 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary: Reframing GUI Critique as Continuous Semantic Alignment
May 14, 2026Test-Time Scaling (TTS), which samples multiple candidate actions and ranks them via a Critic Model, has emerged as a promising paradigm for generalist GUI agents. Its efficacy thus hinges on the critic's fine-grained ranking ability. However, existing GUI critic models uniformly adopt binary classification. Our motivational analysis of these models exposes a severe entanglement: scores for valid actions and plausible-but-invalid distractors become indistinguishable. We attribute this failure to two structural defects: Affordance Collapse--the hierarchical affordance space is compressed into 0/1 labels; and Noise Sensitivity--binary objectives overfit to noisy decision boundaries. To resolve this, we introduce BBCritic (Beyond-Binary Critic), a paradigm shift grounded in the Functional Equivalence Hypothesis. Through two-stage contrastive learning, BBCritic aligns instructions and actions in a shared Affordance Space, recovering the hierarchical structure that binary supervision flattens. We also present BBBench (Beyond-Binary Bench), the first GUI critic benchmark that pairs a dense action space with a hierarchical four-level taxonomy, enabling fine-grained ranking evaluation. Experimental results show that BBCritic-3B, trained without any extra annotation, outperforms 7B-parameter SOTA binary models. It demonstrates strong zero-shot transferability across platforms and tasks, supporting our methodological view: GUI critique is fundamentally a metric-learning problem, not a classification one.
Q-Mask: Query-driven Causal Masks for Text Anchoring in OCR-Oriented Vision-Language Models
Mar 31, 2026Optical Character Recognition (OCR) is increasingly regarded as a foundational capability for modern vision-language models (VLMs), enabling them not only to read text in images but also to support downstream reasoning in real-world visual question answering (VQA). However, practical applications further require reliable text anchors, i.e., accurately grounding queried text to its corresponding spatial region. To systematically evaluate this capability, we introduce TextAnchor-Bench (TABench), a benchmark for fine-grained text-region grounding, which reveals that both general-purpose and OCR-specific VLMs still struggle to establish accurate and stable text anchors. To address this limitation, we propose Q-Mask, a precise OCR framework built upon a causal query-driven mask decoder (CQMD). Inspired by chain-of-thought reasoning, Q-Mask performs causal visual decoding that sequentially generates query-conditioned visual masks before producing the final OCR output. This visual CoT paradigm disentangles where the text is from what the text is, enforcing grounded evidence acquisition prior to recognition and enabling explicit text anchor construction during inference. To train CQMD, we construct TextAnchor-26M, a large-scale dataset of image-text pairs annotated with fine-grained masks corresponding to specific textual elements, encouraging stable text-region correspondences and injecting strong spatial priors into VLM training. Extensive experiments demonstrate that Q-Mask substantially improves text anchoring and understanding across diverse visual scenes.
HyperClick: Advancing Reliable GUI Grounding via Uncertainty Calibration
Oct 31, 2025Autonomous Graphical User Interface (GUI) agents rely on accurate GUI grounding, which maps language instructions to on-screen coordinates, to execute user commands. However, current models, whether trained via supervised fine-tuning (SFT) or reinforcement fine-tuning (RFT), lack self-awareness of their capability boundaries, leading to overconfidence and unreliable predictions. We first systematically evaluate probabilistic and verbalized confidence in general and GUI-specific models, revealing a misalignment between confidence and actual accuracy, which is particularly critical in dynamic GUI automation tasks, where single errors can cause task failure. To address this, we propose HyperClick, a novel framework that enhances reliable GUI grounding through uncertainty calibration. HyperClick introduces a dual reward mechanism, combining a binary reward for correct actions with a truncated Gaussian-based spatial confidence modeling, calibrated using the Brier score. This approach jointly optimizes grounding accuracy and confidence reliability, fostering introspective self-criticism. Extensive experiments on seven challenge benchmarks show that HyperClick achieves state-of-the-art performance while providing well-calibrated confidence. By enabling explicit confidence calibration and introspective self-criticism, HyperClick reduces overconfidence and supports more reliable GUI automation.
CIARD: Cyclic Iterative Adversarial Robustness Distillation
Sep 16, 2025Adversarial robustness distillation (ARD) aims to transfer both performance and robustness from teacher model to lightweight student model, enabling resilient performance on resource-constrained scenarios. Though existing ARD approaches enhance student model's robustness, the inevitable by-product leads to the degraded performance on clean examples. We summarize the causes of this problem inherent in existing methods with dual-teacher framework as: 1. The divergent optimization objectives of dual-teacher models, i.e., the clean and robust teachers, impede effective knowledge transfer to the student model, and 2. The iteratively generated adversarial examples during training lead to performance deterioration of the robust teacher model. To address these challenges, we propose a novel Cyclic Iterative ARD (CIARD) method with two key innovations: a. A multi-teacher framework with contrastive push-loss alignment to resolve conflicts in dual-teacher optimization objectives, and b. Continuous adversarial retraining to maintain dynamic teacher robustness against performance degradation from the varying adversarial examples. Extensive experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet demonstrate that CIARD achieves remarkable performance with an average 3.53 improvement in adversarial defense rates across various attack scenarios and a 5.87 increase in clean sample accuracy, establishing a new benchmark for balancing model robustness and generalization. Our code is available at https://github.com/eminentgu/CIARD
Beyond CNNs: Exploiting Further Inherent Symmetries in Medical Image Segmentation
Jul 29, 2022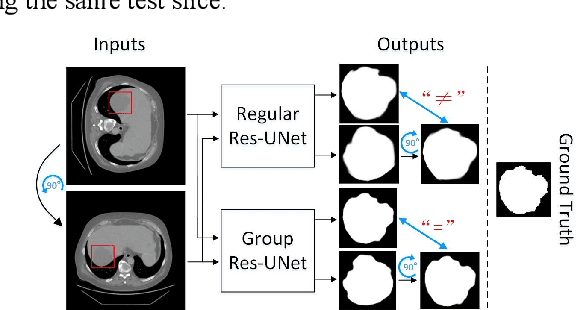
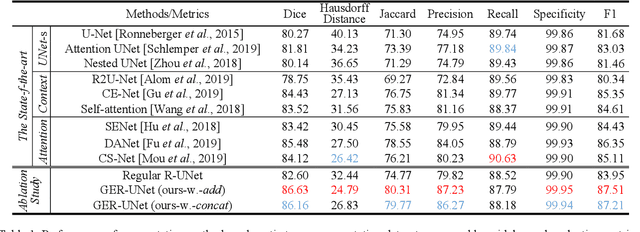
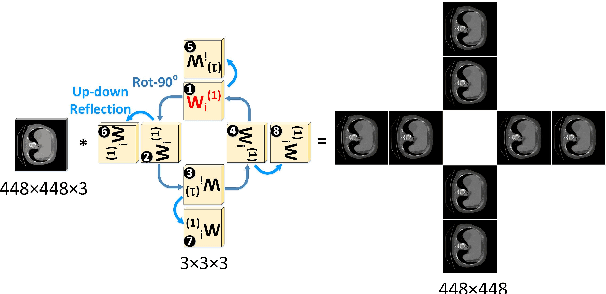
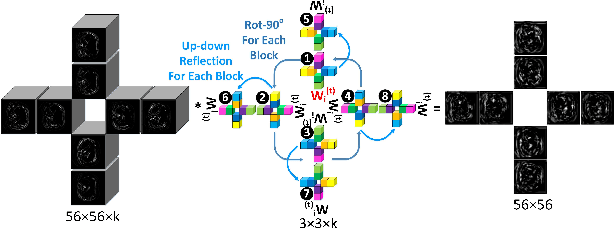
Automatic tumor or lesion segmentation is a crucial step in medical image analysis for computer-aided diagnosis. Although the existing methods based on Convolutional Neural Networks (CNNs) have achieved the state-of-the-art performance, many challenges still remain in medical tumor segmentation. This is because, although the human visual system can detect symmetries in 2D images effectively, regular CNNs can only exploit translation invariance, overlooking further inherent symmetries existing in medical images such as rotations and reflections. To solve this problem, we propose a novel group equivariant segmentation framework by encoding those inherent symmetries for learning more precise representations. First, kernel-based equivariant operations are devised on each orientation, which allows it to effectively address the gaps of learning symmetries in existing approaches. Then, to keep segmentation networks globally equivariant, we design distinctive group layers with layer-wise symmetry constraints. Finally, based on our novel framework, extensive experiments conducted on real-world clinical data demonstrate that a Group Equivariant Res-UNet (named GER-UNet) outperforms its regular CNN-based counterpart and the state-of-the-art segmentation methods in the tasks of hepatic tumor segmentation, COVID-19 lung infection segmentation and retinal vessel detection. More importantly, the newly built GER-UNet also shows potential in reducing the sample complexity and the redundancy of filters, upgrading current segmentation CNNs and delineating organs on other medical imaging modalities.
Beyond CNNs: Exploiting Further Inherent Symmetries in Medical Images for Segmentation
May 08, 2020Automatic tumor segmentation is a crucial step in medical image analysis for computer-aided diagnosis. Although the existing methods based on convolutional neural networks (CNNs) have achieved the state-of-the-art performance, many challenges still remain in medical tumor segmentation. This is because regular CNNs can only exploit translation invariance, ignoring further inherent symmetries existing in medical images such as rotations and reflections. To mitigate this shortcoming, we propose a novel group equivariant segmentation framework by encoding those inherent symmetries for learning more precise representations. First, kernel-based equivariant operations are devised on every orientation, which can effectively address the gaps of learning symmetries in existing approaches. Then, to keep segmentation networks globally equivariant, we design distinctive group layers with layerwise symmetry constraints. By exploiting further symmetries, novel segmentation CNNs can dramatically reduce the sample complexity and the redundancy of filters (by roughly 2/3) over regular CNNs. More importantly, based on our novel framework, we show that a newly built GER-UNet outperforms its regular CNN-based counterpart and the state-of-the-art segmentation methods on real-world clinical data. Specifically, the group layers of our segmentation framework can be seamlessly integrated into any popular CNN-based segmentation architectures.