 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMatch: Matching based Video Object Segmentation
Sep 04, 2018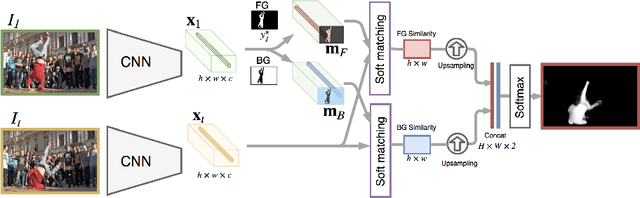

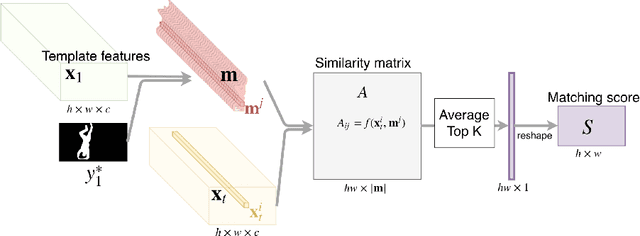

Video object segmentation is challenging yet important in a wide variety of applications for video analysis. Recent works formulate video object segmentation as a prediction task using deep nets to achieve appealing state-of-the-art performance. Due to the formulation as a prediction task, most of these methods require fine-tuning during test time, such that the deep nets memorize the appearance of the objects of interest in the given video. However, fine-tuning is time-consuming and computationally expensive, hence the algorithms are far from real time. To address this issue, we develop a novel matching based algorithm for video object segmentation. In contrast to memorization based classification techniques, the proposed approach learns to match extracted features to a provided template without memorizing the appearance of the objects. We validate the effectiveness and the robustness of the proposed method on the challenging DAVIS-16, DAVIS-17, Youtube-Objects and JumpCut datasets. Extensive results show that our method achieves comparable performance without fine-tuning and is much more favorable in terms of computational time.
Diverse and Coherent Paragraph Generation from Images
Sep 03, 2018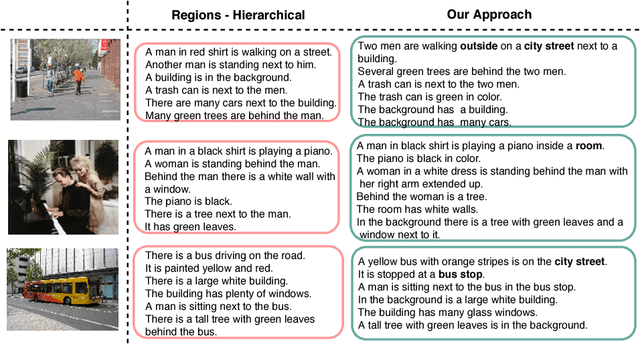
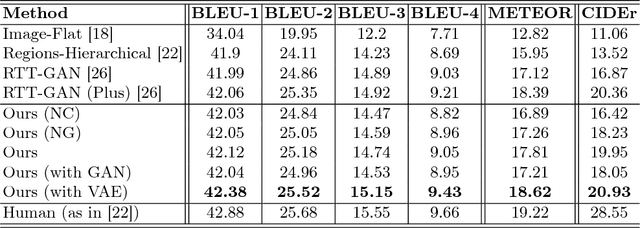
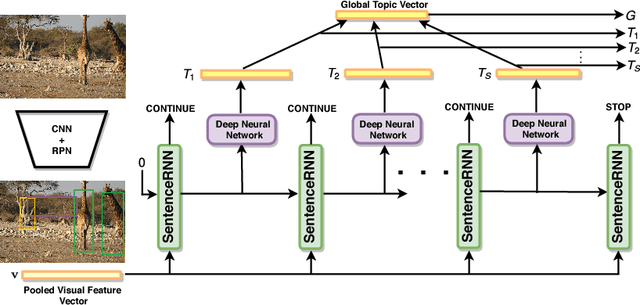
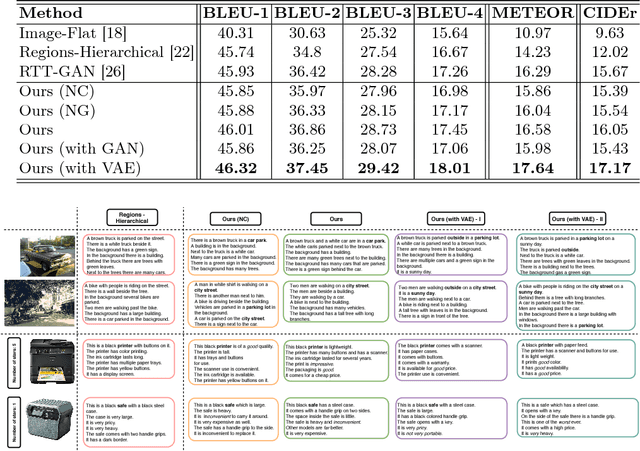
Paragraph generation from images, which has gained popularity recently, is an important task for video summarization, editing, and support of the disabled. Traditional image captioning methods fall short on this front, since they aren't designed to generate long informative descriptions. Moreover, the vanilla approach of simply concatenating multiple short sentences, possibly synthesized from a classical image captioning system, doesn't embrace the intricacies of paragraphs: coherent sentences, globally consistent structure, and diversity. To address those challenges, we propose to augment paragraph generation techniques with 'coherence vectors', 'global topic vectors', and modeling of the inherent ambiguity of associating paragraphs with images, via a variational auto-encoder formulation. We demonstrate the effectiveness of the developed approach on two datasets, outperforming existing state-of-the-art techniques on both.
Interpretable and Globally Optimal Prediction for Textual Grounding using Image Concepts
Mar 29, 2018
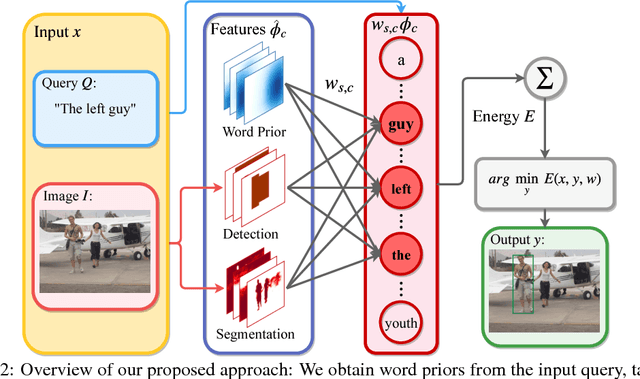
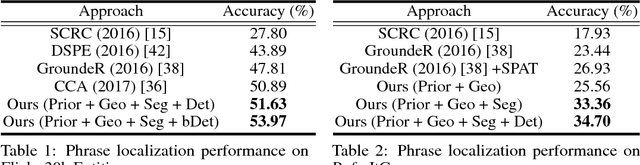

Textual grounding is an important but challenging task for human-computer interaction, robotics and knowledge mining. Existing algorithms generally formulate the task as selection from a set of bounding box proposals obtained from deep net based systems. In this work, we demonstrate that we can cast the problem of textual grounding into a unified framework that permits efficient search over all possible bounding boxes. Hence, the method is able to consider significantly more proposals and doesn't rely on a successful first stage hypothesizing bounding box proposals. Beyond, we demonstrate that the trained parameters of our model can be used as word-embeddings which capture spatial-image relationships and provide interpretability. Lastly, at the time of submission, our approach outperformed the current state-of-the-art methods on the Flickr 30k Entities and the ReferItGame dataset by 3.08% and 7.77% respectively.
MaskRNN: Instance Level Video Object Segmentation
Mar 29, 2018
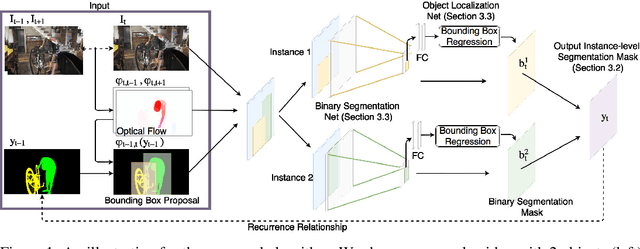
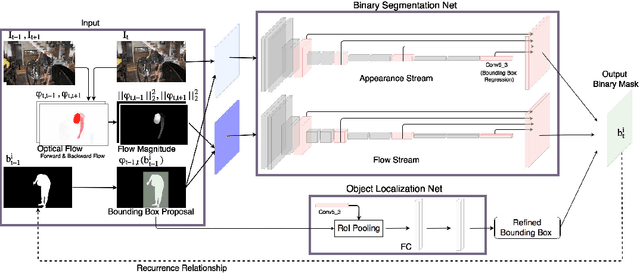
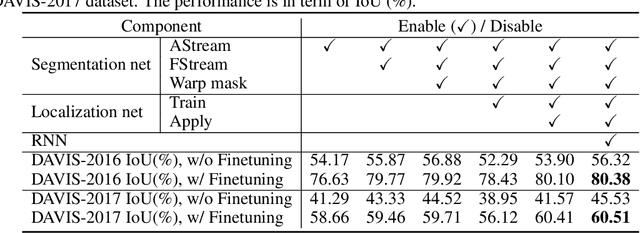
Instance level video object segmentation is an important technique for video editing and compression. To capture the temporal coherence, in this paper, we develop MaskRNN, a recurrent neural net approach which fuses in each frame the output of two deep nets for each object instance -- a binary segmentation net providing a mask and a localization net providing a bounding box. Due to the recurrent component and the localization component, our method is able to take advantage of long-term temporal structures of the video data as well as rejecting outliers. We validate the proposed algorithm on three challenging benchmark datasets, the DAVIS-2016 dataset, the DAVIS-2017 dataset, and the Segtrack v2 dataset, achieving state-of-the-art performance on all of them.
Unsupervised Textual Grounding: Linking Words to Image Concepts
Mar 29, 2018
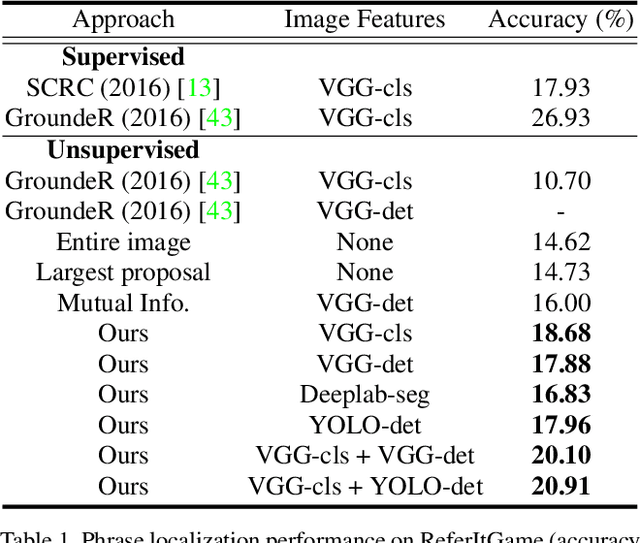
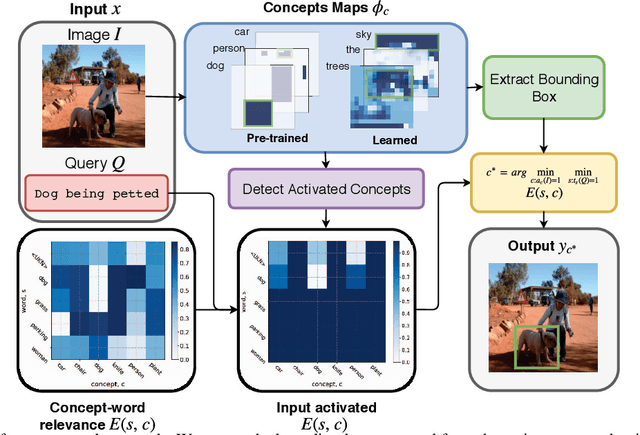
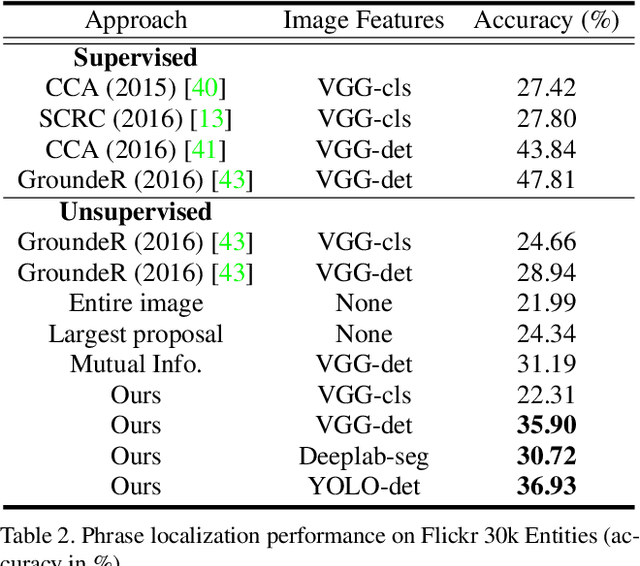
Textual grounding, i.e., linking words to objects in images, is a challenging but important task for robotics and human-computer interaction. Existing techniques benefit from recent progress in deep learning and generally formulate the task as a supervised learning problem, selecting a bounding box from a set of possible options. To train these deep net based approaches, access to a large-scale datasets is required, however, constructing such a dataset is time-consuming and expensive. Therefore, we develop a completely unsupervised mechanism for textual grounding using hypothesis testing as a mechanism to link words to detected image concepts. We demonstrate our approach on the ReferIt Game dataset and the Flickr30k data, outperforming baselines by 7.98% and 6.96% respectively.
Diverse and Accurate Image Description Using a Variational Auto-Encoder with an Additive Gaussian Encoding Space
Nov 19, 2017
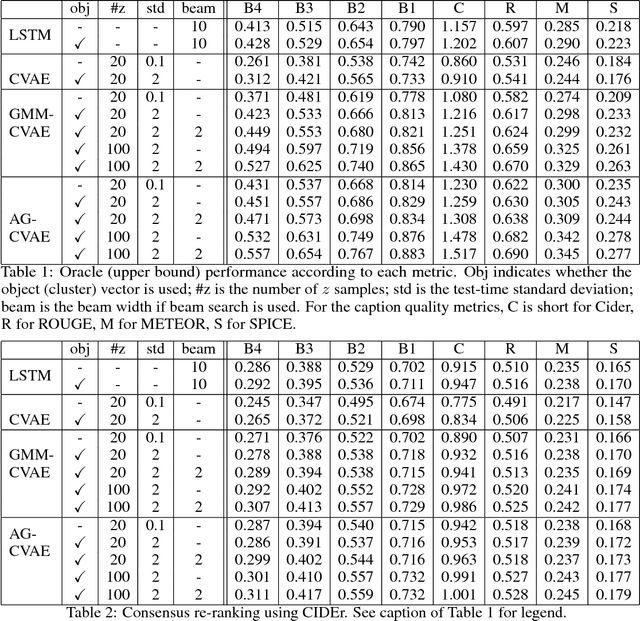

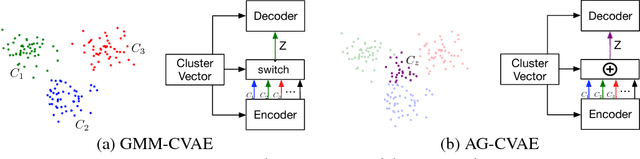
This paper explores image caption generation using conditional variational auto-encoders (CVAEs). Standard CVAEs with a fixed Gaussian prior yield descriptions with too little variability. Instead, we propose two models that explicitly structure the latent space around $K$ components corresponding to different types of image content, and combine components to create priors for images that contain multiple types of content simultaneously (e.g., several kinds of objects). Our first model uses a Gaussian Mixture model (GMM) prior, while the second one defines a novel Additive Gaussian (AG) prior that linearly combines component means. We show that both models produce captions that are more diverse and more accurate than a strong LSTM baseline or a "vanilla" CVAE with a fixed Gaussian prior, with AG-CVAE showing particular promise.
High-Order Attention Models for Visual Question Answering
Nov 12, 2017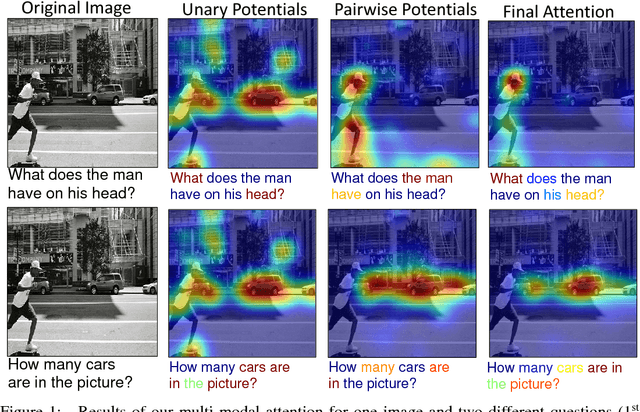
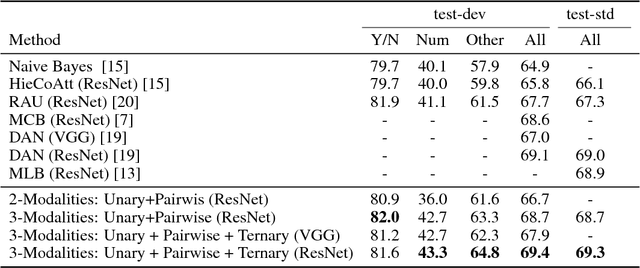
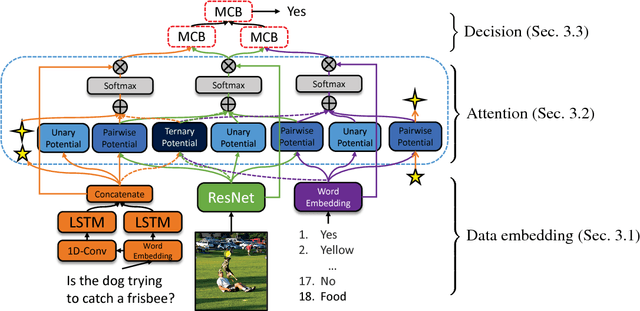
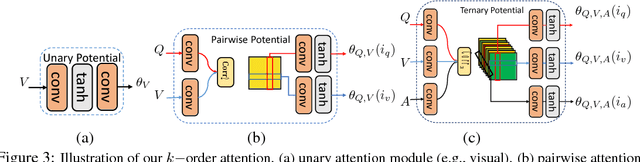
The quest for algorithms that enable cognitive abilities is an important part of machine learning. A common trait in many recently investigated cognitive-like tasks is that they take into account different data modalities, such as visual and textual input. In this paper we propose a novel and generally applicable form of attention mechanism that learns high-order correlations between various data modalities. We show that high-order correlations effectively direct the appropriate attention to the relevant elements in the different data modalities that are required to solve the joint task. We demonstrate the effectiveness of our high-order attention mechanism on the task of visual question answering (VQA), where we achieve state-of-the-art performance on the standard VQA dataset.
Semantic Image Inpainting with Deep Generative Models
Jul 13, 2017
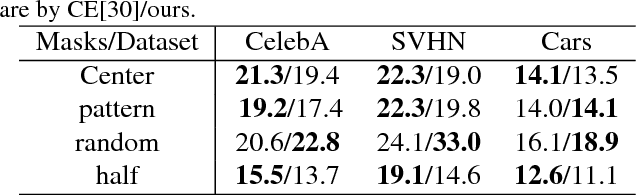

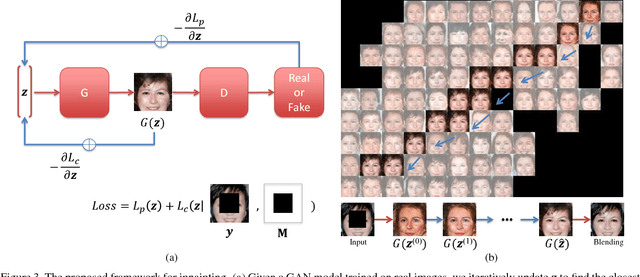
Semantic image inpainting is a challenging task where large missing regions have to be filled based on the available visual data. Existing methods which extract information from only a single image generally produce unsatisfactory results due to the lack of high level context. In this paper, we propose a novel method for semantic image inpainting, which generates the missing content by conditioning on the available data. Given a trained generative model, we search for the closest encoding of the corrupted image in the latent image manifold using our context and prior losses. This encoding is then passed through the generative model to infer the missing content. In our method, inference is possible irrespective of how the missing content is structured, while the state-of-the-art learning based method requires specific information about the holes in the training phase. Experiments on three datasets show that our method successfully predicts information in large missing regions and achieves pixel-level photorealism, significantly outperforming the state-of-the-art methods.
Learning to Play in a Day: Faster Deep Reinforcement Learning by Optimality Tightening
Nov 05, 2016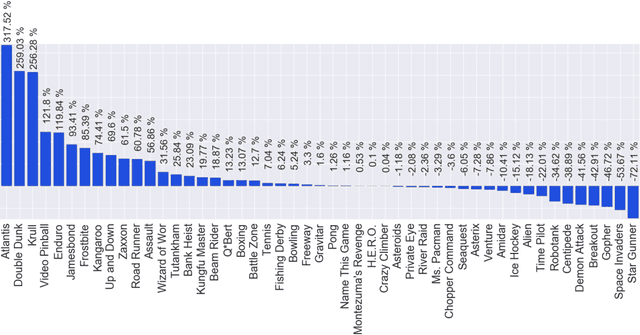

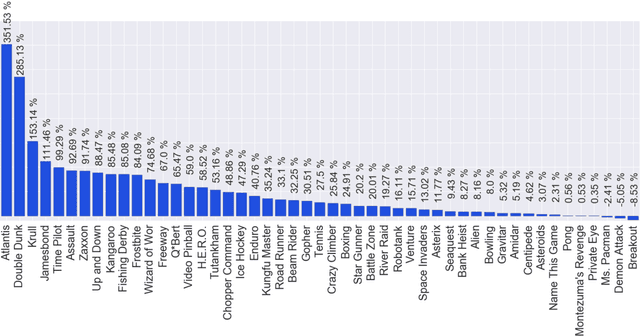
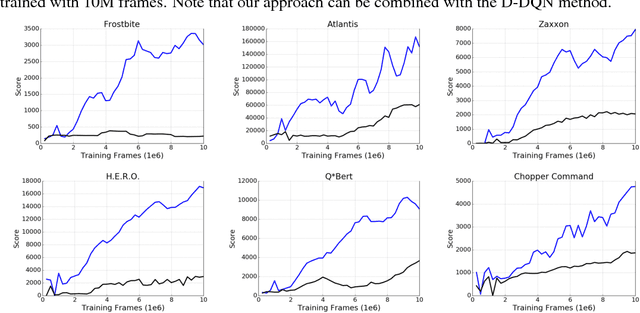
We propose a novel training algorithm for reinforcement learning which combines the strength of deep Q-learning with a constrained optimization approach to tighten optimality and encourage faster reward propagation. Our novel technique makes deep reinforcement learning more practical by drastically reducing the training time. We evaluate the performance of our approach on the 49 games of the challenging Arcade Learning Environment, and report significant improvements in both training time and accuracy.
Training Deep Neural Networks via Direct Loss Minimization
Jun 02, 2016
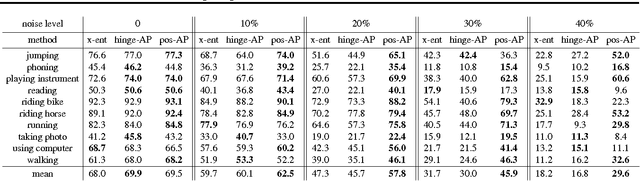

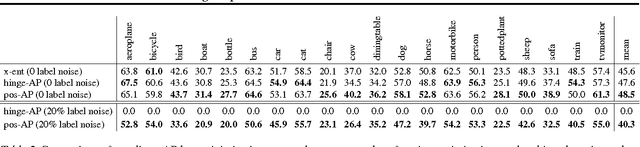
Supervised training of deep neural nets typically relies on minimizing cross-entropy. However, in many domains, we are interested in performing well on metrics specific to the application. In this paper we propose a direct loss minimization approach to train deep neural networks, which provably minimizes the application-specific loss function. This is often non-trivial, since these functions are neither smooth nor decomposable and thus are not amenable to optimization with standard gradient-based methods. We demonstrate the effectiveness of our approach in the context of maximizing average precision for ranking problems. Towards this goal, we develop a novel dynamic programming algorithm that can efficiently compute the weight updates. Our approach proves superior to a variety of baselines in the context of action classification and object detection, especially in the presence of label noise.