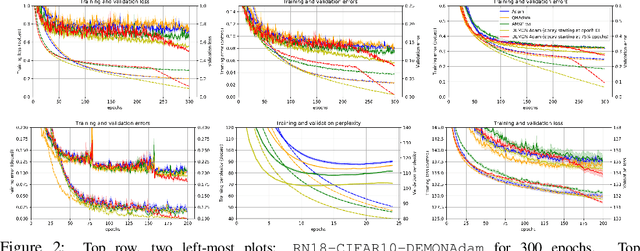
Momentum is a simple and popular technique in deep learning for gradient-based optimizers. We propose a decaying momentum (Demon) rule, motivated by decaying the total contribution of a gradient to all future updates. Applying Demon to Adam leads to significantly improved training, notably competitive to momentum SGD with learning rate decay, even in settings in which adaptive methods are typically non-competitive. Similarly, applying Demon to momentum SGD rivals momentum SGD with learning rate decay, and in many cases leads to improved performance. Demon is trivial to implement and incurs limited extra computational overhead, compared to the vanilla counterparts.
Distributed Learning of Deep Neural Networks using Independent Subnet Training
Oct 04, 2019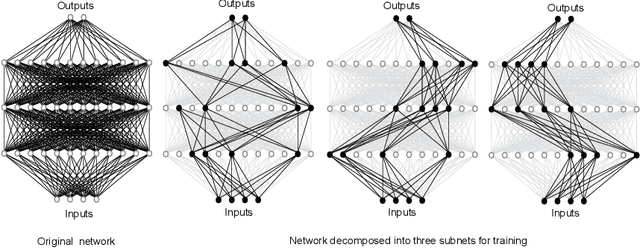
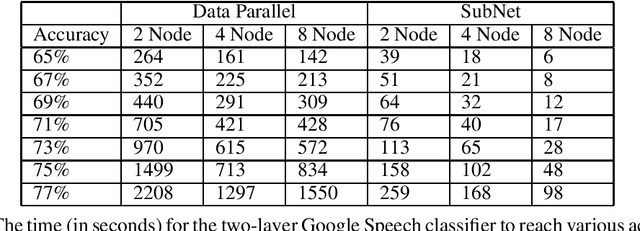
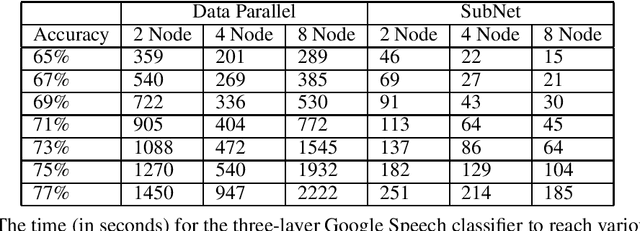

Stochastic gradient descent (SGD) is the method of choice for distributed machine learning, by virtue of its light complexity per iteration on compute nodes, leading to almost linear speedups in theory. Nevertheless, such speedups are rarely observed in practice, due to high communication overheads during synchronization steps. We alleviate this problem by introducing independent subnet training: a simple, jointly model-parallel and data-parallel, approach to distributed training for fully connected, feed-forward neural networks. During subnet training, neurons are stochastically partitioned without replacement, and each partition is sent only to a single worker. This reduces the overall synchronization overhead, as each worker only receives the weights associated with the subnetwork it has been assigned to. Subnet training also reduces synchronization frequency: since workers train disjoint portions of the network, the training can proceed for long periods of time before synchronization, similar to local SGD approaches. We empirically evaluate our approach on real-world speech recognition and product recommendation applications, where we observe that subnet training i) results into accelerated training times, as compared to state of the art distributed models, and ii) often results into boosting the testing accuracy, as it implicitly combines dropout and batch normalization regularizations during training.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Compressing Gradient Optimizers via Count-Sketches
Feb 26, 2019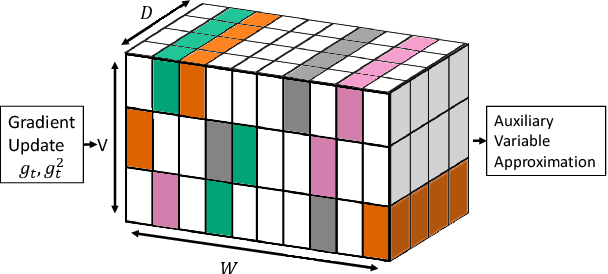

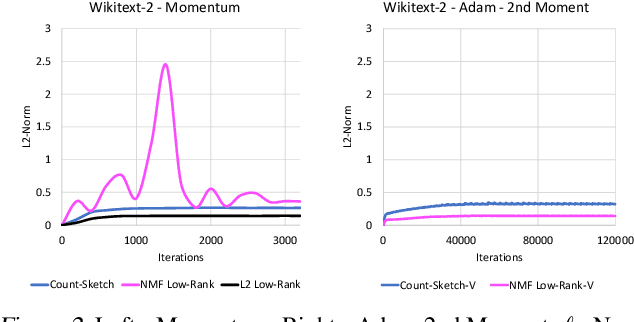
Many popular first-order optimization methods (e.g., Momentum, AdaGrad, Adam) accelerate the convergence rate of deep learning models. However, these algorithms require auxiliary parameters, which cost additional memory proportional to the number of parameters in the model. The problem is becoming more severe as deep learning models continue to grow larger in order to learn from complex, large-scale datasets. Our proposed solution is to maintain a linear sketch to compress the auxiliary variables. We demonstrate that our technique has the same performance as the full-sized baseline, while using significantly less space for the auxiliary variables. Theoretically, we prove that count-sketch optimization maintains the SGD convergence rate, while gracefully reducing memory usage for large-models. On the large-scale 1-Billion Word dataset, we save 25% of the memory used during training (8.6 GB instead of 11.7 GB) by compressing the Adam optimizer in the Embedding and Softmax layers with negligible accuracy and performance loss. For an Amazon extreme classification task with over 49.5 million classes, we also reduce the training time by 38%, by increasing the mini-batch size 3.5x using our count-sketch optimizer.
Minimum norm solutions do not always generalize well for over-parameterized problems
Nov 16, 2018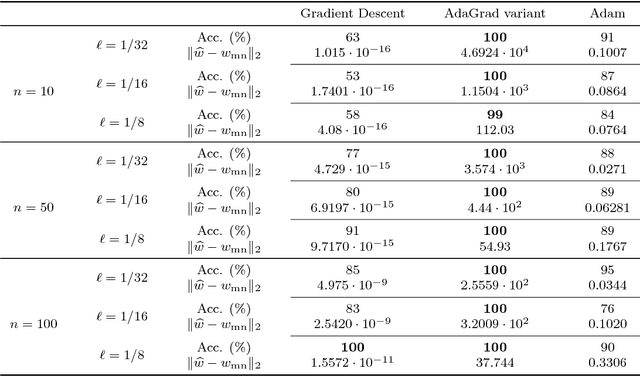
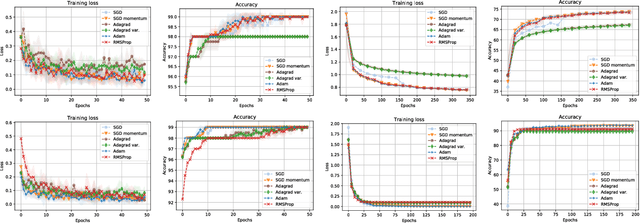

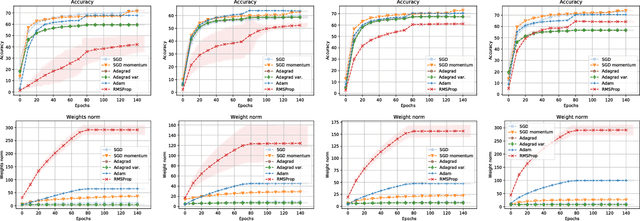
Stochastic gradient descent is the de facto algorithm for training deep neural networks (DNNs). Despite its popularity, it still requires fine hyper-parameter tuning in order to achieve its best performance. This has led to the development of adaptive methods, that claim automatic hyper-parameter tuning. Recently, researchers have studied both algorithmic classes via thoughtful toy problems: e.g., for over-parameterized linear regression, [1] shows that, while SGD always converges to the minimum-norm solution (similar to the case of the maximum margin solution in SVMs that guarantees good prediction error), adaptive methods show no such inclination, leading to worse generalization capabilities. Our aim is to study this conjecture further. We empirically show that the minimum norm solution is not necessarily the proper gauge of good generalization in simplified scenaria, and different models found by adaptive methods could outperform plain gradient methods. In practical DNN settings, we observe that adaptive methods often perform at least as well as SGD, without necessarily reducing the amount of tuning required.
Run Procrustes, Run! On the convergence of accelerated Procrustes Flow
Sep 12, 2018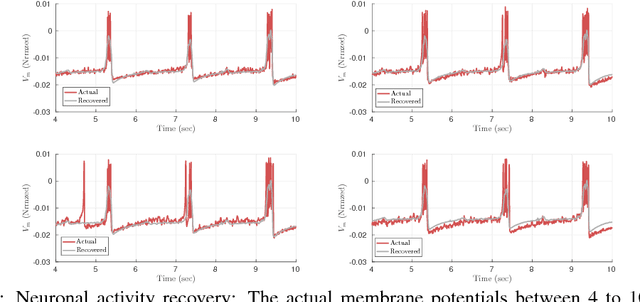
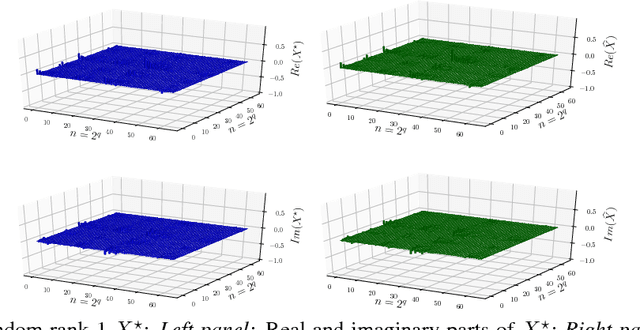
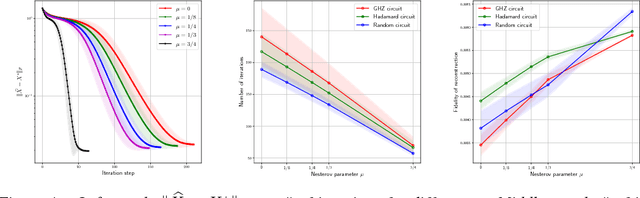
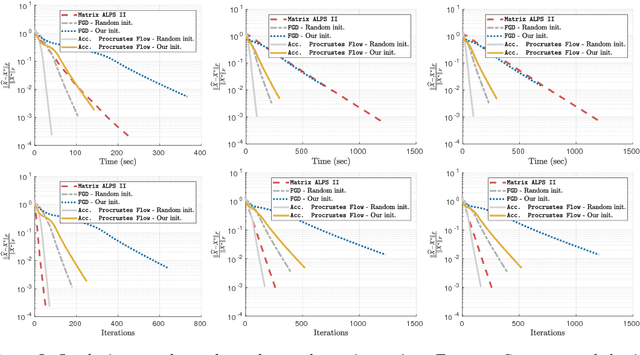
In this work, we present theoretical results on the convergence of non-convex accelerated gradient descent in matrix factorization models. The technique is applied to matrix sensing problems with squared loss, for the estimation of a rank $r$ optimal solution $X^\star \in \mathbb{R}^{n \times n}$. We show that the acceleration leads to linear convergence rate, even under non-convex settings where the variable $X$ is represented as $U U^\top$ for $U \in \mathbb{R}^{n \times r}$. Our result has the same dependence on the condition number of the objective --and the optimal solution-- as that of the recent results on non-accelerated algorithms. However, acceleration is observed in practice, both in synthetic examples and in two real applications: neuronal multi-unit activities recovery from single electrode recordings, and quantum state tomography on quantum computing simulators.
Implicit regularization and solution uniqueness in over-parameterized matrix sensing
Jun 06, 2018
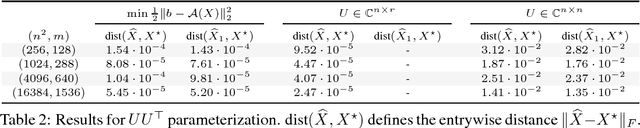
We consider whether algorithmic choices in over-parameterized linear matrix factorization introduce implicit regularization. We focus on noiseless matrix sensing over rank-$r$ positive semi-definite (PSD) matrices in $\mathbb{R}^{n \times n}$, with a sensing mechanism that satisfies the restricted isometry property (RIP). The algorithm we study is that of \emph{factored gradient descent}, where we model the low-rankness and PSD constraints with the factorization $UU^\top$, where $U \in \mathbb{R}^{n \times r}$. Surprisingly, recent work argues that the choice of $r \leq n$ is not pivotal: even setting $U \in \mathbb{R}^{n \times n}$ is sufficient for factored gradient descent to find the rank-$r$ solution, which suggests that operating over the factors leads to an implicit regularization. In this note, we provide a different perspective. We show that, in the noiseless case, under certain conditions, the PSD constraint by itself is sufficient to lead to a unique rank-$r$ matrix recovery, without implicit or explicit low-rank regularization. \emph{I.e.}, under assumptions, the set of PSD matrices, that are consistent with the observed data, is a singleton, irrespective of the algorithm used.
Simple and practical algorithms for $\ell_p$-norm low-rank approximation
May 24, 2018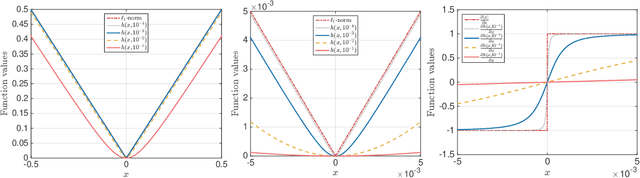
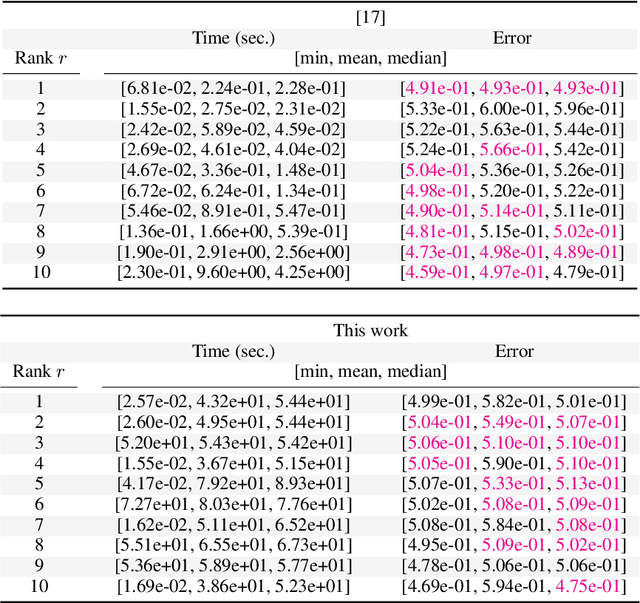
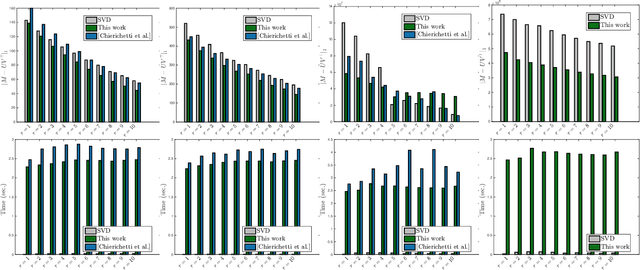
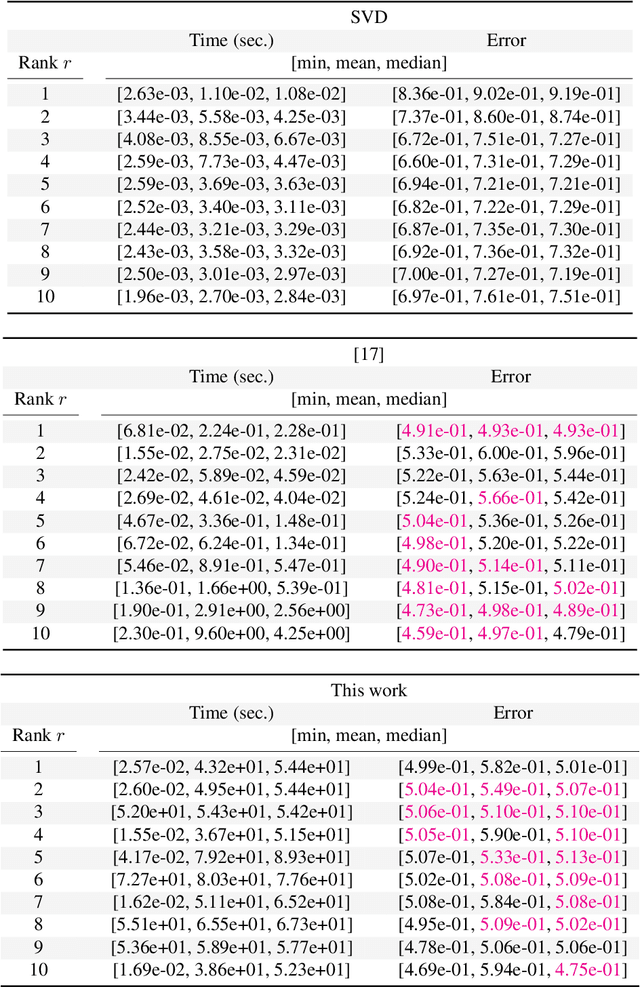
We propose practical algorithms for entrywise $\ell_p$-norm low-rank approximation, for $p = 1$ or $p = \infty$. The proposed framework, which is non-convex and gradient-based, is easy to implement and typically attains better approximations, faster, than state of the art. From a theoretical standpoint, we show that the proposed scheme can attain $(1 + \varepsilon)$-OPT approximations. Our algorithms are not hyperparameter-free: they achieve the desiderata only assuming algorithm's hyperparameters are known a priori---or are at least approximable. I.e., our theory indicates what problem quantities need to be known, in order to get a good solution within polynomial time, and does not contradict to recent inapproximabilty results, as in [46].
Approximate Newton-based statistical inference using only stochastic gradients
May 23, 2018
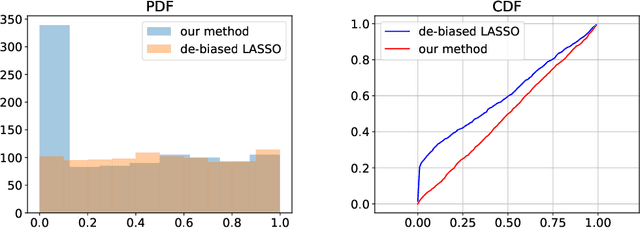

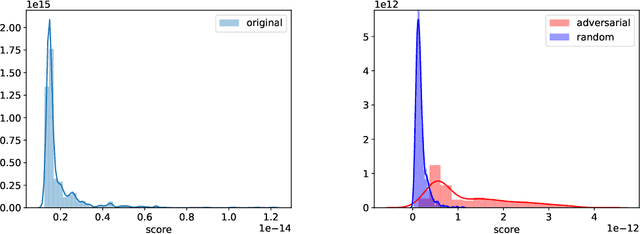
We present a novel inference framework for convex empirical risk minimization, using approximate stochastic Newton steps. The proposed algorithm is based on the notion of finite differences and allows the approximation of a Hessian-vector product from first-order information. In theory, our method efficiently computes the statistical error covariance in $M$-estimation, both for unregularized convex learning problems and high-dimensional LASSO regression, without using exact second order information, or resampling the entire data set. In practice, we demonstrate the effectiveness of our framework on large-scale machine learning problems, that go even beyond convexity: as a highlight, our work can be used to detect certain adversarial attacks on neural networks.
IHT dies hard: Provable accelerated Iterative Hard Thresholding
Dec 26, 2017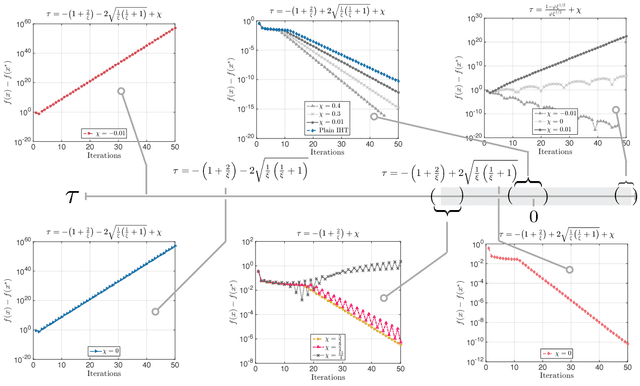
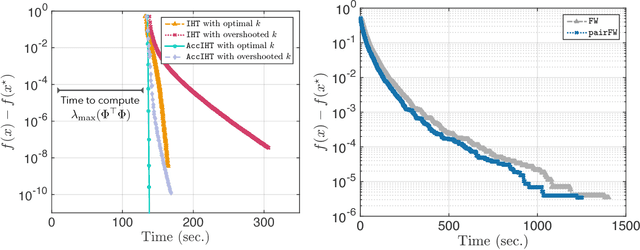
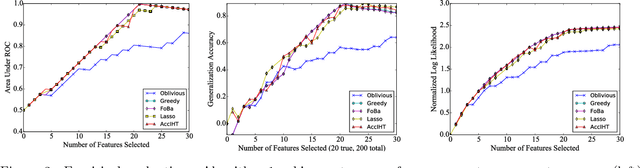
We study --both in theory and practice-- the use of momentum motions in classic iterative hard thresholding (IHT) methods. By simply modifying plain IHT, we investigate its convergence behavior on convex optimization criteria with non-convex constraints, under standard assumptions. In diverse scenaria, we observe that acceleration in IHT leads to significant improvements, compared to state of the art projected gradient descent and Frank-Wolfe variants. As a byproduct of our inspection, we study the impact of selecting the momentum parameter: similar to convex settings, two modes of behavior are observed --"rippling" and linear-- depending on the level of momentum.