 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving challenges in deep learning-based analyses of histopathological images using explanation methods
Aug 15, 2019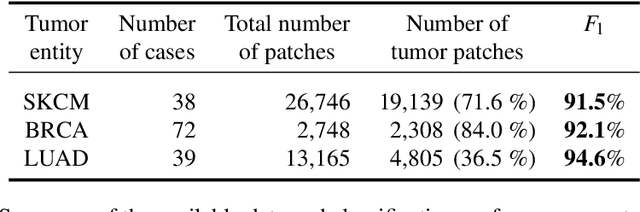
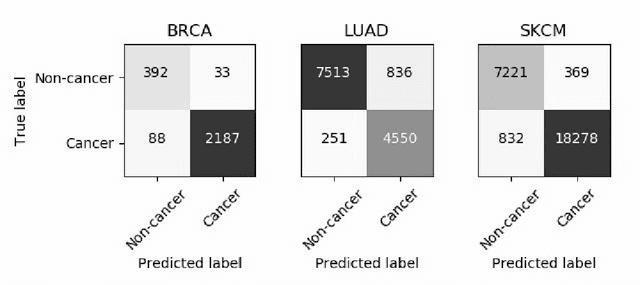

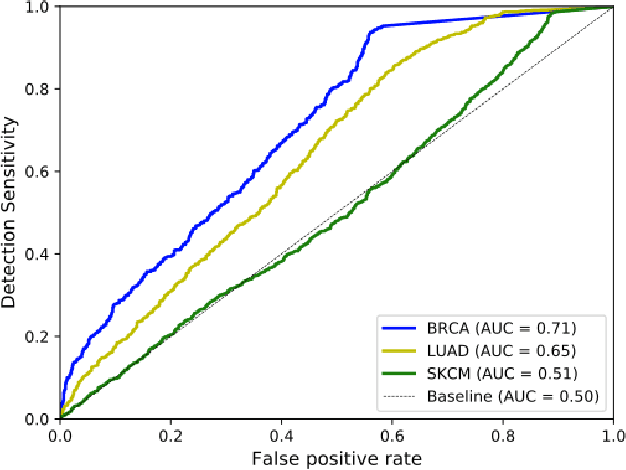
Deep learning has recently gained popularity in digital pathology due to its high prediction quality. However, the medical domain requires explanation and insight for a better understanding beyond standard quantitative performance evaluation. Recently, explanation methods have emerged, which are so far still rarely used in medicine. This work shows their application to generate heatmaps that allow to resolve common challenges encountered in deep learning-based digital histopathology analyses. These challenges comprise biases typically inherent to histopathology data. We study binary classification tasks of tumor tissue discrimination in publicly available haematoxylin and eosin slides of various tumor entities and investigate three types of biases: (1) biases which affect the entire dataset, (2) biases which are by chance correlated with class labels and (3) sampling biases. While standard analyses focus on patch-level evaluation, we advocate pixel-wise heatmaps, which offer a more precise and versatile diagnostic instrument and furthermore help to reveal biases in the data. This insight is shown to not only detect but also to be helpful to remove the effects of common hidden biases, which improves generalization within and across datasets. For example, we could see a trend of improved area under the receiver operating characteristic curve by 5% when reducing a labeling bias. Explanation techniques are thus demonstrated to be a helpful and highly relevant tool for the development and the deployment phases within the life cycle of real-world applications in digital pathology.
Deep Semi-Supervised Anomaly Detection
Jun 06, 2019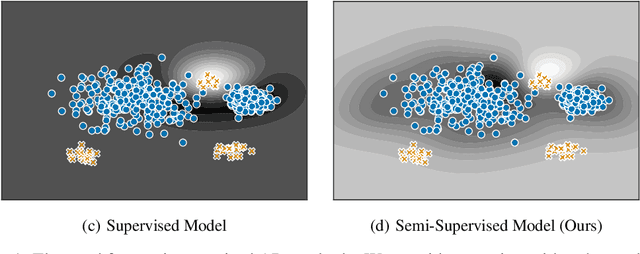
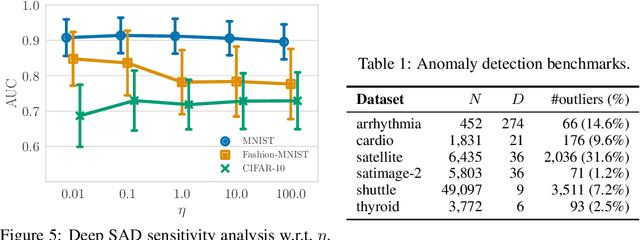
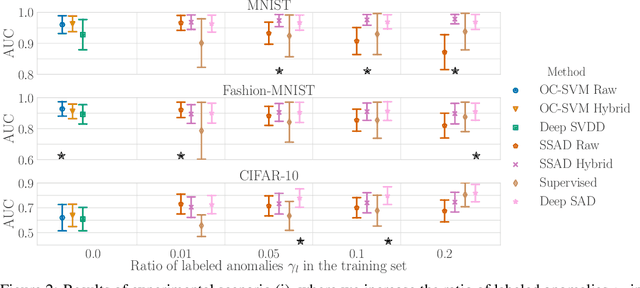
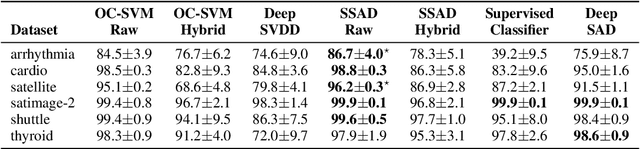
Deep approaches to anomaly detection have recently shown promising results over shallow approaches on high-dimensional data. Typically anomaly detection is treated as an unsupervised learning problem. In practice however, one may have---in addition to a large set of unlabeled samples---access to a small pool of labeled samples, e.g. a subset verified by some domain expert as being normal or anomalous. Semi-supervised approaches to anomaly detection make use of such labeled data to improve detection performance. Few deep semi-supervised approaches to anomaly detection have been proposed so far and those that exist are domain-specific. In this work, we present Deep SAD, an end-to-end methodology for deep semi-supervised anomaly detection. Using an information-theoretic perspective on anomaly detection, we derive a loss motivated by the idea that the entropy for the latent distribution of normal data should be lower than the entropy of the anomalous distribution. We demonstrate in extensive experiments on MNIST, Fashion-MNIST, and CIFAR-10 along with other anomaly detection benchmark datasets that our approach is on par or outperforms shallow, hybrid, and deep competitors, even when provided with only few labeled training data.
Adversarial Attacks on Remote User Authentication Using Behavioural Mouse Dynamics
May 28, 2019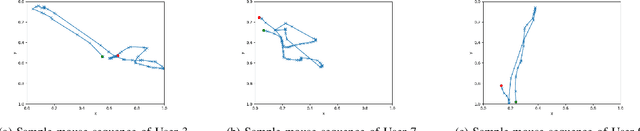
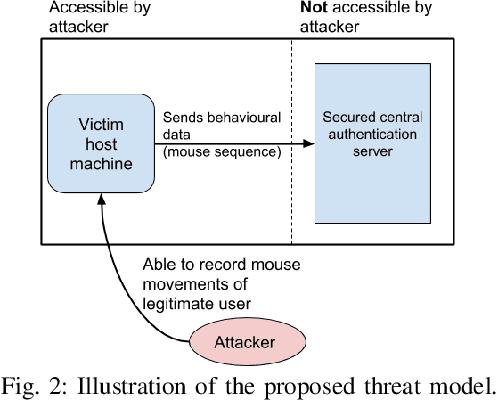
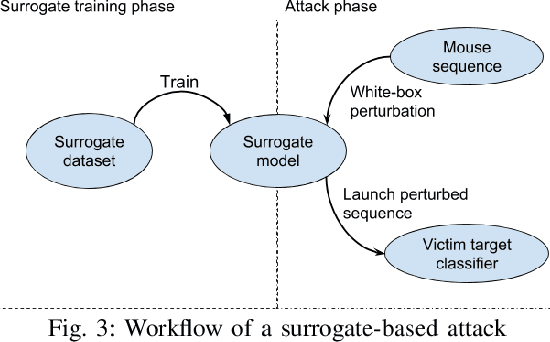
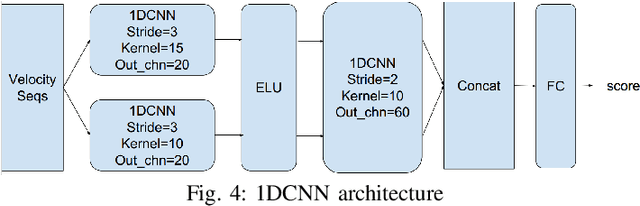
Mouse dynamics is a potential means of authenticating users. Typically, the authentication process is based on classical machine learning techniques, but recently, deep learning techniques have been introduced for this purpose. Although prior research has demonstrated how machine learning and deep learning algorithms can be bypassed by carefully crafted adversarial samples, there has been very little research performed on the topic of behavioural biometrics in the adversarial domain. In an attempt to address this gap, we built a set of attacks, which are applications of several generative approaches, to construct adversarial mouse trajectories that bypass authentication models. These generated mouse sequences will serve as the adversarial samples in the context of our experiments. We also present an analysis of the attack approaches we explored, explaining their limitations. In contrast to previous work, we consider the attacks in a more realistic and challenging setting in which an attacker has access to recorded user data but does not have access to the authentication model or its outputs. We explore three different attack strategies: 1) statistics-based, 2) imitation-based, and 3) surrogate-based; we show that they are able to evade the functionality of the authentication models, thereby impacting their robustness adversely. We show that imitation-based attacks often perform better than surrogate-based attacks, unless, however, the attacker can guess the architecture of the authentication model. In such cases, we propose a potential detection mechanism against surrogate-based attacks.
Unmasking Clever Hans Predictors and Assessing What Machines Really Learn
Feb 26, 2019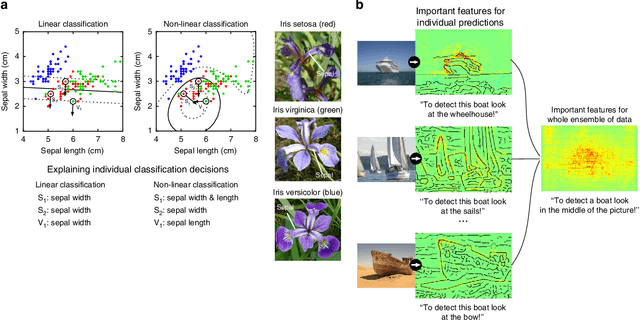
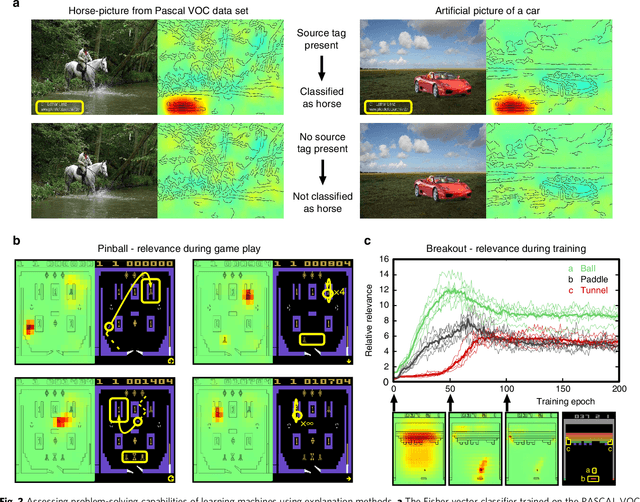
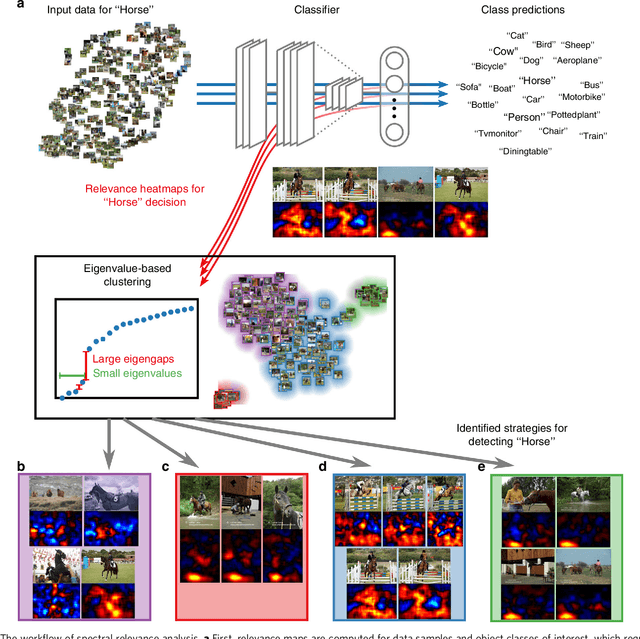
Current learning machines have successfully solved hard application problems, reaching high accuracy and displaying seemingly "intelligent" behavior. Here we apply recent techniques for explaining decisions of state-of-the-art learning machines and analyze various tasks from computer vision and arcade games. This showcases a spectrum of problem-solving behaviors ranging from naive and short-sighted, to well-informed and strategic. We observe that standard performance evaluation metrics can be oblivious to distinguishing these diverse problem solving behaviors. Furthermore, we propose our semi-automated Spectral Relevance Analysis that provides a practically effective way of characterizing and validating the behavior of nonlinear learning machines. This helps to assess whether a learned model indeed delivers reliably for the problem that it was conceived for. Furthermore, our work intends to add a voice of caution to the ongoing excitement about machine intelligence and pledges to evaluate and judge some of these recent successes in a more nuanced manner.
Towards computational fluorescence microscopy: Machine learning-based integrated prediction of morphological and molecular tumor profiles
May 28, 2018
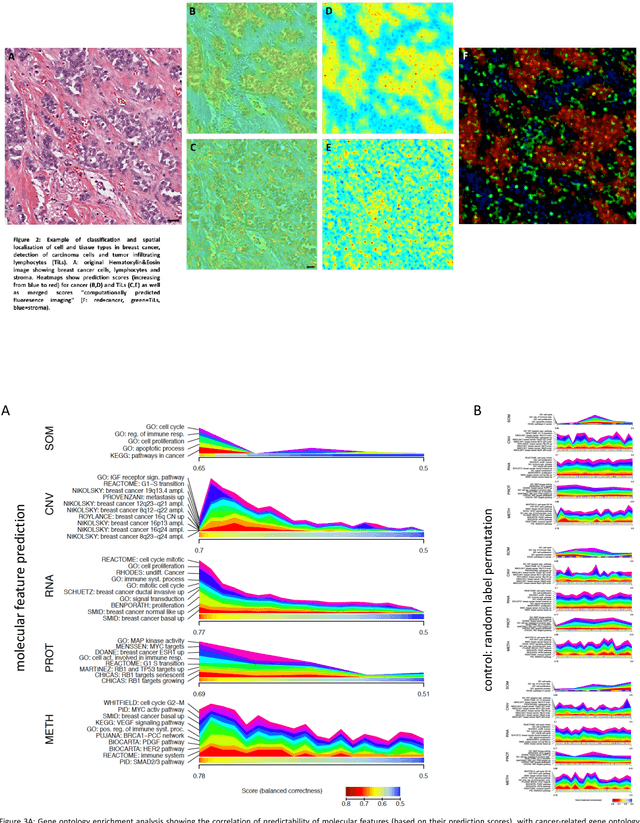
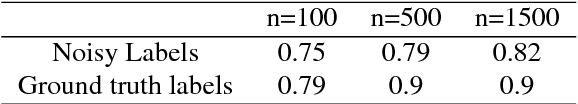

Recent advances in cancer research largely rely on new developments in microscopic or molecular profiling techniques offering high level of detail with respect to either spatial or molecular features, but usually not both. Here, we present a novel machine learning-based computational approach that allows for the identification of morphological tissue features and the prediction of molecular properties from breast cancer imaging data. This integration of microanatomic information of tumors with complex molecular profiling data, including protein or gene expression, copy number variation, gene methylation and somatic mutations, provides a novel means to computationally score molecular markers with respect to their relevance to cancer and their spatial associations within the tumor microenvironment.
Understanding and Comparing Deep Neural Networks for Age and Gender Classification
Aug 25, 2017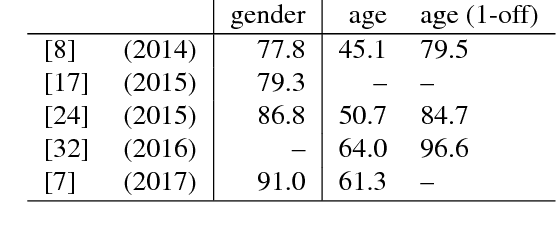
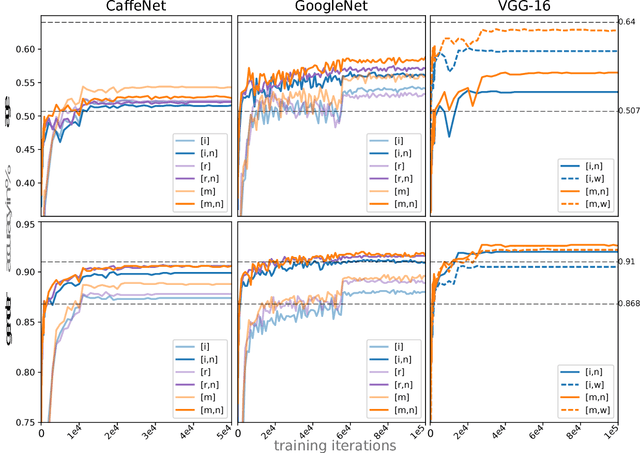
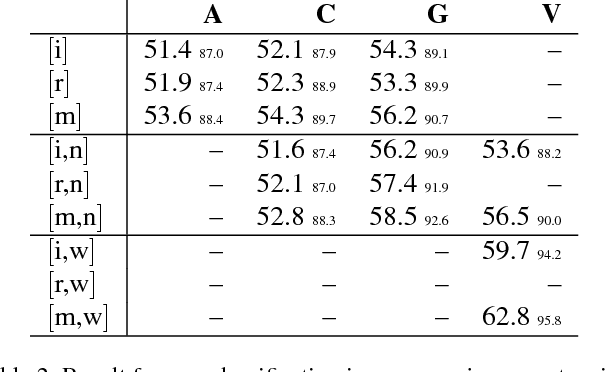

Recently, deep neural networks have demonstrated excellent performances in recognizing the age and gender on human face images. However, these models were applied in a black-box manner with no information provided about which facial features are actually used for prediction and how these features depend on image preprocessing, model initialization and architecture choice. We present a study investigating these different effects. In detail, our work compares four popular neural network architectures, studies the effect of pretraining, evaluates the robustness of the considered alignment preprocessings via cross-method test set swapping and intuitively visualizes the model's prediction strategies in given preprocessing conditions using the recent Layer-wise Relevance Propagation (LRP) algorithm. Our evaluations on the challenging Adience benchmark show that suitable parameter initialization leads to a holistic perception of the input, compensating artefactual data representations. With a combination of simple preprocessing steps, we reach state of the art performance in gender recognition.
Object Boundary Detection and Classification with Image-level Labels
Jun 25, 2017



Semantic boundary and edge detection aims at simultaneously detecting object edge pixels in images and assigning class labels to them. Systematic training of predictors for this task requires the labeling of edges in images which is a particularly tedious task. We propose a novel strategy for solving this task, when pixel-level annotations are not available, performing it in an almost zero-shot manner by relying on conventional whole image neural net classifiers that were trained using large bounding boxes. Our method performs the following two steps at test time. Firstly it predicts the class labels by applying the trained whole image network to the test images. Secondly, it computes pixel-wise scores from the obtained predictions by applying backprop gradients as well as recent visualization algorithms such as deconvolution and layer-wise relevance propagation. We show that high pixel-wise scores are indicative for the location of semantic boundaries, which suggests that the semantic boundary problem can be approached without using edge labels during the training phase.
Interpreting the Predictions of Complex ML Models by Layer-wise Relevance Propagation
Nov 24, 2016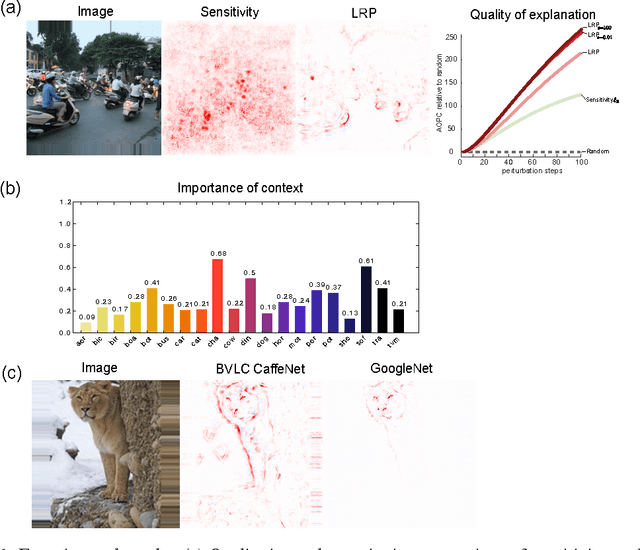
Complex nonlinear models such as deep neural network (DNNs) have become an important tool for image classification, speech recognition, natural language processing, and many other fields of application. These models however lack transparency due to their complex nonlinear structure and to the complex data distributions to which they typically apply. As a result, it is difficult to fully characterize what makes these models reach a particular decision for a given input. This lack of transparency can be a drawback, especially in the context of sensitive applications such as medical analysis or security. In this short paper, we summarize a recent technique introduced by Bach et al. [1] that explains predictions by decomposing the classification decision of DNN models in terms of input variables.
Localized Multiple Kernel Learning---A Convex Approach
Oct 13, 2016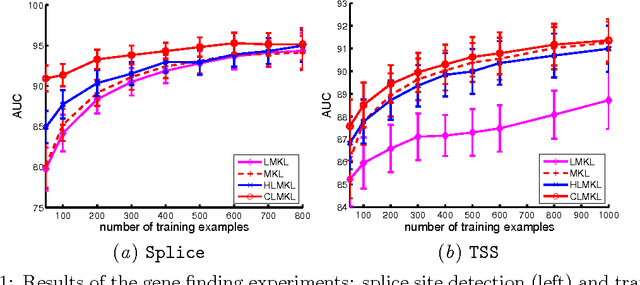
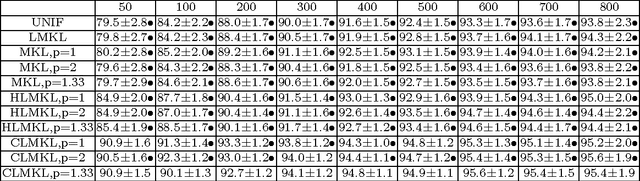
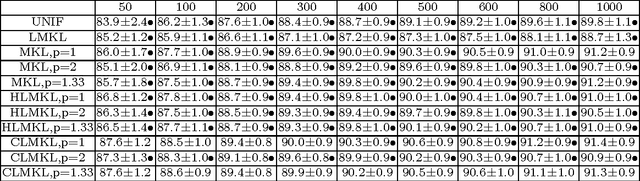

We propose a localized approach to multiple kernel learning that can be formulated as a convex optimization problem over a given cluster structure. For which we obtain generalization error guarantees and derive an optimization algorithm based on the Fenchel dual representation. Experiments on real-world datasets from the application domains of computational biology and computer vision show that convex localized multiple kernel learning can achieve higher prediction accuracies than its global and non-convex local counterparts.
Layer-wise Relevance Propagation for Neural Networks with Local Renormalization Layers
Apr 04, 2016

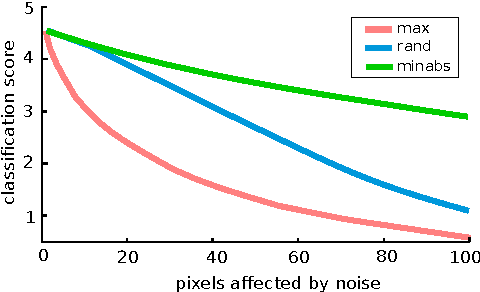
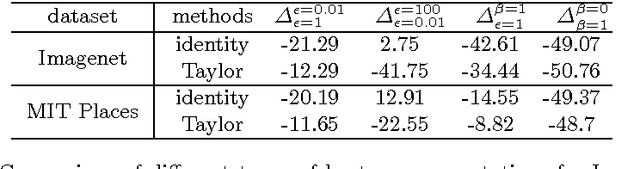
Layer-wise relevance propagation is a framework which allows to decompose the prediction of a deep neural network computed over a sample, e.g. an image, down to relevance scores for the single input dimensions of the sample such as subpixels of an image. While this approach can be applied directly to generalized linear mappings, product type non-linearities are not covered. This paper proposes an approach to extend layer-wise relevance propagation to neural networks with local renormalization layers, which is a very common product-type non-linearity in convolutional neural networks. We evaluate the proposed method for local renormalization layers on the CIFAR-10, Imagenet and MIT Places datasets.