 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAWQV3: Dyadic Neural Network Quantization
Nov 20, 2020
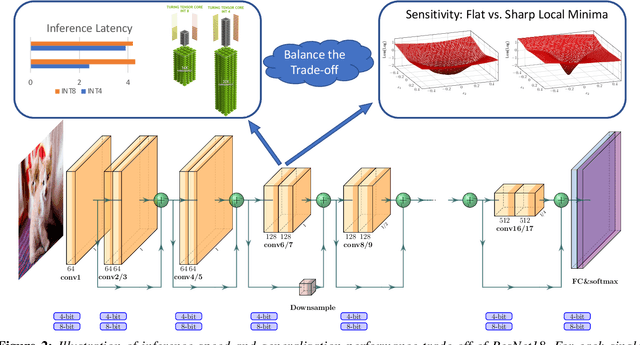
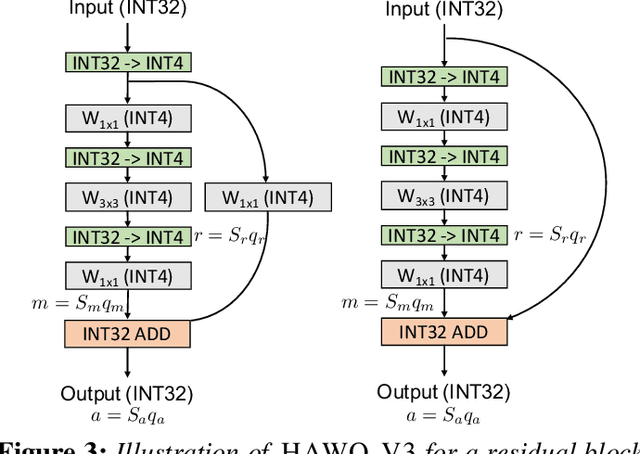
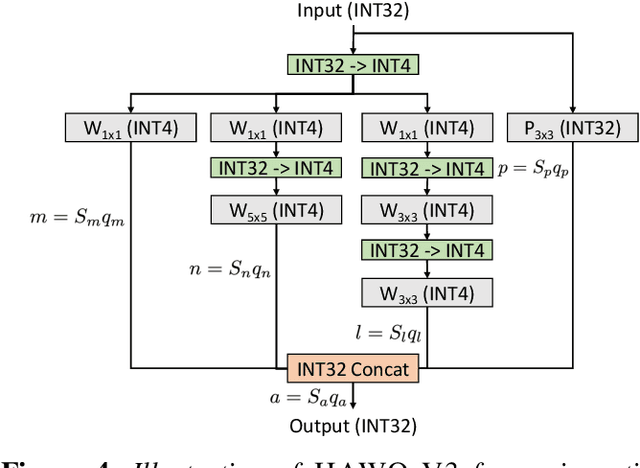
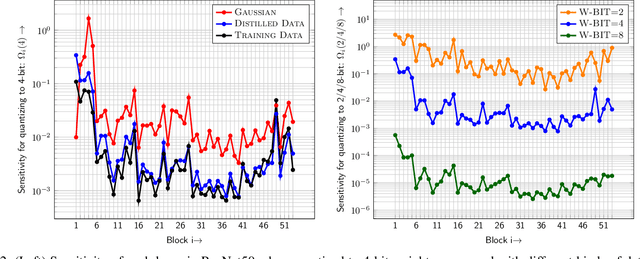
Quantization is one of the key techniques used to make Neural Networks (NNs) faster and more energy efficient. However, current low precision quantization algorithms often have the hidden cost of conversion back and forth from floating point to quantized integer values. This hidden cost limits the latency improvement realized by quantizing NNs. To address this, we present HAWQV3, a novel dyadic quantization framework. The contributions of HAWQV3 are the following. (i) The entire inference process consists of only integer multiplication, addition, and bit shifting in INT4/8 mixed precision, without any floating point operations/casting or even integer division. (ii) We pose the mixed-precision quantization as an integer linear programming problem, where the bit precision setting is computed to minimize model perturbation, while observing application specific constraints on memory footprint, latency, and BOPS. (iii) To verify our approach, we develop the first open source 4-bit mixed-precision quantization in TVM, and we directly deploy the quantized models to T4 GPUs using only the Turing Tensor Cores. We observe an average speed up of $1.45\times$ for uniform 4-bit, as compared to uniform 8-bit, precision for ResNet50. (iv) We extensively test the proposed dyadic quantization approach on multiple different NNs, including ResNet18/50 and InceptionV3, for various model compression levels with/without mixed precision. For instance, we achieve an accuracy of $78.50\%$ with dyadic INT8 quantization, which is more than $4\%$ higher than prior integer-only work for InceptionV3. Furthermore, we show that mixed-precision INT4/8 quantization can be used to achieve higher speed ups, as compared to INT8 inference, with minimal impact on accuracy. For example, for ResNet50 we can reduce INT8 latency by $23\%$ with mixed precision and still achieve $76.73\%$ accuracy.
Boundary thickness and robustness in learning models
Jul 09, 2020
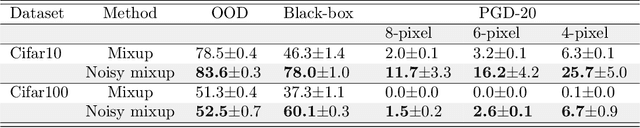
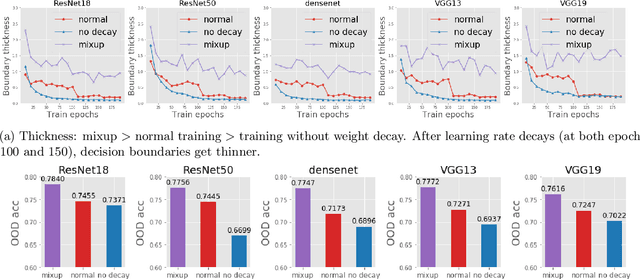
Robustness of machine learning models to various adversarial and non-adversarial corruptions continues to be of interest. In this paper, we introduce the notion of the boundary thickness of a classifier, and we describe its connection with and usefulness for model robustness. Thick decision boundaries lead to improved performance, while thin decision boundaries lead to overfitting (e.g., measured by the robust generalization gap between training and testing) and lower robustness. We show that a thicker boundary helps improve robustness against adversarial examples (e.g., improving the robust test accuracy of adversarial training) as well as so-called out-of-distribution (OOD) transforms, and we show that many commonly-used regularization and data augmentation procedures can increase boundary thickness. On the theoretical side, we establish that maximizing boundary thickness during training is akin to the so-called mixup training. Using these observations, we show that noise-augmentation on mixup training further increases boundary thickness, thereby combating vulnerability to various forms of adversarial attacks and OOD transforms. We can also show that the performance improvement in several lines of recent work happens in conjunction with a thicker boundary.
ADAHESSIAN: An Adaptive Second Order Optimizer for Machine Learning
Jun 01, 2020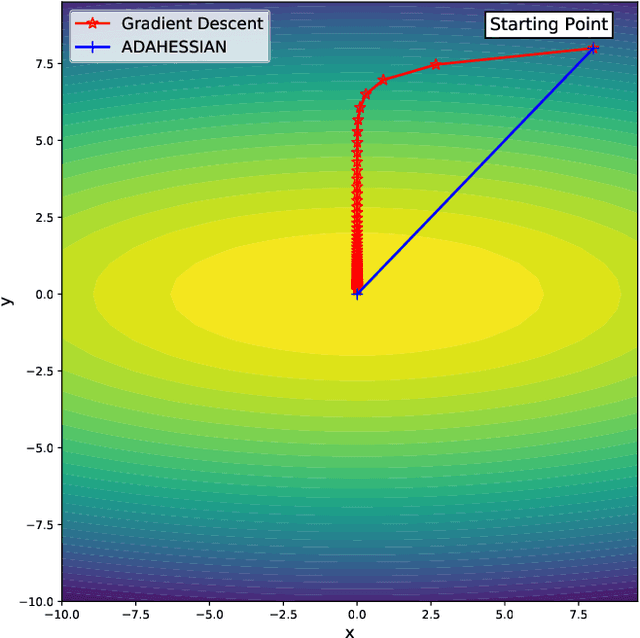
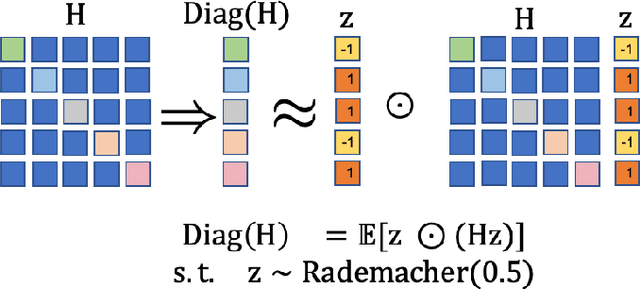
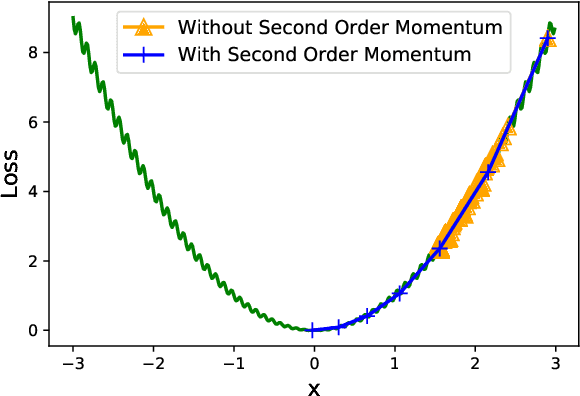
We introduce AdaHessian, a second order stochastic optimization algorithm which dynamically incorporates the curvature of the loss function via ADAptive estimates of the Hessian. Second order algorithms are among the most powerful optimization algorithms with superior convergence properties as compared to first order methods such as SGD and ADAM. The main disadvantage of traditional second order methods is their heavier per-iteration computation and poor accuracy as compared to first order methods. To address these, we incorporate several novel approaches in AdaHessian, including: (i) a new variance reduction estimate of the Hessian diagonal with low computational overhead; (ii) a root-mean-square exponential moving average to smooth out variations of the Hessian diagonal across different iterations; and (iii) a block diagonal averaging to reduce the variance of Hessian diagonal elements. We show that AdaHessian achieves new state-of-the-art results by a large margin as compared to other adaptive optimization methods, including variants of ADAM. In particular, we perform extensive tests on CV, NLP, and recommendation system tasks and find that AdaHessian: (i) achieves 1.80\%/1.45\% higher accuracy on ResNets20/32 on Cifar10, and 5.55\% higher accuracy on ImageNet as compared to ADAM; (ii) outperforms ADAMW for transformers by 0.27/0.33 BLEU score on IWSLT14/WMT14 and 1.8/1.0 PPL on PTB/Wikitext-103; and (iii) achieves 0.032\% better score than AdaGrad for DLRM on the Criteo Ad Kaggle dataset. Importantly, we show that the cost per iteration of AdaHessian is comparable to first-order methods, and that it exhibits robustness towards its hyperparameters. The code for AdaHessian is open-sourced and publicly available.
Rethinking Batch Normalization in Transformers
Mar 17, 2020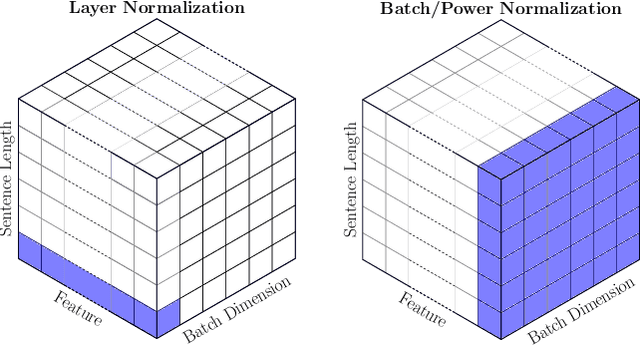
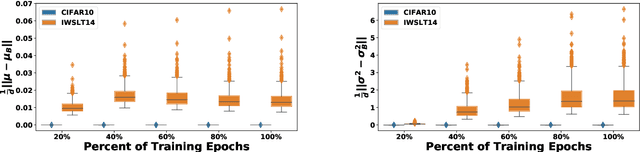
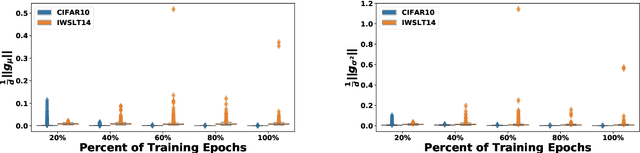
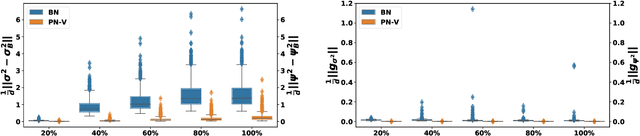
The standard normalization method for neural network (NN) models used in Natural Language Processing (NLP) is layer normalization (LN). This is different than batch normalization (BN), which is widely-adopted in Computer Vision. The preferred use of LN in NLP is principally due to the empirical observation that a (naive/vanilla) use of BN leads to significant performance degradation for NLP tasks; however, a thorough understanding of the underlying reasons for this is not always evident. In this paper, we perform a systematic study of NLP transformer models to understand why BN has a poor performance, as compared to LN. We find that the statistics of NLP data across the batch dimension exhibit large fluctuations throughout training. This results in instability, if BN is naively implemented. To address this, we propose Power Normalization (PN), a novel normalization scheme that resolves this issue by (i) relaxing zero-mean normalization in BN, (ii) incorporating a running quadratic mean instead of per batch statistics to stabilize fluctuations, and (iii) using an approximate backpropagation for incorporating the running statistics in the forward pass. We show theoretically, under mild assumptions, that PN leads to a smaller Lipschitz constant for the loss, compared with BN. Furthermore, we prove that the approximate backpropagation scheme leads to bounded gradients. We extensively test PN for transformers on a range of NLP tasks, and we show that it significantly outperforms both LN and BN. In particular, PN outperforms LN by 0.4/0.6 BLEU on IWSLT14/WMT14 and 5.6/3.0 PPL on PTB/WikiText-103.
PyHessian: Neural Networks Through the Lens of the Hessian
Jan 02, 2020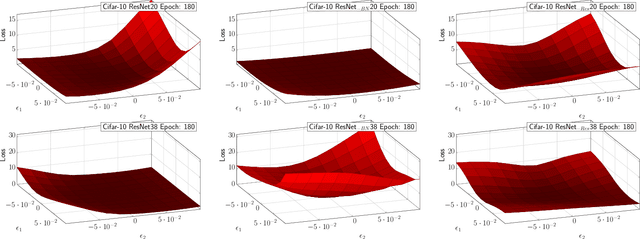
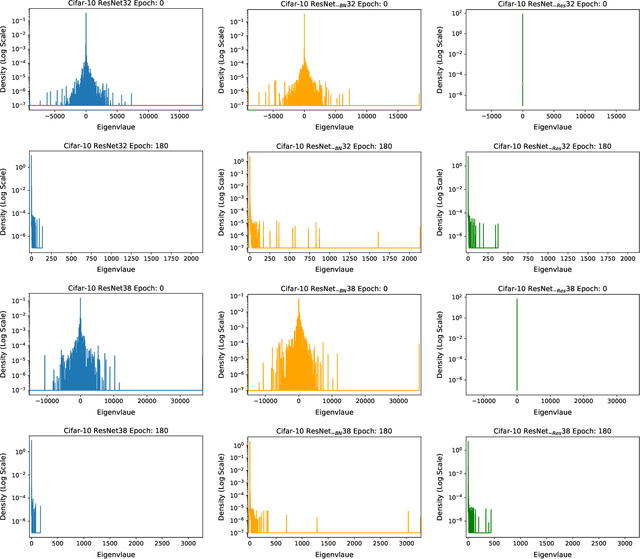
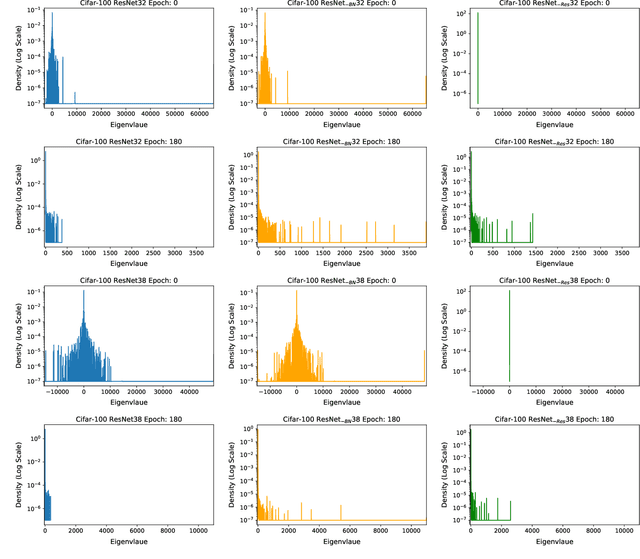
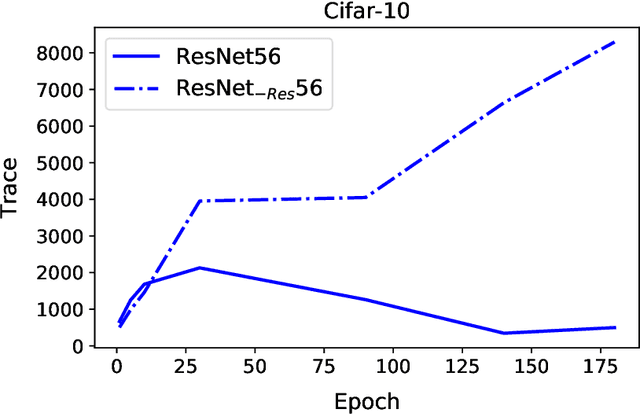
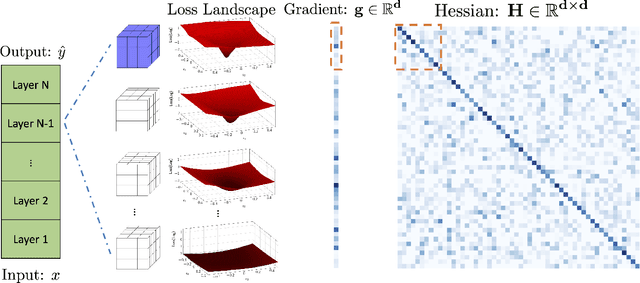
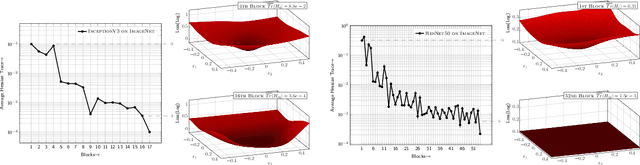
We present PyHessian, a new scalable framework that enables fast computation of Hessian (i.e., second-order derivative) information for deep neural networks. This framework is developed in Pytorch, and it enables distributed-memory execution on both cloud and supercomputer systems. PyHessian enables fast computations of the top Hessian eigenvalues, the Hessian trace, and the full Hessian eigenvalue/spectral density. This general framework can be used to analyze neural network models, including the topology of the loss landscape (i.e., curvature information) to gain insight into the behavior of different models/optimizers. To illustrate this, we apply PyHessian to analyze the effect of residual connections and Batch Normalization layers on the smoothness of the loss landscape during training. One recent claim, based on simpler first-order analysis, is that residual connections and Batch Normalization make the loss landscape ``smoother,'' thus making it easier for Stochastic Gradient Descent to converge to a good solution. We perform an extensive analysis of this hypothesis, on four residual networks (ResNet20/32/38/56) on the Cifar-10/100 dataset, by measuring directly the Hessian spectrum using PyHessian. This analysis leads to finer-scale insight, demonstrating that while conventional wisdom is sometimes validated, in other cases it is simply incorrect. In particular, we find that Batch Normalization layers do not necessarily make the loss landscape smoother, especially for shallow networks. Instead, the claimed smoother loss landscape only becomes evident for deeper neural networks, at least within this ResNet series. We have open-sourced the PyHessian framework for Hessian spectrum computation.
ZeroQ: A Novel Zero Shot Quantization Framework
Jan 01, 2020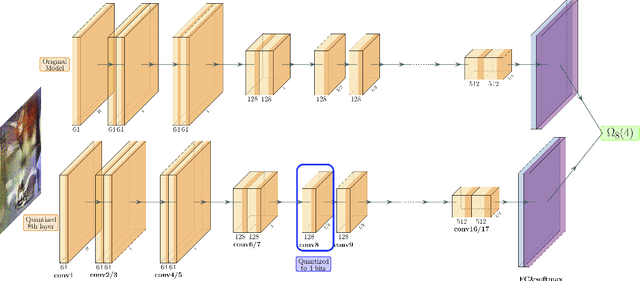

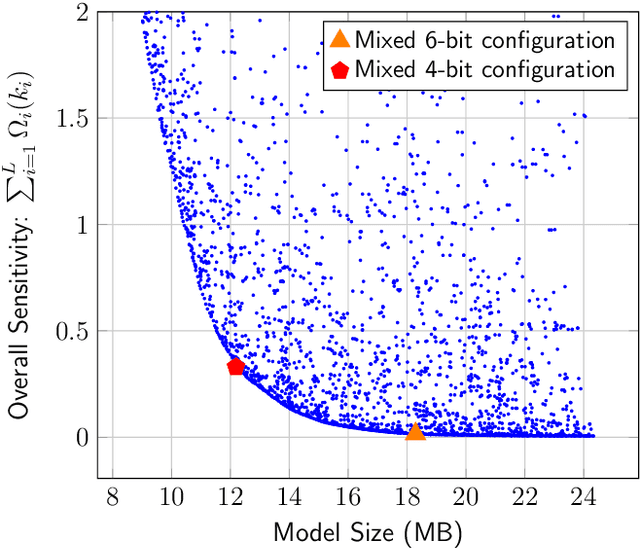
Quantization is a promising approach for reducing the inference time and memory footprint of neural networks. However, most existing quantization methods require access to the original training dataset for retraining during quantization. This is often not possible for applications with sensitive or proprietary data, e.g., due to privacy and security concerns. Existing zero-shot quantization methods use different heuristics to address this, but they result in poor performance, especially when quantizing to ultra-low precision. Here, we propose ZeroQ , a novel zero-shot quantization framework to address this. ZeroQ enables mixed-precision quantization without any access to the training or validation data. This is achieved by optimizing for a Distilled Dataset, which is engineered to match the statistics of batch normalization across different layers of the network. ZeroQ supports both uniform and mixed-precision quantization. For the latter, we introduce a novel Pareto frontier based method to automatically determine the mixed-precision bit setting for all layers, with no manual search involved. We extensively test our proposed method on a diverse set of models, including ResNet18/50/152, MobileNetV2, ShuffleNet, SqueezeNext, and InceptionV3 on ImageNet, as well as RetinaNet-ResNet50 on the Microsoft COCO dataset. In particular, we show that ZeroQ can achieve 1.71\% higher accuracy on MobileNetV2, as compared to the recently proposed DFQ method. Importantly, ZeroQ has a very low computational overhead, and it can finish the entire quantization process in less than 30s (0.5\% of one epoch training time of ResNet50 on ImageNet). We have open-sourced the ZeroQ framework\footnote{https://github.com/amirgholami/ZeroQ}.
HAWQ-V2: Hessian Aware trace-Weighted Quantization of Neural Networks
Nov 10, 2019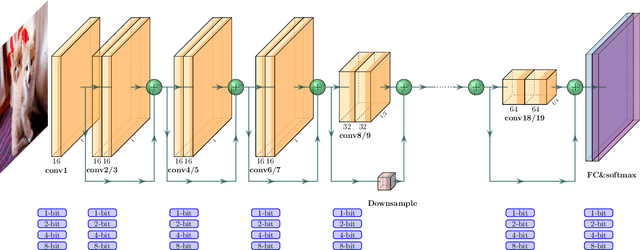
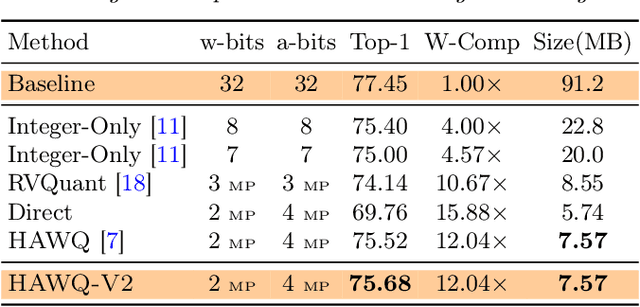
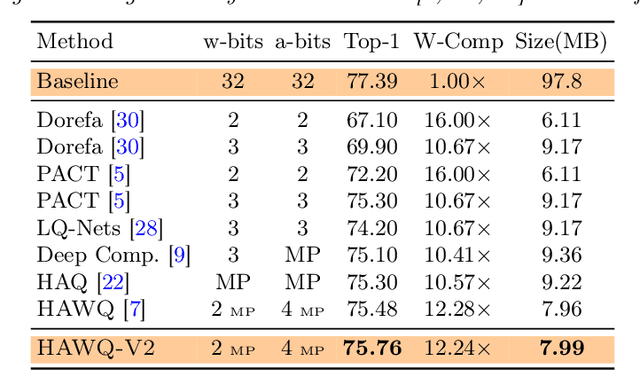
Quantization is an effective method for reducing memory footprint and inference time of Neural Networks, e.g., for efficient inference in the cloud, especially at the edge. However, ultra low precision quantization could lead to significant degradation in model generalization. A promising method to address this is to perform mixed-precision quantization, where more sensitive layers are kept at higher precision. However, the search space for a mixed-precision quantization is exponential in the number of layers. Recent work has proposed HAWQ, a novel Hessian based framework, with the aim of reducing this exponential search space by using second-order information. While promising, this prior work has three major limitations: (i) HAWQV1 only uses the top Hessian eigenvalue as a measure of sensitivity and do not consider the rest of the Hessian spectrum; (ii) HAWQV1 approach only provides relative sensitivity of different layers and therefore requires a manual selection of the mixed-precision setting; and (iii) HAWQV1 does not consider mixed-precision activation quantization. Here, we present HAWQV2 which addresses these shortcomings. For (i), we perform a theoretical analysis showing that a better sensitivity metric is to compute the average of all of the Hessian eigenvalues. For (ii), we develop a Pareto frontier based method for selecting the exact bit precision of different layers without any manual selection. For (iii), we extend the Hessian analysis to mixed-precision activation quantization. We have found this to be very beneficial for object detection. We show that HAWQV2 achieves new state-of-the-art results for a wide range of tasks.
Checkmate: Breaking the Memory Wall with Optimal Tensor Rematerialization
Oct 07, 2019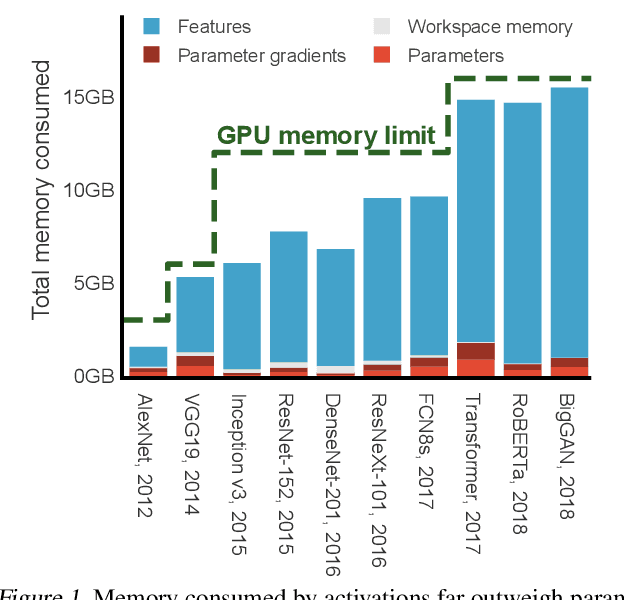

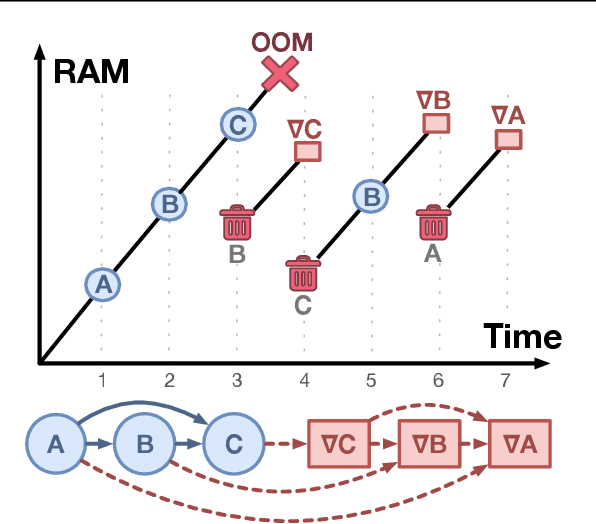
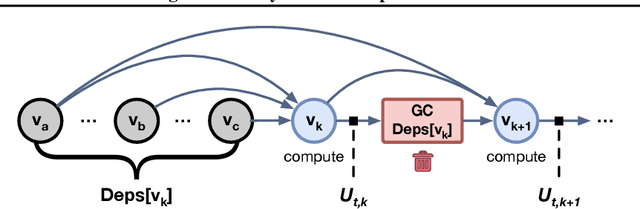
Modern neural networks are increasingly bottlenecked by the limited capacity of on-device GPU memory. Prior work explores dropping activations as a strategy to scale to larger neural networks under memory constraints. However, these heuristics assume uniform per-layer costs and are limited to simple architectures with linear graphs, limiting their usability. In this paper, we formalize the problem of trading-off DNN training time and memory requirements as the tensor rematerialization optimization problem, a generalization of prior checkpointing strategies. We introduce Checkmate, a system that solves for optimal schedules in reasonable times (under an hour) using off-the-shelf MILP solvers, then uses these schedules to accelerate millions of training iterations. Our method scales to complex, realistic architectures and is hardware-aware through the use of accelerator-specific, profile-based cost models. In addition to reducing training cost, Checkmate enables real-world networks to be trained with up to 5.1$\times$ larger input sizes.
Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
Sep 25, 2019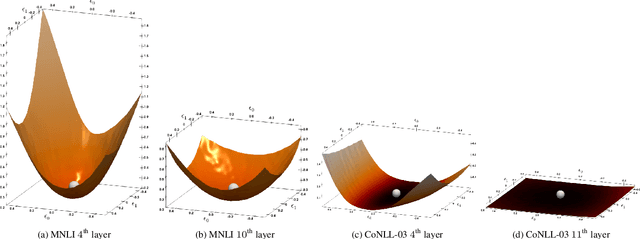
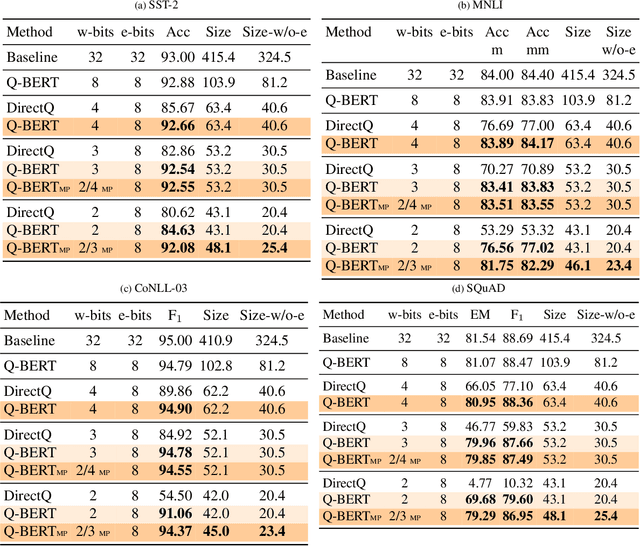
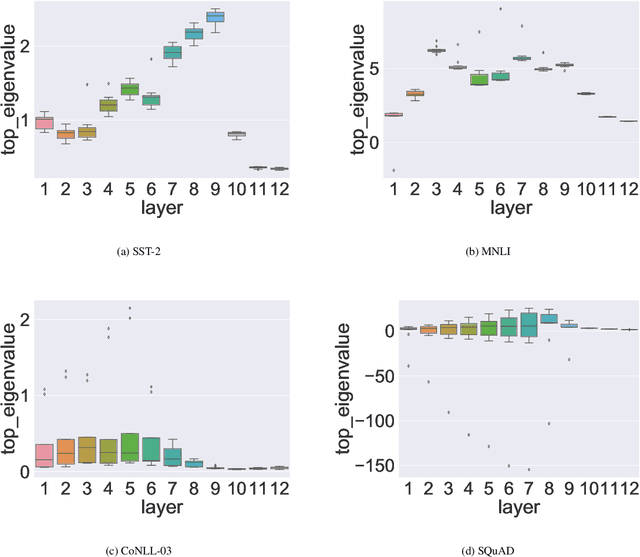
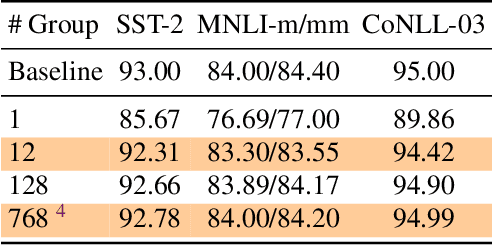
Transformer based architectures have become de-facto models used for a range of Natural Language Processing tasks. In particular, the BERT based models achieved significant accuracy gain for GLUE tasks, CoNLL-03 and SQuAD. However, BERT based models have a prohibitive memory footprint and latency. As a result, deploying BERT based models in resource constrained environments has become a challenging task. In this work, we perform an extensive analysis of fine-tuned BERT models using second order Hessian information, and we use our results to propose a novel method for quantizing BERT models to ultra low precision. In particular, we propose a new group-wise quantization scheme, and we use a Hessian based mix-precision method to compress the model further. We extensively test our proposed method on BERT downstream tasks of SST-2, MNLI, CoNLL-03, and SQuAD. We can achieve comparable performance to baseline with at most $2.3\%$ performance degradation, even with ultra-low precision quantization down to 2 bits, corresponding up to $13\times$ compression of the model parameters, and up to $4\times$ compression of the embedding table as well as activations. Among all tasks, we observed the highest performance loss for BERT fine-tuned on SQuAD. By probing into the Hessian based analysis as well as visualization, we show that this is related to the fact that current training/fine-tuning strategy of BERT does not converge for SQuAD.
ANODEV2: A Coupled Neural ODE Evolution Framework
Jun 10, 2019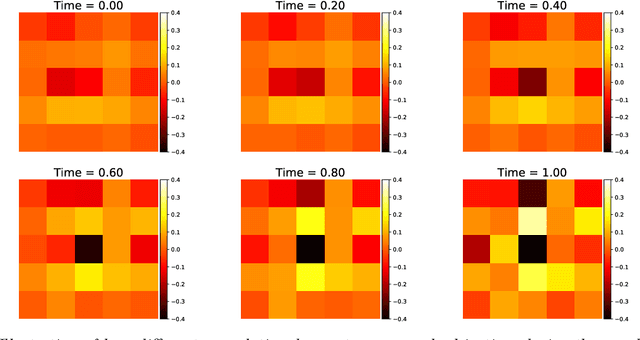

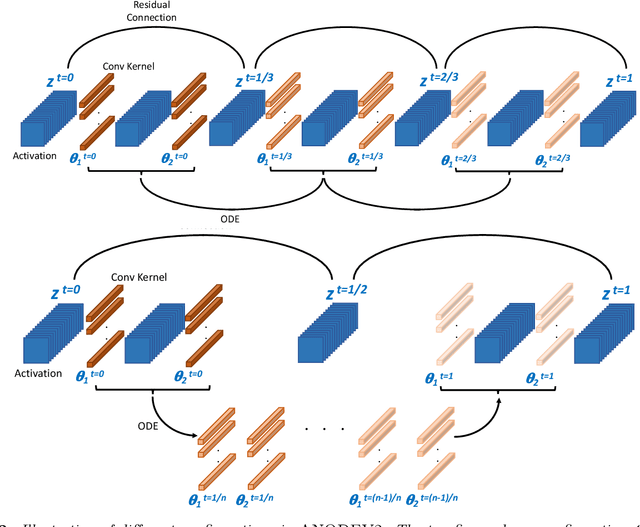

It has been observed that residual networks can be viewed as the explicit Euler discretization of an Ordinary Differential Equation (ODE). This observation motivated the introduction of so-called Neural ODEs, which allow more general discretization schemes with adaptive time stepping. Here, we propose ANODEV2, which is an extension of this approach that also allows evolution of the neural network parameters, in a coupled ODE-based formulation. The Neural ODE method introduced earlier is in fact a special case of this new more general framework. We present the formulation of ANODEV2, derive optimality conditions, and implement a coupled reaction-diffusion-advection version of this framework in PyTorch. We present empirical results using several different configurations of ANODEV2, testing them on multiple models on CIFAR-10. We report results showing that this coupled ODE-based framework is indeed trainable, and that it achieves higher accuracy, as compared to the baseline models as well as the recently-proposed Neural ODE approach.