 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordance Learning for End-to-End Visuomotor Robot Control
Mar 10, 2019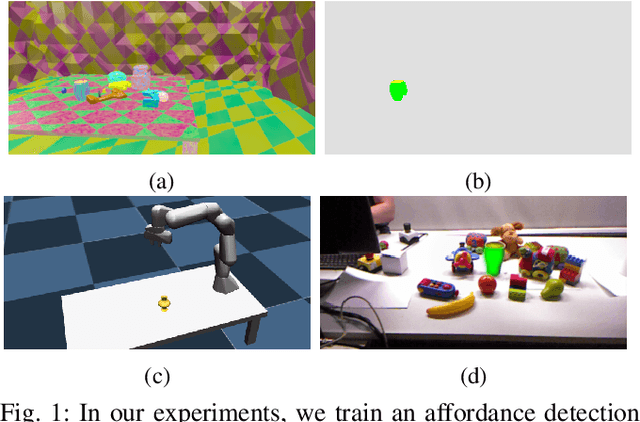
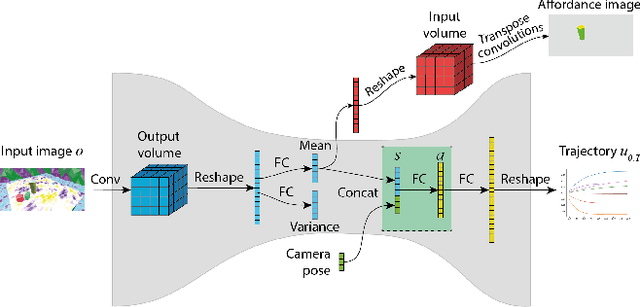
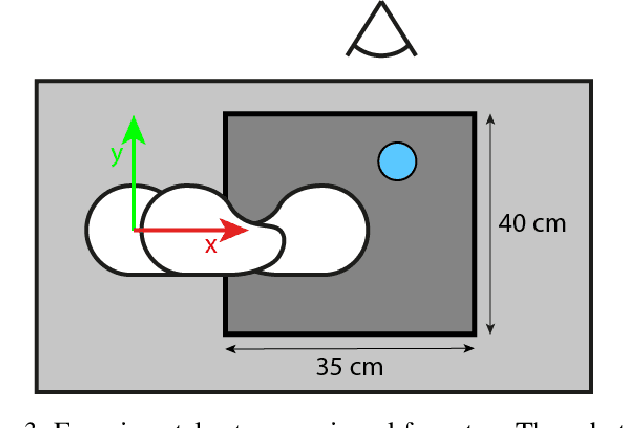

Training end-to-end deep robot policies requires a lot of domain-, task-, and hardware-specific data, which is often costly to provide. In this work, we propose to tackle this issue by employing a deep neural network with a modular architecture, consisting of separate perception, policy, and trajectory parts. Each part of the system is trained fully on synthetic data or in simulation. The data is exchanged between parts of the system as low-dimensional latent representations of affordances and trajectories. The performance is then evaluated in a zero-shot transfer scenario using Franka Panda robot arm. Results demonstrate that a low-dimensional representation of scene affordances extracted from an RGB image is sufficient to successfully train manipulator policies. We also introduce a method for affordance dataset generation, which is easily generalizable to new tasks, objects and environments, and requires no manual pixel labeling.
Exploring Temporal Dependencies in Multimodal Referring Expressions with Mixed Reality
Feb 04, 2019
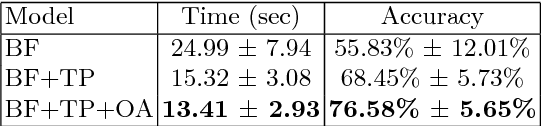
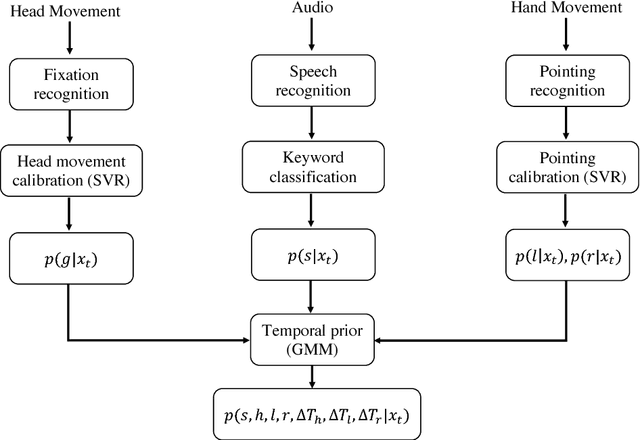

In collaborative tasks, people rely both on verbal and non-verbal cues simultaneously to communicate with each other. For human-robot interaction to run smoothly and naturally, a robot should be equipped with the ability to robustly disambiguate referring expressions. In this work, we propose a model that can disambiguate multimodal fetching requests using modalities such as head movements, hand gestures, and speech. We analysed the acquired data from mixed reality experiments and formulated a hypothesis that modelling temporal dependencies of events in these three modalities increases the model's predictive power. We evaluated our model on a Bayesian framework to interpret referring expressions with and without exploiting a temporal prior.
Meta-Learning for Multi-objective Reinforcement Learning
Nov 08, 2018
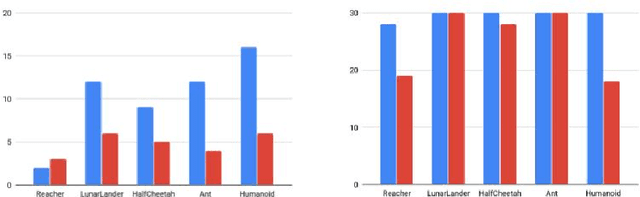
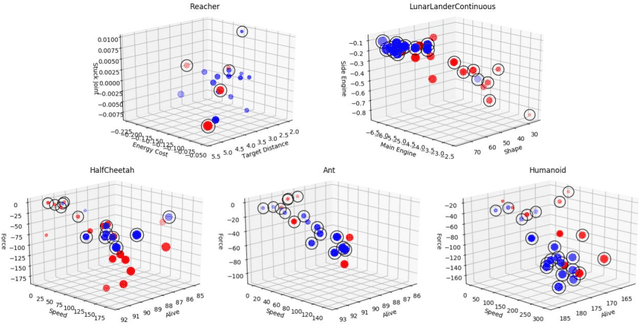
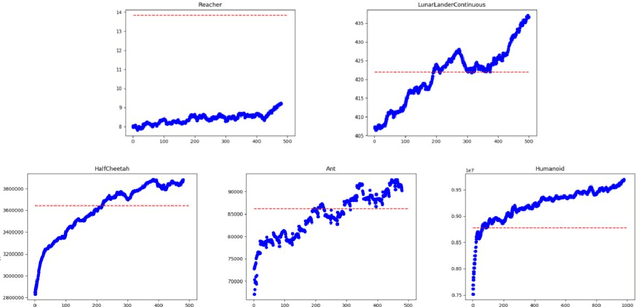
Multi-objective reinforcement learning (MORL) is the generalization of standard reinforcement learning (RL) approaches to solve sequential decision making problems that consist of several, possibly conflicting, objectives. Generally, in such formulations, there is no single optimal policy which optimizes all the objectives simultaneously, and instead, a number of policies has to be found, each optimizing a preference of the objectives. In this paper, we introduce a novel MORL approach by training a meta-policy, a policy simultaneously trained with multiple tasks sampled from a task distribution, for a number of randomly sampled Markov decision processes (MDPs). In other words, the MORL is framed as a meta-learning problem, with the task distribution given by a distribution over the preferences. We demonstrate that such a formulation results in a better approximation of the Pareto optimal solutions, in terms of both the optimality and the computational efficiency. We evaluated our method on obtaining Pareto optimal policies using a number of continuous control problems with high degrees of freedom.
Deep Reinforcement Learning to Acquire Navigation Skills for Wheel-Legged Robots in Complex Environments
Apr 27, 2018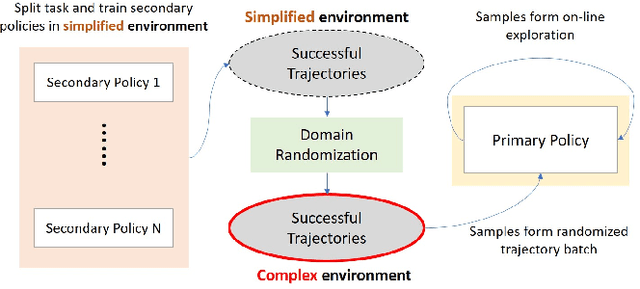
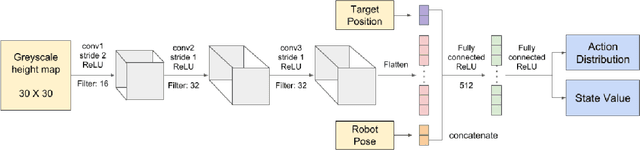
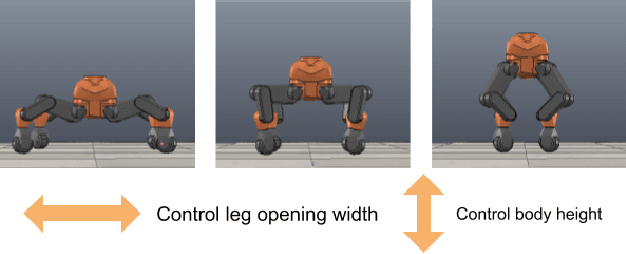

Mobile robot navigation in complex and dynamic environments is a challenging but important problem. Reinforcement learning approaches fail to solve these tasks efficiently due to reward sparsities, temporal complexities and high-dimensionality of sensorimotor spaces which are inherent in such problems. We present a novel approach to train action policies to acquire navigation skills for wheel-legged robots using deep reinforcement learning. The policy maps height-map image observations to motor commands to navigate to a target position while avoiding obstacles. We propose to acquire the multifaceted navigation skill by learning and exploiting a number of manageable navigation behaviors. We also introduce a domain randomization technique to improve the versatility of the training samples. We demonstrate experimentally a significant improvement in terms of data-efficiency, success rate, robustness against irrelevant sensory data, and also the quality of the maneuver skills.
Deep Predictive Policy Training using Reinforcement Learning
Mar 02, 2017

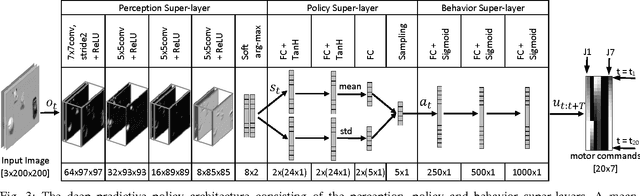

Skilled robot task learning is best implemented by predictive action policies due to the inherent latency of sensorimotor processes. However, training such predictive policies is challenging as it involves finding a trajectory of motor activations for the full duration of the action. We propose a data-efficient deep predictive policy training (DPPT) framework with a deep neural network policy architecture which maps an image observation to a sequence of motor activations. The architecture consists of three sub-networks referred to as the perception, policy and behavior super-layers. The perception and behavior super-layers force an abstraction of visual and motor data trained with synthetic and simulated training samples, respectively. The policy super-layer is a small sub-network with fewer parameters that maps data in-between the abstracted manifolds. It is trained for each task using methods for policy search reinforcement learning. We demonstrate the suitability of the proposed architecture and learning framework by training predictive policies for skilled object grasping and ball throwing on a PR2 robot. The effectiveness of the method is illustrated by the fact that these tasks are trained using only about 180 real robot attempts with qualitative terminal rewards.
A Sensorimotor Reinforcement Learning Framework for Physical Human-Robot Interaction
Jul 27, 2016
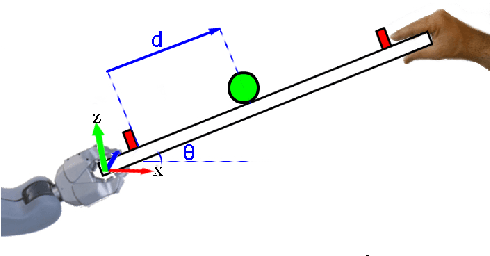
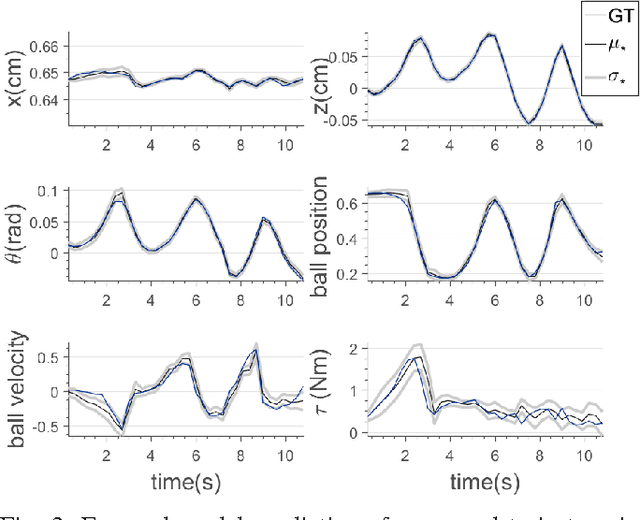
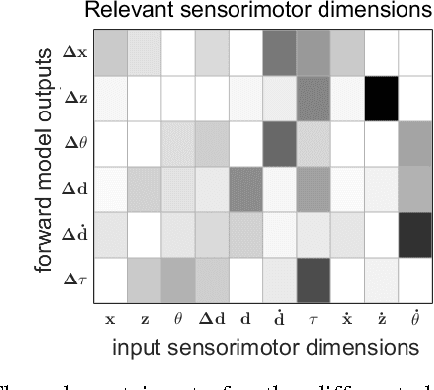
Modeling of physical human-robot collaborations is generally a challenging problem due to the unpredictive nature of human behavior. To address this issue, we present a data-efficient reinforcement learning framework which enables a robot to learn how to collaborate with a human partner. The robot learns the task from its own sensorimotor experiences in an unsupervised manner. The uncertainty of the human actions is modeled using Gaussian processes (GP) to implement action-value functions. Optimal action selection given the uncertain GP model is ensured by Bayesian optimization. We apply the framework to a scenario in which a human and a PR2 robot jointly control the ball position on a plank based on vision and force/torque data. Our experimental results show the suitability of the proposed method in terms of fast and data-efficient model learning, optimal action selection under uncertainties and equal role sharing between the partners.
Self-learning and adaptation in a sensorimotor framework
Jan 05, 2016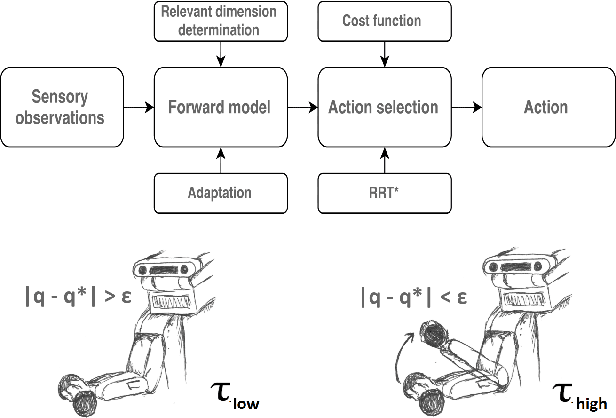
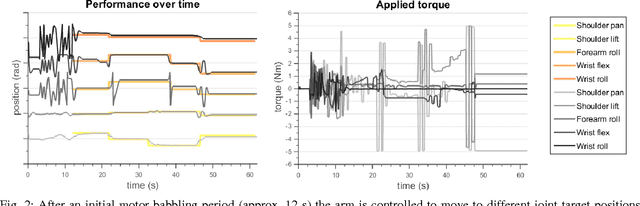
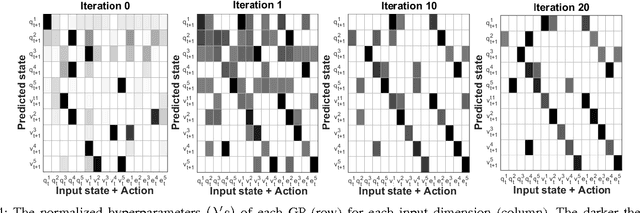
We present a general framework to autonomously achieve a task, where autonomy is acquired by learning sensorimotor patterns of a robot, while it is interacting with its environment. To accomplish the task, using the learned sensorimotor contingencies, our approach predicts a sequence of actions that will lead to the desirable observations. Gaussian processes (GP) with automatic relevance determination is used to learn the sensorimotor mapping. In this way, relevant sensory and motor components can be systematically found in high-dimensional sensory and motor spaces. We propose an incremental GP learning strategy, which discerns between situations, when an update or an adaptation must be implemented. RRT* is exploited to enable long-term planning and generating a sequence of states that lead to a given goal; while a gradient-based search finds the optimum action to steer to a neighbouring state in a single time step. Our experimental results prove the successfulness of the proposed framework to learn a joint space controller with high data dimensions (10$\times$15). It demonstrates short training phase (less than 12 seconds), real-time performance and rapid adaptations capabilities.