 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds
Jun 09, 2019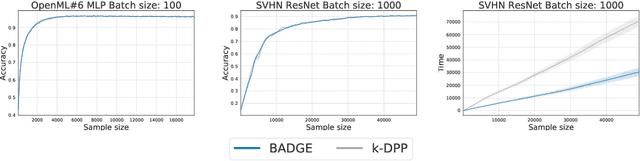
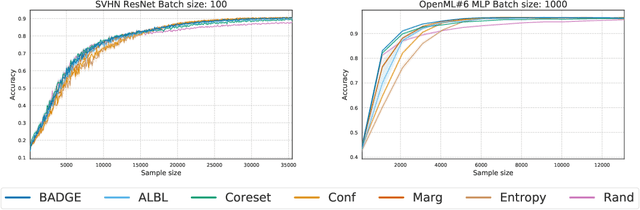
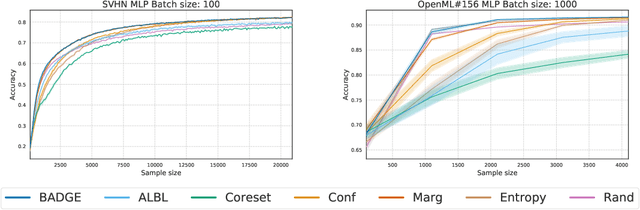
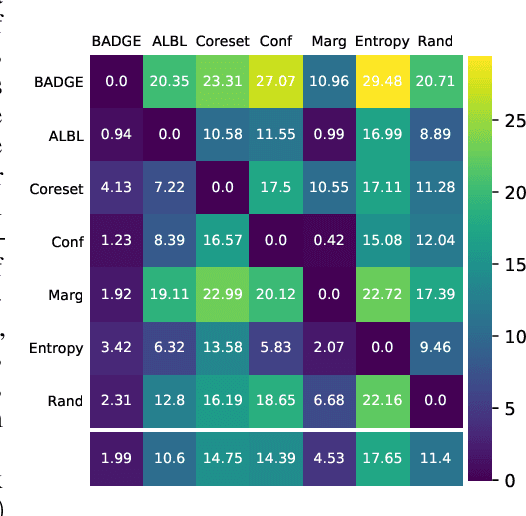
We design a new algorithm for batch active learning with deep neural network models. Our algorithm, Batch Active learning by Diverse Gradient Embeddings (BADGE), samples groups of points that are disparate and high-magnitude when represented in a hallucinated gradient space, a strategy designed to incorporate both predictive uncertainty and sample diversity into every selected batch. Crucially, BADGE trades off between diversity and uncertainty without requiring any hand-tuned hyperparameters. We show that while other approaches sometimes succeed for particular batch sizes or architectures, BADGE consistently performs as well or better, making it a versatile option for practical active learning problems.
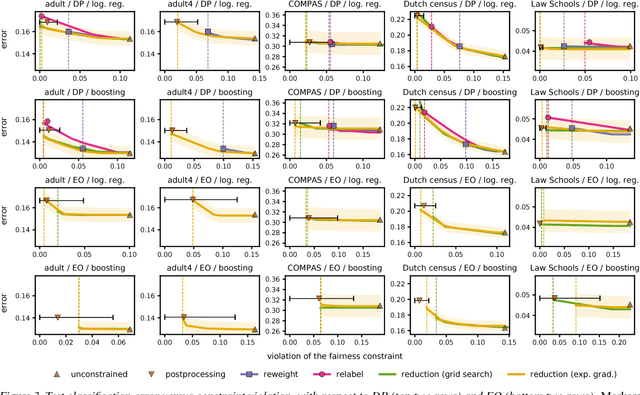
Fair Regression: Quantitative Definitions and Reduction-based Algorithms
May 30, 2019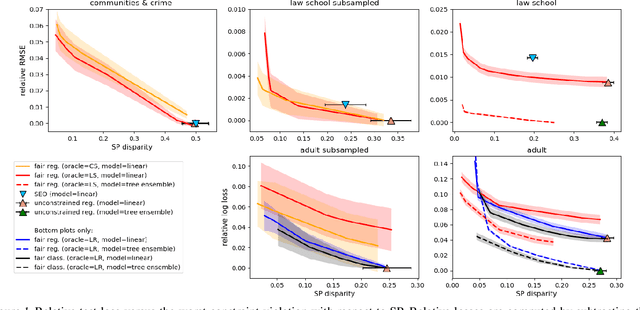
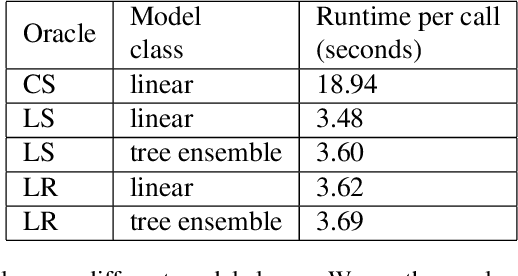
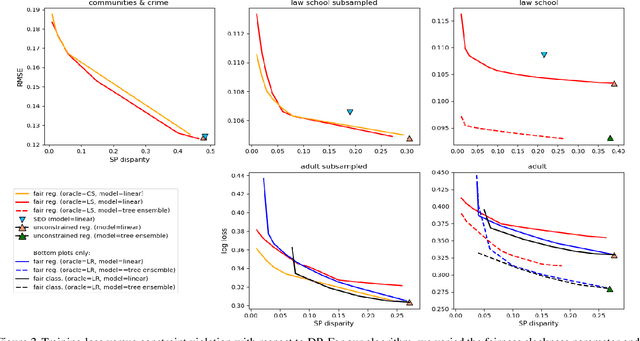
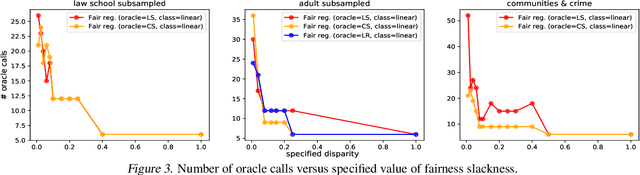
In this paper, we study the prediction of a real-valued target, such as a risk score or recidivism rate, while guaranteeing a quantitative notion of fairness with respect to a protected attribute such as gender or race. We call this class of problems \emph{fair regression}. We propose general schemes for fair regression under two notions of fairness: (1) statistical parity, which asks that the prediction be statistically independent of the protected attribute, and (2) bounded group loss, which asks that the prediction error restricted to any protected group remain below some pre-determined level. While we only study these two notions of fairness, our schemes are applicable to arbitrary Lipschitz-continuous losses, and so they encompass least-squares regression, logistic regression, quantile regression, and many other tasks. Our schemes only require access to standard risk minimization algorithms (such as standard classification or least-squares regression) while providing theoretical guarantees on the optimality and fairness of the obtained solutions. In addition to analyzing theoretical properties of our schemes, we empirically demonstrate their ability to uncover fairness--accuracy frontiers on several standard datasets.
Metareasoning in Modular Software Systems: On-the-Fly Configuration using Reinforcement Learning with Rich Contextual Representations
May 12, 2019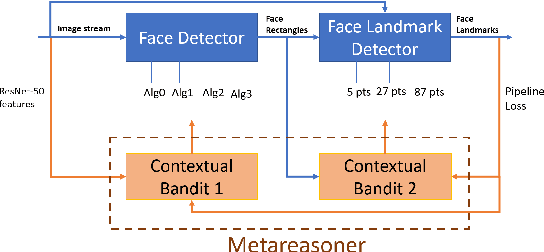

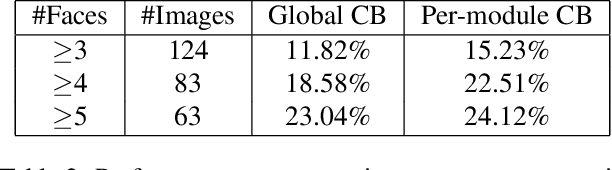
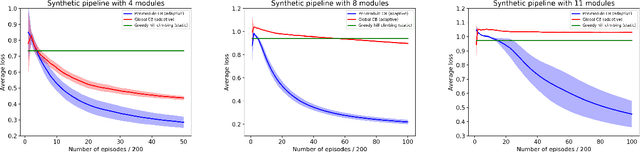
Assemblies of modular subsystems are being pressed into service to perform sensing, reasoning, and decision making in high-stakes, time-critical tasks in such areas as transportation, healthcare, and industrial automation. We address the opportunity to maximize the utility of an overall computing system by employing reinforcement learning to guide the configuration of the set of interacting modules that comprise the system. The challenge of doing system-wide optimization is a combinatorial problem. Local attempts to boost the performance of a specific module by modifying its configuration often leads to losses in overall utility of the system's performance as the distribution of inputs to downstream modules changes drastically. We present metareasoning techniques which consider a rich representation of the input, monitor the state of the entire pipeline, and adjust the configuration of modules on-the-fly so as to maximize the utility of a system's operation. We show significant improvement in both real-world and synthetic pipelines across a variety of reinforcement learning techniques.
Off-Policy Policy Gradient with State Distribution Correction
Apr 17, 2019
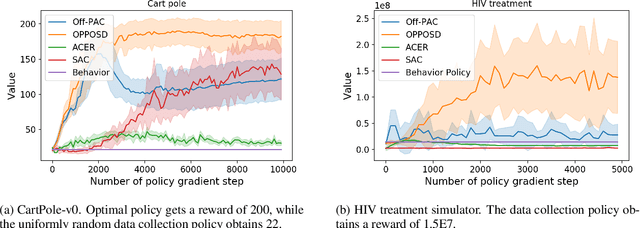
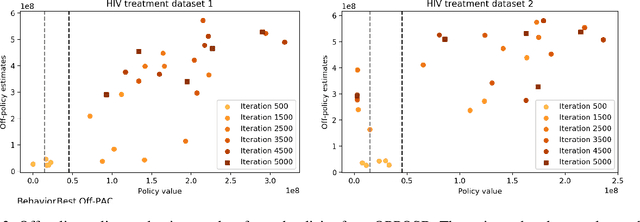
We study the problem of off-policy policy optimization in Markov decision processes, and develop a novel off-policy policy gradient method. Prior off-policy policy gradient approaches have generally ignored the mismatch between the distribution of states visited under the behavior policy used to collect data, and what would be the distribution of states under the learned policy. Here we build on recent progress for estimating the ratio of the Markov chain stationary distribution of states in policy evaluation, and presentan off-policy policy gradient optimization technique that can account for this mismatch in distributions.We present an illustrative example of why this is important, theoretical convergence guarantee for our approach and empirical simulations that highlight the benefits of correcting this distribution mismatch.
Provably efficient RL with Rich Observations via Latent State Decoding
Jan 25, 2019
We study the exploration problem in episodic MDPs with rich observations generated from a small number of latent states. Under certain identifiability assumptions, we demonstrate how to estimate a mapping from the observations to latent states inductively through a sequence of regression and clustering steps---where previously decoded latent states provide labels for later regression problems---and use it to construct good exploration policies. We provide finite-sample guarantees on the quality of the learned state decoding function and exploration policies, and complement our theory with an empirical evaluation on a class of hard exploration problems. Our method exponentially improves over $Q$-learning with na\"ive exploration, even when $Q$-learning has cheating access to latent states.
Warm-starting Contextual Bandits: Robustly Combining Supervised and Bandit Feedback
Jan 02, 2019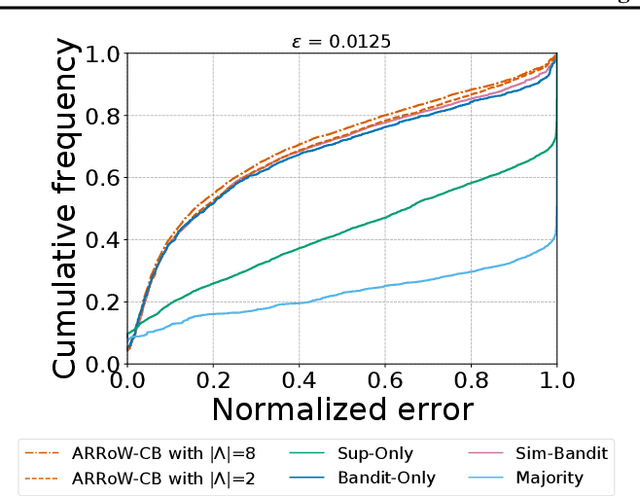
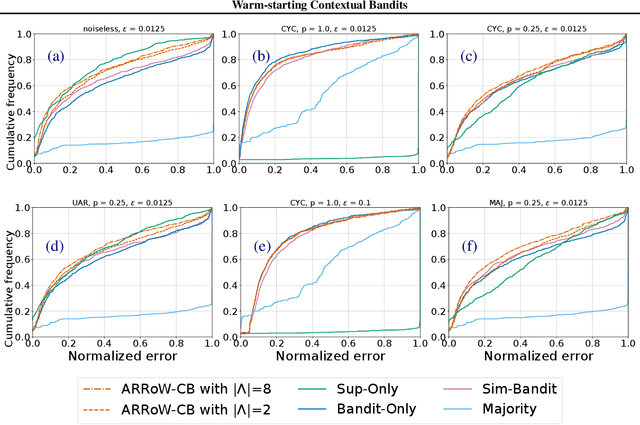
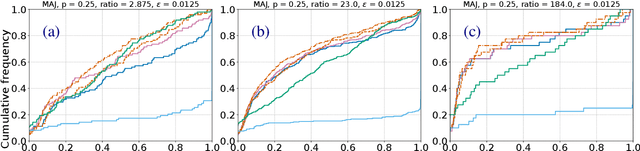
We investigate the feasibility of learning from both fully-labeled supervised data and contextual bandit data. We specifically consider settings in which the underlying learning signal may be different between these two data sources. Theoretically, we state and prove no-regret algorithms for learning that is robust to divergences between the two sources. Empirically, we evaluate some of these algorithms on a large selection of datasets, showing that our approaches are feasible, and helpful in practice.
Model-Based Reinforcement Learning in Contextual Decision Processes
Nov 21, 2018
We study the sample complexity of model-based reinforcement learning in general contextual decision processes. We design new algorithms for RL with an abstract model class and analyze their statistical properties. Our algorithms have sample complexity governed by a new structural parameter called the witness rank, which we show to be small in several settings of interest, including Factored MDPs and reactive POMDPs. We also show that the witness rank of a problem is never larger than the recently proposed Bellman rank parameter governing the sample complexity of the model-free algorithm OLIVE (Jiang et al., 2017), the only other provably sample efficient algorithm at this level of generality. Focusing on the special case of Factored MDPs, we prove an exponential lower bound for all model-free approaches, including OLIVE, which when combined with our algorithmic results demonstrates exponential separation between model-based and model-free RL in some rich-observation settings.
On Oracle-Efficient PAC RL with Rich Observations
Oct 31, 2018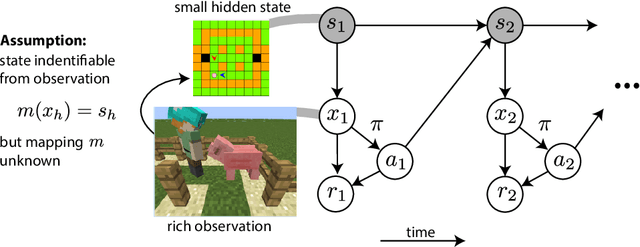
We study the computational tractability of PAC reinforcement learning with rich observations. We present new provably sample-efficient algorithms for environments with deterministic hidden state dynamics and stochastic rich observations. These methods operate in an oracle model of computation -- accessing policy and value function classes exclusively through standard optimization primitives -- and therefore represent computationally efficient alternatives to prior algorithms that require enumeration. With stochastic hidden state dynamics, we prove that the only known sample-efficient algorithm, OLIVE, cannot be implemented in the oracle model. We also present several examples that illustrate fundamental challenges of tractable PAC reinforcement learning in such general settings.
A Reductions Approach to Fair Classification
Jul 16, 2018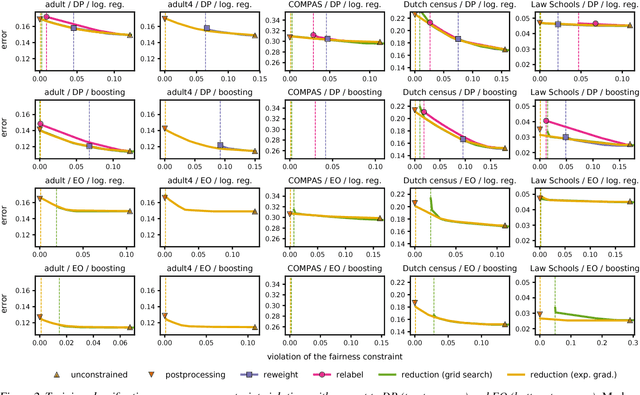
We present a systematic approach for achieving fairness in a binary classification setting. While we focus on two well-known quantitative definitions of fairness, our approach encompasses many other previously studied definitions as special cases. The key idea is to reduce fair classification to a sequence of cost-sensitive classification problems, whose solutions yield a randomized classifier with the lowest (empirical) error subject to the desired constraints. We introduce two reductions that work for any representation of the cost-sensitive classifier and compare favorably to prior baselines on a variety of data sets, while overcoming several of their disadvantages.
Hierarchical Imitation and Reinforcement Learning
Jun 09, 2018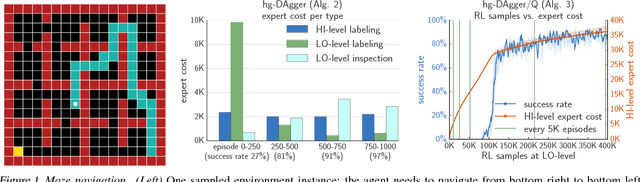
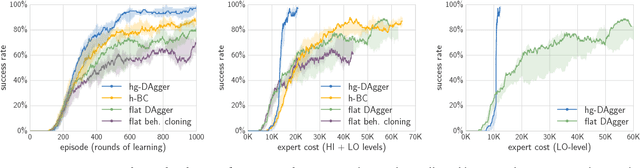
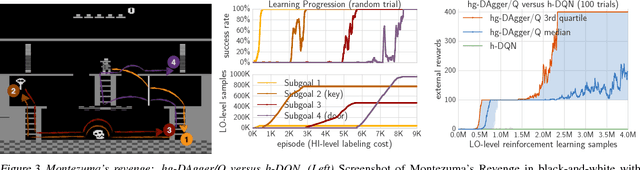
We study how to effectively leverage expert feedback to learn sequential decision-making policies. We focus on problems with sparse rewards and long time horizons, which typically pose significant challenges in reinforcement learning. We propose an algorithmic framework, called hierarchical guidance, that leverages the hierarchical structure of the underlying problem to integrate different modes of expert interaction. Our framework can incorporate different combinations of imitation learning (IL) and reinforcement learning (RL) at different levels, leading to dramatic reductions in both expert effort and cost of exploration. Using long-horizon benchmarks, including Montezuma's Revenge, we demonstrate that our approach can learn significantly faster than hierarchical RL, and be significantly more label-efficient than standard IL. We also theoretically analyze labeling cost for certain instantiations of our framework.