 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Contextual Bandits with Knapsacks via Regression
Nov 14, 2022We consider contextual bandits with knapsacks (CBwK), a variant of the contextual bandit which places global constraints on budget consumption. We present a new algorithm that is simple, statistically optimal, and computationally efficient. Our algorithm combines LagrangeBwK (Immorlica et al., FOCS'19), a Lagrangian-based technique for CBwK, and SquareCB (Foster and Rakhlin, ICML'20), a regression-based technique for contextual bandits. Our analysis emphasizes the modularity of both techniques.
Incentivizing Combinatorial Bandit Exploration
Jun 01, 2022Consider a bandit algorithm that recommends actions to self-interested users in a recommendation system. The users are free to choose other actions and need to be incentivized to follow the algorithm's recommendations. While the users prefer to exploit, the algorithm can incentivize them to explore by leveraging the information collected from the previous users. All published work on this problem, known as incentivized exploration, focuses on small, unstructured action sets and mainly targets the case when the users' beliefs are independent across actions. However, realistic exploration problems often feature large, structured action sets and highly correlated beliefs. We focus on a paradigmatic exploration problem with structure: combinatorial semi-bandits. We prove that Thompson Sampling, when applied to combinatorial semi-bandits, is incentive-compatible when initialized with a sufficient number of samples of each arm (where this number is determined in advance by the Bayesian prior). Moreover, we design incentive-compatible algorithms for collecting the initial samples.
Sayer: Using Implicit Feedback to Optimize System Policies
Oct 28, 2021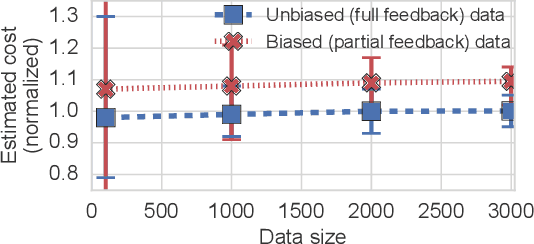
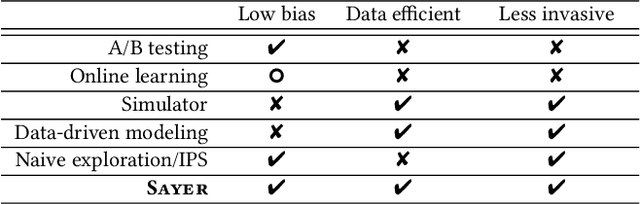
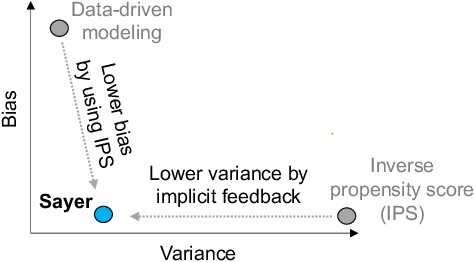
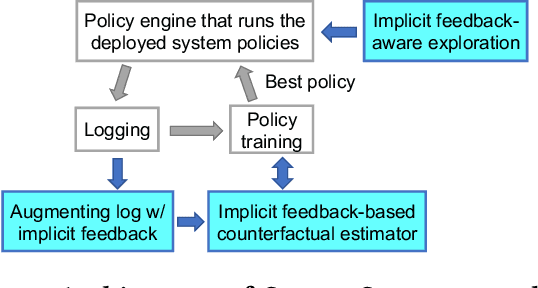
We observe that many system policies that make threshold decisions involving a resource (e.g., time, memory, cores) naturally reveal additional, or implicit feedback. For example, if a system waits X min for an event to occur, then it automatically learns what would have happened if it waited <X min, because time has a cumulative property. This feedback tells us about alternative decisions, and can be used to improve the system policy. However, leveraging implicit feedback is difficult because it tends to be one-sided or incomplete, and may depend on the outcome of the event. As a result, existing practices for using feedback, such as simply incorporating it into a data-driven model, suffer from bias. We develop a methodology, called Sayer, that leverages implicit feedback to evaluate and train new system policies. Sayer builds on two ideas from reinforcement learning -- randomized exploration and unbiased counterfactual estimators -- to leverage data collected by an existing policy to estimate the performance of new candidate policies, without actually deploying those policies. Sayer uses implicit exploration and implicit data augmentation to generate implicit feedback in an unbiased form, which is then used by an implicit counterfactual estimator to evaluate and train new policies. The key idea underlying these techniques is to assign implicit probabilities to decisions that are not actually taken but whose feedback can be inferred; these probabilities are carefully calculated to ensure statistical unbiasedness. We apply Sayer to two production scenarios in Azure, and show that it can evaluate arbitrary policies accurately, and train new policies that outperform the production policies.
Exploration and Incentives in Reinforcement Learning
Feb 28, 2021How do you incentivize self-interested agents to $\textit{explore}$ when they prefer to $\textit{exploit}$ ? We consider complex exploration problems, where each agent faces the same (but unknown) MDP. In contrast with traditional formulations of reinforcement learning, agents control the choice of policies, whereas an algorithm can only issue recommendations. However, the algorithm controls the flow of information, and can incentivize the agents to explore via information asymmetry. We design an algorithm which explores all reachable states in the MDP. We achieve provable guarantees similar to those for incentivizing exploration in static, stateless exploration problems studied previously.
Competing Bandits: The Perils of Exploration Under Competition
Jul 20, 2020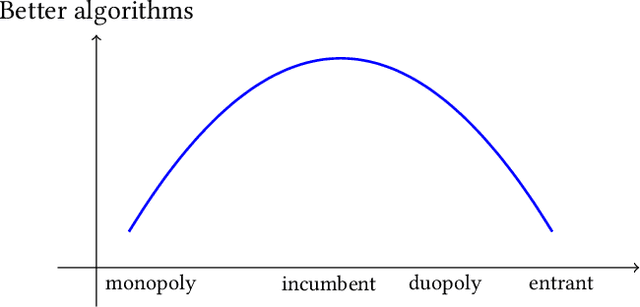
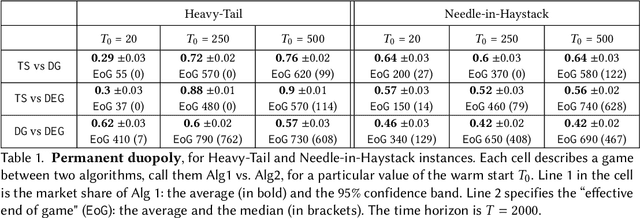
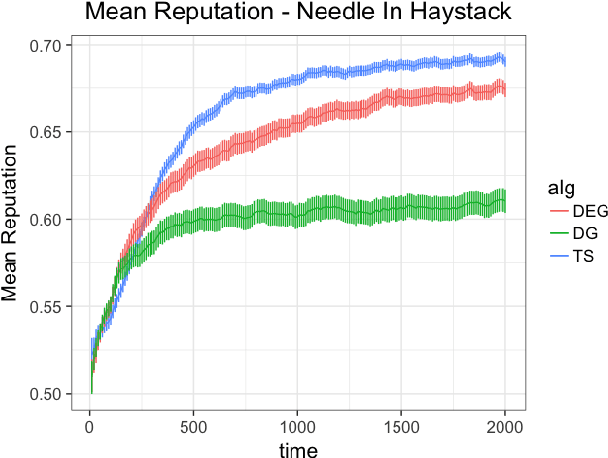
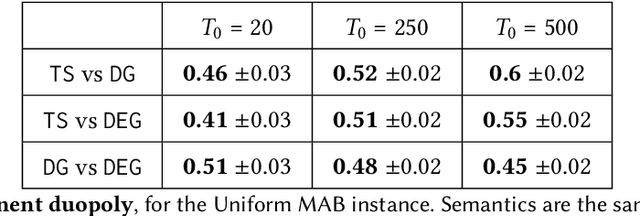
Most online platforms strive to learn from interactions with consumers, and many engage in exploration: making potentially suboptimal choices for the sake of acquiring new information. We initiate a study of the interplay between exploration and competition: how such platforms balance the exploration for learning and the competition for consumers. Here consumers play three distinct roles: they are customers that generate revenue, they are sources of data for learning, and they are self-interested agents which choose among the competing platforms. We consider a stylized duopoly model in which two firms face the same multi-armed bandit instance. Users arrive one by one and choose between the two firms, so that each firm makes progress on its bandit instance only if it is chosen. We study whether and to what extent competition incentivizes the adoption of better bandit algorithms, and whether it leads to welfare increases for consumers. We find that stark competition induces firms to commit to a "greedy" bandit algorithm that leads to low consumer welfare. However, we find that weakening competition by providing firms with some "free" consumers incentivizes better exploration strategies and increases consumer welfare. We investigate two channels for weakening the competition: relaxing the rationality of consumers and giving one firm a first-mover advantage. We provide a mix of theoretical results and numerical simulations. Our findings are closely related to the "competition vs. innovation" relationship, a well-studied theme in economics. They also elucidate the first-mover advantage in the digital economy by exploring the role that data can play as a barrier to entry in online markets.
Adaptive Discretization for Adversarial Bandits with Continuous Action Spaces
Jun 22, 2020Lipschitz bandits is a prominent version of multi-armed bandits that studies large, structured action spaces such as the [0,1] interval, where similar actions are guaranteed to have similar rewards. A central theme here is the adaptive discretization of the action space, which gradually "zooms in" on the more promising regions thereof. The goal is to take advantage of "nicer" problem instances, while retaining near-optimal worst-case performance. While the stochastic version of the problem is well-understood, the general version with adversarially chosen rewards is not. We provide the first algorithm for adaptive discretization in the adversarial version, and derive instance-dependent regret bounds. In particular, we recover the worst-case optimal regret bound for the adversarial version, and the instance-dependent regret bound for the stochastic version. Further, an application of our algorithm to dynamic pricing (a version in which the algorithm repeatedly adjusts prices for a product) enjoys these regret bounds without any smoothness assumptions.
Efficient Contextual Bandits with Continuous Actions
Jun 10, 2020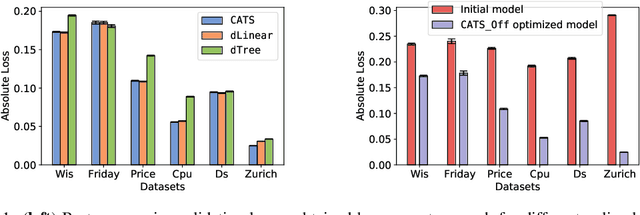
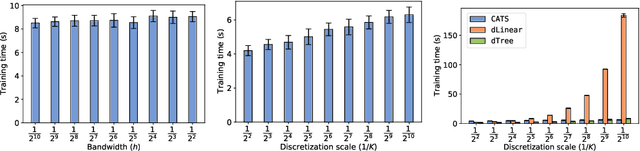
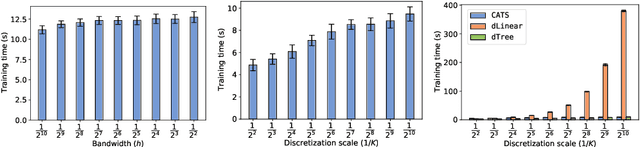
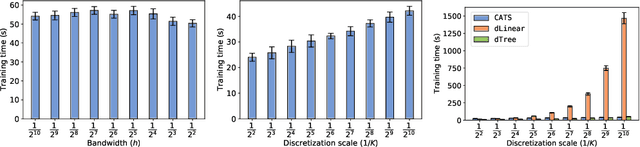
We create a computationally tractable algorithm for contextual bandits with continuous actions having unknown structure. Our reduction-style algorithm composes with most supervised learning representations. We prove that it works in a general sense and verify the new functionality with large-scale experiments.
Constrained episodic reinforcement learning in concave-convex and knapsack settings
Jun 09, 2020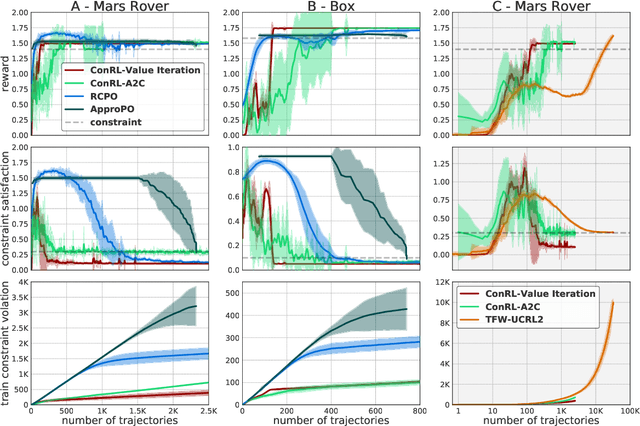

We propose an algorithm for tabular episodic reinforcement learning with constraints. We provide a modular analysis with strong theoretical guarantees for settings with concave rewards and convex constraints, and for settings with hard constraints (knapsacks). Most of the previous work in constrained reinforcement learning is limited to linear constraints, and the remaining work focuses on either the feasibility question or settings with a single episode. Our experiments demonstrate that the proposed algorithm significantly outperforms these approaches in existing constrained episodic environments.
Greedy Algorithm almost Dominates in Smoothed Contextual Bandits
May 19, 2020Online learning algorithms, widely used to power search and content optimization on the web, must balance exploration and exploitation, potentially sacrificing the experience of current users in order to gain information that will lead to better decisions in the future. While necessary in the worst case, explicit exploration has a number of disadvantages compared to the greedy algorithm that always "exploits" by choosing an action that currently looks optimal. We ask under what conditions inherent diversity in the data makes explicit exploration unnecessary. We build on a recent line of work on the smoothed analysis of the greedy algorithm in the linear contextual bandits model. We improve on prior results to show that a greedy approach almost matches the best possible Bayesian regret rate of any other algorithm on the same problem instance whenever the diversity conditions hold, and that this regret is at most $\tilde O(T^{1/3})$.
Sample Complexity of Incentivized Exploration
Feb 03, 2020We consider incentivized exploration: a version of multi-armed bandits where the choice of actions is controlled by self-interested agents, and the algorithm can only issue recommendations. The algorithm controls the flow of information, and the information asymmetry can incentivize the agents to explore. Prior work matches the optimal regret rates for bandits up to "constant" multiplicative factors determined by the Bayesian prior. However, the dependence on the prior in prior work could be arbitrarily large, and the dependence on the number of arms K could be exponential. The optimal dependence on the prior and K is very unclear. We make progress on these issues. Our first result is that Thompson sampling is incentive-compatible if initialized with enough data points. Thus, we reduce the problem of designing incentive-compatible algorithms to that of sample complexity: (i) How many data points are needed to incentivize Thompson sampling? (ii) How many rounds does it take to collect these samples? We address both questions, providing upper bounds on sample complexity that are typically polynomial in K and lower bounds that are polynomially matching.