 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoli-enabled Noncontact Heart Rate Detection for Sleep and Meditation Tracking
Jul 08, 2024Heart rate (HR) is a crucial physiological signal that can be used to monitor health and fitness. Traditional methods for measuring HR require wearable devices, which can be inconvenient or uncomfortable, especially during sleep and meditation. Noncontact HR detection methods employing microwave radar can be a promising alternative. However, the existing approaches in the literature usually use high-gain antennas and require the sensor to face the user's chest or back, making them difficult to integrate into a portable device and unsuitable for sleep and meditation tracking applications. This study presents a novel approach for noncontact HR detection using a miniaturized Soli radar chip embedded in a portable device (Google Nest Hub). The chip has a $6.5 \mbox{ mm} \times 5 \mbox{ mm} \times 0.9 \mbox{ mm}$ dimension and can be easily integrated into various devices. The proposed approach utilizes advanced signal processing and machine learning techniques to extract HRs from radar signals. The approach is validated on a sleep dataset (62 users, 498 hours) and a meditation dataset (114 users, 1131 minutes). The approach achieves a mean absolute error (MAE) of $1.69$ bpm and a mean absolute percentage error (MAPE) of $2.67\%$ on the sleep dataset. On the meditation dataset, the approach achieves an MAE of $1.05$ bpm and a MAPE of $1.56\%$. The recall rates for the two datasets are $88.53\%$ and $98.16\%$, respectively. This study represents the first application of the noncontact HR detection technology to sleep and meditation tracking, offering a promising alternative to wearable devices for HR monitoring during sleep and meditation.
* 15 pages
LGMCTS: Language-Guided Monte-Carlo Tree Search for Executable Semantic Object Rearrangement
Sep 27, 2023



We introduce a novel approach to the executable semantic object rearrangement problem. In this challenge, a robot seeks to create an actionable plan that rearranges objects within a scene according to a pattern dictated by a natural language description. Unlike existing methods such as StructFormer and StructDiffusion, which tackle the issue in two steps by first generating poses and then leveraging a task planner for action plan formulation, our method concurrently addresses pose generation and action planning. We achieve this integration using a Language-Guided Monte-Carlo Tree Search (LGMCTS). Quantitative evaluations are provided on two simulation datasets, and complemented by qualitative tests with a real robot.
Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control
Dec 03, 2018

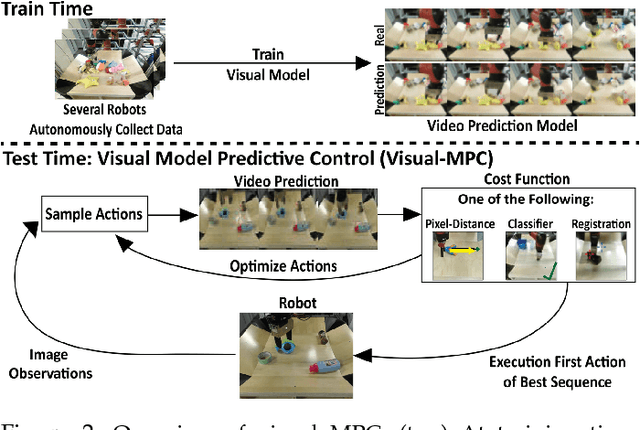

Deep reinforcement learning (RL) algorithms can learn complex robotic skills from raw sensory inputs, but have yet to achieve the kind of broad generalization and applicability demonstrated by deep learning methods in supervised domains. We present a deep RL method that is practical for real-world robotics tasks, such as robotic manipulation, and generalizes effectively to never-before-seen tasks and objects. In these settings, ground truth reward signals are typically unavailable, and we therefore propose a self-supervised model-based approach, where a predictive model learns to directly predict the future from raw sensory readings, such as camera images. At test time, we explore three distinct goal specification methods: designated pixels, where a user specifies desired object manipulation tasks by selecting particular pixels in an image and corresponding goal positions, goal images, where the desired goal state is specified with an image, and image classifiers, which define spaces of goal states. Our deep predictive models are trained using data collected autonomously and continuously by a robot interacting with hundreds of objects, without human supervision. We demonstrate that visual MPC can generalize to never-before-seen objects---both rigid and deformable---and solve a range of user-defined object manipulation tasks using the same model.