 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLSE: Corpus of Linguistically Significant Entities
Nov 04, 2022



One of the biggest challenges of natural language generation (NLG) is the proper handling of named entities. Named entities are a common source of grammar mistakes such as wrong prepositions, wrong article handling, or incorrect entity inflection. Without factoring linguistic representation, such errors are often underrepresented when evaluating on a small set of arbitrarily picked argument values, or when translating a dataset from a linguistically simpler language, like English, to a linguistically complex language, like Russian. However, for some applications, broadly precise grammatical correctness is critical -- native speakers may find entity-related grammar errors silly, jarring, or even offensive. To enable the creation of more linguistically diverse NLG datasets, we release a Corpus of Linguistically Significant Entities (CLSE) annotated by linguist experts. The corpus includes 34 languages and covers 74 different semantic types to support various applications from airline ticketing to video games. To demonstrate one possible use of CLSE, we produce an augmented version of the Schema-Guided Dialog Dataset, SGD-CLSE. Using the CLSE's entities and a small number of human translations, we create a linguistically representative NLG evaluation benchmark in three languages: French (high-resource), Marathi (low-resource), and Russian (highly inflected language). We establish quality baselines for neural, template-based, and hybrid NLG systems and discuss the strengths and weaknesses of each approach.
Text Generation with Text-Editing Models
Jun 14, 2022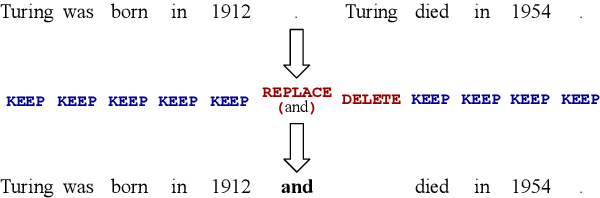

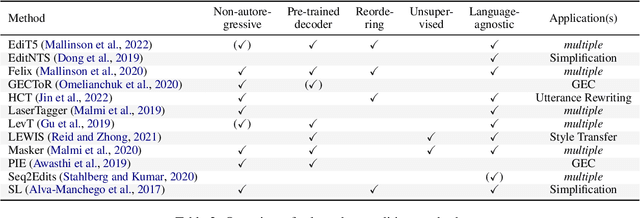
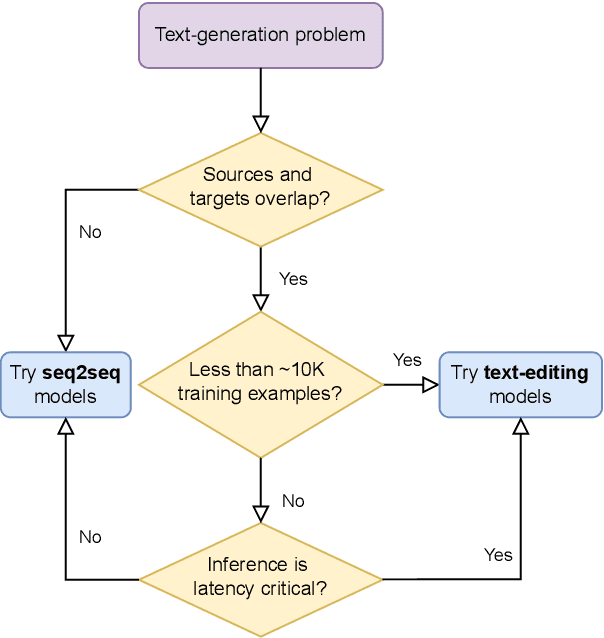
Text-editing models have recently become a prominent alternative to seq2seq models for monolingual text-generation tasks such as grammatical error correction, simplification, and style transfer. These tasks share a common trait - they exhibit a large amount of textual overlap between the source and target texts. Text-editing models take advantage of this observation and learn to generate the output by predicting edit operations applied to the source sequence. In contrast, seq2seq models generate outputs word-by-word from scratch thus making them slow at inference time. Text-editing models provide several benefits over seq2seq models including faster inference speed, higher sample efficiency, and better control and interpretability of the outputs. This tutorial provides a comprehensive overview of text-editing models and current state-of-the-art approaches, and analyzes their pros and cons. We discuss challenges related to productionization and how these models can be used to mitigate hallucination and bias, both pressing challenges in the field of text generation.
Building and Evaluating Open-Domain Dialogue Corpora with Clarifying Questions
Sep 13, 2021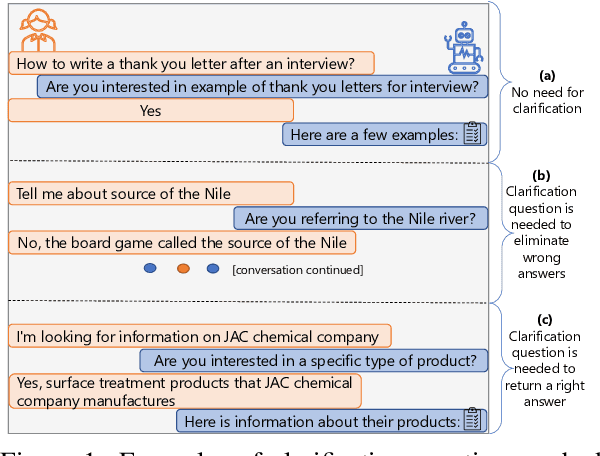

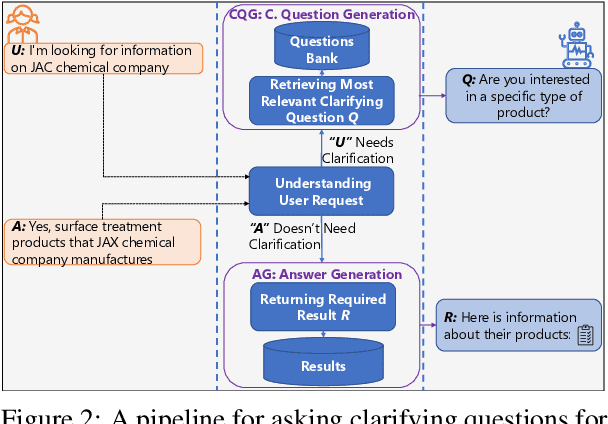

Enabling open-domain dialogue systems to ask clarifying questions when appropriate is an important direction for improving the quality of the system response. Namely, for cases when a user request is not specific enough for a conversation system to provide an answer right away, it is desirable to ask a clarifying question to increase the chances of retrieving a satisfying answer. To address the problem of 'asking clarifying questions in open-domain dialogues': (1) we collect and release a new dataset focused on open-domain single- and multi-turn conversations, (2) we benchmark several state-of-the-art neural baselines, and (3) we propose a pipeline consisting of offline and online steps for evaluating the quality of clarifying questions in various dialogues. These contributions are suitable as a foundation for further research.
ConvAI3: Generating Clarifying Questions for Open-Domain Dialogue Systems (ClariQ)
Sep 23, 2020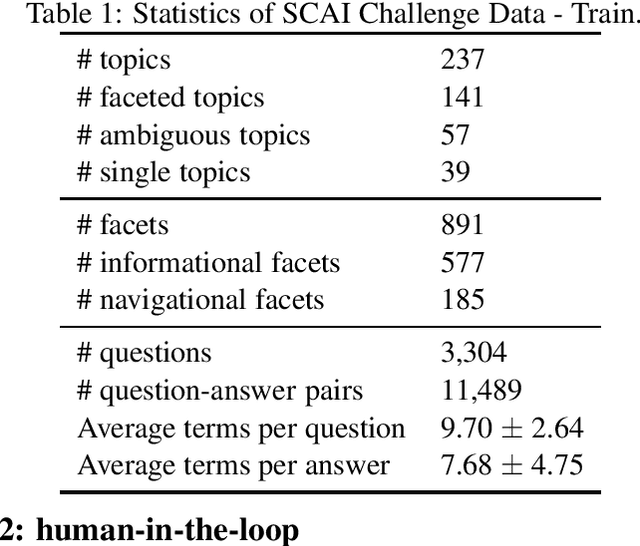
This document presents a detailed description of the challenge on clarifying questions for dialogue systems (ClariQ). The challenge is organized as part of the Conversational AI challenge series (ConvAI3) at Search Oriented Conversational AI (SCAI) EMNLP workshop in 2020. The main aim of the conversational systems is to return an appropriate answer in response to the user requests. However, some user requests might be ambiguous. In IR settings such a situation is handled mainly thought the diversification of the search result page. It is however much more challenging in dialogue settings with limited bandwidth. Therefore, in this challenge, we provide a common evaluation framework to evaluate mixed-initiative conversations. Participants are asked to rank clarifying questions in an information-seeking conversations. The challenge is organized in two stages where in Stage 1 we evaluate the submissions in an offline setting and single-turn conversations. Top participants of Stage 1 get the chance to have their model tested by human annotators.
Prosody Modifications for Question-Answering in Voice-Only Settings
Jun 11, 2018

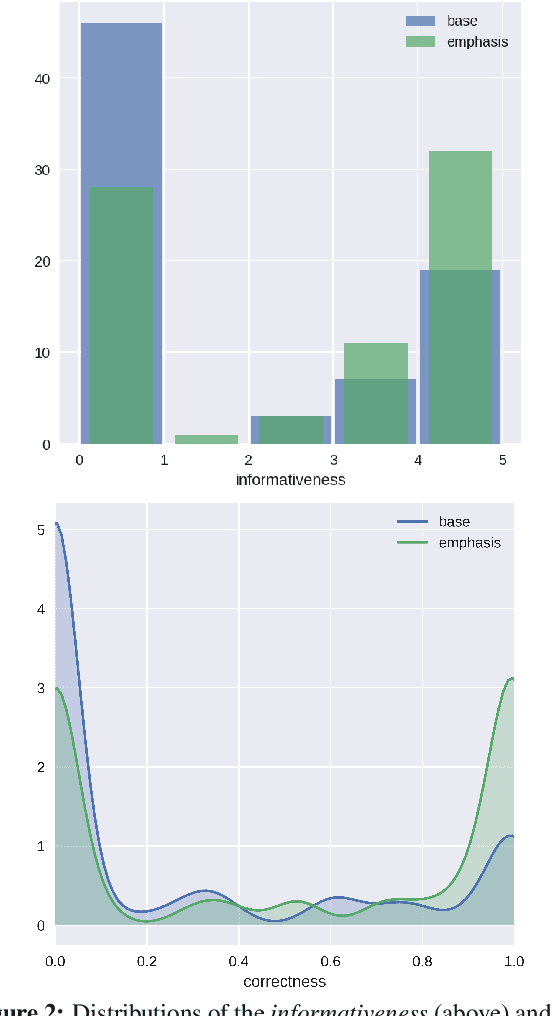

Many popular form factors of digital assistant---such as Amazon Echo, Apple Homepod or Google Home---enable the user to hold a conversation with the assistant based only on the speech modality. The lack of a screen from which the user can read text or watch supporting images or video presents unique challenges. In order to satisfy the information need of a user, we believe that the presentation of the answer needs to be optimized for such voice-only interactions. In this paper we propose a task of evaluating usefulness of prosody modifications for the purpose of voice-only question answering. We describe a crowd-sourcing setup where we evaluate the quality of these modifications along multiple dimensions corresponding to the informativeness, naturalness, and ability of the user to identify the key part of the answer. In addition, we propose a set of simple prosodic modifications that highlight important parts of the answer using various acoustic cues.