 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Algebraic Tensors: Provably-optimal Equivariant Learning and Physical Symmetry Discovery
May 19, 2026We introduce the $\star_G$ tensor algebra, in which any finite group $G$ defines the multiplication rule, making equivariance an intrinsic algebraic property rather than an architectural constraint. The framework rests on three machine-verified theoretical pillars: (i)~an Eckart-Young optimality guarantee for the $\star_G$-SVD: the first such result for symmetry-preserving tensor approximation, exact and polynomial-time; (ii)~a Kronecker factorization that composes multiple symmetries by replacing $F_G$ with $F_{G_1} \otimes F_{G_2}$ with no architectural redesign; and (iii)~a 600-line Lean~4 formalization of the $\star_G$ algebra. The framework provides capabilities that equivariant neural networks (ENNs) structurally cannot: a closed-form per-irreducible-representation decomposition of every prediction, and data-driven discovery of the symmetry group that best fits a dataset. As a non-trivial empirical demonstration, decomposing QM9 molecular geometry over the chiral octahedral subgroup of SO(3) recovers the Wigner--Eckart selection rules of angular momentum from data alone, with no quantum mechanical input: scalar properties are A$_1$-dominated, dipole components are T$_1$-dominated, the isotropic polarizability is uniquely insensitive to $l\!=\!1$ as the rank-2-trace decomposition $l\!=\!0 \oplus l\!=\!2$ requires, and the T$_1$/A$_1$ predictive-power ratio separates vector observables from scalar observables by a factor of five. On full QM9 (130{,}831 molecules), $\star_G$-SVD with ridge regression provides closed form predictions at $\sim50-90\times$ fewer parameters than parameter-matched MLPs. Algebraic equivariance thus complements architectural equivariance not as a faster-better-cheaper alternative but as a different mathematical affordance: provably-optimal symmetry-preserving compression, per-irrep interpretability, and data-driven physical discovery.
Surrogate-based quantification of policy uncertainty in generative flow networks
Oct 24, 2025Generative flow networks are able to sample, via sequential construction, high-reward, complex objects according to a reward function. However, such reward functions are often estimated approximately from noisy data, leading to epistemic uncertainty in the learnt policy. We present an approach to quantify this uncertainty by constructing a surrogate model composed of a polynomial chaos expansion, fit on a small ensemble of trained flow networks. This model learns the relationship between reward functions, parametrised in a low-dimensional space, and the probability distributions over actions at each step along a trajectory of the flow network. The surrogate model can then be used for inexpensive Monte Carlo sampling to estimate the uncertainty in the policy given uncertain rewards. We illustrate the performance of our approach on a discrete and continuous grid-world, symbolic regression, and a Bayesian structure learning task.
Transformers Learn Faster with Semantic Focus
Jun 18, 2025Various forms of sparse attention have been explored to mitigate the quadratic computational and memory cost of the attention mechanism in transformers. We study sparse transformers not through a lens of efficiency but rather in terms of learnability and generalization. Empirically studying a range of attention mechanisms, we find that input-dependent sparse attention models appear to converge faster and generalize better than standard attention models, while input-agnostic sparse attention models show no such benefits -- a phenomenon that is robust across architectural and optimization hyperparameter choices. This can be interpreted as demonstrating that concentrating a model's "semantic focus" with respect to the tokens currently being considered (in the form of input-dependent sparse attention) accelerates learning. We develop a theoretical characterization of the conditions that explain this behavior. We establish a connection between the stability of the standard softmax and the loss function's Lipschitz properties, then show how sparsity affects the stability of the softmax and the subsequent convergence and generalization guarantees resulting from the attention mechanism. This allows us to theoretically establish that input-agnostic sparse attention does not provide any benefits. We also characterize conditions when semantic focus (input-dependent sparse attention) can provide improved guarantees, and we validate that these conditions are in fact met in our empirical evaluations.
Combinatorial Multi-armed Bandits: Arm Selection via Group Testing
Oct 14, 2024This paper considers the problem of combinatorial multi-armed bandits with semi-bandit feedback and a cardinality constraint on the super-arm size. Existing algorithms for solving this problem typically involve two key sub-routines: (1) a parameter estimation routine that sequentially estimates a set of base-arm parameters, and (2) a super-arm selection policy for selecting a subset of base arms deemed optimal based on these parameters. State-of-the-art algorithms assume access to an exact oracle for super-arm selection with unbounded computational power. At each instance, this oracle evaluates a list of score functions, the number of which grows as low as linearly and as high as exponentially with the number of arms. This can be prohibitive in the regime of a large number of arms. This paper introduces a novel realistic alternative to the perfect oracle. This algorithm uses a combination of group-testing for selecting the super arms and quantized Thompson sampling for parameter estimation. Under a general separability assumption on the reward function, the proposed algorithm reduces the complexity of the super-arm-selection oracle to be logarithmic in the number of base arms while achieving the same regret order as the state-of-the-art algorithms that use exact oracles. This translates to at least an exponential reduction in complexity compared to the oracle-based approaches.
Multivariate trace estimation using quantum state space linear algebra
May 02, 2024In this paper, we present a quantum algorithm for approximating multivariate traces, i.e. the traces of matrix products. Our research is motivated by the extensive utility of multivariate traces in elucidating spectral characteristics of matrices, as well as by recent advancements in leveraging quantum computing for faster numerical linear algebra. Central to our approach is a direct translation of a multivariate trace formula into a quantum circuit, achieved through a sequence of low-level circuit construction operations. To facilitate this translation, we introduce \emph{quantum Matrix States Linear Algebra} (qMSLA), a framework tailored for the efficient generation of state preparation circuits via primitive matrix algebra operations. Our algorithm relies on sets of state preparation circuits for input matrices as its primary inputs and yields two state preparation circuits encoding the multivariate trace as output. These circuits are constructed utilizing qMSLA operations, which enact the aforementioned multivariate trace formula. We emphasize that our algorithm's inputs consist solely of state preparation circuits, eschewing harder to synthesize constructs such as Block Encodings. Furthermore, our approach operates independently of the availability of specialized hardware like QRAM, underscoring its versatility and practicality.
Capacity Analysis of Vector Symbolic Architectures
Jan 24, 2023Hyperdimensional computing (HDC) is a biologically-inspired framework that uses high-dimensional vectors and various vector operations to represent and manipulate symbols. The ensemble of a particular vector space and two vector operations (one addition-like for "bundling" and one outer-product-like for "binding") form what is called a "vector symbolic architecture" (VSA). While VSAs have been employed in numerous applications and studied empirically, many theoretical questions about VSAs remain open. We provide theoretical analyses for the *representation capacities* of three popular VSAs: MAP-I, MAP-B, and Binary Sparse. Representation capacity here refers to upper bounds on the dimensions of the VSA vectors required to perform certain symbolic tasks (such as testing for set membership $i \in S$ and estimating set intersection sizes $|S \cap T|$) to a given degree of accuracy. We also describe a relationship between the MAP-I VSA to Hopfield networks, which are simple models of associative memory, and analyze the ability of Hopfield networks to perform some of the same tasks that are typically asked of VSAs. Our analysis of MAP-I casts the VSA vectors as the outputs of *sketching* (dimensionality reduction) algorithms such as the Johnson-Lindenstrauss transform; this provides a clean, simple framework for obtaining bounds on MAP-I's representation capacity. We also provide, to our knowledge, the first analysis of testing set membership in a bundle of general pairwise bindings from MAP-I. Binary sparse VSAs are well-known to be related to Bloom filters; we give analyses of set intersection for Bloom and Counting Bloom filters. Our analysis of MAP-B and Binary Sparse bundling include new applications of several concentration inequalities.
Towards Quantum Advantage on Noisy Quantum Computers
Sep 27, 2022

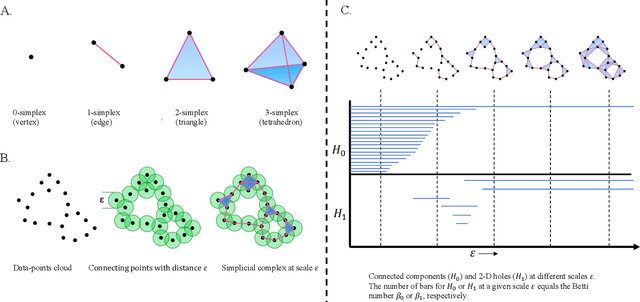
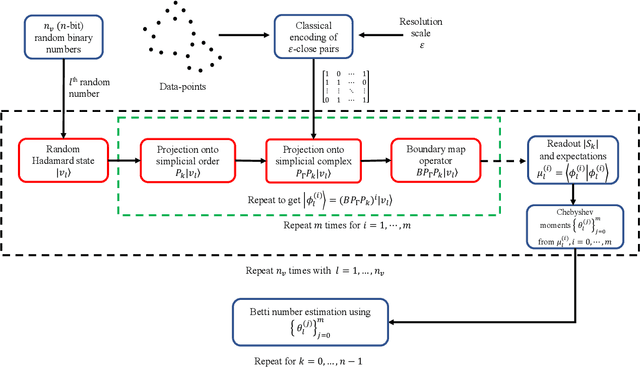
Topological data analysis (TDA) is a powerful technique for extracting complex and valuable shape-related summaries of high-dimensional data. However, the computational demands of classical TDA algorithms are exorbitant, and quickly become impractical for high-order characteristics. Quantum computing promises exponential speedup for certain problems. Yet, many existing quantum algorithms with notable asymptotic speedups require a degree of fault tolerance that is currently unavailable. In this paper, we present NISQ-TDA, the first fully implemented end-to-end quantum machine learning algorithm needing only a linear circuit-depth, that is applicable to non-handcrafted high-dimensional classical data, with potential speedup under stringent conditions. The algorithm neither suffers from the data-loading problem nor does it need to store the input data on the quantum computer explicitly. Our approach includes three key innovations: (a) an efficient realization of the full boundary operator as a sum of Pauli operators; (b) a quantum rejection sampling and projection approach to restrict a uniform superposition to the simplices of the desired order in the complex; and (c) a stochastic rank estimation method to estimate the topological features in the form of approximate Betti numbers. We present theoretical results that establish additive error guarantees for NISQ-TDA, and the circuit and computational time and depth complexities for exponentially scaled output estimates, up to the error tolerance. The algorithm was successfully executed on quantum computing devices, as well as on noisy quantum simulators, applied to small datasets. Preliminary empirical results suggest that the algorithm is robust to noise.
PCENet: High Dimensional Surrogate Modeling for Learning Uncertainty
Feb 11, 2022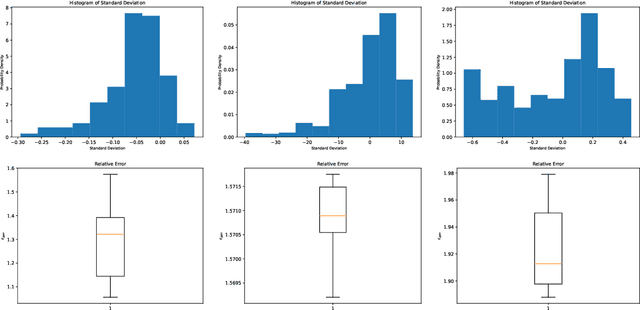
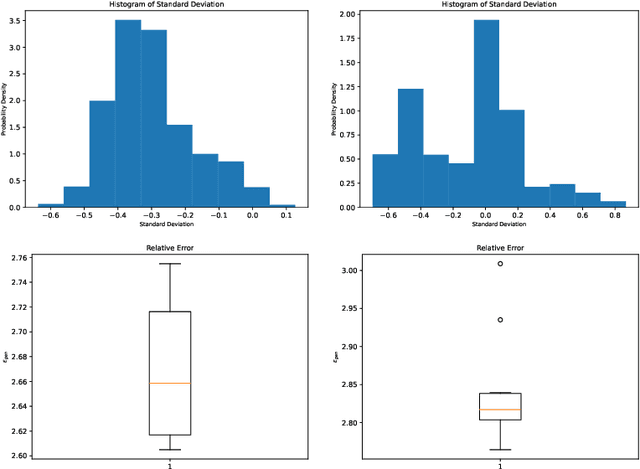
Learning data representations under uncertainty is an important task that emerges in numerous machine learning applications. However, uncertainty quantification (UQ) techniques are computationally intensive and become prohibitively expensive for high-dimensional data. In this paper, we present a novel surrogate model for representation learning and uncertainty quantification, which aims to deal with data of moderate to high dimensions. The proposed model combines a neural network approach for dimensionality reduction of the (potentially high-dimensional) data, with a surrogate model method for learning the data distribution. We first employ a variational autoencoder (VAE) to learn a low-dimensional representation of the data distribution. We then propose to harness polynomial chaos expansion (PCE) formulation to map this distribution to the output target. The coefficients of PCE are learned from the distribution representation of the training data using a maximum mean discrepancy (MMD) approach. Our model enables us to (a) learn a representation of the data, (b) estimate uncertainty in the high-dimensional data system, and (c) match high order moments of the output distribution; without any prior statistical assumptions on the data. Numerical experimental results are presented to illustrate the performance of the proposed method.
Efficient Scaling of Dynamic Graph Neural Networks
Sep 16, 2021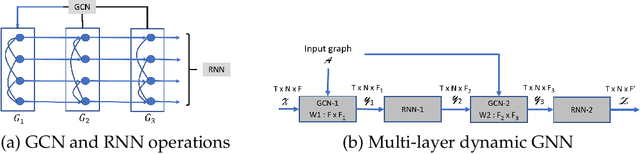
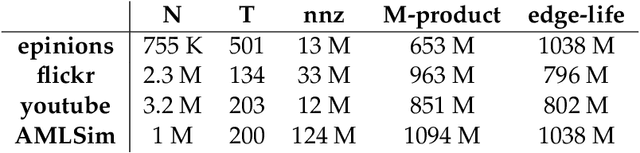
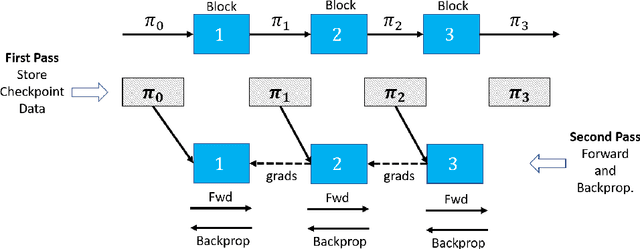
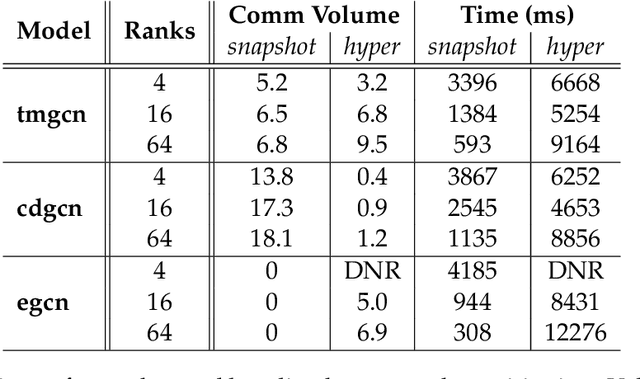
We present distributed algorithms for training dynamic Graph Neural Networks (GNN) on large scale graphs spanning multi-node, multi-GPU systems. To the best of our knowledge, this is the first scaling study on dynamic GNN. We devise mechanisms for reducing the GPU memory usage and identify two execution time bottlenecks: CPU-GPU data transfer; and communication volume. Exploiting properties of dynamic graphs, we design a graph difference-based strategy to significantly reduce the transfer time. We develop a simple, but effective data distribution technique under which the communication volume remains fixed and linear in the input size, for any number of GPUs. Our experiments using billion-size graphs on a system of 128 GPUs shows that: (i) the distribution scheme achieves up to 30x speedup on 128 GPUs; (ii) the graph-difference technique reduces the transfer time by a factor of up to 4.1x and the overall execution time by up to 40%
Quantum Topological Data Analysis with Linear Depth and Exponential Speedup
Aug 05, 2021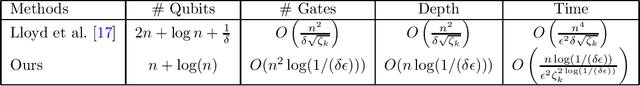
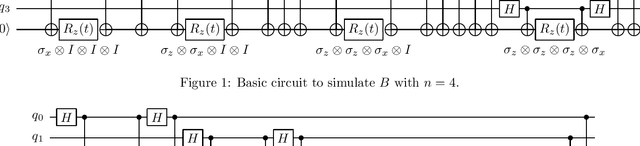
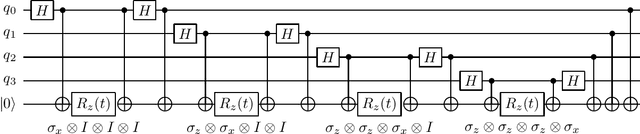
Quantum computing offers the potential of exponential speedups for certain classical computations. Over the last decade, many quantum machine learning (QML) algorithms have been proposed as candidates for such exponential improvements. However, two issues unravel the hope of exponential speedup for some of these QML algorithms: the data-loading problem and, more recently, the stunning dequantization results of Tang et al. A third issue, namely the fault-tolerance requirements of most QML algorithms, has further hindered their practical realization. The quantum topological data analysis (QTDA) algorithm of Lloyd, Garnerone and Zanardi was one of the first QML algorithms that convincingly offered an expected exponential speedup. From the outset, it did not suffer from the data-loading problem. A recent result has also shown that the generalized problem solved by this algorithm is likely classically intractable, and would therefore be immune to any dequantization efforts. However, the QTDA algorithm of Lloyd et~al. has a time complexity of $O(n^4/(\epsilon^2 \delta))$ (where $n$ is the number of data points, $\epsilon$ is the error tolerance, and $\delta$ is the smallest nonzero eigenvalue of the restricted Laplacian) and requires fault-tolerant quantum computing, which has not yet been achieved. In this paper, we completely overhaul the QTDA algorithm to achieve an improved exponential speedup and depth complexity of $O(n\log(1/(\delta\epsilon)))$. Our approach includes three key innovations: (a) an efficient realization of the combinatorial Laplacian as a sum of Pauli operators; (b) a quantum rejection sampling approach to restrict the superposition to the simplices in the complex; and (c) a stochastic rank estimation method to estimate the Betti numbers. We present a theoretical error analysis, and the circuit and computational time and depth complexities for Betti number estimation.