 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Application-Grounded Experimental Design for Evaluating Explainable ML Methods
Jun 30, 2022
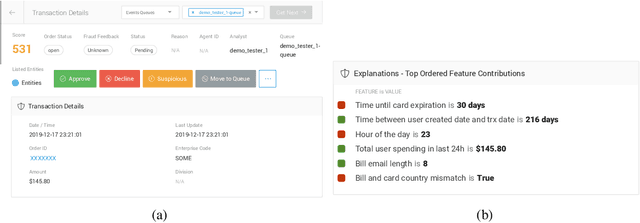
Machine Learning (ML) models now inform a wide range of human decisions, but using ``black box'' models carries risks such as relying on spurious correlations or errant data. To address this, researchers have proposed methods for supplementing models with explanations of their predictions. However, robust evaluations of these methods' usefulness in real-world contexts have remained elusive, with experiments tending to rely on simplified settings or proxy tasks. We present an experimental study extending a prior explainable ML evaluation experiment and bringing the setup closer to the deployment setting by relaxing its simplifying assumptions. Our empirical study draws dramatically different conclusions than the prior work, highlighting how seemingly trivial experimental design choices can yield misleading results. Beyond the present experiment, we believe this work holds lessons about the necessity of situating the evaluation of any ML method and choosing appropriate tasks, data, users, and metrics to match the intended deployment contexts.
Use-Case-Grounded Simulations for Explanation Evaluation
Jun 05, 2022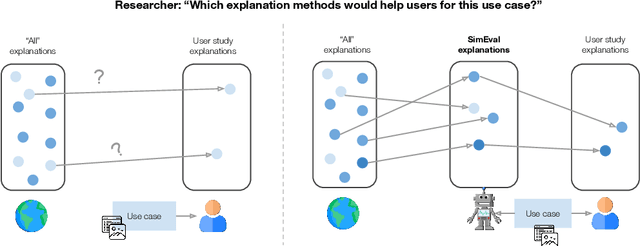
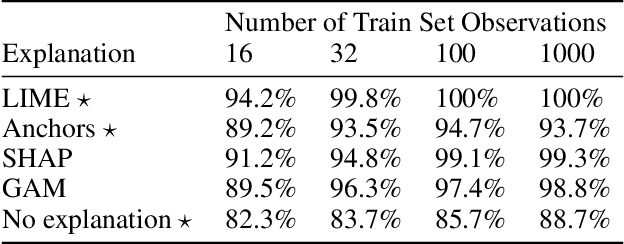
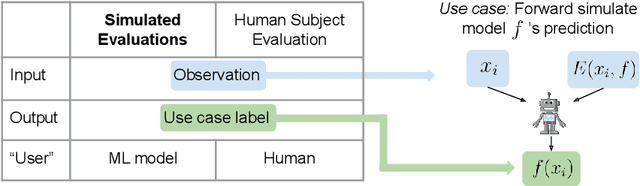
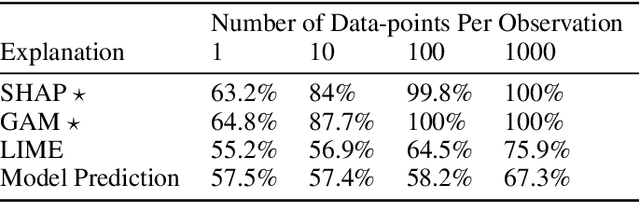
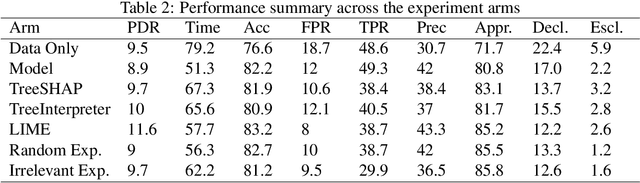
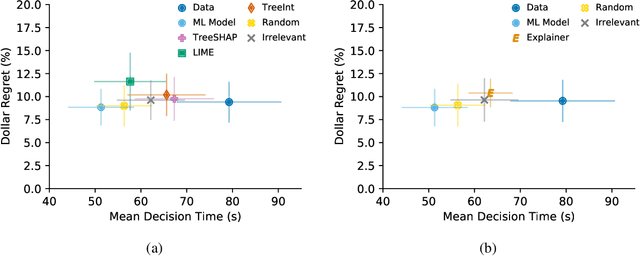
A growing body of research runs human subject evaluations to study whether providing users with explanations of machine learning models can help them with practical real-world use cases. However, running user studies is challenging and costly, and consequently each study typically only evaluates a limited number of different settings, e.g., studies often only evaluate a few arbitrarily selected explanation methods. To address these challenges and aid user study design, we introduce Use-Case-Grounded Simulated Evaluations (SimEvals). SimEvals involve training algorithmic agents that take as input the information content (such as model explanations) that would be presented to each participant in a human subject study, to predict answers to the use case of interest. The algorithmic agent's test set accuracy provides a measure of the predictiveness of the information content for the downstream use case. We run a comprehensive evaluation on three real-world use cases (forward simulation, model debugging, and counterfactual reasoning) to demonstrate that Simevals can effectively identify which explanation methods will help humans for each use case. These results provide evidence that SimEvals can be used to efficiently screen an important set of user study design decisions, e.g. selecting which explanations should be presented to the user, before running a potentially costly user study.
AANG: Automating Auxiliary Learning
May 27, 2022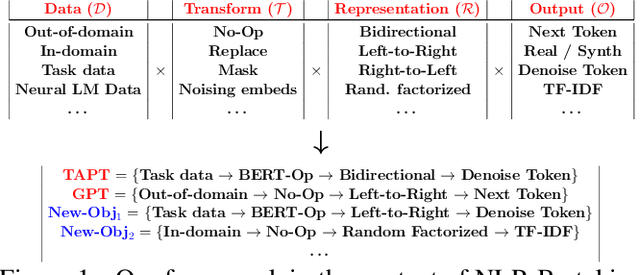

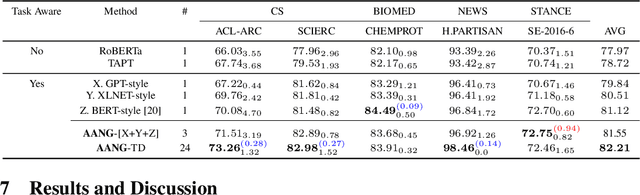
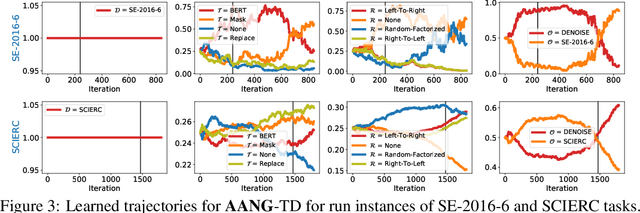
When faced with data-starved or highly complex end-tasks, it is commonplace for machine learning practitioners to introduce auxiliary objectives as supplementary learning signals. Whilst much work has been done to formulate useful auxiliary objectives, their construction is still an art which proceeds by slow and tedious hand-design. Intuitions about how and when these objectives improve end-task performance have also had limited theoretical backing. In this work, we present an approach for automatically generating a suite of auxiliary objectives. We achieve this by deconstructing existing objectives within a novel unified taxonomy, identifying connections between them, and generating new ones based on the uncovered structure. Next, we theoretically formalize widely-held intuitions about how auxiliary learning improves generalization of the end-task. This leads us to a principled and efficient algorithm for searching the space of generated objectives to find those most useful to a specified end-task. With natural language processing (NLP) as our domain of study, we empirically verify that our automated auxiliary learning pipeline leads to strong improvements over competitive baselines across continued training experiments on a pre-trained model on 5 NLP end-tasks.
Perspectives on Incorporating Expert Feedback into Model Updates
May 13, 2022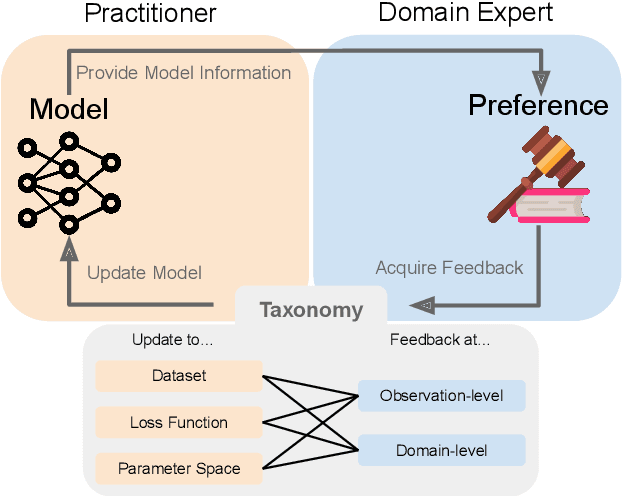
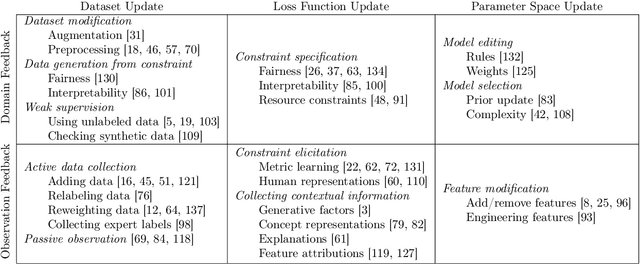
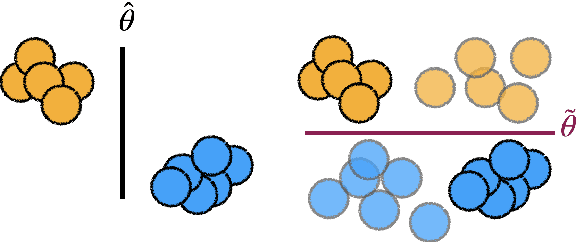
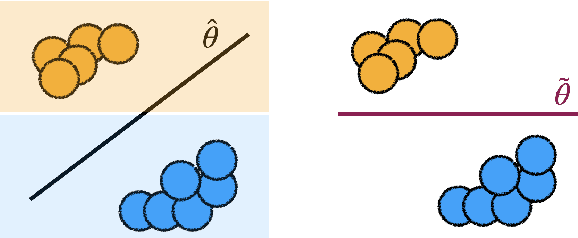
Machine learning (ML) practitioners are increasingly tasked with developing models that are aligned with non-technical experts' values and goals. However, there has been insufficient consideration on how practitioners should translate domain expertise into ML updates. In this paper, we consider how to capture interactions between practitioners and experts systematically. We devise a taxonomy to match expert feedback types with practitioner updates. A practitioner may receive feedback from an expert at the observation- or domain-level, and convert this feedback into updates to the dataset, loss function, or parameter space. We review existing work from ML and human-computer interaction to describe this feedback-update taxonomy, and highlight the insufficient consideration given to incorporating feedback from non-technical experts. We end with a set of open questions that naturally arise from our proposed taxonomy and subsequent survey.
Efficient Architecture Search for Diverse Tasks
Apr 15, 2022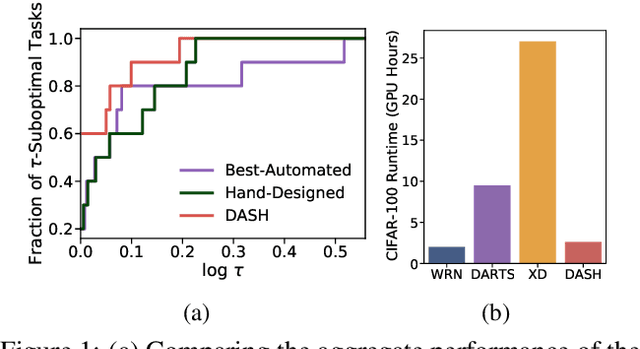

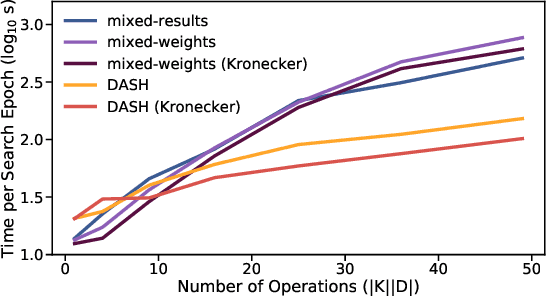
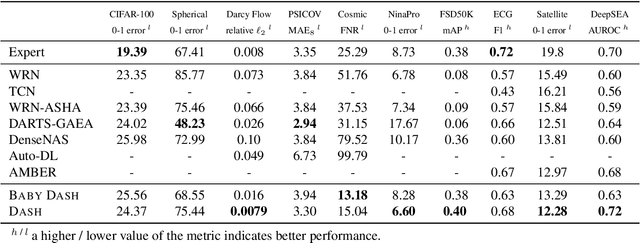
While neural architecture search (NAS) has enabled automated machine learning (AutoML) for well-researched areas, its application to tasks beyond computer vision is still under-explored. As less-studied domains are precisely those where we expect AutoML to have the greatest impact, in this work we study NAS for efficiently solving diverse problems. Seeking an approach that is fast, simple, and broadly applicable, we fix a standard convolutional network (CNN) topology and propose to search for the right kernel sizes and dilations its operations should take on. This dramatically expands the model's capacity to extract features at multiple resolutions for different types of data while only requiring search over the operation space. To overcome the efficiency challenges of naive weight-sharing in this search space, we introduce DASH, a differentiable NAS algorithm that computes the mixture-of-operations using the Fourier diagonalization of convolution, achieving both a better asymptotic complexity and an up-to-10x search time speedup in practice. We evaluate DASH on NAS-Bench-360, a suite of ten tasks designed for benchmarking NAS in diverse domains. DASH outperforms state-of-the-art methods in aggregate, attaining the best-known automated performance on seven tasks. Meanwhile, on six of the ten tasks, the combined search and retraining time is less than 2x slower than simply training a CNN backbone that is far less accurate.
Learning Predictions for Algorithms with Predictions
Feb 18, 2022
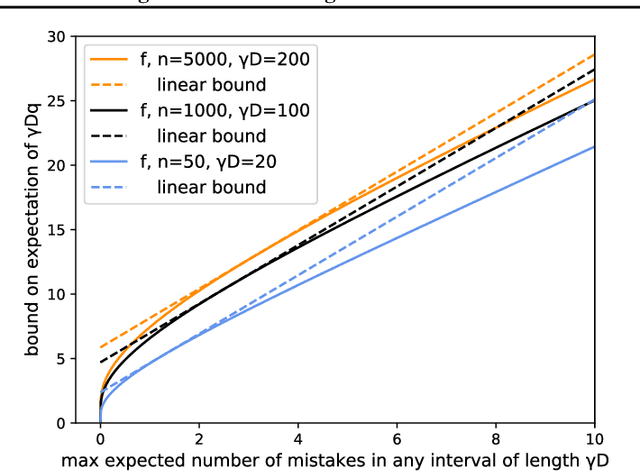
A burgeoning paradigm in algorithm design is the field of algorithms with predictions, in which algorithms are designed to take advantage of a possibly-imperfect prediction of some aspect of the problem. While much work has focused on using predictions to improve competitive ratios, running times, or other performance measures, less effort has been devoted to the question of how to obtain the predictions themselves, especially in the critical online setting. We introduce a general design approach for algorithms that learn predictors: (1) identify a functional dependence of the performance measure on the prediction quality, and (2) apply techniques from online learning to learn predictors against adversarial instances, tune robustness-consistency trade-offs, and obtain new statistical guarantees. We demonstrate the effectiveness of our approach at deriving learning algorithms by analyzing methods for bipartite matching, page migration, ski-rental, and job scheduling. In the first and last settings we improve upon existing learning-theoretic results by deriving online results, obtaining better or more general statistical guarantees, and utilizing a much simpler analysis, while in the second and fourth we provide the first learning-theoretic guarantees.
Bayesian Persuasion for Algorithmic Recourse
Dec 12, 2021
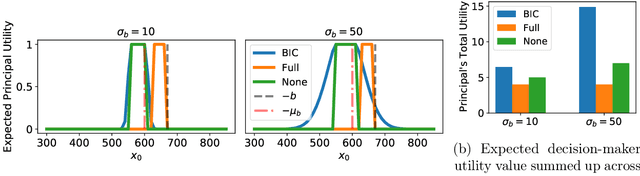
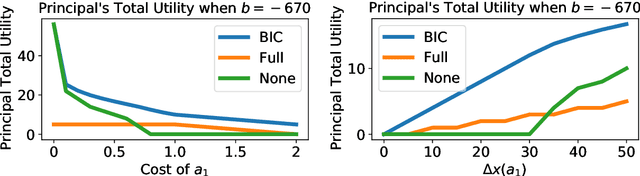
When subjected to automated decision-making, decision-subjects will strategically modify their observable features in ways they believe will maximize their chances of receiving a desirable outcome. In many situations, the underlying predictive model is deliberately kept secret to avoid gaming and maintain competitive advantage. This opacity forces the decision subjects to rely on incomplete information when making strategic feature modifications. We capture such settings as a game of Bayesian persuasion, in which the decision-maker sends a signal, e.g., an action recommendation, to a decision subject to incentivize them to take desirable actions. We formulate the decision-maker's problem of finding the optimal Bayesian incentive-compatible (BIC) action recommendation policy as an optimization problem and characterize the solution via a linear program. Through this characterization, we observe that while the problem of finding the optimal BIC recommendation policy can be simplified dramatically, the computational complexity of solving this linear program is closely tied to (1) the relative size of the decision-subjects' action space, and (2) the number of features utilized by the underlying predictive model. Finally, we provide bounds on the performance of the optimal BIC recommendation policy and show that it can lead to arbitrarily better outcomes compared to standard baselines.
NAS-Bench-360: Benchmarking Diverse Tasks for Neural Architecture Search
Oct 26, 2021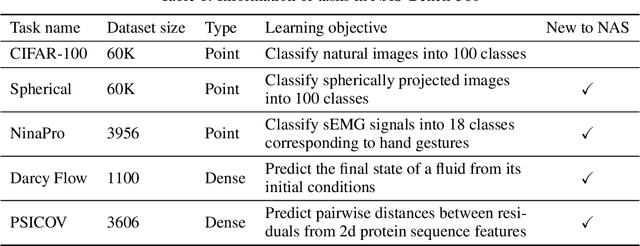
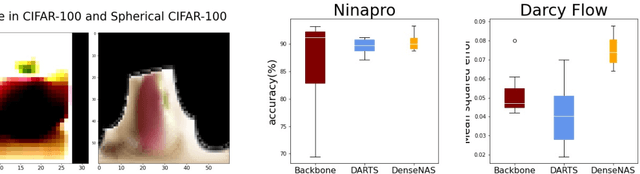
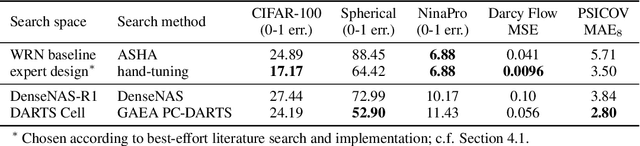
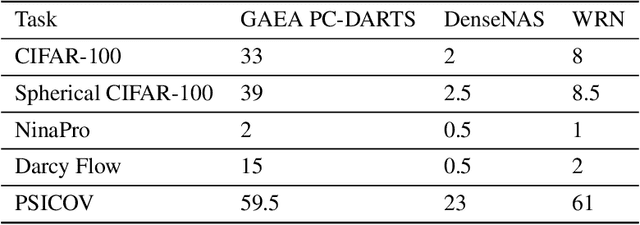
Most existing neural architecture search (NAS) benchmarks and algorithms prioritize performance on well-studied tasks, e.g., image classification on CIFAR and ImageNet. This makes the applicability of NAS approaches in more diverse areas inadequately understood. In this paper, we present NAS-Bench-360, a benchmark suite for evaluating state-of-the-art NAS methods for convolutional neural networks (CNNs). To construct it, we curate a collection of ten tasks spanning a diverse array of application domains, dataset sizes, problem dimensionalities, and learning objectives. By carefully selecting tasks that can both interoperate with modern CNN-based search methods but that are also far-afield from their original development domain, we can use NAS-Bench-360 to investigate the following central question: do existing state-of-the-art NAS methods perform well on diverse tasks? Our experiments show that a modern NAS procedure designed for image classification can indeed find good architectures for tasks with other dimensionalities and learning objectives; however, the same method struggles against more task-specific methods and performs catastrophically poorly on classification in non-vision domains. The case for NAS robustness becomes even more dire in a resource-constrained setting, where a recent NAS method provides little-to-no benefit over much simpler baselines. These results demonstrate the need for a benchmark such as NAS-Bench-360 to help develop NAS approaches that work well on a variety of tasks, a crucial component of a truly robust and automated pipeline. We conclude with a demonstration of the kind of future research our suite of tasks will enable. All data and code is made publicly available.
Should We Be Pre-training? An Argument for End-task Aware Training as an Alternative
Sep 15, 2021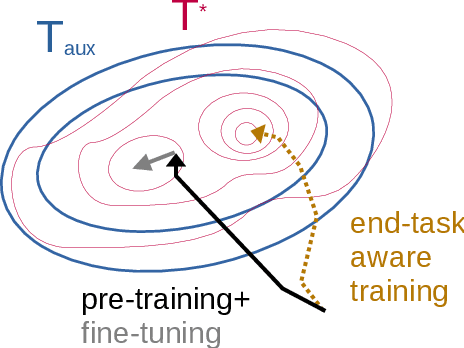

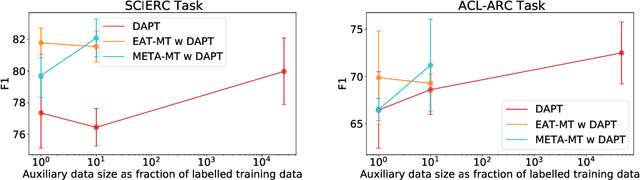
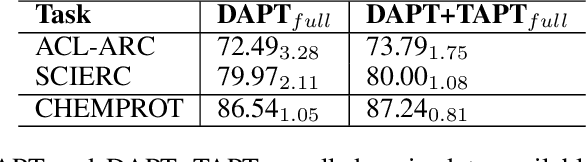
Pre-training, where models are trained on an auxiliary objective with abundant data before being fine-tuned on data from the downstream task, is now the dominant paradigm in NLP. In general, the pre-training step relies on little to no direct knowledge of the task on which the model will be fine-tuned, even when the end-task is known in advance. Our work challenges this status-quo of end-task agnostic pre-training. First, on three different low-resource NLP tasks from two domains, we demonstrate that multi-tasking the end-task and auxiliary objectives results in significantly better downstream task performance than the widely-used task-agnostic continued pre-training paradigm of Gururangan et al. (2020). We next introduce an online meta-learning algorithm that learns a set of multi-task weights to better balance among our multiple auxiliary objectives, achieving further improvements on end task performance and data efficiency.
Learning-to-learn non-convex piecewise-Lipschitz functions
Aug 19, 2021
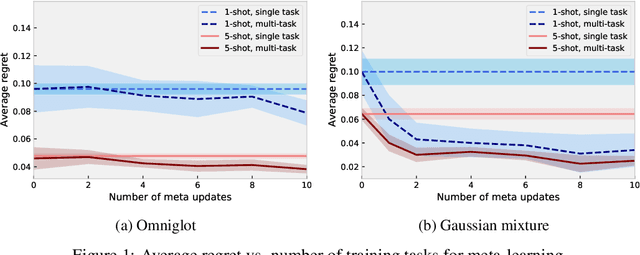
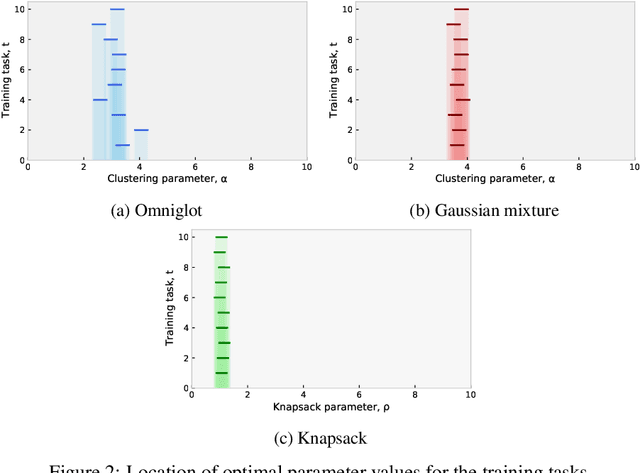
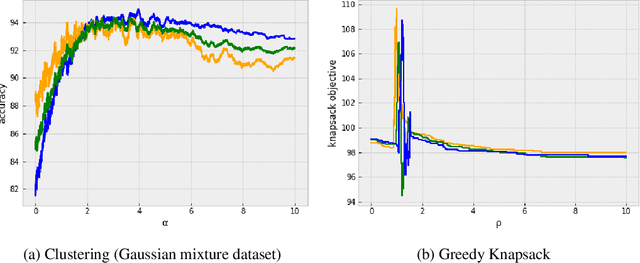
We analyze the meta-learning of the initialization and step-size of learning algorithms for piecewise-Lipschitz functions, a non-convex setting with applications to both machine learning and algorithms. Starting from recent regret bounds for the exponential forecaster on losses with dispersed discontinuities, we generalize them to be initialization-dependent and then use this result to propose a practical meta-learning procedure that learns both the initialization and the step-size of the algorithm from multiple online learning tasks. Asymptotically, we guarantee that the average regret across tasks scales with a natural notion of task-similarity that measures the amount of overlap between near-optimal regions of different tasks. Finally, we instantiate the method and its guarantee in two important settings: robust meta-learning and multi-task data-driven algorithm design.