 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrospective Cross-Attention Probing for Lightweight Transfer of Pre-trained Models
Mar 07, 2023



We propose InCA, a lightweight method for transfer learning that cross-attends to any activation layer of a pre-trained model. During training, InCA uses a single forward pass to extract multiple activations, which are passed to external cross-attention adapters, trained anew and combined or selected for downstream tasks. We show that, even when selecting a single top-scoring adapter, InCA achieves performance comparable to full fine-tuning, at a cost comparable to fine-tuning just the last layer. For example, with a cross-attention probe 1.3% the size of a pre-trained ViT-L/16 model, we achieve performance within 0.2% of the full fine-tuning paragon at 51% training cost of the baseline, on average across 11 downstream classification tasks. Unlike other forms of efficient adaptation, InCA does not require backpropagating through the pre-trained model, thus leaving its execution unaltered at both training and inference. The versatility of InCA is best illustrated in fine-grained tasks, which may require accessing information absent in the last layer but accessible in intermediate layer activations. Since the backbone is fixed, InCA allows parallel ensembling as well as parallel execution of multiple tasks. InCA achieves state-of-the-art performance in the ImageNet-to-Sketch multi-task benchmark.
Spacetime-Efficient Low-Depth Quantum State Preparation with Applications
Mar 03, 2023



We propose a novel deterministic method for preparing arbitrary quantum states, and we show that it requires asymptotically fewer quantum resources than previous methods. When our protocol is compiled into CNOT and arbitrary single-qubit gates, it prepares an $N$-dimensional state in depth $O(\log(N))$ and spacetime allocation (a metric that accounts for the fact that oftentimes some ancilla qubits need not be active for the entire protocol) $O(N)$, which are both optimal and not simultaneously achieved by previous methods. When compiled into the $\{\mathrm{H,S,T,CNOT}\}$ gate set, it prepares an arbitrary state up to error $\epsilon$ in depth $O(\log(N/\epsilon))$ and spacetime allocation $O(N\log(\log(N)/\epsilon))$, improving over $O(\log(N)\log(N/\epsilon))$ and $O(N\log(N/\epsilon))$, respectively. We illustrate how the reduced spacetime allocation of our protocol enables rapid preparation of many disjoint states with only constant-factor ancilla overhead -- $O(N)$ ancilla qubits are reused efficiently to prepare a product state of $w$ $N$-dimensional states in depth $O(w + \log(N))$ rather than $O(w\log(N))$, achieving effectively constant depth per state. We highlight several applications where this ability would be useful, including quantum machine learning, Hamiltonian simulation, and solving linear systems of equations. We provide quantum circuit descriptions of our protocol along with detailed pseudocode.
A Meta-Learning Approach to Predicting Performance and Data Requirements
Mar 02, 2023We propose an approach to estimate the number of samples required for a model to reach a target performance. We find that the power law, the de facto principle to estimate model performance, leads to large error when using a small dataset (e.g., 5 samples per class) for extrapolation. This is because the log-performance error against the log-dataset size follows a nonlinear progression in the few-shot regime followed by a linear progression in the high-shot regime. We introduce a novel piecewise power law (PPL) that handles the two data regimes differently. To estimate the parameters of the PPL, we introduce a random forest regressor trained via meta learning that generalizes across classification/detection tasks, ResNet/ViT based architectures, and random/pre-trained initializations. The PPL improves the performance estimation on average by 37% across 16 classification and 33% across 10 detection datasets, compared to the power law. We further extend the PPL to provide a confidence bound and use it to limit the prediction horizon that reduces over-estimation of data by 76% on classification and 91% on detection datasets.
Linear Spaces of Meanings: the Compositional Language of VLMs
Feb 28, 2023We investigate compositional structures in vector data embeddings from pre-trained vision-language models (VLMs). Traditionally, compositionality has been associated with algebraic operations on embeddings of words from a pre-existing vocabulary. In contrast, we seek to approximate label representations from a text encoder as combinations of a smaller set of vectors in the embedding space. These vectors can be seen as "ideal words" which can be used to generate new concepts in an efficient way. We present a theoretical framework for understanding linear compositionality, drawing connections with mathematical representation theory and previous definitions of disentanglement. We provide theoretical and empirical evidence that ideal words provide good compositional approximations of composite concepts and can be more effective than token-based decompositions of the same concepts.
À-la-carte Prompt Tuning : Combining Distinct Data Via Composable Prompting
Feb 15, 2023We introduce \`A-la-carte Prompt Tuning (APT), a transformer-based scheme to tune prompts on distinct data so that they can be arbitrarily composed at inference time. The individual prompts can be trained in isolation, possibly on different devices, at different times, and on different distributions or domains. Furthermore each prompt only contains information about the subset of data it was exposed to during training. During inference, models can be assembled based on arbitrary selections of data sources, which we call "\`a-la-carte learning". \`A-la-carte learning enables constructing bespoke models specific to each user's individual access rights and preferences. We can add or remove information from the model by simply adding or removing the corresponding prompts without retraining from scratch. We demonstrate that \`a-la-carte built models achieve accuracy within $5\%$ of models trained on the union of the respective sources, with comparable cost in terms of training and inference time. For the continual learning benchmarks Split CIFAR-100 and CORe50, we achieve state-of-the-art performance.
Integral Continual Learning Along the Tangent Vector Field of Tasks
Nov 23, 2022We propose a continual learning method which incorporates information from specialized datasets incrementally, by integrating it along the vector field of "generalist" models. The tangent plane to the specialist model acts as a generalist guide and avoids the kind of over-fitting that leads to catastrophic forgetting, while exploiting the convexity of the optimization landscape in the tangent plane. It maintains a small fixed-size memory buffer, as low as 0.4% of the source datasets, which is updated by simple resampling. Our method achieves state-of-the-art across various buffer sizes for different datasets. Specifically, in the class-incremental setting we outperform the existing methods by an average of 26.24% and 28.48%, for Seq-CIFAR-10 and Seq-TinyImageNet respectively. Our method can easily be combined with existing replay-based continual learning methods. When memory buffer constraints are relaxed to allow storage of other metadata such as logits, we attain state-of-the-art accuracy with an error reduction of 36% towards the paragon performance on Seq-CIFAR-10.
Critical Learning Periods for Multisensory Integration in Deep Networks
Oct 06, 2022
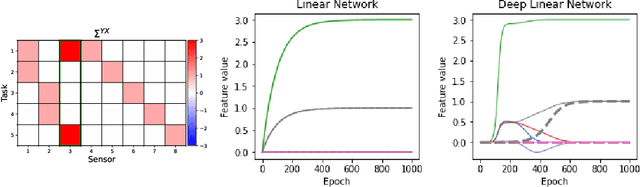
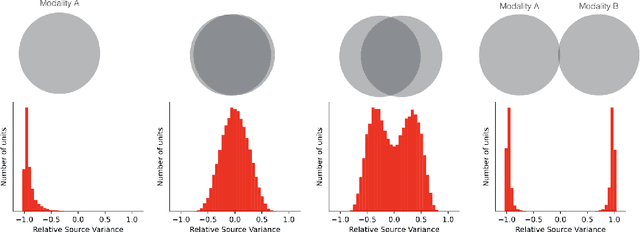
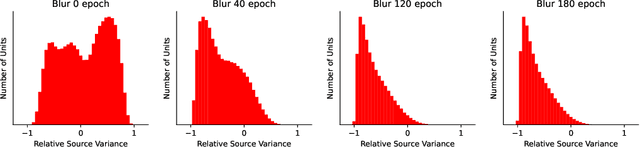
We show that the ability of a neural network to integrate information from diverse sources hinges critically on being exposed to properly correlated signals during the early phases of training. Interfering with the learning process during this initial stage can permanently impair the development of a skill, both in artificial and biological systems where the phenomenon is known as critical learning period. We show that critical periods arise from the complex and unstable early transient dynamics, which are decisive of final performance of the trained system and their learned representations. This evidence challenges the view, engendered by analysis of wide and shallow networks, that early learning dynamics of neural networks are simple, akin to those of a linear model. Indeed, we show that even deep linear networks exhibit critical learning periods for multi-source integration, while shallow networks do not. To better understand how the internal representations change according to disturbances or sensory deficits, we introduce a new measure of source sensitivity, which allows us to track the inhibition and integration of sources during training. Our analysis of inhibition suggests cross-source reconstruction as a natural auxiliary training objective, and indeed we show that architectures trained with cross-sensor reconstruction objectives are remarkably more resilient to critical periods. Our findings suggest that the recent success in self-supervised multi-modal training compared to previous supervised efforts may be in part due to more robust learning dynamics and not solely due to better architectures and/or more data.
On the Learnability of Physical Concepts: Can a Neural Network Understand What's Real?
Aug 04, 2022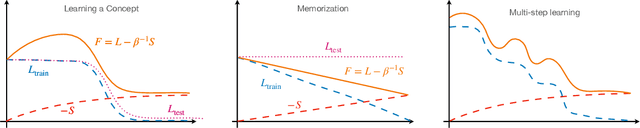
We revisit the classic signal-to-symbol barrier in light of the remarkable ability of deep neural networks to generate realistic synthetic data. DeepFakes and spoofing highlight the feebleness of the link between physical reality and its abstract representation, whether learned by a digital computer or a biological agent. Starting from a widely applicable definition of abstract concept, we show that standard feed-forward architectures cannot capture but trivial concepts, regardless of the number of weights and the amount of training data, despite being extremely effective classifiers. On the other hand, architectures that incorporate recursion can represent a significantly larger class of concepts, but may still be unable to learn them from a finite dataset. We qualitatively describe the class of concepts that can be "understood" by modern architectures trained with variants of stochastic gradient descent, using a (free energy) Lagrangian to measure information complexity. Even if a concept has been understood, however, a network has no means of communicating its understanding to an external agent, except through continuous interaction and validation. We then characterize physical objects as abstract concepts and use the previous analysis to show that physical objects can be encoded by finite architectures. However, to understand physical concepts, sensors must provide persistently exciting observations, for which the ability to control the data acquisition process is essential (active perception). The importance of control depends on the modality, benefiting visual more than acoustic or chemical perception. Finally, we conclude that binding physical entities to digital identities is possible in finite time with finite resources, solving in principle the signal-to-symbol barrier problem, but we highlight the need for continuous validation.
On Leave-One-Out Conditional Mutual Information For Generalization
Jul 01, 2022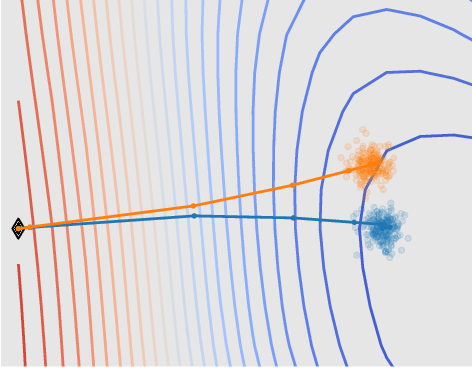

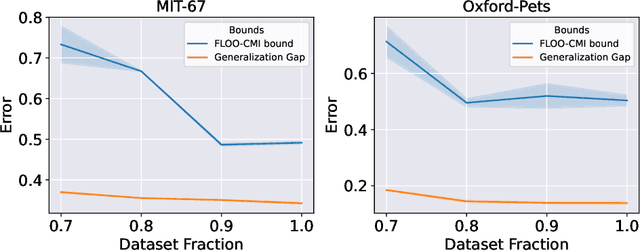
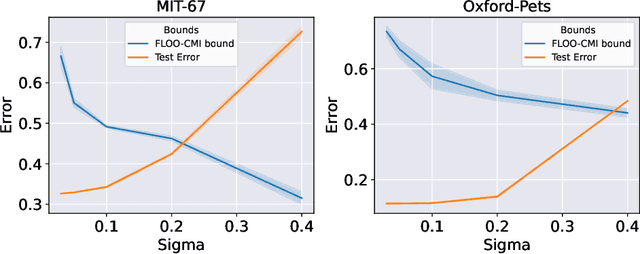
We derive information theoretic generalization bounds for supervised learning algorithms based on a new measure of leave-one-out conditional mutual information (loo-CMI). Contrary to other CMI bounds, which are black-box bounds that do not exploit the structure of the problem and may be hard to evaluate in practice, our loo-CMI bounds can be computed easily and can be interpreted in connection to other notions such as classical leave-one-out cross-validation, stability of the optimization algorithm, and the geometry of the loss-landscape. It applies both to the output of training algorithms as well as their predictions. We empirically validate the quality of the bound by evaluating its predicted generalization gap in scenarios for deep learning. In particular, our bounds are non-vacuous on large-scale image-classification tasks.
Gacs-Korner Common Information Variational Autoencoder
May 24, 2022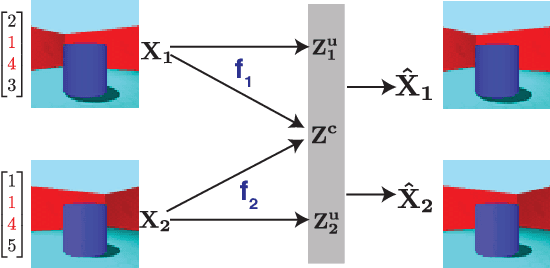

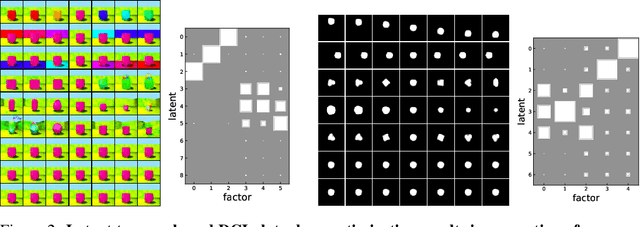

We propose a notion of common information that allows one to quantify and separate the information that is shared between two random variables from the information that is unique to each. Our notion of common information is a variational relaxation of the G\'acs-K\"orner common information, which we recover as a special case, but is more amenable to optimization and can be approximated empirically using samples from the underlying distribution. We then provide a method to partition and quantify the common and unique information using a simple modification of a traditional variational auto-encoder. Empirically, we demonstrate that our formulation allows us to learn semantically meaningful common and unique factors of variation even on high-dimensional data such as images and videos. Moreover, on datasets where ground-truth latent factors are known, we show that we can accurately quantify the common information between the random variables. Additionally, we show that the auto-encoder that we learn recovers semantically meaningful disentangled factors of variation, even though we do not explicitly optimize for it.