 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Third Person to First Person: Dataset and Baselines for Synthesis and Retrieval
Dec 01, 2018



First-person (egocentric) and third person (exocentric) videos are drastically different in nature. The relationship between these two views have been studied in recent years, however, it has yet to be fully explored. In this work, we introduce two datasets (synthetic and natural/real) containing simultaneously recorded egocentric and exocentric videos. We also explore relating the two domains (egocentric and exocentric) in two aspects. First, we synthesize images in the egocentric domain from the exocentric domain using a conditional generative adversarial network (cGAN). We show that with enough training data, our network is capable of hallucinating how the world would look like from an egocentric perspective, given an exocentric video. Second, we address the cross-view retrieval problem across the two views. Given an egocentric query frame (or its momentary optical flow), we retrieve its corresponding exocentric frame (or optical flow) from a gallery set. We show that using synthetic data could be beneficial in retrieving real data. We show that performing domain adaptation from the synthetic domain to the natural/real domain, is helpful in tasks such as retrieval. We believe that the presented datasets and the proposed baselines offer new opportunities for further research in this direction. The code and dataset are publicly available.
Improving Sequential Determinantal Point Processes for Supervised Video Summarization
Oct 24, 2018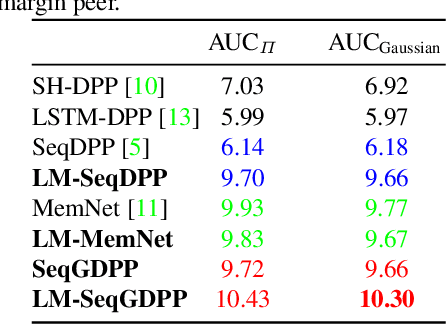
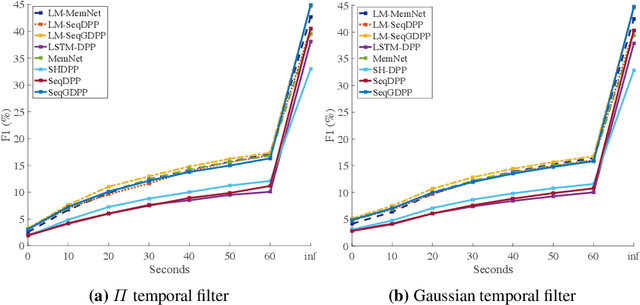
It is now much easier than ever before to produce videos. While the ubiquitous video data is a great source for information discovery and extraction, the computational challenges are unparalleled. Automatically summarizing the videos has become a substantial need for browsing, searching, and indexing visual content. This paper is in the vein of supervised video summarization using sequential determinantal point process (SeqDPP), which models diversity by a probabilistic distribution. We improve this model in two folds. In terms of learning, we propose a large-margin algorithm to address the exposure bias problem in SeqDPP. In terms of modeling, we design a new probabilistic distribution such that, when it is integrated into SeqDPP, the resulting model accepts user input about the expected length of the summary. Moreover, we also significantly extend a popular video summarization dataset by 1) more egocentric videos, 2) dense user annotations, and 3) a refined evaluation scheme. We conduct extensive experiments on this dataset (about 60 hours of videos in total) and compare our approach to several competitive baselines.
Pros and Cons of GAN Evaluation Measures
Oct 24, 2018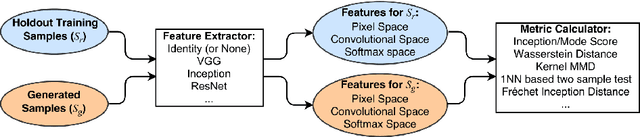
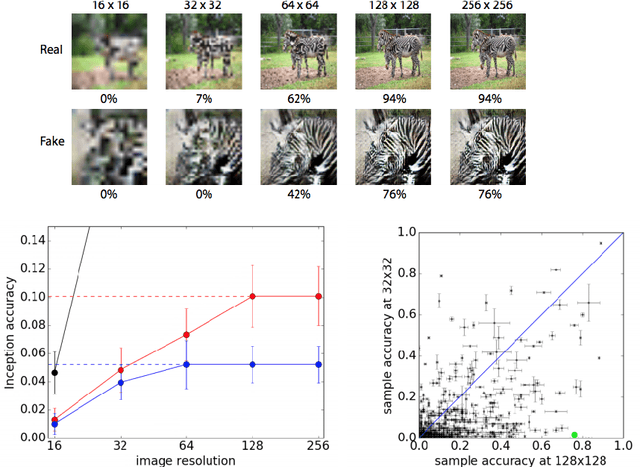
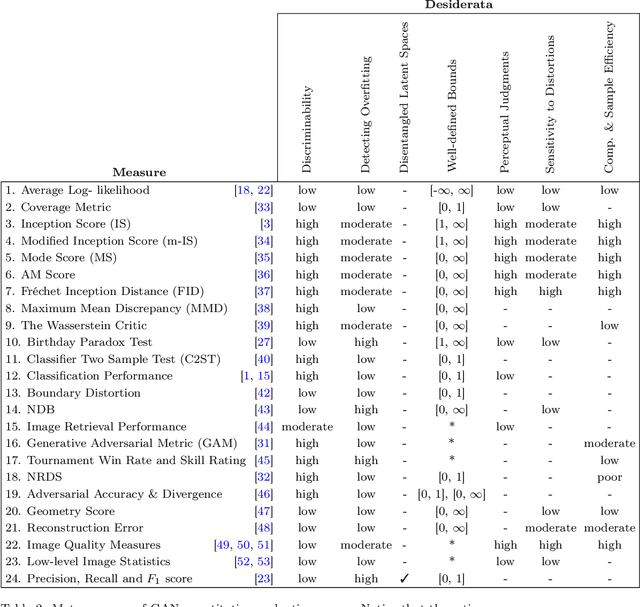
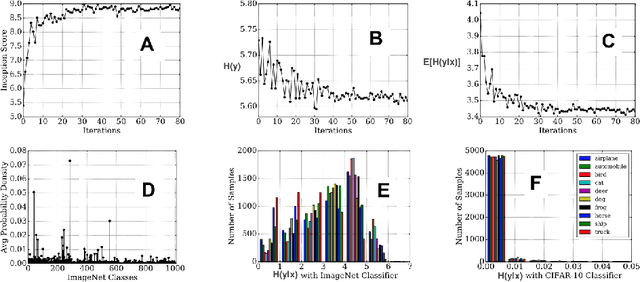
Generative models, in particular generative adversarial networks (GANs), have received significant attention recently. A number of GAN variants have been proposed and have been utilized in many applications. Despite large strides in terms of theoretical progress, evaluating and comparing GANs remains a daunting task. While several measures have been introduced, as of yet, there is no consensus as to which measure best captures strengths and limitations of models and should be used for fair model comparison. As in other areas of computer vision and machine learning, it is critical to settle on one or few good measures to steer the progress in this field. In this paper, I review and critically discuss more than 24 quantitative and 5 qualitative measures for evaluating generative models with a particular emphasis on GAN-derived models. I also provide a set of 7 desiderata followed by an evaluation of whether a given measure or a family of measures is compatible with them.
Saliency Prediction in the Deep Learning Era: An Empirical Investigation
Oct 11, 2018

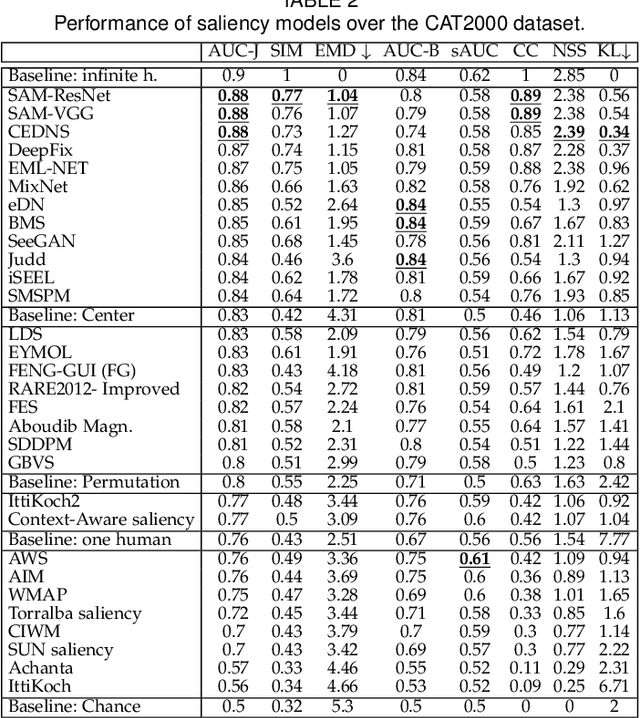

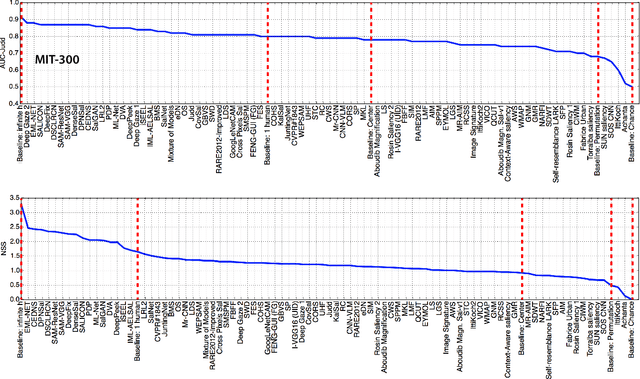
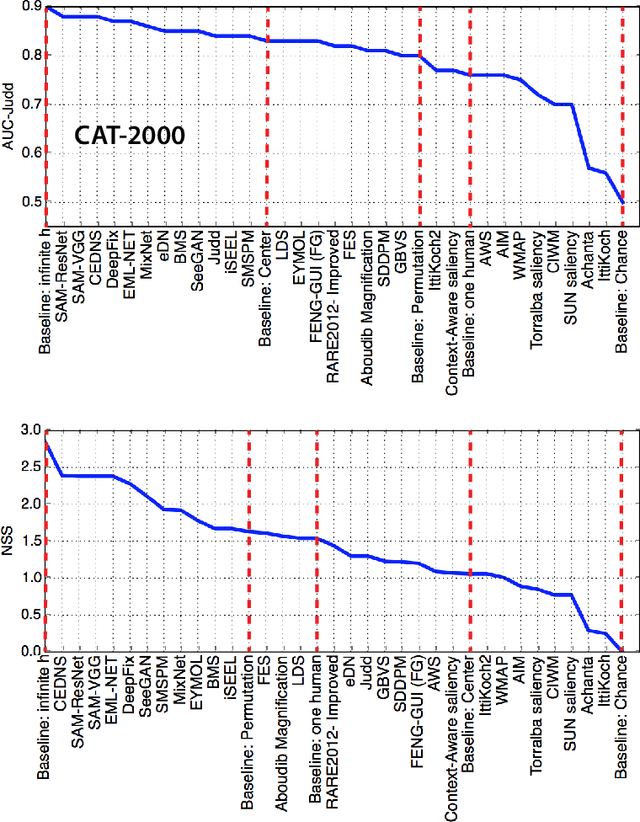
Visual saliency models have enjoyed a big leap in performance in recent years, thanks to advances in deep learning and large scale annotated data. Despite enormous effort and huge breakthroughs, however, models still fall short in reaching human-level accuracy. In this work, I explore the landscape of the field emphasizing on new deep saliency models, benchmarks, and datasets. A large number of image and video saliency models are reviewed and compared over two image benchmarks and two large scale video datasets. Further, I identify factors that contribute to the gap between models and humans and discuss remaining issues that need to be addressed to build the next generation of more powerful saliency models. Some specific questions that are addressed include: in what ways current models fail, how to remedy them, what can be learned from cognitive studies of attention, how explicit saliency judgments relate to fixations, how to conduct fair model comparison, and what are the emerging applications of saliency models.
Bottom-up Attention, Models of
Oct 11, 2018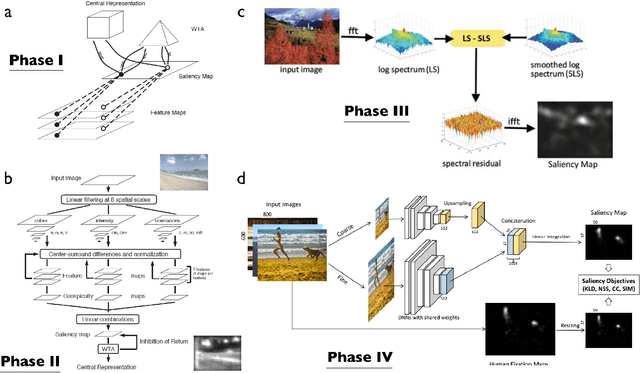

In this review, we examine the recent progress in saliency prediction and proposed several avenues for future research. In spite of tremendous efforts and huge progress, there is still room for improvement in terms finer-grained analysis of deep saliency models, evaluation measures, datasets, annotation methods, cognitive studies, and new applications. This chapter will appear in Encyclopedia of Computational Neuroscience.
Invariance Analysis of Saliency Models versus Human Gaze During Scene Free Viewing
Oct 10, 2018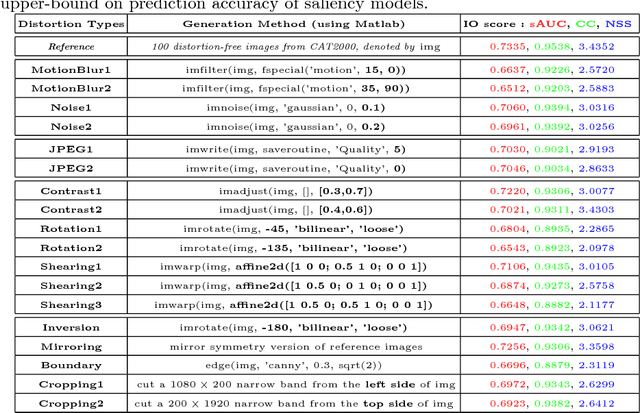
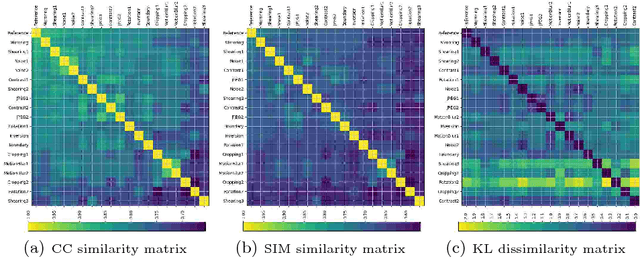
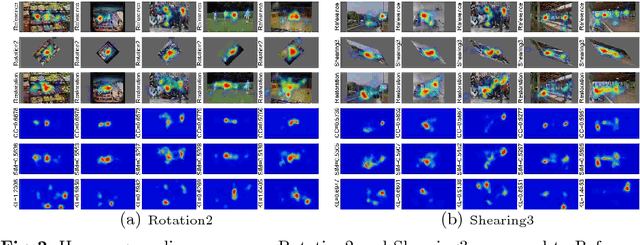
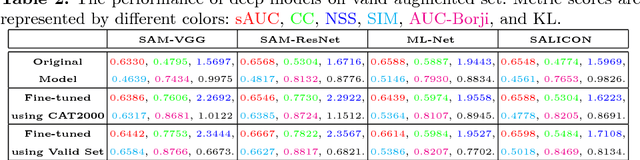
Most of current studies on human gaze and saliency modeling have used high-quality stimuli. In real world, however, captured images undergo various types of distortions during the whole acquisition, transmission, and displaying chain. Some distortion types include motion blur, lighting variations and rotation. Despite few efforts, influences of ubiquitous distortions on visual attention and saliency models have not been systematically investigated. In this paper, we first create a large-scale database including eye movements of 10 observers over 1900 images degraded by 19 types of distortions. Second, by analyzing eye movements and saliency models, we find that: a) observers look at different locations over distorted versus original images, and b) performances of saliency models are drastically hindered over distorted images, with the maximum performance drop belonging to Rotation and Shearing distortions. Finally, we investigate the effectiveness of different distortions when serving as data augmentation transformations. Experimental results verify that some useful data augmentation transformations which preserve human gaze of reference images can improve deep saliency models against distortions, while some invalid transformations which severely change human gaze will degrade the performance.
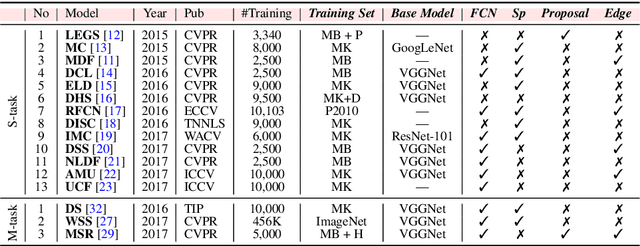
Salient Object Detection: A Survey
Sep 06, 2018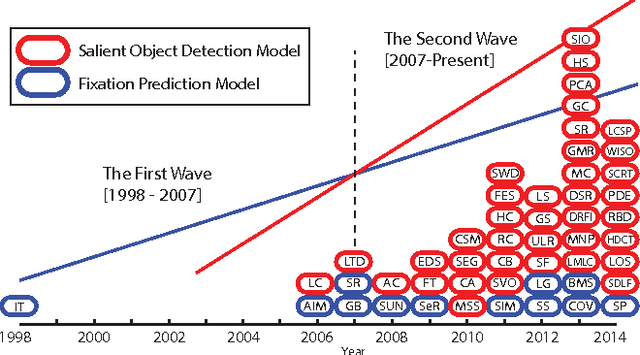


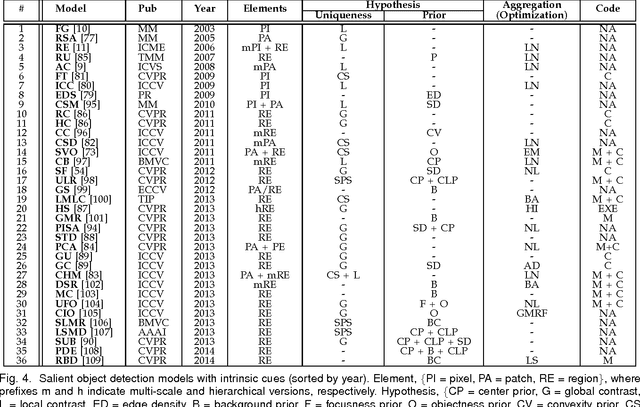
Detecting and segmenting salient objects in natural scenes, often referred to as salient object detection, has attracted a lot of interest in computer vision. While many models have been proposed and several applications have emerged, yet a deep understanding of achievements and issues is lacking. We aim to provide a comprehensive review of the recent progress in salient object detection and situate this field among other closely related areas such as generic scene segmentation, object proposal generation, and saliency for fixation prediction. Covering 228 publications, we survey i) roots, key concepts, and tasks, ii) core techniques and main modeling trends, and iii) datasets and evaluation metrics in salient object detection. We also discuss open problems such as evaluation metrics and dataset bias in model performance and suggest future research directions.
Cross-view image synthesis using geometry-guided conditional GANs
Aug 14, 2018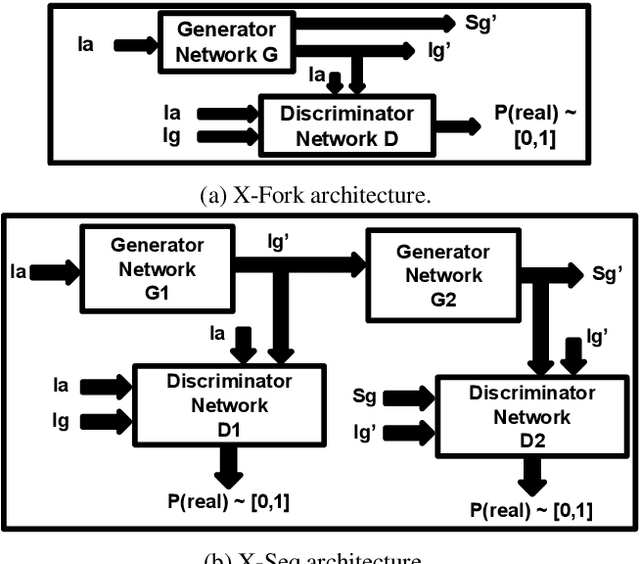
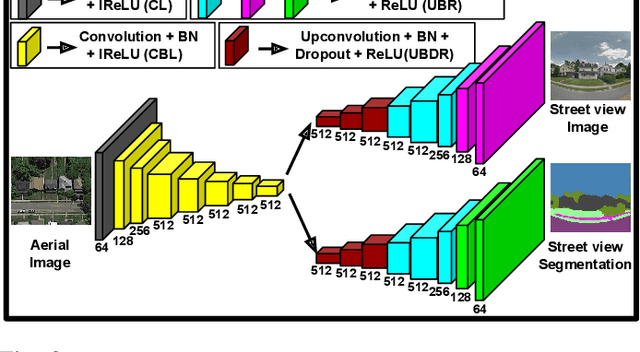
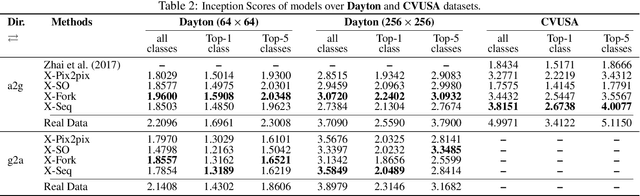

We address the problem of generating images across two drastically different views, namely ground (street) and aerial (overhead) views. Image synthesis by itself is a very challenging computer vision task and is even more so when generation is conditioned on an image in another view. Due the difference in viewpoints, there is small overlapping field of view and little common content between these two views. Here, we try to preserve the pixel information between the views so that the generated image is a realistic representation of cross view input image. For this, we propose to use homography as a guide to map the images between the views based on the common field of view to preserve the details in the input image. We then use generative adversarial networks to inpaint the missing regions in the transformed image and add realism to it. Our exhaustive evaluation and model comparison demonstrate that utilizing geometry constraints adds fine details to the generated images and can be a better approach for cross view image synthesis than purely pixel based synthesis methods.
Enhanced-alignment Measure for Binary Foreground Map Evaluation
Jul 24, 2018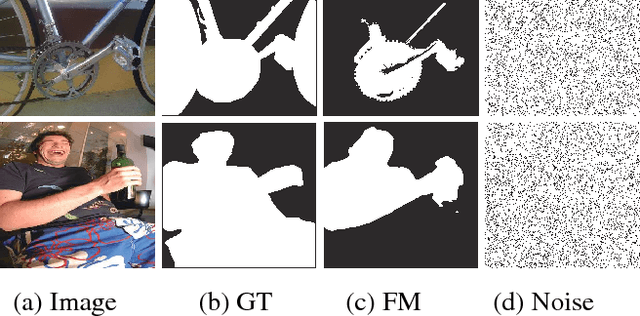

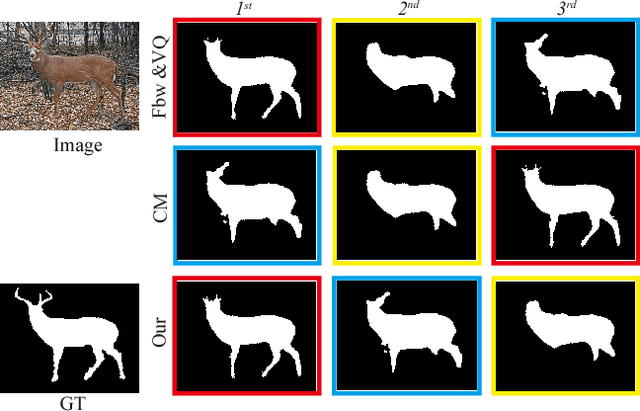

The existing binary foreground map (FM) measures to address various types of errors in either pixel-wise or structural ways. These measures consider pixel-level match or image-level information independently, while cognitive vision studies have shown that human vision is highly sensitive to both global information and local details in scenes. In this paper, we take a detailed look at current binary FM evaluation measures and propose a novel and effective E-measure (Enhanced-alignment measure). Our measure combines local pixel values with the image-level mean value in one term, jointly capturing image-level statistics and local pixel matching information. We demonstrate the superiority of our measure over the available measures on 4 popular datasets via 5 meta-measures, including ranking models for applications, demoting generic, random Gaussian noise maps, ground-truth switch, as well as human judgments. We find large improvements in almost all the meta-measures. For instance, in terms of application ranking, we observe improvementrangingfrom9.08% to 19.65% compared with other popular measures.
Salient Objects in Clutter: Bringing Salient Object Detection to the Foreground
Jul 22, 2018


We provide a comprehensive evaluation of salient object detection (SOD) models. Our analysis identifies a serious design bias of existing SOD datasets which assumes that each image contains at least one clearly outstanding salient object in low clutter. The design bias has led to a saturated high performance for state-of-the-art SOD models when evaluated on existing datasets. The models, however, still perform far from being satisfactory when applied to real-world daily scenes. Based on our analyses, we first identify 7 crucial aspects that a comprehensive and balanced dataset should fulfill. Then, we propose a new high quality dataset and update the previous saliency benchmark. Specifically, our SOC (Salient Objects in Clutter) dataset, includes images with salient and non-salient objects from daily object categories. Beyond object category annotations, each salient image is accompanied by attributes that reflect common challenges in real-world scenes. Finally, we report attribute-based performance assessment on our dataset.