 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Image Scene Structure to Video via Frame-Clip Consistency of Object Tokens
Jun 15, 2022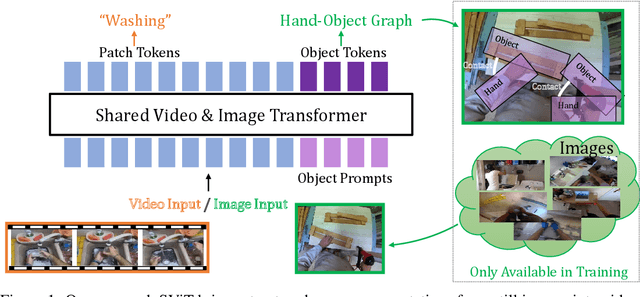
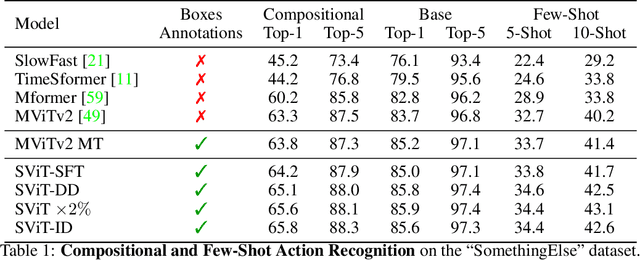
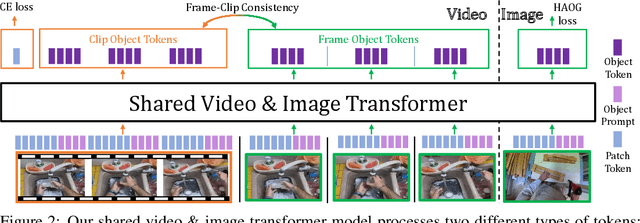
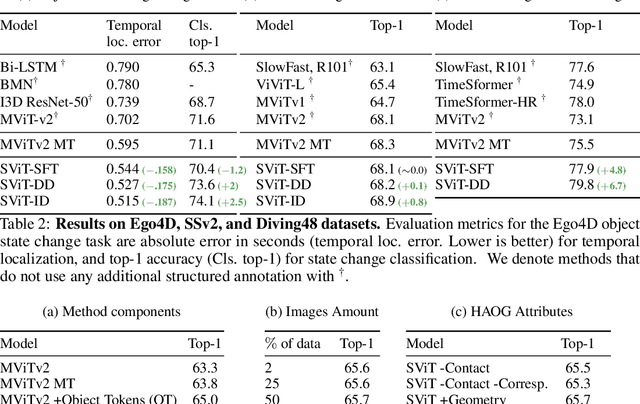
Recent action recognition models have achieved impressive results by integrating objects, their locations and interactions. However, obtaining dense structured annotations for each frame is tedious and time-consuming, making these methods expensive to train and less scalable. At the same time, if a small set of annotated images is available, either within or outside the domain of interest, how could we leverage these for a video downstream task? We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a \emph{Frame-Clip Consistency} loss, which ensures the flow of structured information between images and videos. We explore a particular instantiation of scene structure, namely a \emph{Hand-Object Graph}, consisting of hands and objects with their locations as nodes, and physical relations of contact/no-contact as edges. SViT shows strong performance improvements on multiple video understanding tasks and datasets. Furthermore, it won in the Ego4D CVPR'22 Object State Localization challenge. For code and pretrained models, visit the project page at \url{https://eladb3.github.io/SViT/}
Active Learning with Label Comparisons
Apr 10, 2022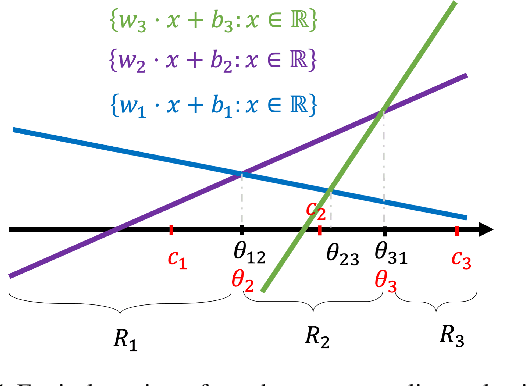
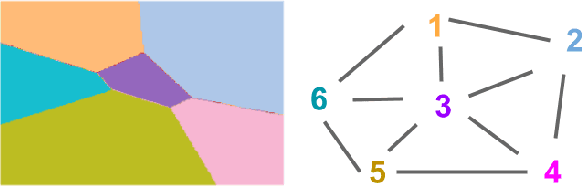
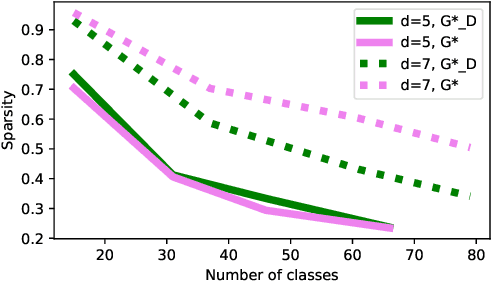
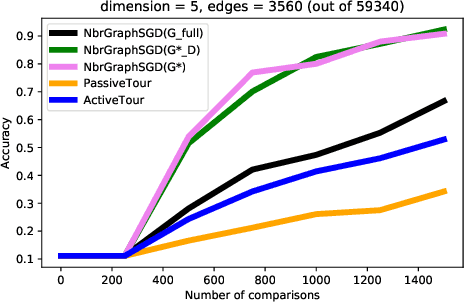
Supervised learning typically relies on manual annotation of the true labels. When there are many potential classes, searching for the best one can be prohibitive for a human annotator. On the other hand, comparing two candidate labels is often much easier. We focus on this type of pairwise supervision and ask how it can be used effectively in learning, and in particular in active learning. We obtain several insightful results in this context. In principle, finding the best of $k$ labels can be done with $k-1$ active queries. We show that there is a natural class where this approach is sub-optimal, and that there is a more comparison-efficient active learning scheme. A key element in our analysis is the "label neighborhood graph" of the true distribution, which has an edge between two classes if they share a decision boundary. We also show that in the PAC setting, pairwise comparisons cannot provide improved sample complexity in the worst case. We complement our theoretical results with experiments, clearly demonstrating the effect of the neighborhood graph on sample complexity.
On the Implicit Bias of Gradient Descent for Temporal Extrapolation
Feb 09, 2022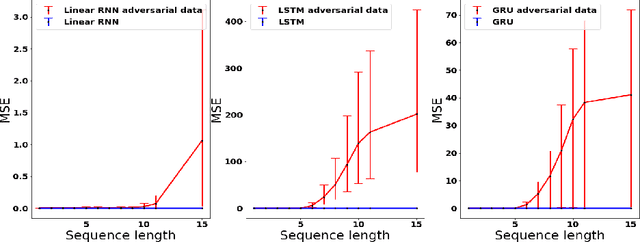
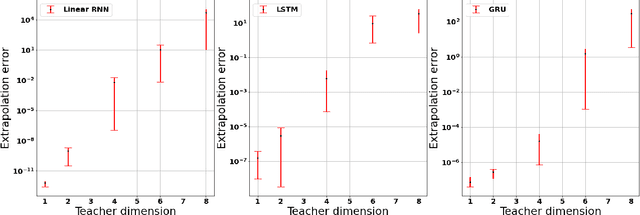
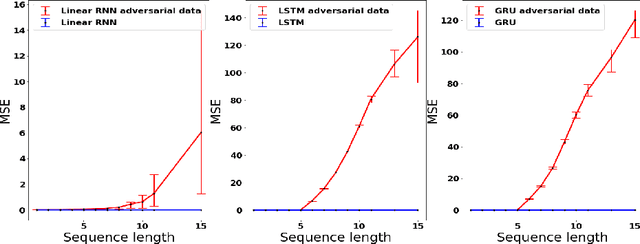
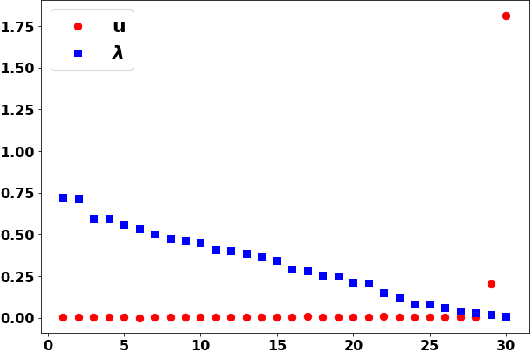
Common practice when using recurrent neural networks (RNNs) is to apply a model to sequences longer than those seen in training. This "extrapolating" usage deviates from the traditional statistical learning setup where guarantees are provided under the assumption that train and test distributions are identical. Here we set out to understand when RNNs can extrapolate, focusing on a simple case where the data generating distribution is memoryless. We first show that even with infinite training data, there exist RNN models that interpolate perfectly (i.e., they fit the training data) yet extrapolate poorly to longer sequences. We then show that if gradient descent is used for training, learning will converge to perfect extrapolation under certain assumption on initialization. Our results complement recent studies on the implicit bias of gradient descent, showing that it plays a key role in extrapolation when learning temporal prediction models.
Learning to Retrieve Passages without Supervision
Dec 14, 2021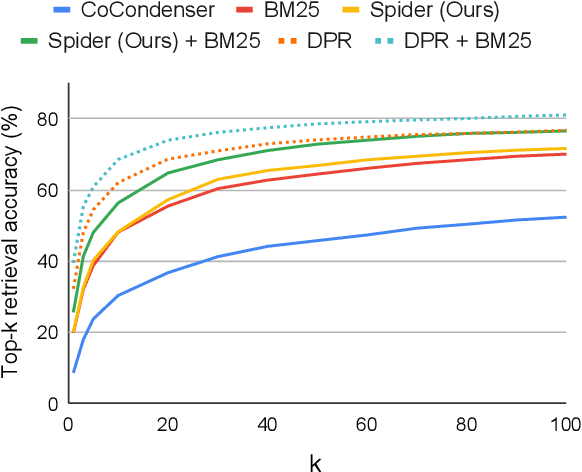
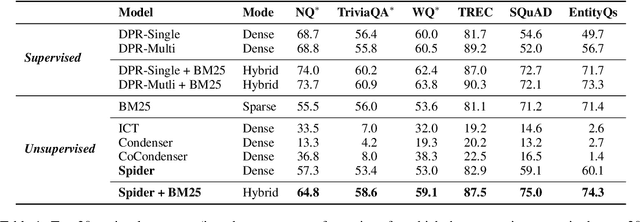
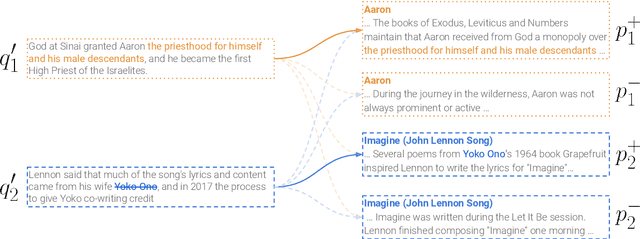
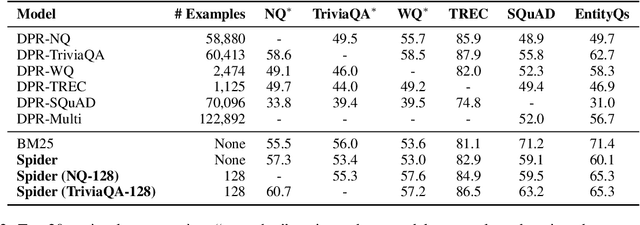
Dense retrievers for open-domain question answering (ODQA) have been shown to achieve impressive performance by training on large datasets of question-passage pairs. We investigate whether dense retrievers can be learned in a self-supervised fashion, and applied effectively without any annotations. We observe that existing pretrained models for retrieval struggle in this scenario, and propose a new pretraining scheme designed for retrieval: recurring span retrieval. We use recurring spans across passages in a document to create pseudo examples for contrastive learning. The resulting model -- Spider -- performs surprisingly well without any examples on a wide range of ODQA datasets, and is competitive with BM25, a strong sparse baseline. In addition, Spider often outperforms strong baselines like DPR trained on Natural Questions, when evaluated on questions from other datasets. Our hybrid retriever, which combines Spider with BM25, improves over its components across all datasets, and is often competitive with in-domain DPR models, which are trained on tens of thousands of examples.
On the Optimization Landscape of Maximum Mean Discrepancy
Oct 26, 2021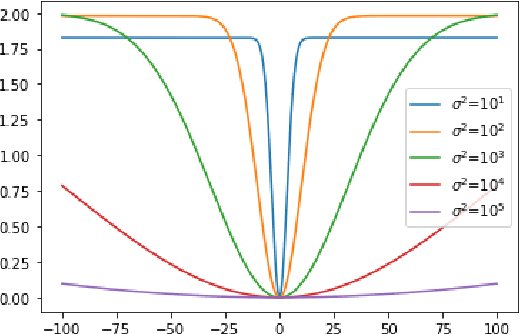
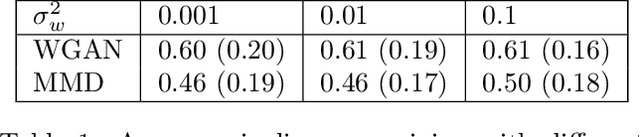
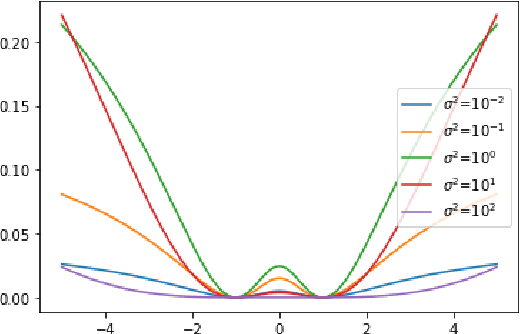
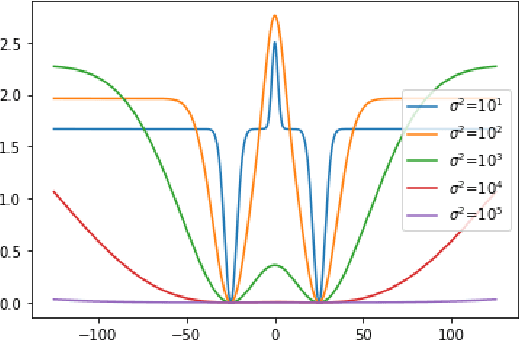
Generative models have been successfully used for generating realistic signals. Because the likelihood function is typically intractable in most of these models, the common practice is to use "implicit" models that avoid likelihood calculation. However, it is hard to obtain theoretical guarantees for such models. In particular, it is not understood when they can globally optimize their non-convex objectives. Here we provide such an analysis for the case of Maximum Mean Discrepancy (MMD) learning of generative models. We prove several optimality results, including for a Gaussian distribution with low rank covariance (where likelihood is inapplicable) and a mixture of Gaussians. Our analysis shows that that the MMD optimization landscape is benign in these cases, and therefore gradient based methods will globally minimize the MMD objective.
Object-Region Video Transformers
Oct 13, 2021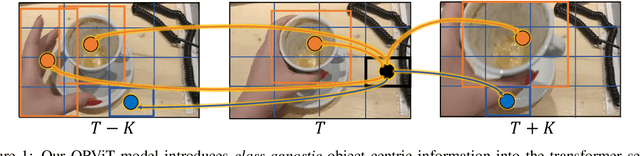
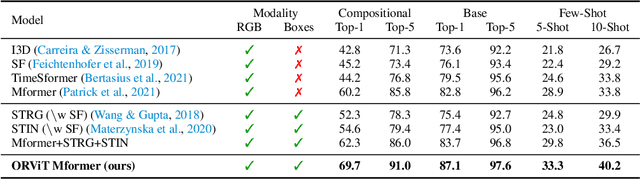
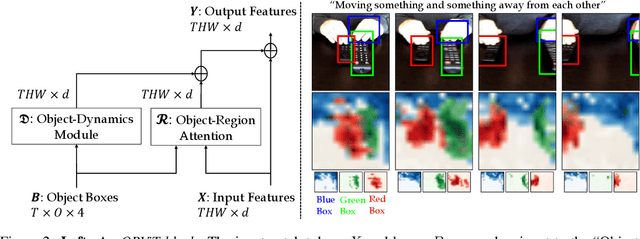
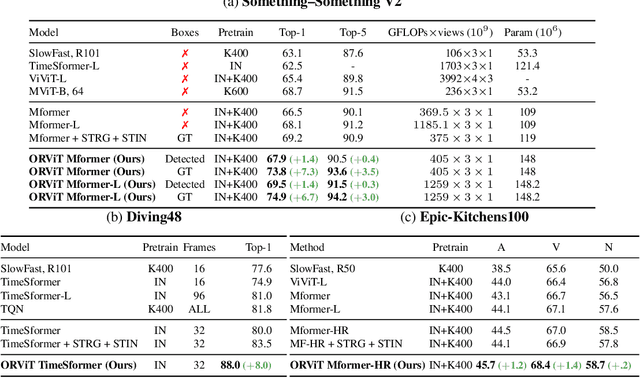
Evidence from cognitive psychology suggests that understanding spatio-temporal object interactions and dynamics can be essential for recognizing actions in complex videos. Therefore, action recognition models are expected to benefit from explicit modeling of objects, including their appearance, interaction, and dynamics. Recently, video transformers have shown great success in video understanding, exceeding CNN performance. Yet, existing video transformer models do not explicitly model objects. In this work, we present Object-Region Video Transformers (ORViT), an \emph{object-centric} approach that extends video transformer layers with a block that directly incorporates object representations. The key idea is to fuse object-centric spatio-temporal representations throughout multiple transformer layers. Our ORViT block consists of two object-level streams: appearance and dynamics. In the appearance stream, an ``Object-Region Attention'' element applies self-attention over the patches and \emph{object regions}. In this way, visual object regions interact with uniform patch tokens and enrich them with contextualized object information. We further model object dynamics via a separate ``Object-Dynamics Module'', which captures trajectory interactions, and show how to integrate the two streams. We evaluate our model on standard and compositional action recognition on Something-Something V2, standard action recognition on Epic-Kitchen100 and Diving48, and spatio-temporal action detection on AVA. We show strong improvement in performance across all tasks and datasets considered, demonstrating the value of a model that incorporates object representations into a transformer architecture. For code and pretrained models, visit the project page at https://roeiherz.github.io/ORViT/.
A Theoretical Analysis of Fine-tuning with Linear Teachers
Jul 04, 2021
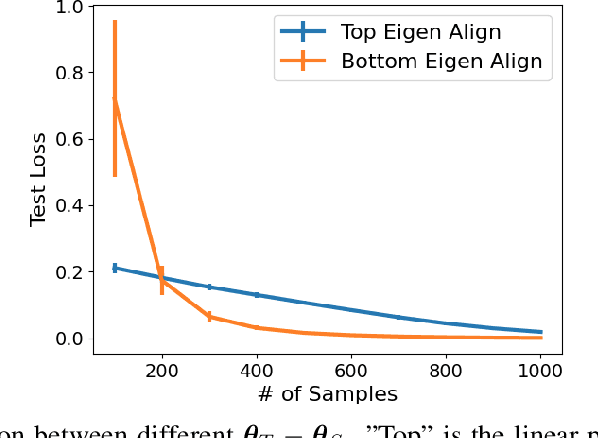
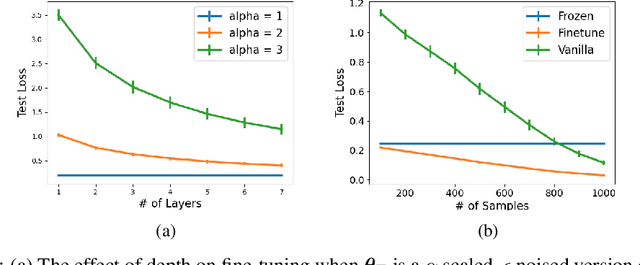
Fine-tuning is a common practice in deep learning, achieving excellent generalization results on downstream tasks using relatively little training data. Although widely used in practice, it is lacking strong theoretical understanding. We analyze the sample complexity of this scheme for regression with linear teachers in several architectures. Intuitively, the success of fine-tuning depends on the similarity between the source tasks and the target task, however measuring it is non trivial. We show that a relevant measure considers the relation between the source task, the target task and the covariance structure of the target data. In the setting of linear regression, we show that under realistic settings a substantial sample complexity reduction is plausible when the above measure is low. For deep linear regression, we present a novel result regarding the inductive bias of gradient-based training when the network is initialized with pretrained weights. Using this result we show that the similarity measure for this setting is also affected by the depth of the network. We further present results on shallow ReLU models, and analyze the dependence of sample complexity there on source and target tasks. We empirically demonstrate our results for both synthetic and realistic data.
DETReg: Unsupervised Pretraining with Region Priors for Object Detection
Jun 08, 2021
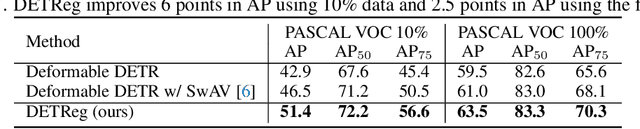
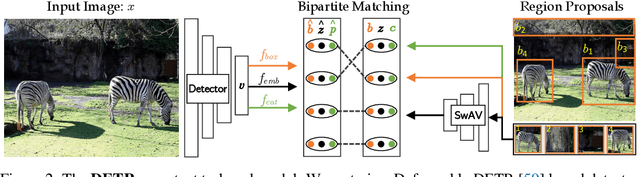
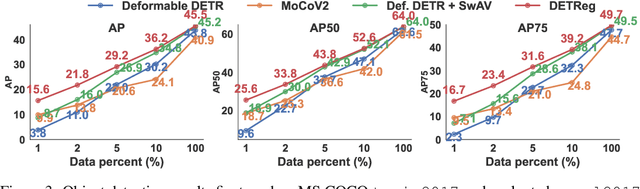
Unsupervised pretraining has recently proven beneficial for computer vision tasks, including object detection. However, previous self-supervised approaches are not designed to handle a key aspect of detection: localizing objects. Here, we present DETReg, an unsupervised pretraining approach for object DEtection with TRansformers using Region priors. Motivated by the two tasks underlying object detection: localization and categorization, we combine two complementary signals for self-supervision. For an object localization signal, we use pseudo ground truth object bounding boxes from an off-the-shelf unsupervised region proposal method, Selective Search, which does not require training data and can detect objects at a high recall rate and very low precision. The categorization signal comes from an object embedding loss that encourages invariant object representations, from which the object category can be inferred. We show how to combine these two signals to train the Deformable DETR detection architecture from large amounts of unlabeled data. DETReg improves the performance over competitive baselines and previous self-supervised methods on standard benchmarks like MS COCO and PASCAL VOC. DETReg also outperforms previous supervised and unsupervised baseline approaches on low-data regime when trained with only 1%, 2%, 5%, and 10% of the labeled data on MS COCO. For code and pretrained models, visit the project page at https://amirbar.net/detreg
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
Apr 27, 2021
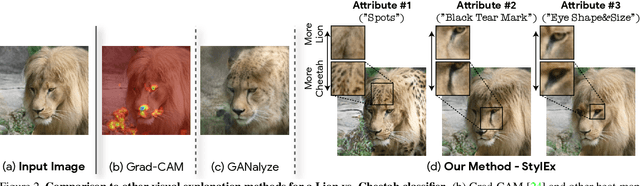
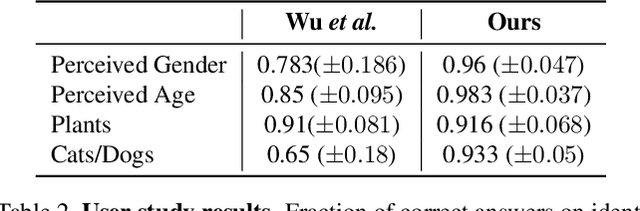
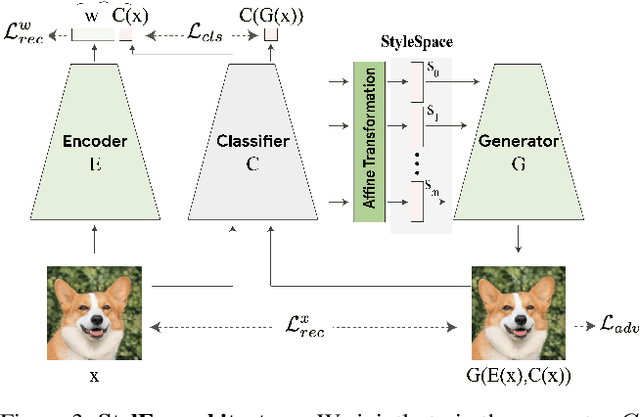
Image classification models can depend on multiple different semantic attributes of the image. An explanation of the decision of the classifier needs to both discover and visualize these properties. Here we present StylEx, a method for doing this, by training a generative model to specifically explain multiple attributes that underlie classifier decisions. A natural source for such attributes is the StyleSpace of StyleGAN, which is known to generate semantically meaningful dimensions in the image. However, because standard GAN training is not dependent on the classifier, it may not represent these attributes which are important for the classifier decision, and the dimensions of StyleSpace may represent irrelevant attributes. To overcome this, we propose a training procedure for a StyleGAN, which incorporates the classifier model, in order to learn a classifier-specific StyleSpace. Explanatory attributes are then selected from this space. These can be used to visualize the effect of changing multiple attributes per image, thus providing image-specific explanations. We apply StylEx to multiple domains, including animals, leaves, faces and retinal images. For these, we show how an image can be modified in different ways to change its classifier output. Our results show that the method finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are human-interpretable as measured in user-studies.
BERTese: Learning to Speak to BERT
Mar 11, 2021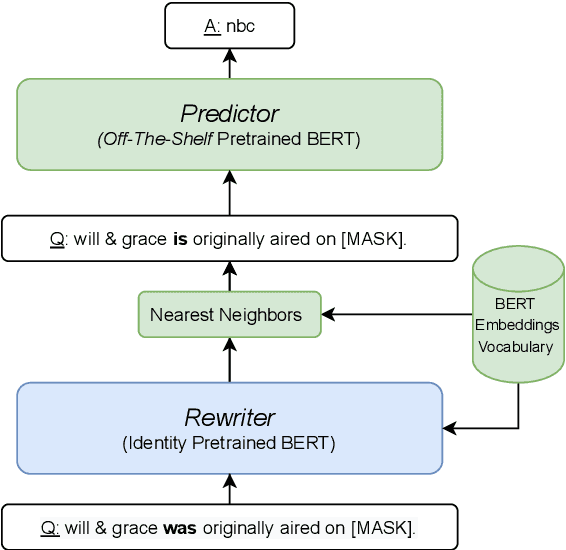



Large pre-trained language models have been shown to encode large amounts of world and commonsense knowledge in their parameters, leading to substantial interest in methods for extracting that knowledge. In past work, knowledge was extracted by taking manually-authored queries and gathering paraphrases for them using a separate pipeline. In this work, we propose a method for automatically rewriting queries into "BERTese", a paraphrase query that is directly optimized towards better knowledge extraction. To encourage meaningful rewrites, we add auxiliary loss functions that encourage the query to correspond to actual language tokens. We empirically show our approach outperforms competing baselines, obviating the need for complex pipelines. Moreover, BERTese provides some insight into the type of language that helps language models perform knowledge extraction.