 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Guidance: Training-free Acceleration of Conditional Diffusion Models
Dec 19, 2023This paper presents a comprehensive study on the role of Classifier-Free Guidance (CFG) in text-conditioned diffusion models from the perspective of inference efficiency. In particular, we relax the default choice of applying CFG in all diffusion steps and instead search for efficient guidance policies. We formulate the discovery of such policies in the differentiable Neural Architecture Search framework. Our findings suggest that the denoising steps proposed by CFG become increasingly aligned with simple conditional steps, which renders the extra neural network evaluation of CFG redundant, especially in the second half of the denoising process. Building upon this insight, we propose "Adaptive Guidance" (AG), an efficient variant of CFG, that adaptively omits network evaluations when the denoising process displays convergence. Our experiments demonstrate that AG preserves CFG's image quality while reducing computation by 25%. Thus, AG constitutes a plug-and-play alternative to Guidance Distillation, achieving 50% of the speed-ups of the latter while being training-free and retaining the capacity to handle negative prompts. Finally, we uncover further redundancies of CFG in the first half of the diffusion process, showing that entire neural function evaluations can be replaced by simple affine transformations of past score estimates. This method, termed LinearAG, offers even cheaper inference at the cost of deviating from the baseline model. Our findings provide insights into the efficiency of the conditional denoising process that contribute to more practical and swift deployment of text-conditioned diffusion models.
Bespoke Solvers for Generative Flow Models
Oct 29, 2023



Diffusion or flow-based models are powerful generative paradigms that are notoriously hard to sample as samples are defined as solutions to high-dimensional Ordinary or Stochastic Differential Equations (ODEs/SDEs) which require a large Number of Function Evaluations (NFE) to approximate well. Existing methods to alleviate the costly sampling process include model distillation and designing dedicated ODE solvers. However, distillation is costly to train and sometimes can deteriorate quality, while dedicated solvers still require relatively large NFE to produce high quality samples. In this paper we introduce "Bespoke solvers", a novel framework for constructing custom ODE solvers tailored to the ODE of a given pre-trained flow model. Our approach optimizes an order consistent and parameter-efficient solver (e.g., with 80 learnable parameters), is trained for roughly 1% of the GPU time required for training the pre-trained model, and significantly improves approximation and generation quality compared to dedicated solvers. For example, a Bespoke solver for a CIFAR10 model produces samples with Fr\'echet Inception Distance (FID) of 2.73 with 10 NFE, and gets to 1% of the Ground Truth (GT) FID (2.59) for this model with only 20 NFE. On the more challenging ImageNet-64$\times$64, Bespoke samples at 2.2 FID with 10 NFE, and gets within 2% of GT FID (1.71) with 20 NFE.
BoDiffusion: Diffusing Sparse Observations for Full-Body Human Motion Synthesis
Apr 21, 2023



Mixed reality applications require tracking the user's full-body motion to enable an immersive experience. However, typical head-mounted devices can only track head and hand movements, leading to a limited reconstruction of full-body motion due to variability in lower body configurations. We propose BoDiffusion -- a generative diffusion model for motion synthesis to tackle this under-constrained reconstruction problem. We present a time and space conditioning scheme that allows BoDiffusion to leverage sparse tracking inputs while generating smooth and realistic full-body motion sequences. To the best of our knowledge, this is the first approach that uses the reverse diffusion process to model full-body tracking as a conditional sequence generation task. We conduct experiments on the large-scale motion-capture dataset AMASS and show that our approach outperforms the state-of-the-art approaches by a significant margin in terms of full-body motion realism and joint reconstruction error.
Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model
Apr 17, 2023



With the recent surge in popularity of AR/VR applications, realistic and accurate control of 3D full-body avatars has become a highly demanded feature. A particular challenge is that only a sparse tracking signal is available from standalone HMDs (Head Mounted Devices), often limited to tracking the user's head and wrists. While this signal is resourceful for reconstructing the upper body motion, the lower body is not tracked and must be synthesized from the limited information provided by the upper body joints. In this paper, we present AGRoL, a novel conditional diffusion model specifically designed to track full bodies given sparse upper-body tracking signals. Our model is based on a simple multi-layer perceptron (MLP) architecture and a novel conditioning scheme for motion data. It can predict accurate and smooth full-body motion, particularly the challenging lower body movement. Unlike common diffusion architectures, our compact architecture can run in real-time, making it suitable for online body-tracking applications. We train and evaluate our model on AMASS motion capture dataset, and demonstrate that our approach outperforms state-of-the-art methods in generated motion accuracy and smoothness. We further justify our design choices through extensive experiments and ablation studies.
VisCo Grids: Surface Reconstruction with Viscosity and Coarea Grids
Mar 25, 2023



Surface reconstruction has been seeing a lot of progress lately by utilizing Implicit Neural Representations (INRs). Despite their success, INRs often introduce hard to control inductive bias (i.e., the solution surface can exhibit unexplainable behaviours), have costly inference, and are slow to train. The goal of this work is to show that replacing neural networks with simple grid functions, along with two novel geometric priors achieve comparable results to INRs, with instant inference, and improved training times. To that end we introduce VisCo Grids: a grid-based surface reconstruction method incorporating Viscosity and Coarea priors. Intuitively, the Viscosity prior replaces the smoothness inductive bias of INRs, while the Coarea favors a minimal area solution. Experimenting with VisCo Grids on a standard reconstruction baseline provided comparable results to the best performing INRs on this dataset.
Re-ReND: Real-time Rendering of NeRFs across Devices
Mar 15, 2023



This paper proposes a novel approach for rendering a pre-trained Neural Radiance Field (NeRF) in real-time on resource-constrained devices. We introduce Re-ReND, a method enabling Real-time Rendering of NeRFs across Devices. Re-ReND is designed to achieve real-time performance by converting the NeRF into a representation that can be efficiently processed by standard graphics pipelines. The proposed method distills the NeRF by extracting the learned density into a mesh, while the learned color information is factorized into a set of matrices that represent the scene's light field. Factorization implies the field is queried via inexpensive MLP-free matrix multiplications, while using a light field allows rendering a pixel by querying the field a single time-as opposed to hundreds of queries when employing a radiance field. Since the proposed representation can be implemented using a fragment shader, it can be directly integrated with standard rasterization frameworks. Our flexible implementation can render a NeRF in real-time with low memory requirements and on a wide range of resource-constrained devices, including mobiles and AR/VR headsets. Notably, we find that Re-ReND can achieve over a 2.6-fold increase in rendering speed versus the state-of-the-art without perceptible losses in quality.
Towards Assessing and Characterizing the Semantic Robustness of Face Recognition
Feb 10, 2022Deep Neural Networks (DNNs) lack robustness against imperceptible perturbations to their input. Face Recognition Models (FRMs) based on DNNs inherit this vulnerability. We propose a methodology for assessing and characterizing the robustness of FRMs against semantic perturbations to their input. Our methodology causes FRMs to malfunction by designing adversarial attacks that search for identity-preserving modifications to faces. In particular, given a face, our attacks find identity-preserving variants of the face such that an FRM fails to recognize the images belonging to the same identity. We model these identity-preserving semantic modifications via direction- and magnitude-constrained perturbations in the latent space of StyleGAN. We further propose to characterize the semantic robustness of an FRM by statistically describing the perturbations that induce the FRM to malfunction. Finally, we combine our methodology with a certification technique, thus providing (i) theoretical guarantees on the performance of an FRM, and (ii) a formal description of how an FRM may model the notion of face identity.
Snapshot HDR Video Construction Using Coded Mask
Dec 05, 2021
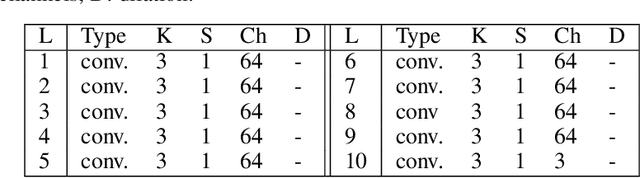
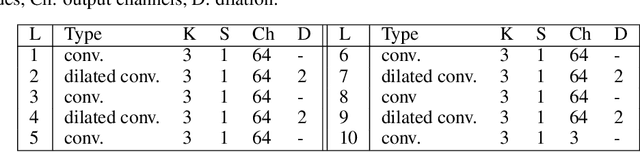
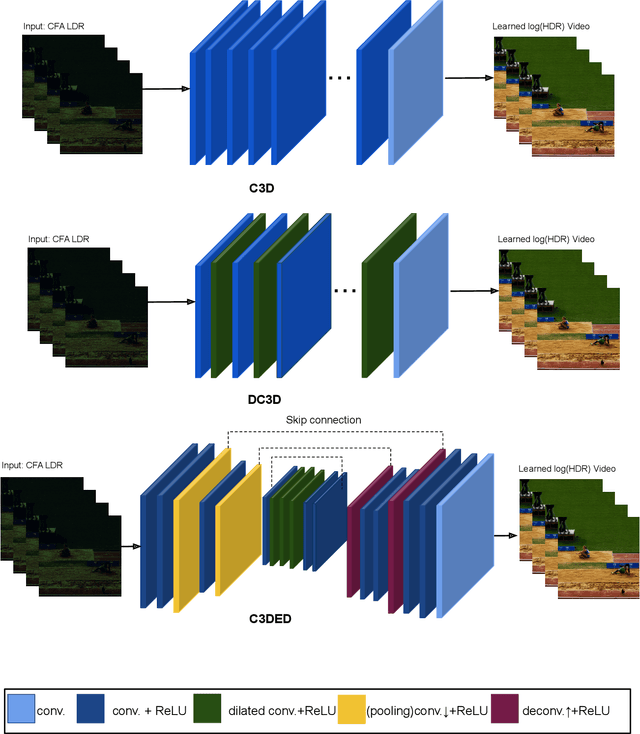
This paper study the reconstruction of High Dynamic Range (HDR) video from snapshot-coded LDR video. Constructing an HDR video requires restoring the HDR values for each frame and maintaining the consistency between successive frames. HDR image acquisition from single image capture, also known as snapshot HDR imaging, can be achieved in several ways. For example, the reconfigurable snapshot HDR camera is realized by introducing an optical element into the optical stack of the camera; by placing a coded mask at a small standoff distance in front of the sensor. High-quality HDR image can be recovered from the captured coded image using deep learning methods. This study utilizes 3D-CNNs to perform a joint demosaicking, denoising, and HDR video reconstruction from coded LDR video. We enforce more temporally consistent HDR video reconstruction by introducing a temporal loss function that considers the short-term and long-term consistency. The obtained results are promising and could lead to affordable HDR video capture using conventional cameras.
ASSANet: An Anisotropic Separable Set Abstraction for Efficient Point Cloud Representation Learning
Oct 24, 2021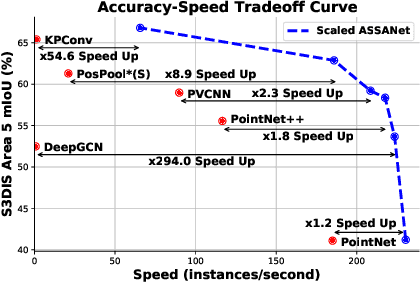
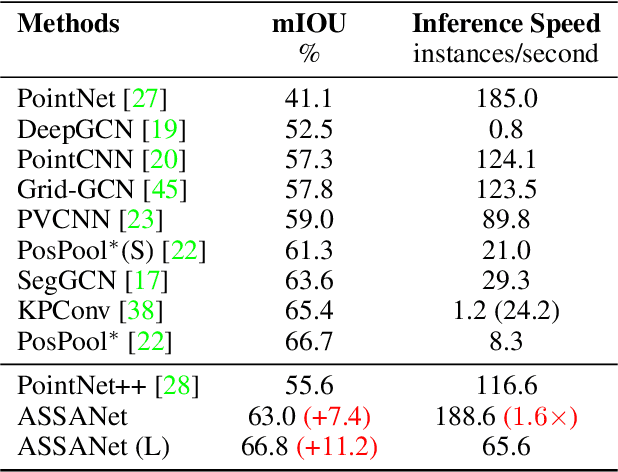

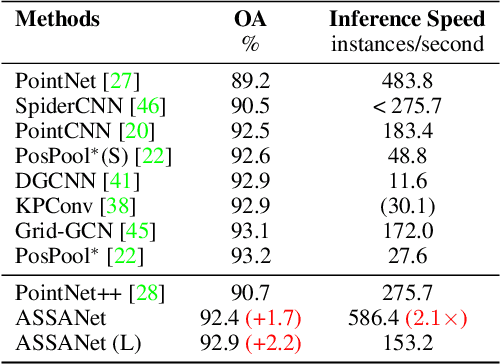
Access to 3D point cloud representations has been widely facilitated by LiDAR sensors embedded in various mobile devices. This has led to an emerging need for fast and accurate point cloud processing techniques. In this paper, we revisit and dive deeper into PointNet++, one of the most influential yet under-explored networks, and develop faster and more accurate variants of the model. We first present a novel Separable Set Abstraction (SA) module that disentangles the vanilla SA module used in PointNet++ into two separate learning stages: (1) learning channel correlation and (2) learning spatial correlation. The Separable SA module is significantly faster than the vanilla version, yet it achieves comparable performance. We then introduce a new Anisotropic Reduction function into our Separable SA module and propose an Anisotropic Separable SA (ASSA) module that substantially increases the network's accuracy. We later replace the vanilla SA modules in PointNet++ with the proposed ASSA module, and denote the modified network as ASSANet. Extensive experiments on point cloud classification, semantic segmentation, and part segmentation show that ASSANet outperforms PointNet++ and other methods, achieving much higher accuracy and faster speeds. In particular, ASSANet outperforms PointNet++ by $7.4$ mIoU on S3DIS Area 5, while maintaining $1.6 \times $ faster inference speed on a single NVIDIA 2080Ti GPU. Our scaled ASSANet variant achieves $66.8$ mIoU and outperforms KPConv, while being more than $54 \times$ faster.
MovieCuts: A New Dataset and Benchmark for Cut Type Recognition
Sep 19, 2021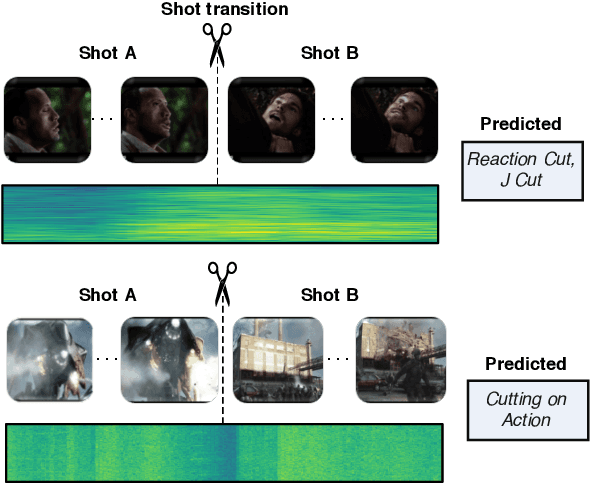
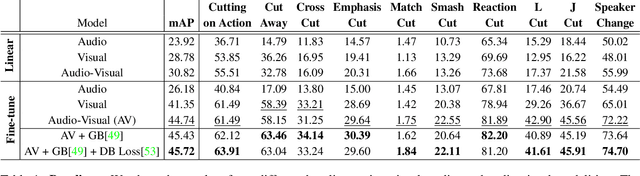
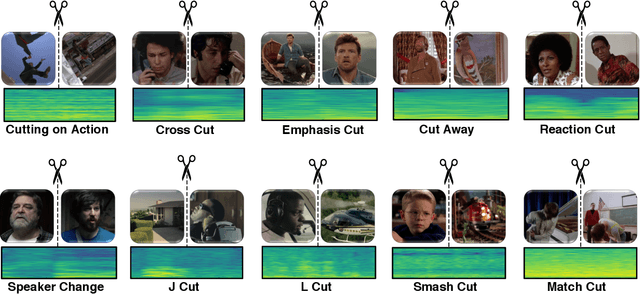
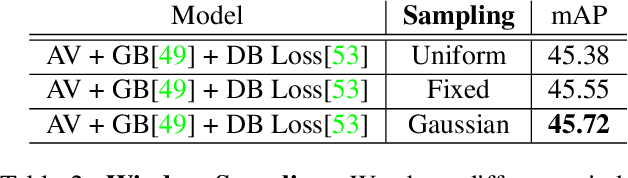
Understanding movies and their structural patterns is a crucial task to decode the craft of video editing. While previous works have developed tools for general analysis such as detecting characters or recognizing cinematography properties at the shot level, less effort has been devoted to understanding the most basic video edit, the Cut. This paper introduces the cut type recognition task, which requires modeling of multi-modal information. To ignite research in the new task, we construct a large-scale dataset called MovieCuts, which contains more than 170K videoclips labeled among ten cut types. We benchmark a series of audio-visual approaches, including some that deal with the problem's multi-modal and multi-label nature. Our best model achieves 45.7% mAP, which suggests that the task is challenging and that attaining highly accurate cut type recognition is an open research problem.