 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Accurate Geometry Data for Dense 3D Vision Tasks
Mar 26, 2023



Learning-based methods to solve dense 3D vision problems typically train on 3D sensor data. The respectively used principle of measuring distances provides advantages and drawbacks. These are typically not compared nor discussed in the literature due to a lack of multi-modal datasets. Texture-less regions are problematic for structure from motion and stereo, reflective material poses issues for active sensing, and distances for translucent objects are intricate to measure with existing hardware. Training on inaccurate or corrupt data induces model bias and hampers generalisation capabilities. These effects remain unnoticed if the sensor measurement is considered as ground truth during the evaluation. This paper investigates the effect of sensor errors for the dense 3D vision tasks of depth estimation and reconstruction. We rigorously show the significant impact of sensor characteristics on the learned predictions and notice generalisation issues arising from various technologies in everyday household environments. For evaluation, we introduce a carefully designed dataset\footnote{dataset available at https://github.com/Junggy/HAMMER-dataset} comprising measurements from commodity sensors, namely D-ToF, I-ToF, passive/active stereo, and monocular RGB+P. Our study quantifies the considerable sensor noise impact and paves the way to improved dense vision estimates and targeted data fusion.
Category-Level 6D Object Pose Estimation with Flexible Vector-Based Rotation Representation
Dec 09, 2022



In this paper, we propose a novel 3D graph convolution based pipeline for category-level 6D pose and size estimation from monocular RGB-D images. The proposed method leverages an efficient 3D data augmentation and a novel vector-based decoupled rotation representation. Specifically, we first design an orientation-aware autoencoder with 3D graph convolution for latent feature learning. The learned latent feature is insensitive to point shift and size thanks to the shift and scale-invariance properties of the 3D graph convolution. Then, to efficiently decode the rotation information from the latent feature, we design a novel flexible vector-based decomposable rotation representation that employs two decoders to complementarily access the rotation information. The proposed rotation representation has two major advantages: 1) decoupled characteristic that makes the rotation estimation easier; 2) flexible length and rotated angle of the vectors allow us to find a more suitable vector representation for specific pose estimation task. Finally, we propose a 3D deformation mechanism to increase the generalization ability of the pipeline. Extensive experiments show that the proposed pipeline achieves state-of-the-art performance on category-level tasks. Further, the experiments demonstrate that the proposed rotation representation is more suitable for the pose estimation tasks than other rotation representations.
Region Proposal Network Pre-Training Helps Label-Efficient Object Detection
Nov 16, 2022Self-supervised pre-training, based on the pretext task of instance discrimination, has fueled the recent advance in label-efficient object detection. However, existing studies focus on pre-training only a feature extractor network to learn transferable representations for downstream detection tasks. This leads to the necessity of training multiple detection-specific modules from scratch in the fine-tuning phase. We argue that the region proposal network (RPN), a common detection-specific module, can additionally be pre-trained towards reducing the localization error of multi-stage detectors. In this work, we propose a simple pretext task that provides an effective pre-training for the RPN, towards efficiently improving downstream object detection performance. We evaluate the efficacy of our approach on benchmark object detection tasks and additional downstream tasks, including instance segmentation and few-shot detection. In comparison with multi-stage detectors without RPN pre-training, our approach is able to consistently improve downstream task performance, with largest gains found in label-scarce settings.
Content-Diverse Comparisons improve IQA
Nov 09, 2022



Image quality assessment (IQA) forms a natural and often straightforward undertaking for humans, yet effective automation of the task remains highly challenging. Recent metrics from the deep learning community commonly compare image pairs during training to improve upon traditional metrics such as PSNR or SSIM. However, current comparisons ignore the fact that image content affects quality assessment as comparisons only occur between images of similar content. This restricts the diversity and number of image pairs that the model is exposed to during training. In this paper, we strive to enrich these comparisons with content diversity. Firstly, we relax comparison constraints, and compare pairs of images with differing content. This increases the variety of available comparisons. Secondly, we introduce listwise comparisons to provide a holistic view to the model. By including differentiable regularizers, derived from correlation coefficients, models can better adjust predicted scores relative to one another. Evaluation on multiple benchmarks, covering a wide range of distortions and image content, shows the effectiveness of our learning scheme for training image quality assessment models.
Disentangling 3D Attributes from a Single 2D Image: Human Pose, Shape and Garment
Aug 05, 2022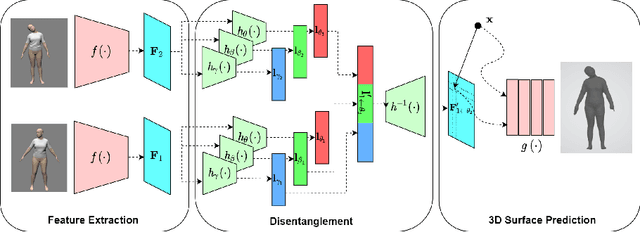

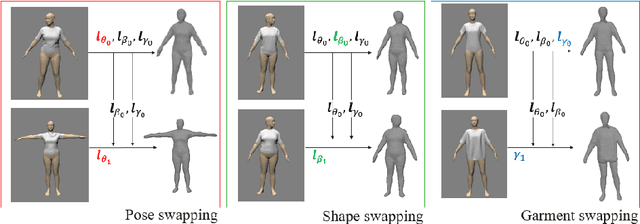
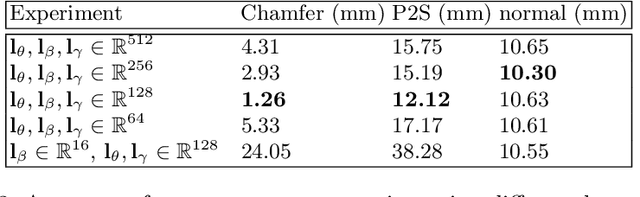
For visual manipulation tasks, we aim to represent image content with semantically meaningful features. However, learning implicit representations from images often lacks interpretability, especially when attributes are intertwined. We focus on the challenging task of extracting disentangled 3D attributes only from 2D image data. Specifically, we focus on human appearance and learn implicit pose, shape and garment representations of dressed humans from RGB images. Our method learns an embedding with disentangled latent representations of these three image properties and enables meaningful re-assembling of features and property control through a 2D-to-3D encoder-decoder structure. The 3D model is inferred solely from the feature map in the learned embedding space. To the best of our knowledge, our method is the first to achieve cross-domain disentanglement for this highly under-constrained problem. We qualitatively and quantitatively demonstrate our framework's ability to transfer pose, shape, and garments in 3D reconstruction on virtual data and show how an implicit shape loss can benefit the model's ability to recover fine-grained reconstruction details.
S$^2$Contact: Graph-based Network for 3D Hand-Object Contact Estimation with Semi-Supervised Learning
Aug 01, 2022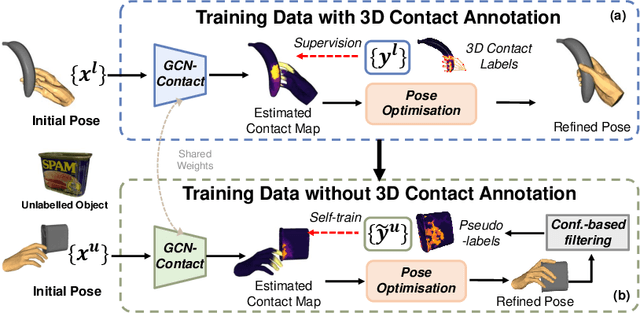
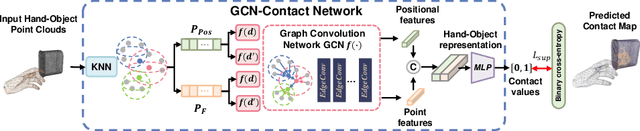
Despite the recent efforts in accurate 3D annotations in hand and object datasets, there still exist gaps in 3D hand and object reconstructions. Existing works leverage contact maps to refine inaccurate hand-object pose estimations and generate grasps given object models. However, they require explicit 3D supervision which is seldom available and therefore, are limited to constrained settings, e.g., where thermal cameras observe residual heat left on manipulated objects. In this paper, we propose a novel semi-supervised framework that allows us to learn contact from monocular images. Specifically, we leverage visual and geometric consistency constraints in large-scale datasets for generating pseudo-labels in semi-supervised learning and propose an efficient graph-based network to infer contact. Our semi-supervised learning framework achieves a favourable improvement over the existing supervised learning methods trained on data with `limited' annotations. Notably, our proposed model is able to achieve superior results with less than half the network parameters and memory access cost when compared with the commonly-used PointNet-based approach. We show benefits from using a contact map that rules hand-object interactions to produce more accurate reconstructions. We further demonstrate that training with pseudo-labels can extend contact map estimations to out-of-domain objects and generalise better across multiple datasets.
Is my Depth Ground-Truth Good Enough? HAMMER -- Highly Accurate Multi-Modal Dataset for DEnse 3D Scene Regression
May 09, 2022


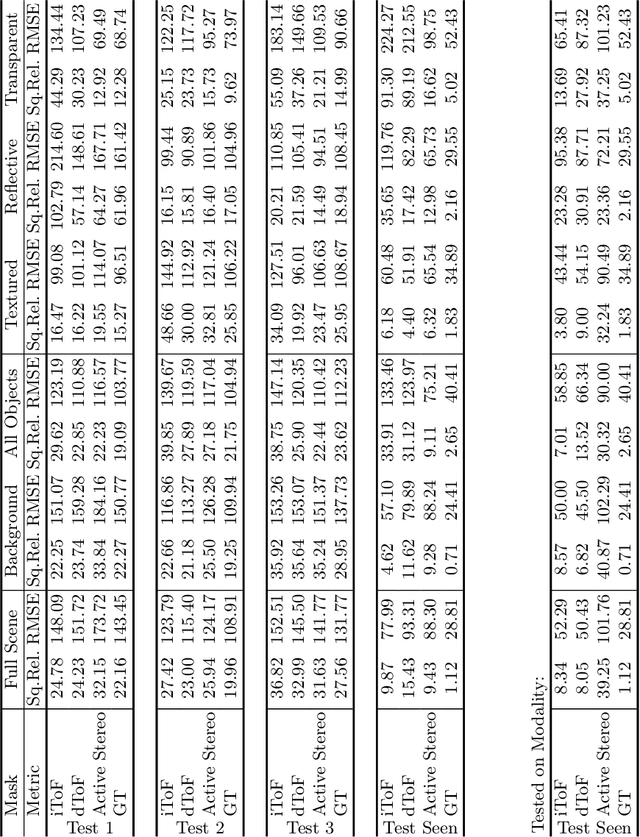
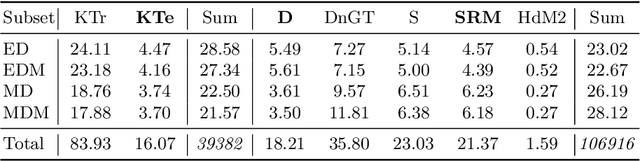
Depth estimation is a core task in 3D computer vision. Recent methods investigate the task of monocular depth trained with various depth sensor modalities. Every sensor has its advantages and drawbacks caused by the nature of estimates. In the literature, mostly mean average error of the depth is investigated and sensor capabilities are typically not discussed. Especially indoor environments, however, pose challenges for some devices. Textureless regions pose challenges for structure from motion, reflective materials are problematic for active sensing, and distances for translucent material are intricate to measure with existing sensors. This paper proposes HAMMER, a dataset comprising depth estimates from multiple commonly used sensors for indoor depth estimation, namely ToF, stereo, structured light together with monocular RGB+P data. We construct highly reliable ground truth depth maps with the help of 3D scanners and aligned renderings. A popular depth estimators is trained on this data and typical depth senosors. The estimates are extensively analyze on different scene structures. We notice generalization issues arising from various sensor technologies in household environments with challenging but everyday scene content. HAMMER, which we make publicly available, provides a reliable base to pave the way to targeted depth improvements and sensor fusion approaches.
Collaborative Learning for Hand and Object Reconstruction with Attention-guided Graph Convolution
Apr 27, 2022
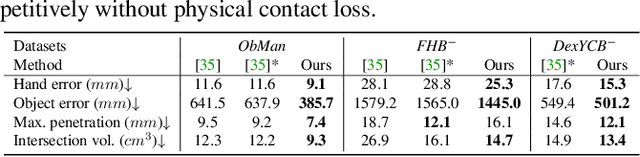
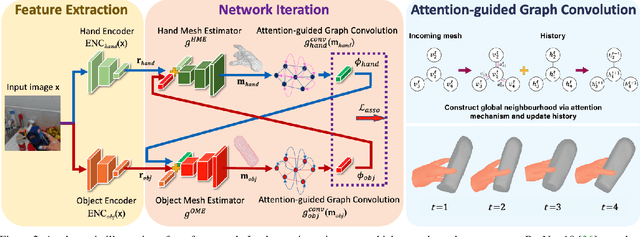
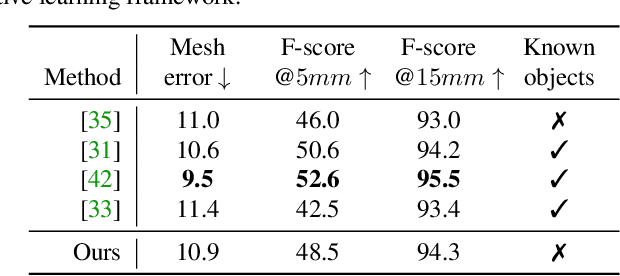
Estimating the pose and shape of hands and objects under interaction finds numerous applications including augmented and virtual reality. Existing approaches for hand and object reconstruction require explicitly defined physical constraints and known objects, which limits its application domains. Our algorithm is agnostic to object models, and it learns the physical rules governing hand-object interaction. This requires automatically inferring the shapes and physical interaction of hands and (potentially unknown) objects. We seek to approach this challenging problem by proposing a collaborative learning strategy where two-branches of deep networks are learning from each other. Specifically, we transfer hand mesh information to the object branch and vice versa for the hand branch. The resulting optimisation (training) problem can be unstable, and we address this via two strategies: (i) attention-guided graph convolution which helps identify and focus on mutual occlusion and (ii) unsupervised associative loss which facilitates the transfer of information between the branches. Experiments using four widely-used benchmarks show that our framework achieves beyond state-of-the-art accuracy in 3D pose estimation, as well as recovers dense 3D hand and object shapes. Each technical component above contributes meaningfully in the ablation study.
HDR Reconstruction from Bracketed Exposures and Events
Mar 28, 2022
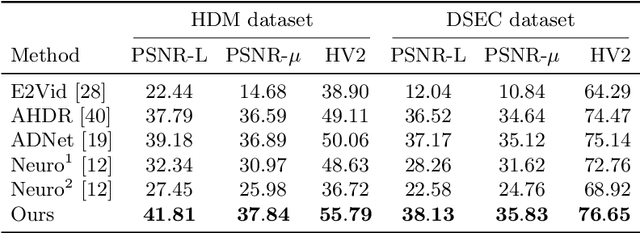
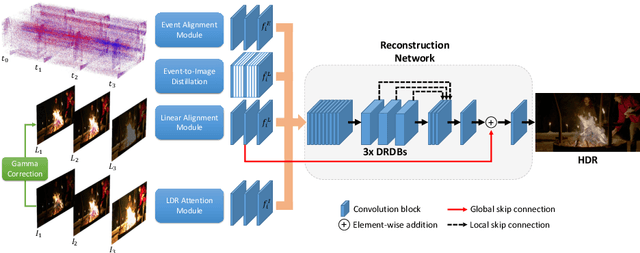
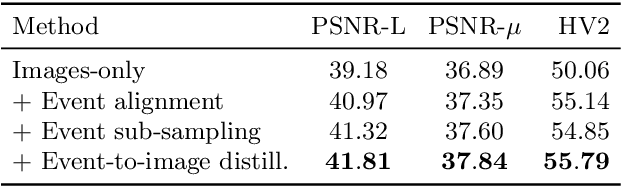
Reconstruction of high-quality HDR images is at the core of modern computational photography. Significant progress has been made with multi-frame HDR reconstruction methods, producing high-resolution, rich and accurate color reconstructions with high-frequency details. However, they are still prone to fail in dynamic or largely over-exposed scenes, where frame misalignment often results in visible ghosting artifacts. Recent approaches attempt to alleviate this by utilizing an event-based camera (EBC), which measures only binary changes of illuminations. Despite their desirable high temporal resolution and dynamic range characteristics, such approaches have not outperformed traditional multi-frame reconstruction methods, mainly due to the lack of color information and low-resolution sensors. In this paper, we propose to leverage both bracketed LDR images and simultaneously captured events to obtain the best of both worlds: high-quality RGB information from bracketed LDRs and complementary high frequency and dynamic range information from events. We present a multi-modal end-to-end learning-based HDR imaging system that fuses bracketed images and event modalities in the feature domain using attention and multi-scale spatial alignment modules. We propose a novel event-to-image feature distillation module that learns to translate event features into the image-feature space with self-supervision. Our framework exploits the higher temporal resolution of events by sub-sampling the input event streams using a sliding window, enriching our combined feature representation. Our proposed approach surpasses SoTA multi-frame HDR reconstruction methods using synthetic and real events, with a 2dB and 1dB improvement in PSNR-L and PSNR-mu on the HdM HDR dataset, respectively.
Self-supervised HDR Imaging from Motion and Exposure Cues
Mar 23, 2022
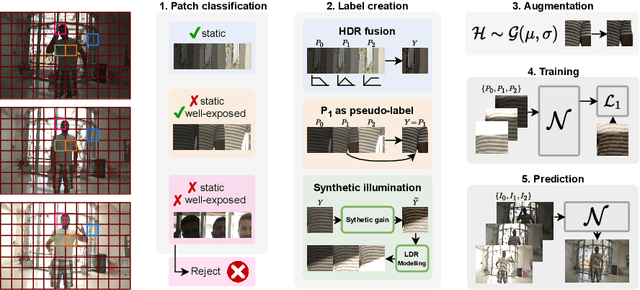
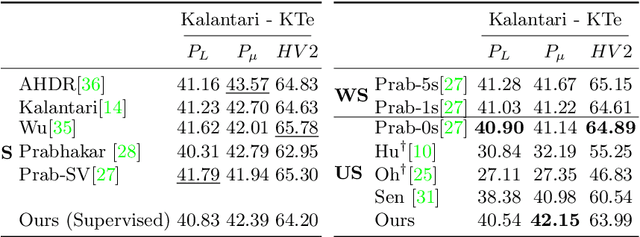
Recent High Dynamic Range (HDR) techniques extend the capabilities of current cameras where scenes with a wide range of illumination can not be accurately captured with a single low-dynamic-range (LDR) image. This is generally accomplished by capturing several LDR images with varying exposure values whose information is then incorporated into a merged HDR image. While such approaches work well for static scenes, dynamic scenes pose several challenges, mostly related to the difficulty of finding reliable pixel correspondences. Data-driven approaches tackle the problem by learning an end-to-end mapping with paired LDR-HDR training data, but in practice generating such HDR ground-truth labels for dynamic scenes is time-consuming and requires complex procedures that assume control of certain dynamic elements of the scene (e.g. actor pose) and repeatable lighting conditions (stop-motion capturing). In this work, we propose a novel self-supervised approach for learnable HDR estimation that alleviates the need for HDR ground-truth labels. We propose to leverage the internal statistics of LDR images to create HDR pseudo-labels. We separately exploit static and well-exposed parts of the input images, which in conjunction with synthetic illumination clipping and motion augmentation provide high quality training examples. Experimental results show that the HDR models trained using our proposed self-supervision approach achieve performance competitive with those trained under full supervision, and are to a large extent superior to previous methods that equally do not require any supervision.