 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroth-order Deterministic Policy Gradient
Jul 11, 2020
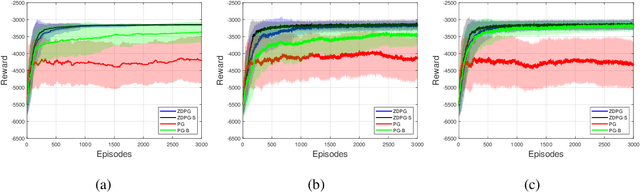
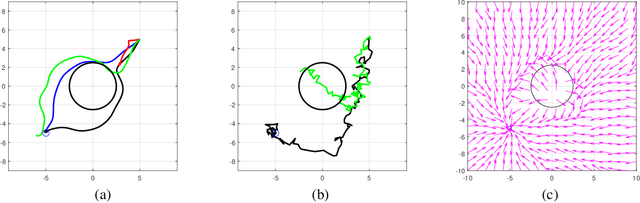
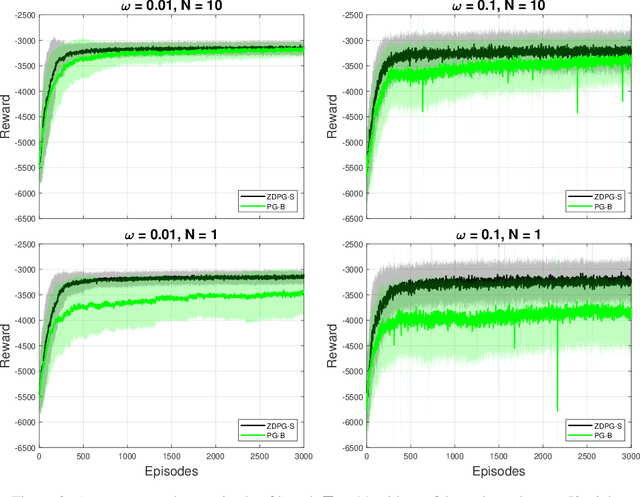
Deterministic Policy Gradient (DPG) removes a level of randomness from standard randomized-action Policy Gradient (PG), and demonstrates substantial empirical success for tackling complex dynamic problems involving Markov decision processes. At the same time, though, DPG loses its ability to learn in a model-free (i.e., actor-only) fashion, frequently necessitating the use of critics in order to obtain consistent estimates of the associated policy-reward gradient. In this work, we introduce Zeroth-order Deterministic Policy Gradient (ZDPG), which approximates policy-reward gradients via two-point stochastic evaluations of the $Q$-function, constructed by properly designed low-dimensional action-space perturbations. Exploiting the idea of random horizon rollouts for obtaining unbiased estimates of the $Q$-function, ZDPG lifts the dependence on critics and restores true model-free policy learning, while enjoying built-in and provable algorithmic stability. Additionally, we present new finite sample complexity bounds for ZDPG, which improve upon existing results by up to two orders of magnitude. Our findings are supported by several numerical experiments, which showcase the effectiveness of ZDPG in a practical setting, and its advantages over both PG and Baseline PG.
Balancing Rates and Variance via Adaptive Batch-Size for Stochastic Optimization Problems
Jul 09, 2020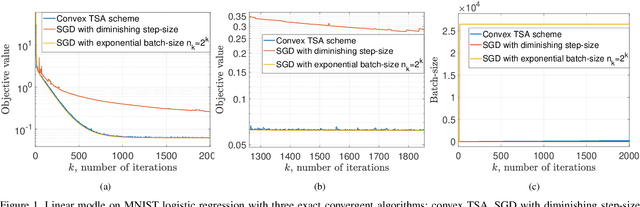
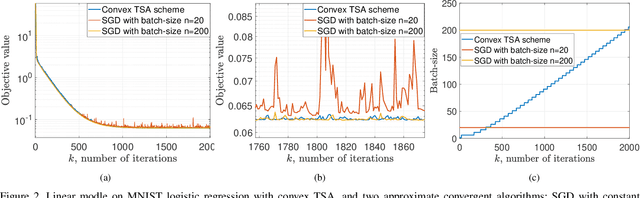
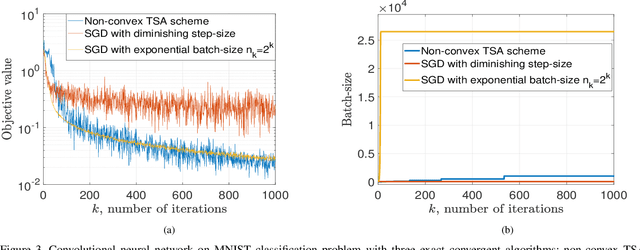
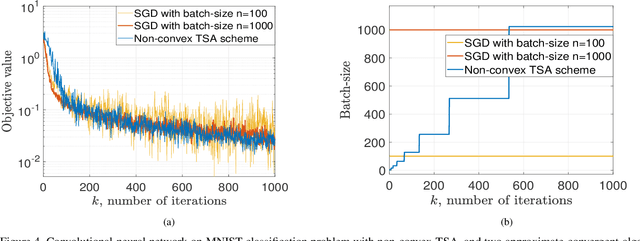
Stochastic gradient descent is a canonical tool for addressing stochastic optimization problems, and forms the bedrock of modern machine learning and statistics. In this work, we seek to balance the fact that attenuating step-size is required for exact asymptotic convergence with the fact that constant step-size learns faster in finite time up to an error. To do so, rather than fixing the mini-batch and the step-size at the outset, we propose a strategy to allow parameters to evolve adaptively. Specifically, the batch-size is set to be a piecewise-constant increasing sequence where the increase occurs when a suitable error criterion is satisfied. Moreover, the step-size is selected as that which yields the fastest convergence. The overall algorithm, two scale adaptive (TSA) scheme, is developed for both convex and non-convex stochastic optimization problems. It inherits the exact asymptotic convergence of stochastic gradient method. More importantly, the optimal error decreasing rate is achieved theoretically, as well as an overall reduction in computational cost. Experimentally, we observe that TSA attains a favorable tradeoff relative to standard SGD that fixes the mini-batch and the step-size, or simply allowing one to increase or decrease respectively.
Resource Allocation via Graph Neural Networks in Free Space Optical Fronthaul Networks
Jun 26, 2020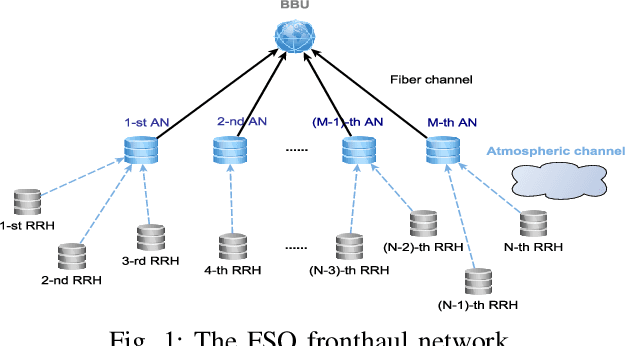
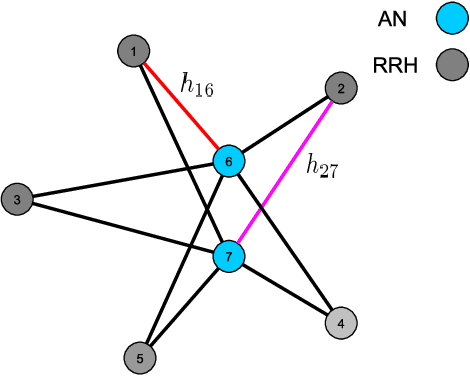
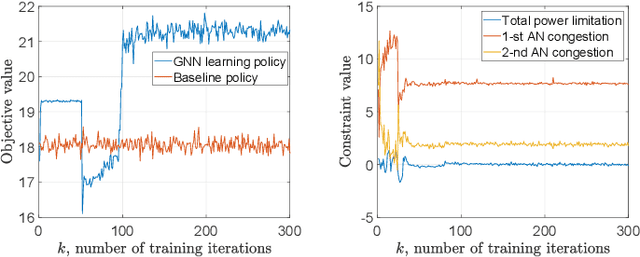
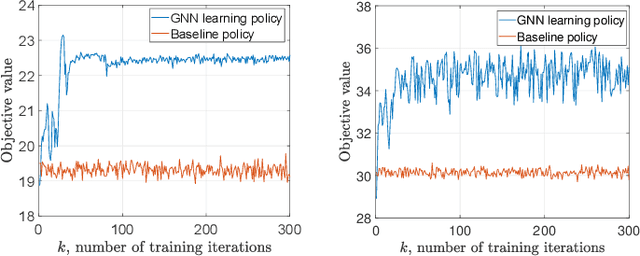
This paper investigates the optimal resource allocation in free space optical (FSO) fronthaul networks. The optimal allocation maximizes an average weighted sum-capacity subject to power limitation and data congestion constraints. Both adaptive power assignment and node selection are considered based on the instantaneous channel state information (CSI) of the links. By parameterizing the resource allocation policy, we formulate the problem as an unsupervised statistical learning problem. We consider the graph neural network (GNN) for the policy parameterization to exploit the FSO network structure with small-scale training parameters. The GNN is shown to retain the permutation equivariance that matches with the permutation equivariance of resource allocation policy in networks. The primal-dual learning algorithm is developed to train the GNN in a model-free manner, where the knowledge of system models is not required. Numerical simulations present the strong performance of the GNN relative to a baseline policy with equal power assignment and random node selection.
Wide and Deep Graph Neural Networks with Distributed Online Learning
Jun 11, 2020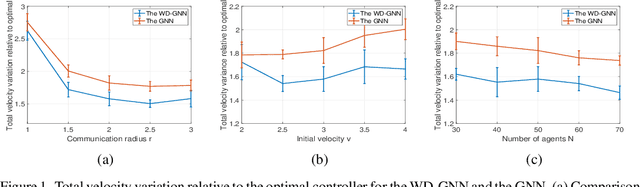
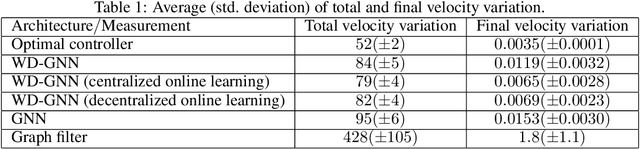
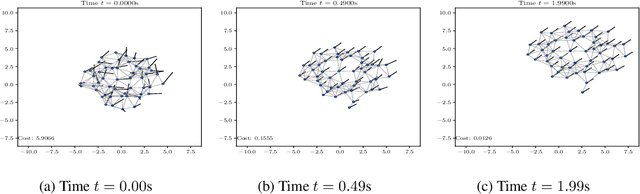
Graph neural networks (GNNs) learn representations from network data with naturally distributed architectures. This renders them well-suited candidates for decentralized learning since the operations respect the structure imposed by the underlying graph. Oftentimes, this graph support changes with time, whether it is due to link failures or topology changes caused by mobile components. Modifications to the underlying structure create a mismatch between the graphs on which GNNs were trained and the ones on which they are tested. Online learning can be used to retrain the GNNs at test time, overcoming this issue. However, most online learning algorithms are centralized and work on convex objective functions (which GNNs rarely lead to). This paper puts forth the Wide and Deep GNN (WD-GNN), a novel architecture that can be easily updated with distributed online learning mechanisms. The WD-GNN consists of two components: the wide part is a bank of linear graph filters and the deep part is a convolutional GNN. At training time, the joint architecture learns a relevant nonlinear representation from data. At test time, the deep part is left unchanged, while the wide part is retrained online. Since the wide part is linear, the problem becomes convex, and online optimization algorithms can be used. We also propose a distributed online optimization algorithm that updates the wide part at test time, without violating its decentralized nature. We also analyze the stability of the WD-GNN to changes in the underlying topology and derive convergence guarantees for the online retraining procedure. These results indicate the transferability, scalability, and efficiency of the WD-GNN to adapt online to new testing scenarios in a distributed manner. Experiments on the control of robot swarms corroborate the theory and show the potential of the proposed architecture for distributed online learning.
Graph Neural Networks for Motion Planning
Jun 11, 2020
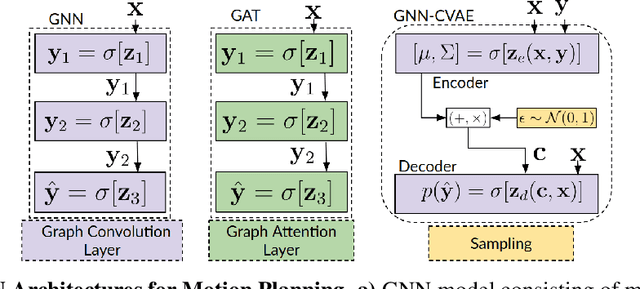
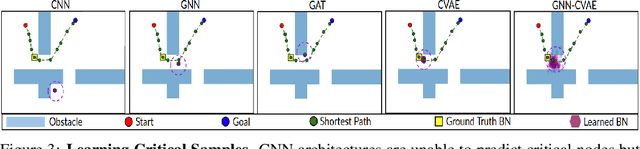
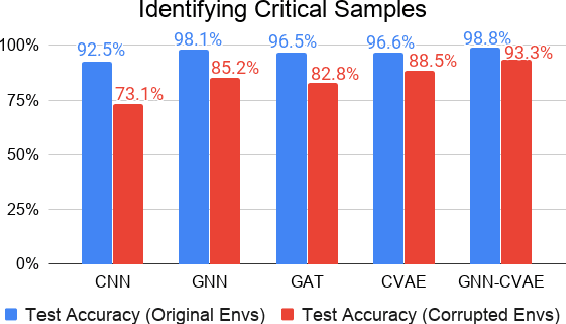
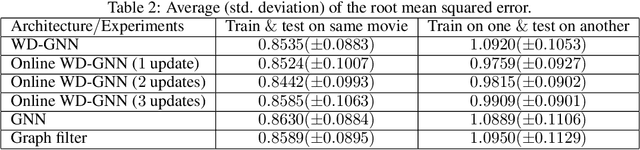
This paper investigates the feasibility of using Graph Neural Networks (GNNs) for classical motion planning problems. Planning algorithms that search through discrete spaces as well as continuous ones are studied. This paper proposes using GNNs to guide the search algorithm by exploiting the ability of GNNs to extract low level information about the topology of a planning space. We present two techniques, GNNs over dense fixed graphs for low-dimensional problems and sampling-based GNNs for high-dimensional problems. We examine the ability of a GNN to tackle planning problems that are heavily dependent on the topology of the space such as identifying critical nodes, learning a heuristic that guides exploration in $\text{A}^*$, and learning the sampling distribution in Rapidly-exploring Random Trees (RRT). We demonstrate that GNNs can offer better results when compared to traditional analytic methods as well as learning-based approaches that employ fully-connected networks or convolutional neural networks.
Probably Approximately Correct Constrained Learning
Jun 09, 2020
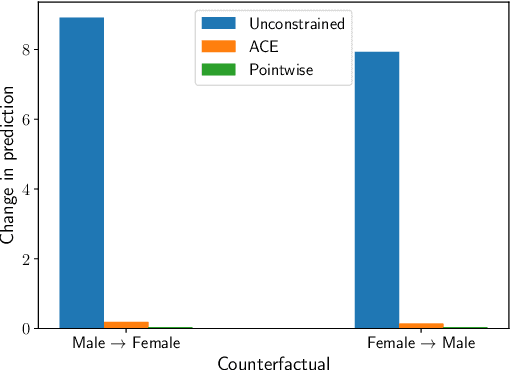
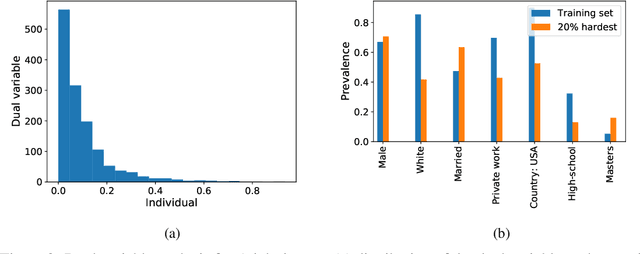
As learning solutions reach critical applications in social, industrial, and medical domains, the need to curtail their behavior becomes paramount. There is now ample evidence that without explicit tailoring, learning can lead to biased, unsafe, and prejudiced solutions. To tackle these problems, we develop a generalization theory of constrained learning based on the probably approximately correct (PAC) learning framework. In particular, we show that imposing requirements does not make a learning problem harder in the sense that any PAC learnable class is also PAC constrained learnable using a constrained counterpart of the empirical risk minimization (ERM) rule. For typical parametrized models, however, this learner involves solving a non-convex optimization program for which even obtaining a feasible solution may be hard. To overcome this issue, we prove that under mild conditions the empirical dual problem of constrained learning is also a PAC constrained learner that now leads to a practical constrained learning algorithm. We analyze the generalization properties of this solution and use it to illustrate how constrained learning can address problems in fair and robust classification.
Graphon Neural Networks and the Transferability of Graph Neural Networks
Jun 05, 2020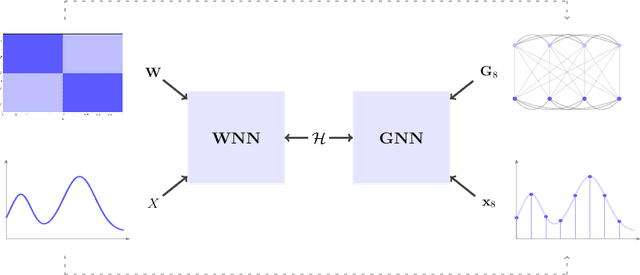
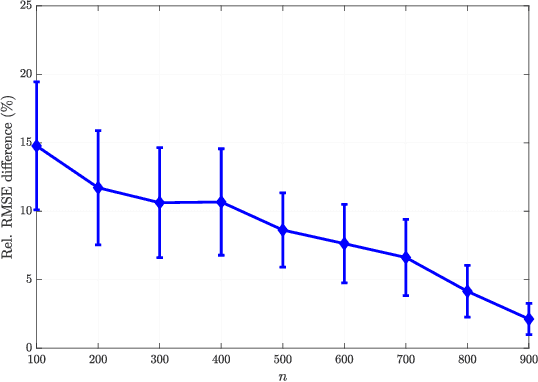
Graph neural networks (GNNs) rely on graph convolutions to extract local features from network data. These graph convolutions combine information from adjacent nodes using coefficients that are shared across all nodes. As a byproduct, coefficients can also be transferred to different graphs, thereby motivating the analysis of transferability across graphs. In this paper we introduce graphon NNs as limit objects of GNNs and prove a bound on the difference between the output of a GNN and its limit graphon-NN. This bound vanishes with growing number of nodes if the graph convolutional filters are bandlimited in the graph spectral domain. This result establishes a tradeoff between discriminability and transferability of GNNs.
Stochastic Graph Neural Networks
Jun 04, 2020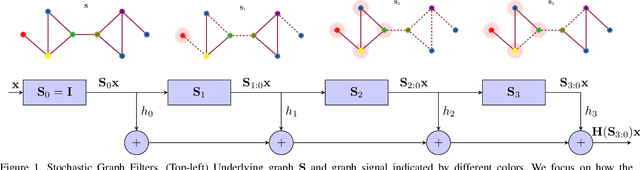
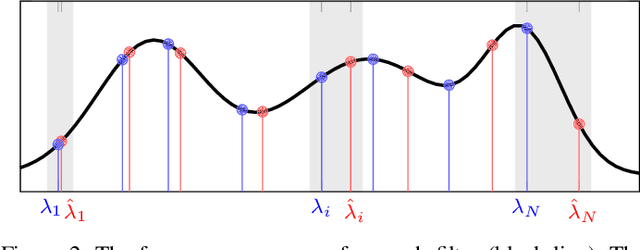
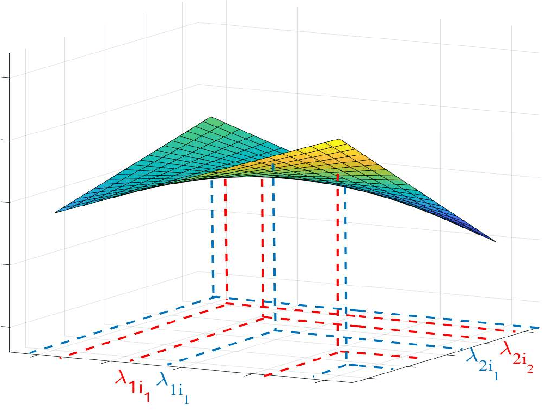
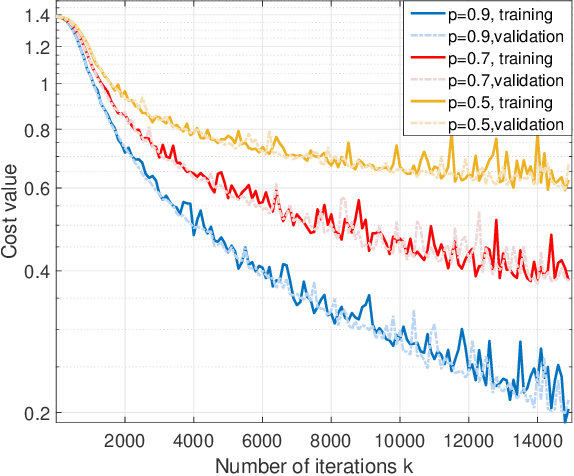
Graph neural networks (GNNs) model nonlinear representations in graph data with applications in distributed agent coordination, control, and planning among others. Current GNN architectures assume ideal scenarios and ignore link fluctuations that occur due to environment, human factors, or external attacks. In these situations, the GNN fails to address its distributed task if the topological randomness is not considered accordingly. To overcome this issue, we put forth the stochastic graph neural network (SGNN) model: a GNN where the distributed graph convolution module accounts for the random network changes. Since stochasticity brings in a new learning paradigm, we conduct a statistical analysis on the SGNN output variance to identify conditions the learned filters should satisfy for achieving robust transference to perturbed scenarios, ultimately revealing the explicit impact of random link losses. We further develop a stochastic gradient descent (SGD) based learning process for the SGNN and derive conditions on the learning rate under which this learning process converges to a stationary point. Numerical results corroborate our theoretical findings and compare the benefits of SGNN robust transference with a conventional GNN that ignores graph perturbations during learning.
Graph Neural Networks for Decentralized Controllers
Mar 23, 2020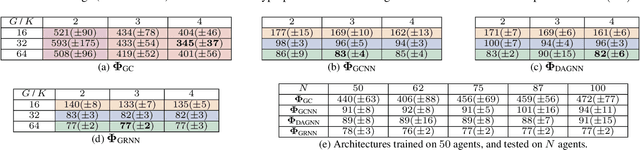
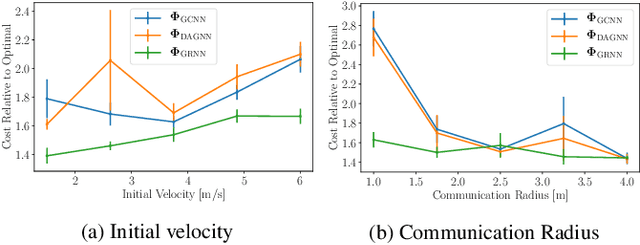
Dynamical systems comprised of autonomous agents arise in many relevant problems such as multi-agent robotics, smart grids, or smart cities. Controlling these systems is of paramount importance to guarantee a successful deployment. Optimal centralized controllers are readily available but face limitations in terms of scalability and practical implementation. Optimal decentralized controllers, on the other hand, are difficult to find. In this paper, we use graph neural networks (GNNs) to learn decentralized controllers from data. GNNs are well-suited for the task since they are naturally distributed architectures. Furthermore, they are equivariant and stable, leading to good scalability and transferability properties. The problem of flocking is explored to illustrate the power of GNNs in learning decentralized controllers.
Graphs, Convolutions, and Neural Networks
Mar 08, 2020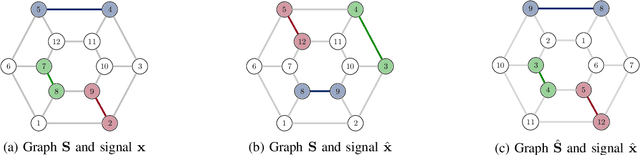
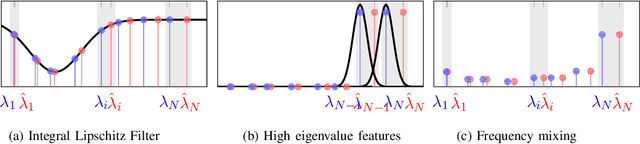
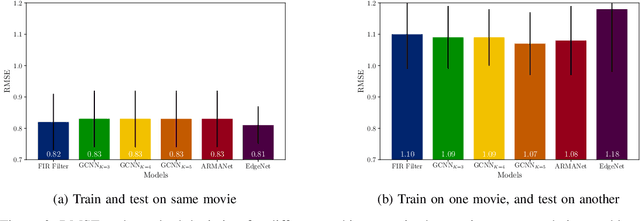

Network data can be conveniently modeled as a graph signal, where data values are assigned to nodes of a graph that describes the underlying network topology. Successful learning from network data is built upon methods that effectively exploit this graph structure. In this work, we overview graph convolutional filters, which are linear, local and distributed operations that adequately leverage the graph structure. We then discuss graph neural networks (GNNs), built upon graph convolutional filters, that have been shown to be powerful nonlinear learning architectures. We show that GNNs are permutation equivariant and stable to changes in the underlying graph topology, allowing them to scale and transfer. We also introduce GNN extensions using edge-varying and autoregressive moving average graph filters and discuss their properties. Finally, we study the use of GNNs in learning decentralized controllers for robot swarm and in addressing the recommender system problem.