 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Fried Convnets
Jul 17, 2015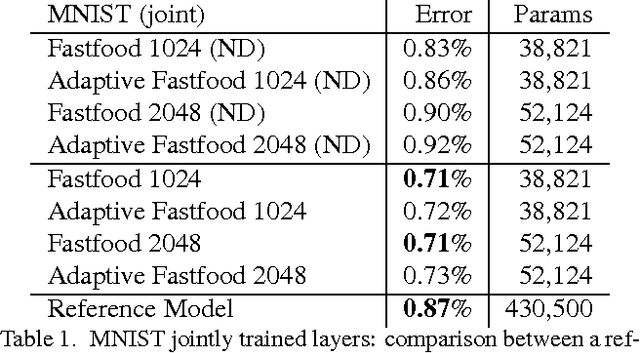
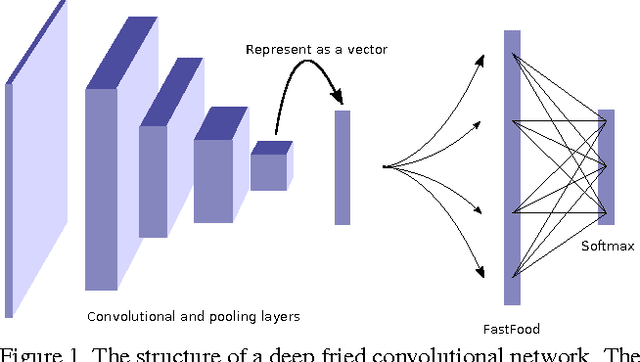
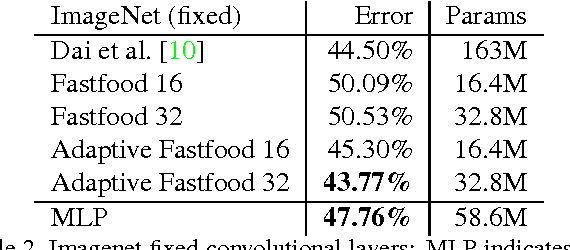
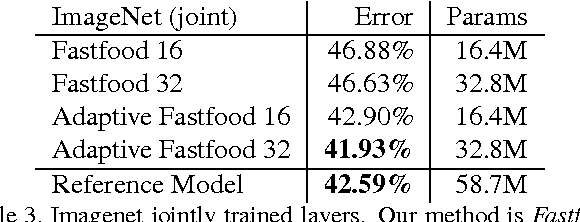
The fully connected layers of a deep convolutional neural network typically contain over 90% of the network parameters, and consume the majority of the memory required to store the network parameters. Reducing the number of parameters while preserving essentially the same predictive performance is critically important for operating deep neural networks in memory constrained environments such as GPUs or embedded devices. In this paper we show how kernel methods, in particular a single Fastfood layer, can be used to replace all fully connected layers in a deep convolutional neural network. This novel Fastfood layer is also end-to-end trainable in conjunction with convolutional layers, allowing us to combine them into a new architecture, named deep fried convolutional networks, which substantially reduces the memory footprint of convolutional networks trained on MNIST and ImageNet with no drop in predictive performance.
Privacy for Free: Posterior Sampling and Stochastic Gradient Monte Carlo
Apr 12, 2015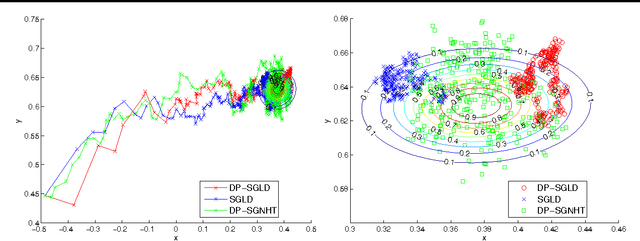
We consider the problem of Bayesian learning on sensitive datasets and present two simple but somewhat surprising results that connect Bayesian learning to "differential privacy:, a cryptographic approach to protect individual-level privacy while permiting database-level utility. Specifically, we show that that under standard assumptions, getting one single sample from a posterior distribution is differentially private "for free". We will see that estimator is statistically consistent, near optimal and computationally tractable whenever the Bayesian model of interest is consistent, optimal and tractable. Similarly but separately, we show that a recent line of works that use stochastic gradient for Hybrid Monte Carlo (HMC) sampling also preserve differentially privacy with minor or no modifications of the algorithmic procedure at all, these observations lead to an "anytime" algorithm for Bayesian learning under privacy constraint. We demonstrate that it performs much better than the state-of-the-art differential private methods on synthetic and real datasets.
The Falling Factorial Basis and Its Statistical Applications
Oct 27, 2014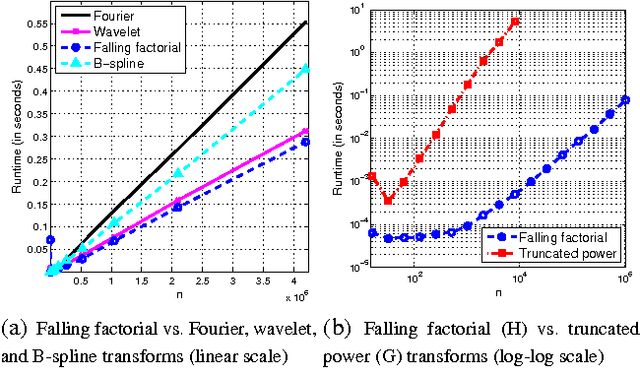
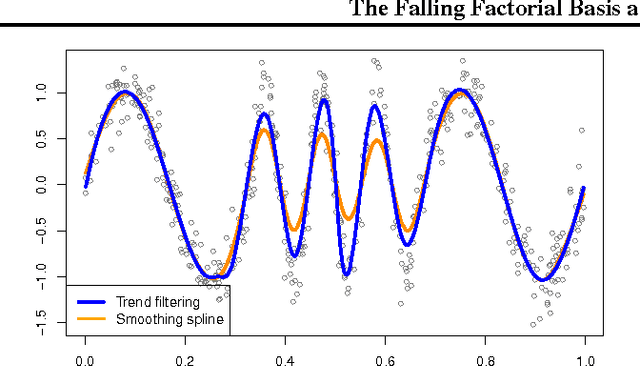
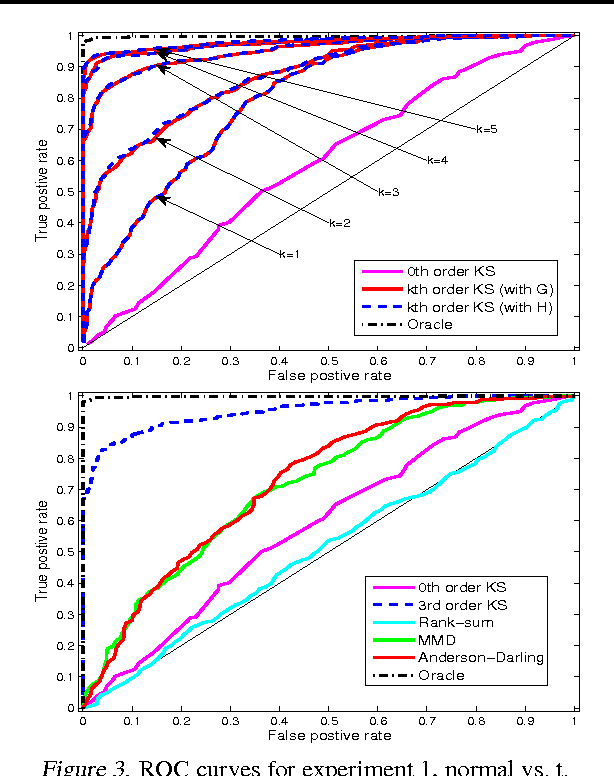
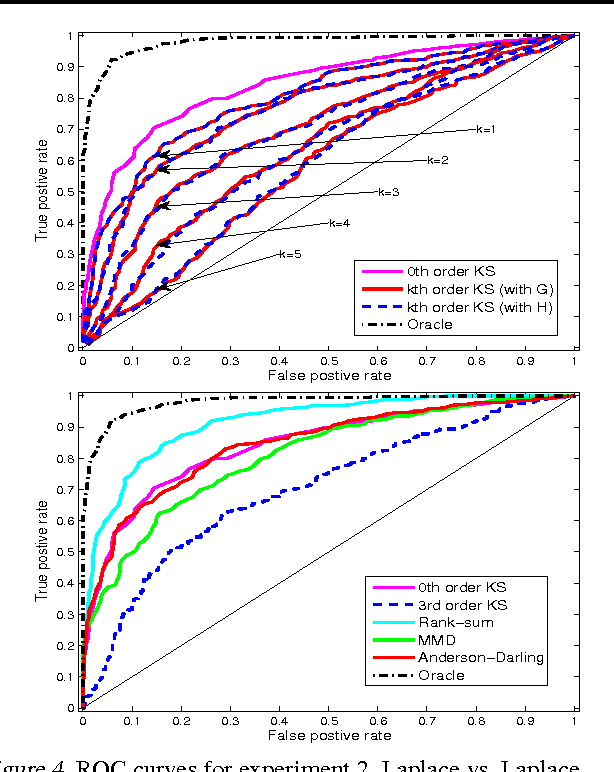
We study a novel spline-like basis, which we name the "falling factorial basis", bearing many similarities to the classic truncated power basis. The advantage of the falling factorial basis is that it enables rapid, linear-time computations in basis matrix multiplication and basis matrix inversion. The falling factorial functions are not actually splines, but are close enough to splines that they provably retain some of the favorable properties of the latter functions. We examine their application in two problems: trend filtering over arbitrary input points, and a higher-order variant of the two-sample Kolmogorov-Smirnov test.
Randomized Nonlinear Component Analysis
May 13, 2014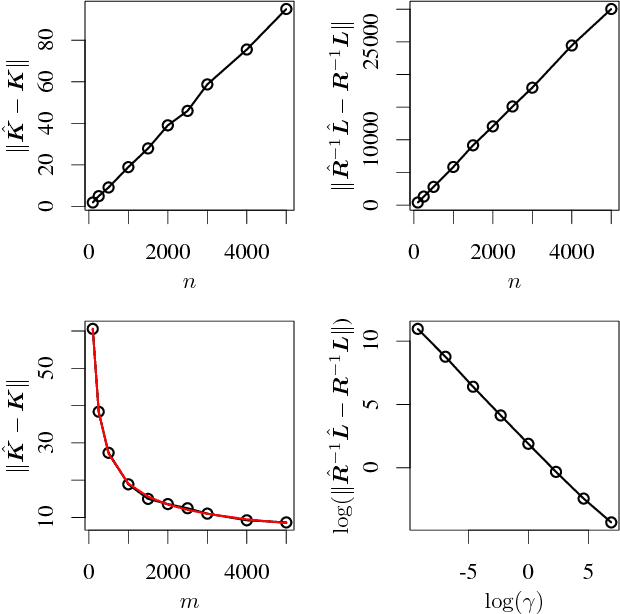
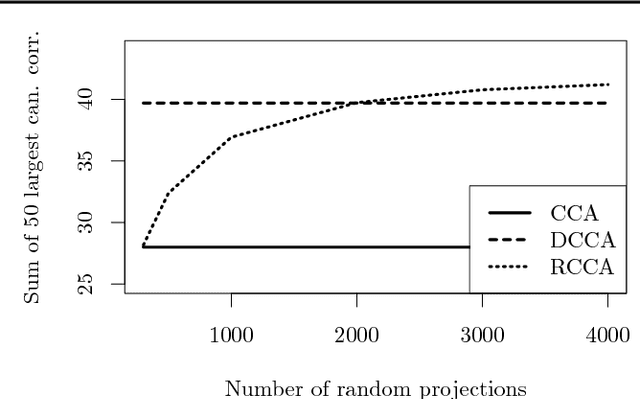
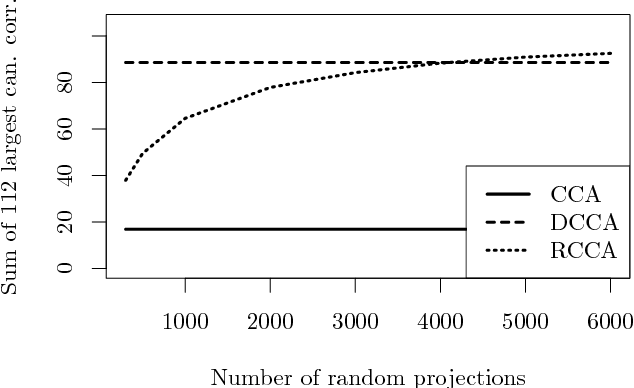
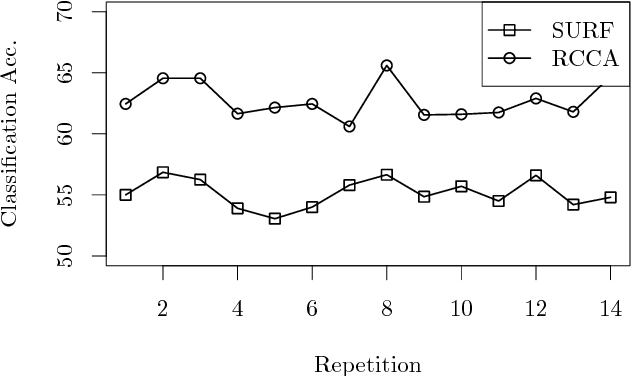
Classical methods such as Principal Component Analysis (PCA) and Canonical Correlation Analysis (CCA) are ubiquitous in statistics. However, these techniques are only able to reveal linear relationships in data. Although nonlinear variants of PCA and CCA have been proposed, these are computationally prohibitive in the large scale. In a separate strand of recent research, randomized methods have been proposed to construct features that help reveal nonlinear patterns in data. For basic tasks such as regression or classification, random features exhibit little or no loss in performance, while achieving drastic savings in computational requirements. In this paper we leverage randomness to design scalable new variants of nonlinear PCA and CCA; our ideas extend to key multivariate analysis tools such as spectral clustering or LDA. We demonstrate our algorithms through experiments on real-world data, on which we compare against the state-of-the-art. A simple R implementation of the presented algorithms is provided.
Exponential Families for Conditional Random Fields
Jul 11, 2012
In this paper we de ne conditional random elds in reproducing kernel Hilbert spaces and show connections to Gaussian Process classi cation. More speci cally, we prove decomposition results for undirected graphical models and we give constructions for kernels. Finally we present e cient means of solving the optimization problem using reduced rank decompositions and we show how stationarity can be exploited e ciently in the optimization process.
Exponential Regret Bounds for Gaussian Process Bandits with Deterministic Observations
Jun 27, 2012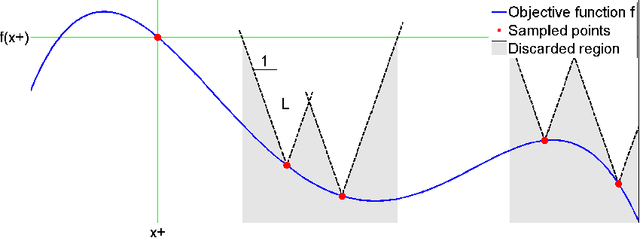
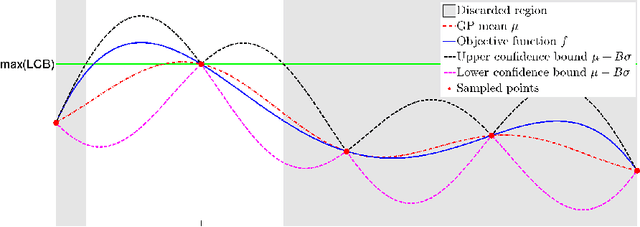
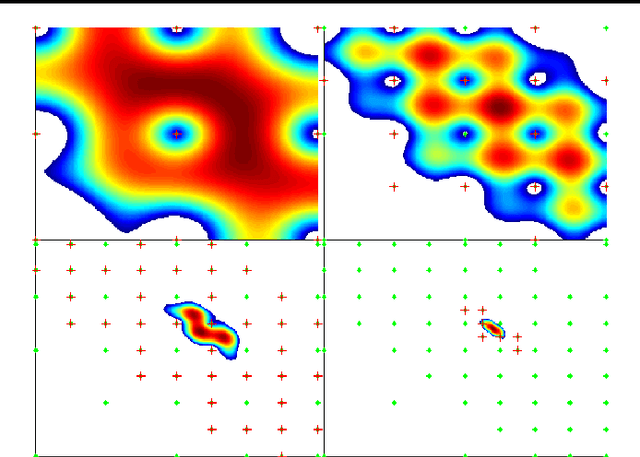
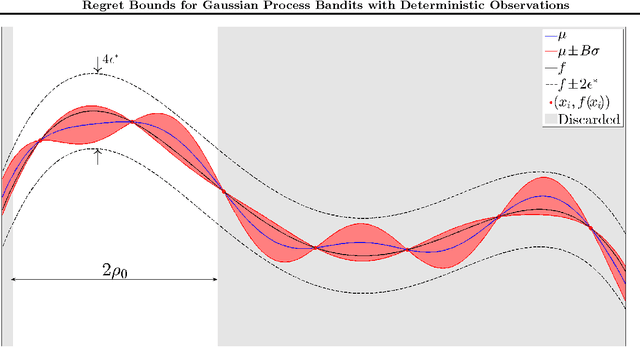
This paper analyzes the problem of Gaussian process (GP) bandits with deterministic observations. The analysis uses a branch and bound algorithm that is related to the UCB algorithm of (Srinivas et al, 2010). For GPs with Gaussian observation noise, with variance strictly greater than zero, Srinivas et al proved that the regret vanishes at the approximate rate of $O(1/\sqrt{t})$, where t is the number of observations. To complement their result, we attack the deterministic case and attain a much faster exponential convergence rate. Under some regularity assumptions, we show that the regret decreases asymptotically according to $O(e^{-\frac{\tau t}{(\ln t)^{d/4}}})$ with high probability. Here, d is the dimension of the search space and tau is a constant that depends on the behaviour of the objective function near its global maximum.
Super-Samples from Kernel Herding
Mar 15, 2012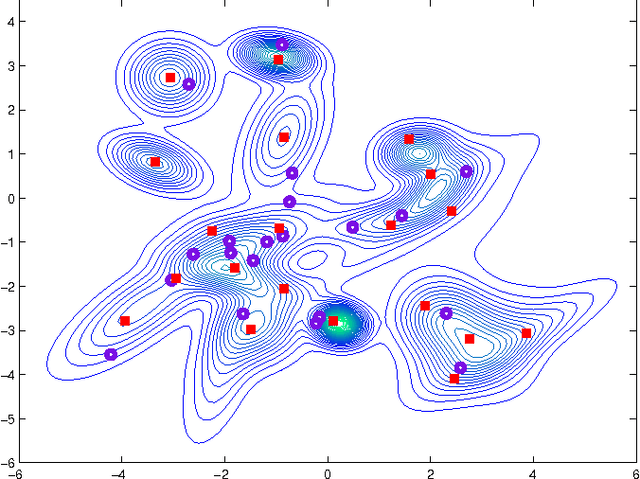
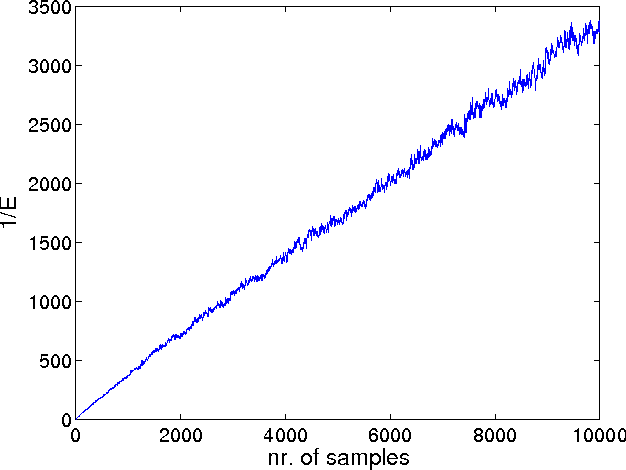
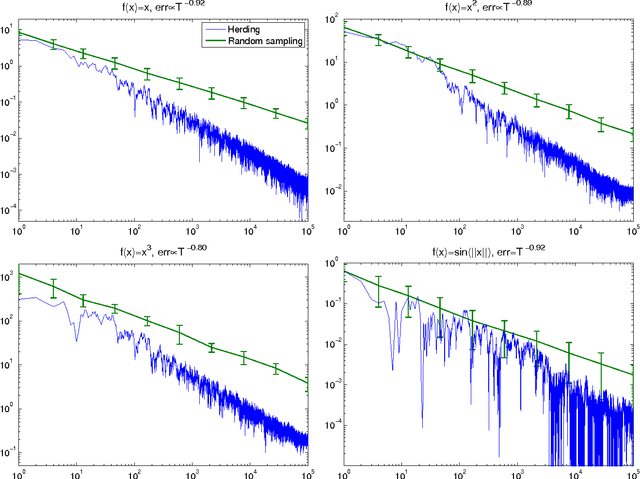
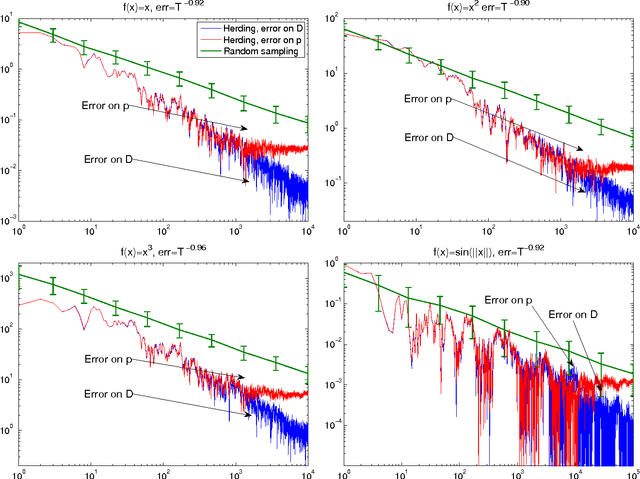
We extend the herding algorithm to continuous spaces by using the kernel trick. The resulting "kernel herding" algorithm is an infinite memory deterministic process that learns to approximate a PDF with a collection of samples. We show that kernel herding decreases the error of expectations of functions in the Hilbert space at a rate O(1/T) which is much faster than the usual O(1/pT) for iid random samples. We illustrate kernel herding by approximating Bayesian predictive distributions.
Regret Bounds for Deterministic Gaussian Process Bandits
Mar 09, 2012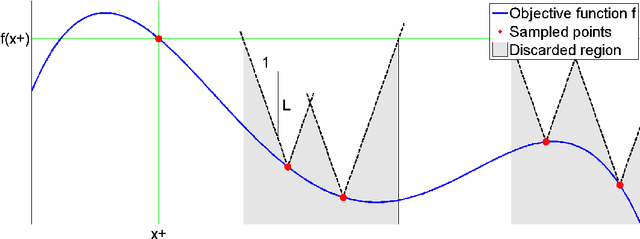
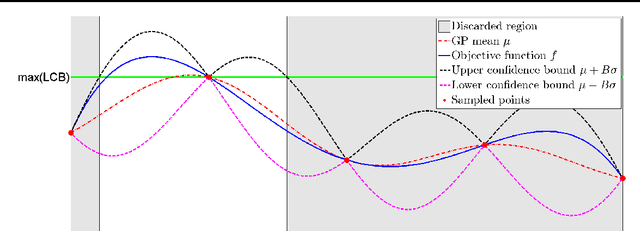
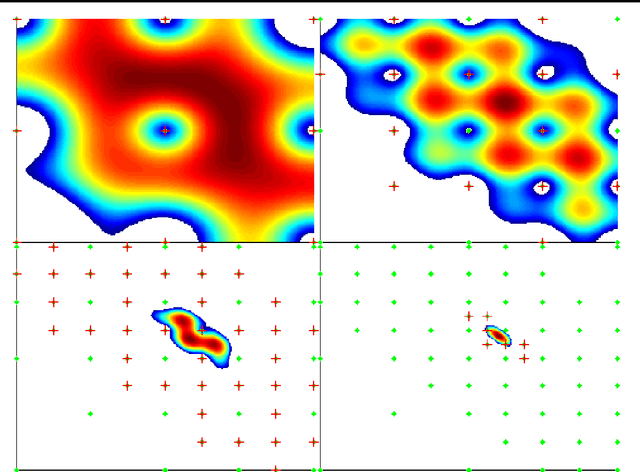
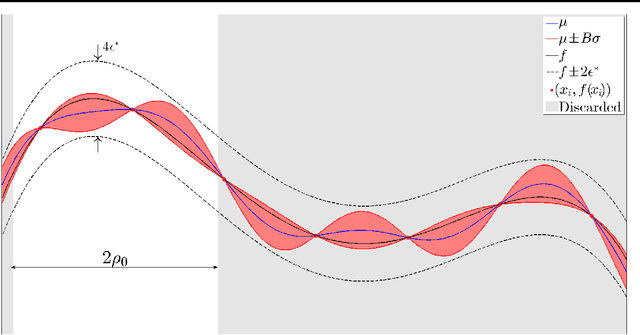
This paper analyses the problem of Gaussian process (GP) bandits with deterministic observations. The analysis uses a branch and bound algorithm that is related to the UCB algorithm of (Srinivas et al., 2010). For GPs with Gaussian observation noise, with variance strictly greater than zero, (Srinivas et al., 2010) proved that the regret vanishes at the approximate rate of $O(\frac{1}{\sqrt{t}})$, where t is the number of observations. To complement their result, we attack the deterministic case and attain a much faster exponential convergence rate. Under some regularity assumptions, we show that the regret decreases asymptotically according to $O(e^{-\frac{\tau t}{(\ln t)^{d/4}}})$ with high probability. Here, d is the dimension of the search space and $\tau$ is a constant that depends on the behaviour of the objective function near its global maximum.
Parallel Online Learning
Mar 22, 2011In this work we study parallelization of online learning, a core primitive in machine learning. In a parallel environment all known approaches for parallel online learning lead to delayed updates, where the model is updated using out-of-date information. In the worst case, or when examples are temporally correlated, delay can have a very adverse effect on the learning algorithm. Here, we analyze and present preliminary empirical results on a set of learning architectures based on a feature sharding approach that present various tradeoffs between delay, degree of parallelism, representation power and empirical performance.
Feature Hashing for Large Scale Multitask Learning
Feb 27, 2010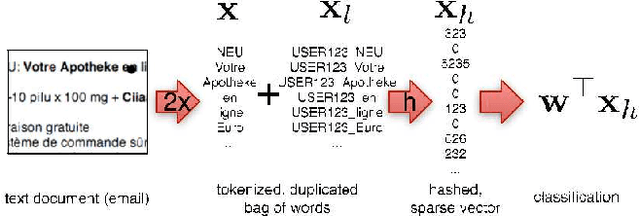
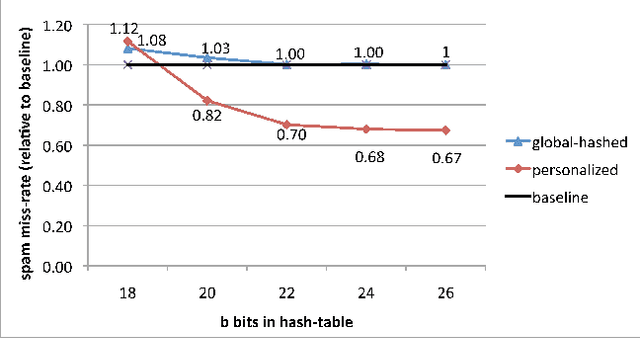
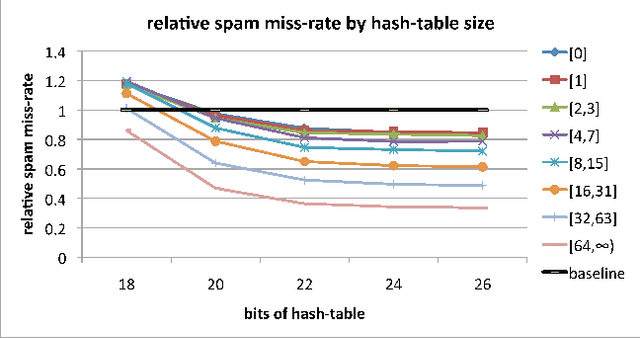
Empirical evidence suggests that hashing is an effective strategy for dimensionality reduction and practical nonparametric estimation. In this paper we provide exponential tail bounds for feature hashing and show that the interaction between random subspaces is negligible with high probability. We demonstrate the feasibility of this approach with experimental results for a new use case -- multitask learning with hundreds of thousands of tasks.