 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAVA: A Foundational Language And Vision Alignment Model
Dec 08, 2021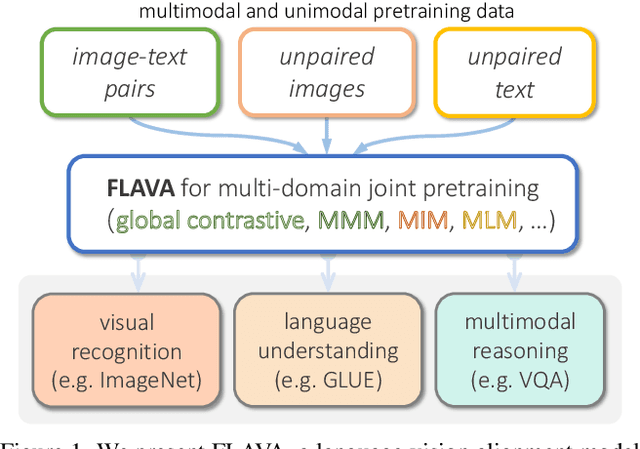
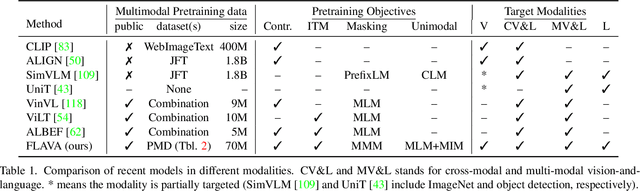
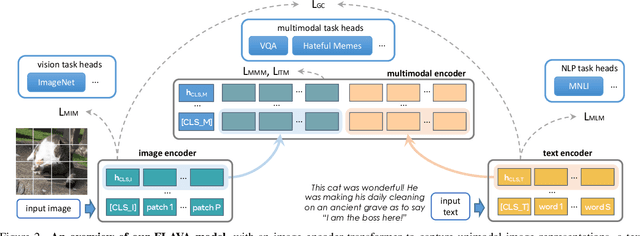
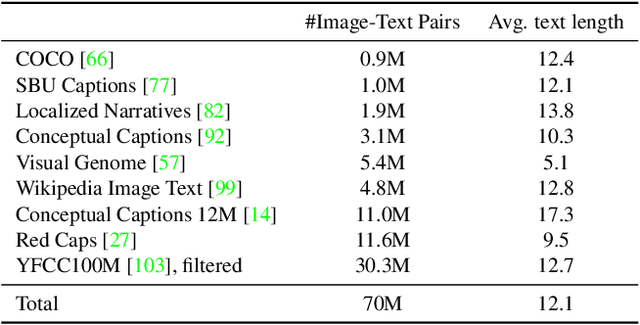
State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal (with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising direction would be to use a single holistic universal model, as a "foundation", that targets all modalities at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate impressive performance on a wide range of 35 tasks spanning these target modalities.
Human-Adversarial Visual Question Answering
Jun 04, 2021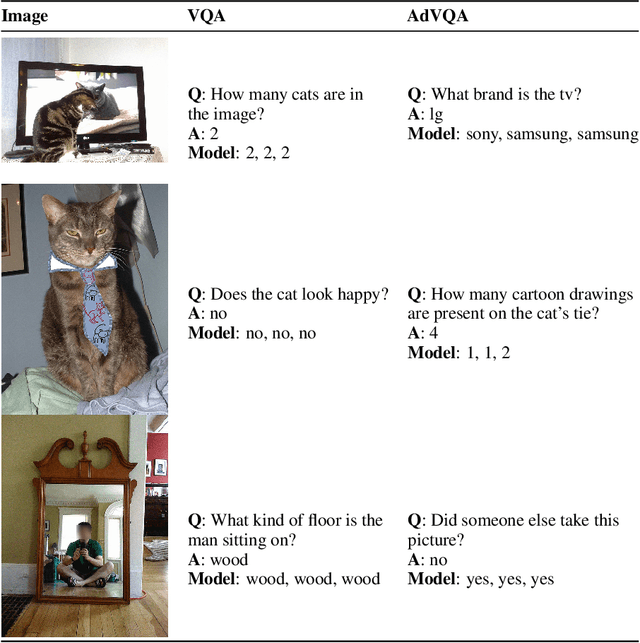
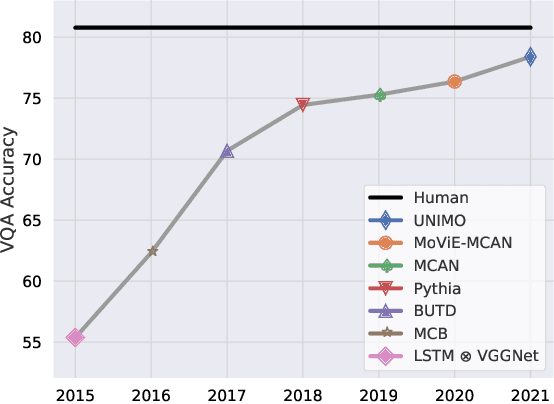
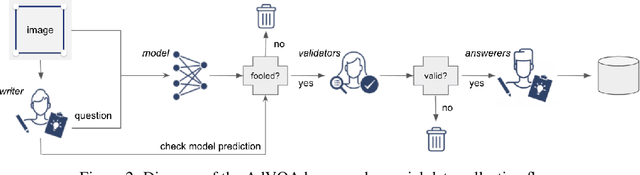

Performance on the most commonly used Visual Question Answering dataset (VQA v2) is starting to approach human accuracy. However, in interacting with state-of-the-art VQA models, it is clear that the problem is far from being solved. In order to stress test VQA models, we benchmark them against human-adversarial examples. Human subjects interact with a state-of-the-art VQA model, and for each image in the dataset, attempt to find a question where the model's predicted answer is incorrect. We find that a wide range of state-of-the-art models perform poorly when evaluated on these examples. We conduct an extensive analysis of the collected adversarial examples and provide guidance on future research directions. We hope that this Adversarial VQA (AdVQA) benchmark can help drive progress in the field and advance the state of the art.
TextOCR: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text
May 12, 2021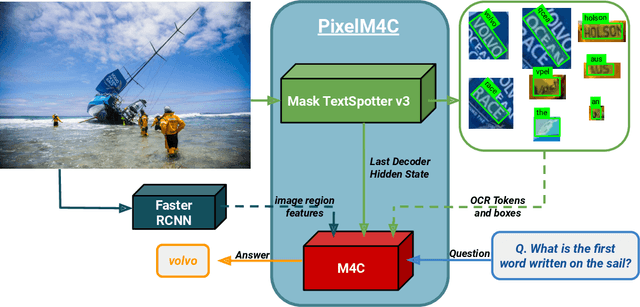
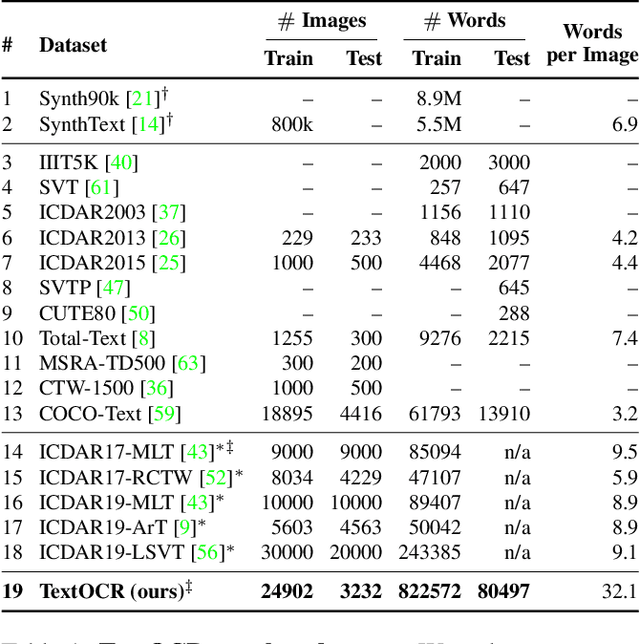

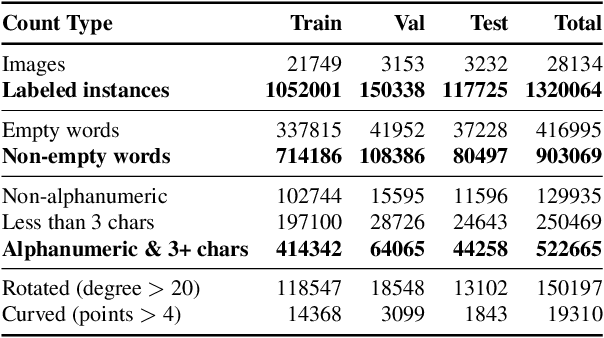
A crucial component for the scene text based reasoning required for TextVQA and TextCaps datasets involve detecting and recognizing text present in the images using an optical character recognition (OCR) system. The current systems are crippled by the unavailability of ground truth text annotations for these datasets as well as lack of scene text detection and recognition datasets on real images disallowing the progress in the field of OCR and evaluation of scene text based reasoning in isolation from OCR systems. In this work, we propose TextOCR, an arbitrary-shaped scene text detection and recognition with 900k annotated words collected on real images from TextVQA dataset. We show that current state-of-the-art text-recognition (OCR) models fail to perform well on TextOCR and that training on TextOCR helps achieve state-of-the-art performance on multiple other OCR datasets as well. We use a TextOCR trained OCR model to create PixelM4C model which can do scene text based reasoning on an image in an end-to-end fashion, allowing us to revisit several design choices to achieve new state-of-the-art performance on TextVQA dataset.
Dynabench: Rethinking Benchmarking in NLP
Apr 07, 2021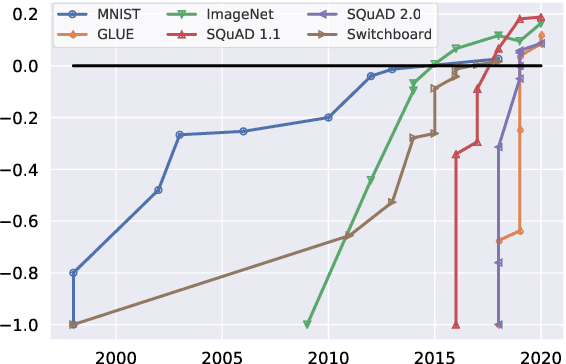
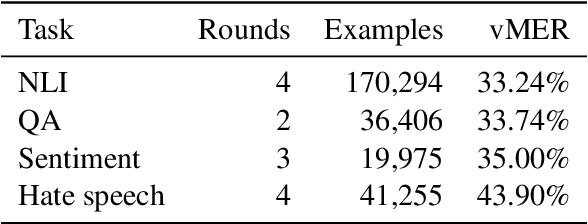
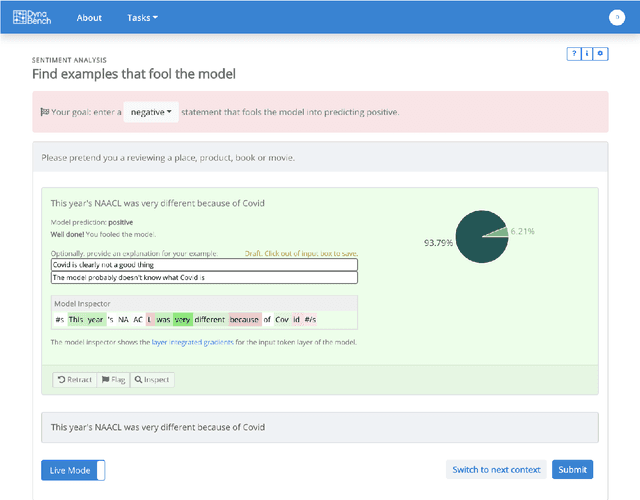
We introduce Dynabench, an open-source platform for dynamic dataset creation and model benchmarking. Dynabench runs in a web browser and supports human-and-model-in-the-loop dataset creation: annotators seek to create examples that a target model will misclassify, but that another person will not. In this paper, we argue that Dynabench addresses a critical need in our community: contemporary models quickly achieve outstanding performance on benchmark tasks but nonetheless fail on simple challenge examples and falter in real-world scenarios. With Dynabench, dataset creation, model development, and model assessment can directly inform each other, leading to more robust and informative benchmarks. We report on four initial NLP tasks, illustrating these concepts and highlighting the promise of the platform, and address potential objections to dynamic benchmarking as a new standard for the field.
Physics Informed Convex Artificial Neural Networks (PICANNs) for Optimal Transport based Density Estimation
Apr 02, 2021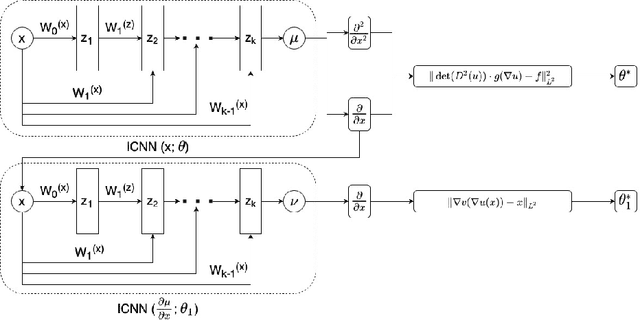
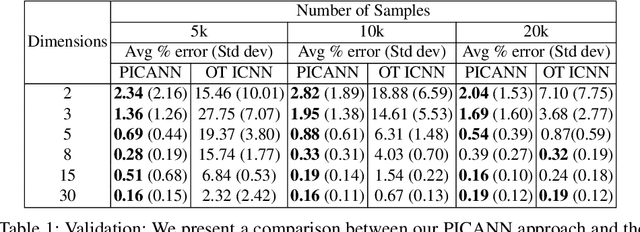
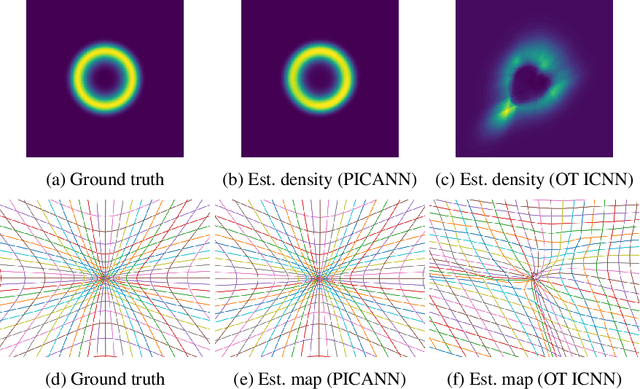
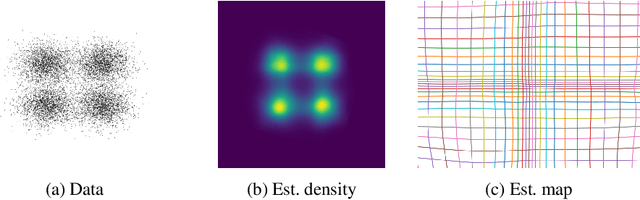
Optimal Mass Transport (OMT) is a well studied problem with a variety of applications in a diverse set of fields ranging from Physics to Computer Vision and in particular Statistics and Data Science. Since the original formulation of Monge in 1781 significant theoretical progress been made on the existence, uniqueness and properties of the optimal transport maps. The actual numerical computation of the transport maps, particularly in high dimensions, remains a challenging problem. By Brenier's theorem, the continuous OMT problem can be reduced to that of solving a non-linear PDE of Monge-Ampere type whose solution is a convex function. In this paper, building on recent developments of input convex neural networks and physics informed neural networks for solving PDE's, we propose a Deep Learning approach to solve the continuous OMT problem. To demonstrate the versatility of our framework we focus on the ubiquitous density estimation and generative modeling tasks in statistics and machine learning. Finally as an example we show how our framework can be incorporated with an autoencoder to estimate an effective probabilistic generative model.
Transformer is All You Need: Multimodal Multitask Learning with a Unified Transformer
Feb 22, 2021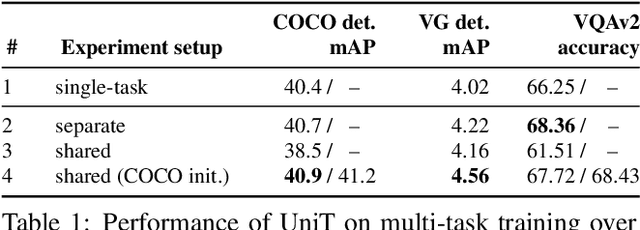
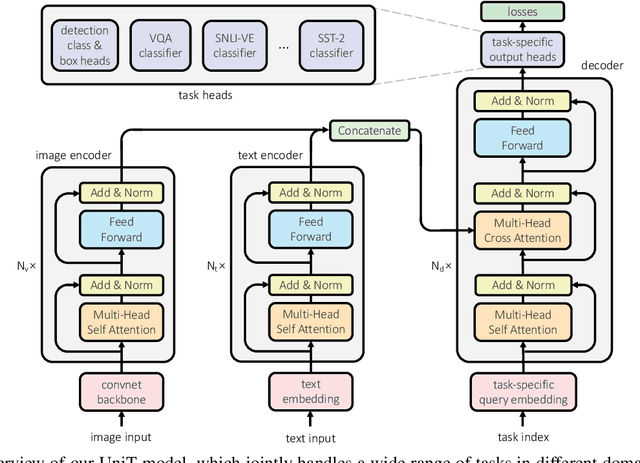

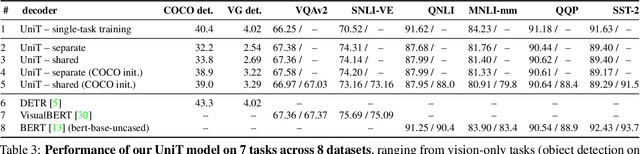
We propose UniT, a Unified Transformer model to simultaneously learn the most prominent tasks across different domains, ranging from object detection to language understanding and multimodal reasoning. Based on the transformer encoder-decoder architecture, our UniT model encodes each input modality with an encoder and makes predictions on each task with a shared decoder over the encoded input representations, followed by task-specific output heads. The entire model is jointly trained end-to-end with losses from each task. Compared to previous efforts on multi-task learning with transformers, we share the same model parameters to all tasks instead of separately fine-tuning task-specific models and handle a much higher variety of tasks across different domains. In our experiments, we learn 7 tasks jointly over 8 datasets, achieving comparable performance to well-established prior work on each domain under the same supervision with a compact set of model parameters. Code will be released in MMF at https://mmf.sh.
Open4Business(O4B): An Open Access Dataset for Summarizing Business Documents
Nov 29, 2020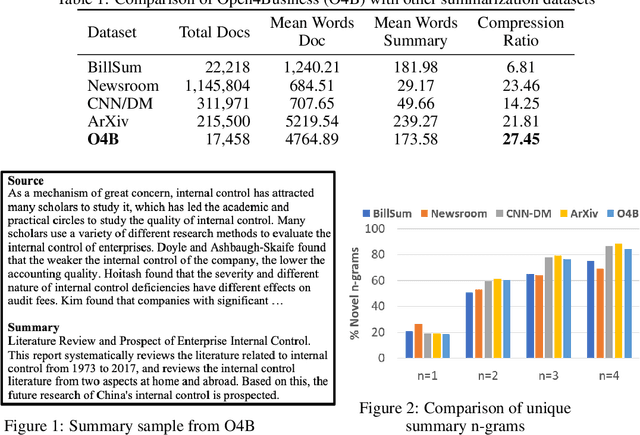
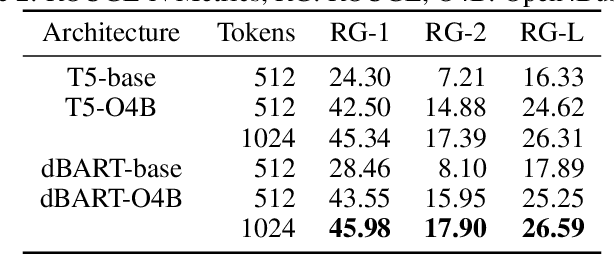
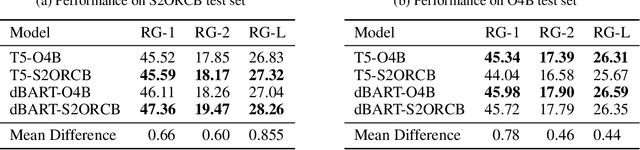

A major challenge in fine-tuning deep learning models for automatic summarization is the need for large domain specific datasets. One of the barriers to curating such data from resources like online publications is navigating the license regulations applicable to their re-use, especially for commercial purposes. As a result, despite the availability of several business journals there are no large scale datasets for summarizing business documents. In this work, we introduce Open4Business(O4B),a dataset of 17,458 open access business articles and their reference summaries. The dataset introduces a new challenge for summarization in the business domain, requiring highly abstractive and more concise summaries as compared to other existing datasets. Additionally, we evaluate existing models on it and consequently show that models trained on O4B and a 7x larger non-open access dataset achieve comparable performance on summarization. We release the dataset, along with the code which can be leveraged to similarly gather data for multiple domains.
Seeing the Un-Scene: Learning Amodal Semantic Maps for Room Navigation
Jul 20, 2020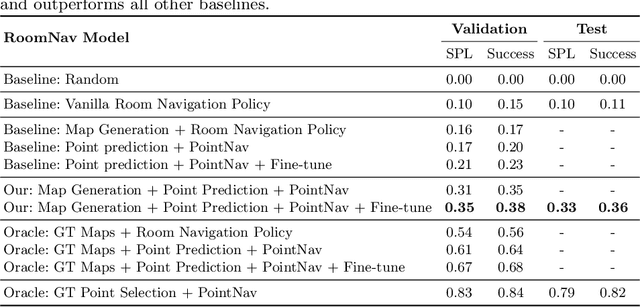
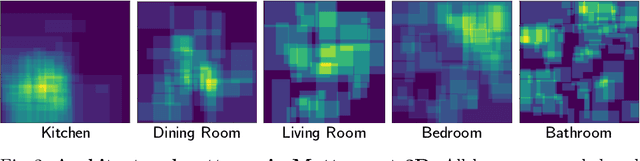
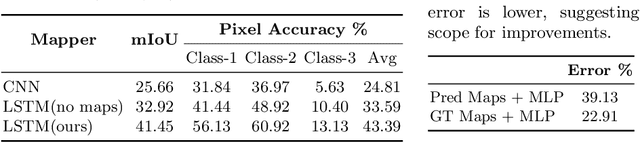
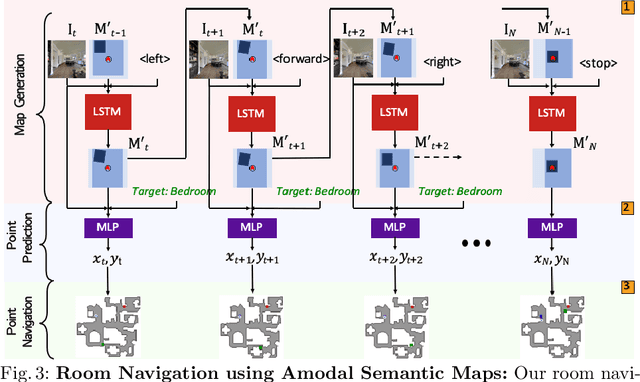
We introduce a learning-based approach for room navigation using semantic maps. Our proposed architecture learns to predict top-down belief maps of regions that lie beyond the agent's field of view while modeling architectural and stylistic regularities in houses. First, we train a model to generate amodal semantic top-down maps indicating beliefs of location, size, and shape of rooms by learning the underlying architectural patterns in houses. Next, we use these maps to predict a point that lies in the target room and train a policy to navigate to the point. We empirically demonstrate that by predicting semantic maps, the model learns common correlations found in houses and generalizes to novel environments. We also demonstrate that reducing the task of room navigation to point navigation improves the performance further.
The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes
Jun 08, 2020
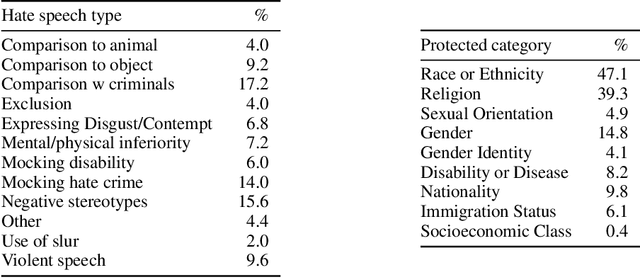
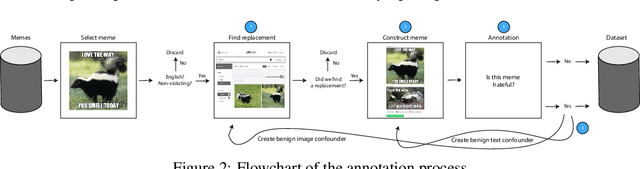

This work proposes a new challenge set for multimodal classification, focusing on detecting hate speech in multimodal memes. It is constructed such that unimodal models struggle and only multimodal models can succeed: difficult examples ("benign confounders") are added to the dataset to make it hard to rely on unimodal signals. The task requires subtle reasoning, yet is straightforward to evaluate as a binary classification problem. We provide baseline performance numbers for unimodal models, as well as for multimodal models with various degrees of sophistication. We find that state-of-the-art methods perform poorly compared to humans (64.73% vs. 84.7% accuracy), illustrating the difficulty of the task and highlighting the challenge that this important problem poses to the community.
Are we pretraining it right? Digging deeper into visio-linguistic pretraining
Apr 19, 2020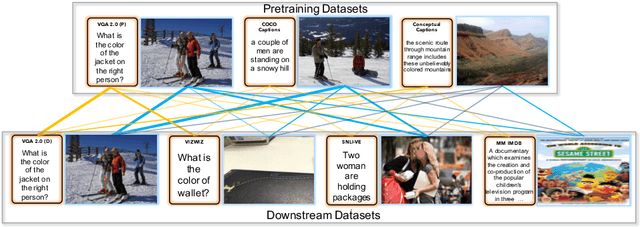
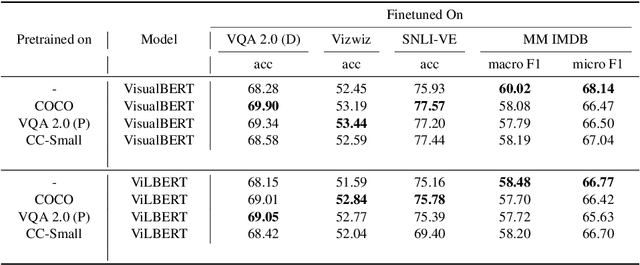
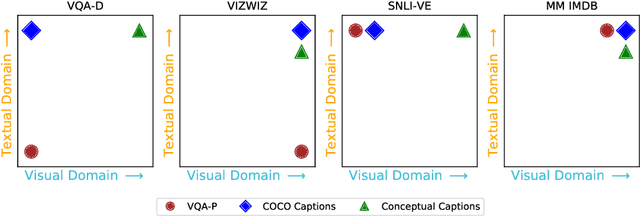
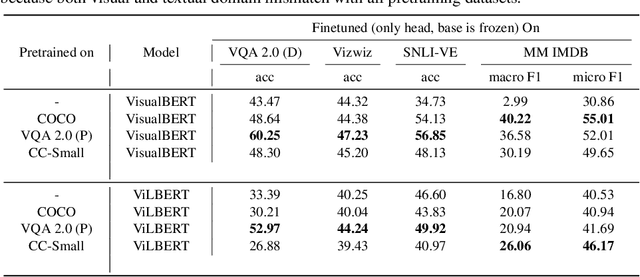
Numerous recent works have proposed pretraining generic visio-linguistic representations and then finetuning them for downstream vision and language tasks. While architecture and objective function design choices have received attention, the choice of pretraining datasets has received little attention. In this work, we question some of the default choices made in literature. For instance, we systematically study how varying similarity between the pretraining dataset domain (textual and visual) and the downstream domain affects performance. Surprisingly, we show that automatically generated data in a domain closer to the downstream task (e.g., VQA v2) is a better choice for pretraining than "natural" data but of a slightly different domain (e.g., Conceptual Captions). On the other hand, some seemingly reasonable choices of pretraining datasets were found to be entirely ineffective for some downstream tasks. This suggests that despite the numerous recent efforts, vision & language pretraining does not quite work "out of the box" yet. Overall, as a by-product of our study, we find that simple design choices in pretraining can help us achieve close to state-of-art results on downstream tasks without any architectural changes.