 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Graph Convolutions: Message Passing in the Concept Space
Apr 22, 2026The trust in the predictions of Graph Neural Networks is limited by their opaque reasoning process. Prior methods have tried to explain graph networks via concept-based explanations extracted from the latent representations obtained after message passing. However, these explanations fall short of explaining the message passing process itself. To this aim, we propose the Concept Graph Convolution, the first graph convolution designed to operate on node-level concepts for improved interpretability. The proposed convolutional layer performs message passing on a combination of raw and concept representations using structural and attention-based edge weights. We also propose a pure variant of the convolution, only operating in the concept space. Our results show that the Concept Graph Convolution allows to obtain competitive task accuracy, while enabling an increased insight into the evolution of concepts across convolutional steps.
Subgraph Concept Networks: Concept Levels in Graph Classification
Apr 20, 2026The reasoning process of Graph Neural Networks is complex and considered opaque, limiting trust in their predictions. To alleviate this issue, prior work has proposed concept-based explanations, extracted from clusters in the model's node embeddings. However, a limitation of concept-based explanations is that they only explain the node embedding space and are obscured by pooling in graph classification. To mitigate this issue and provide a deeper level of understanding, we propose the Subgraph Concept Network. The Subgraph Concept Network is the first graph neural network architecture that distils subgraph and graph-level concepts. It achieves this by performing soft clustering on node concept embeddings to derive subgraph and graph-level concepts. Our results show that the Subgraph Concept Network allows to obtain competitive model accuracy, while discovering meaningful concepts at different levels of the network.
On the Way to LLM Personalization: Learning to Remember User Conversations
Nov 20, 2024



Large Language Models (LLMs) have quickly become an invaluable assistant for a variety of tasks. However, their effectiveness is constrained by their ability to tailor responses to human preferences and behaviors via personalization. Prior work in LLM personalization has largely focused on style transfer or incorporating small factoids about the user, as knowledge injection remains an open challenge. In this paper, we explore injecting knowledge of prior conversations into LLMs to enable future work on less redundant, personalized conversations. We identify two real-world constraints: (1) conversations are sequential in time and must be treated as such during training, and (2) per-user personalization is only viable in parameter-efficient settings. To this aim, we propose PLUM, a pipeline performing data augmentation for up-sampling conversations as question-answer pairs, that are then used to finetune a low-rank adaptation adapter with a weighted cross entropy loss. Even in this first exploration of the problem, we perform competitively with baselines such as RAG, attaining an accuracy of 81.5% across 100 conversations.
Explaining Hypergraph Neural Networks: From Local Explanations to Global Concepts
Oct 10, 2024



Hypergraph neural networks are a class of powerful models that leverage the message passing paradigm to learn over hypergraphs, a generalization of graphs well-suited to describing relational data with higher-order interactions. However, such models are not naturally interpretable, and their explainability has received very limited attention. We introduce SHypX, the first model-agnostic post-hoc explainer for hypergraph neural networks that provides both local and global explanations. At the instance-level, it performs input attribution by discretely sampling explanation subhypergraphs optimized to be faithful and concise. At the model-level, it produces global explanation subhypergraphs using unsupervised concept extraction. Extensive experiments across four real-world and four novel, synthetic hypergraph datasets demonstrate that our method finds high-quality explanations which can target a user-specified balance between faithfulness and concision, improving over baselines by 25 percent points in fidelity on average.
Digital Histopathology with Graph Neural Networks: Concepts and Explanations for Clinicians
Dec 04, 2023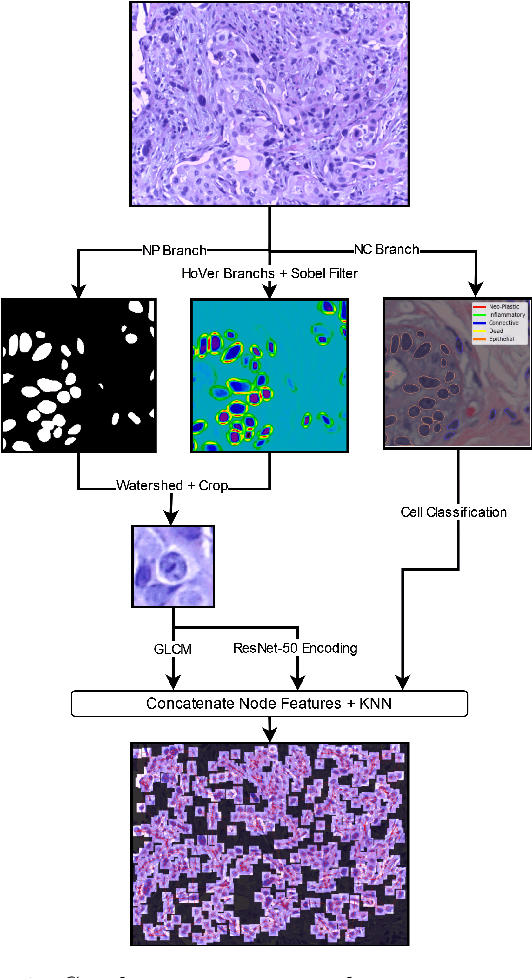
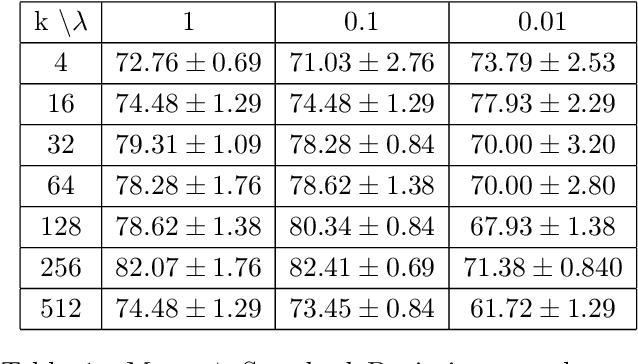
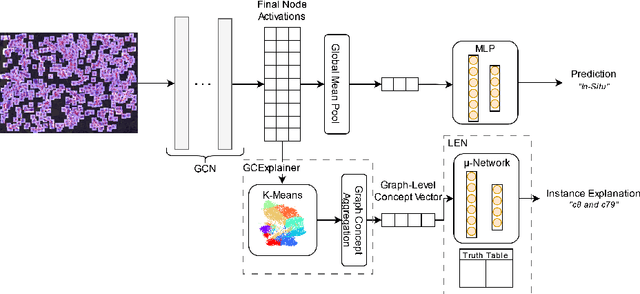
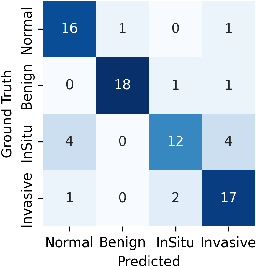
To address the challenge of the ``black-box" nature of deep learning in medical settings, we combine GCExplainer - an automated concept discovery solution - along with Logic Explained Networks to provide global explanations for Graph Neural Networks. We demonstrate this using a generally applicable graph construction and classification pipeline, involving panoptic segmentation with HoVer-Net and cancer prediction with Graph Convolution Networks. By training on H&E slides of breast cancer, we show promising results in offering explainable and trustworthy AI tools for clinicians.
Everybody Needs a Little HELP: Explaining Graphs via Hierarchical Concepts
Dec 02, 2023



Graph neural networks (GNNs) have led to major breakthroughs in a variety of domains such as drug discovery, social network analysis, and travel time estimation. However, they lack interpretability which hinders human trust and thereby deployment to settings with high-stakes decisions. A line of interpretable methods approach this by discovering a small set of relevant concepts as subgraphs in the last GNN layer that together explain the prediction. This can yield oversimplified explanations, failing to explain the interaction between GNN layers. To address this oversight, we provide HELP (Hierarchical Explainable Latent Pooling), a novel, inherently interpretable graph pooling approach that reveals how concepts from different GNN layers compose to new ones in later steps. HELP is more than 1-WL expressive and is the first non-spectral, end-to-end-learnable, hierarchical graph pooling method that can learn to pool a variable number of arbitrary connected components. We empirically demonstrate that it performs on-par with standard GCNs and popular pooling methods in terms of accuracy while yielding explanations that are aligned with expert knowledge in the domains of chemistry and social networks. In addition to a qualitative analysis, we employ concept completeness scores as well as concept conformity, a novel metric to measure the noise in discovered concepts, quantitatively verifying that the discovered concepts are significantly easier to fully understand than those from previous work. Our work represents a first step towards an understanding of graph neural networks that goes beyond a set of concepts from the final layer and instead explains the complex interplay of concepts on different levels.
SHARCS: Shared Concept Space for Explainable Multimodal Learning
Jul 01, 2023



Multimodal learning is an essential paradigm for addressing complex real-world problems, where individual data modalities are typically insufficient to accurately solve a given modelling task. While various deep learning approaches have successfully addressed these challenges, their reasoning process is often opaque; limiting the capabilities for a principled explainable cross-modal analysis and any domain-expert intervention. In this paper, we introduce SHARCS (SHARed Concept Space) -- a novel concept-based approach for explainable multimodal learning. SHARCS learns and maps interpretable concepts from different heterogeneous modalities into a single unified concept-manifold, which leads to an intuitive projection of semantically similar cross-modal concepts. We demonstrate that such an approach can lead to inherently explainable task predictions while also improving downstream predictive performance. Moreover, we show that SHARCS can operate and significantly outperform other approaches in practically significant scenarios, such as retrieval of missing modalities and cross-modal explanations. Our approach is model-agnostic and easily applicable to different types (and number) of modalities, thus advancing the development of effective, interpretable, and trustworthy multimodal approaches.
Deep Multiple Instance Learning with Distance-Aware Self-Attention
May 20, 2023



Traditional supervised learning tasks require a label for every instance in the training set, but in many real-world applications, labels are only available for collections (bags) of instances. This problem setting, known as multiple instance learning (MIL), is particularly relevant in the medical domain, where high-resolution images are split into smaller patches, but labels apply to the image as a whole. Recent MIL models are able to capture correspondences between patches by employing self-attention, allowing them to weigh each patch differently based on all other patches in the bag. However, these approaches still do not consider the relative spatial relationships between patches within the larger image, which is especially important in computational pathology. To this end, we introduce a novel MIL model with distance-aware self-attention (DAS-MIL), which explicitly takes into account relative spatial information when modelling the interactions between patches. Unlike existing relative position representations for self-attention which are discrete, our approach introduces continuous distance-dependent terms into the computation of the attention weights, and is the first to apply relative position representations in the context of MIL. We evaluate our model on a custom MNIST-based MIL dataset that requires the consideration of relative spatial information, as well as on CAMELYON16, a publicly available cancer metastasis detection dataset, where we achieve a test AUROC score of 0.91. On both datasets, our model outperforms existing MIL approaches that employ absolute positional encodings, as well as existing relative position representation schemes applied to MIL. Our code is available at https://anonymous.4open.science/r/das-mil.
Interpretable Neural-Symbolic Concept Reasoning
Apr 27, 2023



Deep learning methods are highly accurate, yet their opaque decision process prevents them from earning full human trust. Concept-based models aim to address this issue by learning tasks based on a set of human-understandable concepts. However, state-of-the-art concept-based models rely on high-dimensional concept embedding representations which lack a clear semantic meaning, thus questioning the interpretability of their decision process. To overcome this limitation, we propose the Deep Concept Reasoner (DCR), the first interpretable concept-based model that builds upon concept embeddings. In DCR, neural networks do not make task predictions directly, but they build syntactic rule structures using concept embeddings. DCR then executes these rules on meaningful concept truth degrees to provide a final interpretable and semantically-consistent prediction in a differentiable manner. Our experiments show that DCR: (i) improves up to +25% w.r.t. state-of-the-art interpretable concept-based models on challenging benchmarks (ii) discovers meaningful logic rules matching known ground truths even in the absence of concept supervision during training, and (iii), facilitates the generation of counterfactual examples providing the learnt rules as guidance.
GCI: A (G)raph (C)oncept (I)nterpretation Framework
Feb 09, 2023



Explainable AI (XAI) underwent a recent surge in research on concept extraction, focusing on extracting human-interpretable concepts from Deep Neural Networks. An important challenge facing concept extraction approaches is the difficulty of interpreting and evaluating discovered concepts, especially for complex tasks such as molecular property prediction. We address this challenge by presenting GCI: a (G)raph (C)oncept (I)nterpretation framework, used for quantitatively measuring alignment between concepts discovered from Graph Neural Networks (GNNs) and their corresponding human interpretations. GCI encodes concept interpretations as functions, which can be used to quantitatively measure the alignment between a given interpretation and concept definition. We demonstrate four applications of GCI: (i) quantitatively evaluating concept extractors, (ii) measuring alignment between concept extractors and human interpretations, (iii) measuring the completeness of interpretations with respect to an end task and (iv) a practical application of GCI to molecular property prediction, in which we demonstrate how to use chemical functional groups to explain GNNs trained on molecular property prediction tasks, and implement interpretations with a 0.76 AUCROC completeness score.