 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Local Attention Maps for Synthesising Vessel Segmentations
Aug 24, 2023Magnetic resonance angiography (MRA) is an imaging modality for visualising blood vessels. It is useful for several diagnostic applications and for assessing the risk of adverse events such as haemorrhagic stroke (resulting from the rupture of aneurysms in blood vessels). However, MRAs are not acquired routinely, hence, an approach to synthesise blood vessel segmentations from more routinely acquired MR contrasts such as T1 and T2, would be useful. We present an encoder-decoder model for synthesising segmentations of the main cerebral arteries in the circle of Willis (CoW) from only T2 MRI. We propose a two-phase multi-objective learning approach, which captures both global and local features. It uses learned local attention maps generated by dilating the segmentation labels, which forces the network to only extract information from the T2 MRI relevant to synthesising the CoW. Our synthetic vessel segmentations generated from only T2 MRI achieved a mean Dice score of $0.79 \pm 0.03$ in testing, compared to state-of-the-art segmentation networks such as transformer U-Net ($0.71 \pm 0.04$) and nnU-net($0.68 \pm 0.05$), while using only a fraction of the parameters. The main qualitative difference between our synthetic vessel segmentations and the comparative models was in the sharper resolution of the CoW vessel segments, especially in the posterior circulation.
Shape-guided Conditional Latent Diffusion Models for Synthesising Brain Vasculature
Aug 13, 2023



The Circle of Willis (CoW) is the part of cerebral vasculature responsible for delivering blood to the brain. Understanding the diverse anatomical variations and configurations of the CoW is paramount to advance research on cerebrovascular diseases and refine clinical interventions. However, comprehensive investigation of less prevalent CoW variations remains challenging because of the dominance of a few commonly occurring configurations. We propose a novel generative approach utilising a conditional latent diffusion model with shape and anatomical guidance to generate realistic 3D CoW segmentations, including different phenotypical variations. Our conditional latent diffusion model incorporates shape guidance to better preserve vessel continuity and demonstrates superior performance when compared to alternative generative models, including conditional variants of 3D GAN and 3D VAE. We observed that our model generated CoW variants that are more realistic and demonstrate higher visual fidelity than competing approaches with an FID score 53\% better than the best-performing GAN-based model.
GSMorph: Gradient Surgery for cine-MRI Cardiac Deformable Registration
Jun 26, 2023Deep learning-based deformable registration methods have been widely investigated in diverse medical applications. Learning-based deformable registration relies on weighted objective functions trading off registration accuracy and smoothness of the deformation field. Therefore, they inevitably require tuning the hyperparameter for optimal registration performance. Tuning the hyperparameters is highly computationally expensive and introduces undesired dependencies on domain knowledge. In this study, we construct a registration model based on the gradient surgery mechanism, named GSMorph, to achieve a hyperparameter-free balance on multiple losses. In GSMorph, we reformulate the optimization procedure by projecting the gradient of similarity loss orthogonally to the plane associated with the smoothness constraint, rather than additionally introducing a hyperparameter to balance these two competing terms. Furthermore, our method is model-agnostic and can be merged into any deep registration network without introducing extra parameters or slowing down inference. In this study, We compared our method with state-of-the-art (SOTA) deformable registration approaches over two publicly available cardiac MRI datasets. GSMorph proves superior to five SOTA learning-based registration models and two conventional registration techniques, SyN and Demons, on both registration accuracy and smoothness.
A Conditional Flow Variational Autoencoder for Controllable Synthesis of Virtual Populations of Anatomy
Jun 26, 2023Generating virtual populations (VPs) of anatomy is essential for conducting in-silico trials of medical devices. Typically, the generated VP should capture sufficient variability while remaining plausible, and should reflect specific characteristics and patient demographics observed in real populations. It is desirable in several applications to synthesize VPs in a \textit{controlled} manner, where relevant covariates are used to conditionally synthesise virtual populations that fit specific target patient populations/characteristics. We propose to equip a conditional variational autoencoder (cVAE) with normalizing flows to boost the flexibility and complexity of the approximate posterior learned, leading to enhanced flexibility for controllable synthesis of VPs of anatomical structures. We demonstrate the performance of our conditional-flow VAE using a dataset of cardiac left ventricles acquired from 2360 patients, with associated demographic information and clinical measurements (used as covariates/conditioning information). The obtained results indicate the superiority of the proposed method for conditional synthesis of virtual populations of cardiac left ventricles relative to a cVAE. Conditional synthesis performance was assessed in terms of generalisation and specificity errors, and in terms of the ability to preserve clinical relevant biomarkers in the synthesised VPs, I.e. left ventricular blood pool and myocardial volume, relative to the observed real population.
A Generalised Deep Meta-Learning Model for Automated Quality Control of Cardiovascular Magnetic Resonance Images
Mar 23, 2023


Background and Objectives: Cardiovascular magnetic resonance (CMR) imaging is a powerful modality in functional and anatomical assessment for various cardiovascular diseases. Sufficient image quality is essential to achieve proper diagnosis and treatment. A large number of medical images, the variety of imaging artefacts, and the workload of imaging centres are among the things that reveal the necessity of automatic image quality assessment (IQA). However, automated IQA requires access to bulk annotated datasets for training deep learning (DL) models. Labelling medical images is a tedious, costly and time-consuming process, which creates a fundamental challenge in proposing DL-based methods for medical applications. This study aims to present a new method for CMR IQA when there is limited access to annotated datasets. Methods: The proposed generalised deep meta-learning model can evaluate the quality by learning tasks in the prior stage and then fine-tuning the resulting model on a small labelled dataset of the desired tasks. This model was evaluated on the data of over 6,000 subjects from the UK Biobank for five defined tasks, including detecting respiratory motion, cardiac motion, Aliasing and Gibbs ringing artefacts and images without artefacts. Results: The results of extensive experiments show the superiority of the proposed model. Besides, comparing the model's accuracy with the domain adaptation model indicates a significant difference by using only 64 annotated images related to the desired tasks. Conclusion: The proposed model can identify unknown artefacts in images with acceptable accuracy, which makes it suitable for medical applications and quality assessment of large cohorts.
Boosting Personalised Musculoskeletal Modelling with Physics-informed Knowledge Transfer
Nov 22, 2022



Data-driven methods have become increasingly more prominent for musculoskeletal modelling due to their conceptually intuitive simple and fast implementation. However, the performance of a pre-trained data-driven model using the data from specific subject(s) may be seriously degraded when validated using the data from a new subject, hindering the utility of the personalised musculoskeletal model in clinical applications. This paper develops an active physics-informed deep transfer learning framework to enhance the dynamic tracking capability of the musculoskeletal model on the unseen data. The salient advantages of the proposed framework are twofold: 1) For the generic model, physics-based domain knowledge is embedded into the loss function of the data-driven model as soft constraints to penalise/regularise the data-driven model. 2) For the personalised model, the parameters relating to the feature extraction will be directly inherited from the generic model, and only the parameters relating to the subject-specific inference will be finetuned by jointly minimising the conventional data prediction loss and the modified physics-based loss. In this paper, we use the synchronous muscle forces and joint kinematics prediction from surface electromyogram (sEMG) as the exemplar to illustrate the proposed framework. Moreover, convolutional neural network (CNN) is employed as the deep neural network to implement the proposed framework, and the physics law between muscle forces and joint kinematics is utilised as the soft constraints. Results of comprehensive experiments on a self-collected dataset from eight healthy subjects indicate the effectiveness and great generalization of the proposed framework.
A Generative Shape Compositional Framework: Towards Representative Populations of Virtual Heart Chimaeras
Oct 04, 2022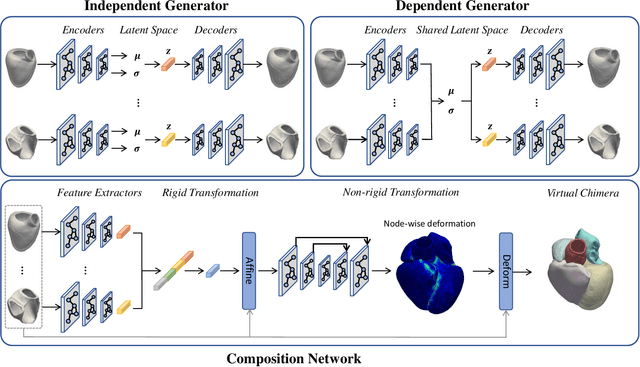
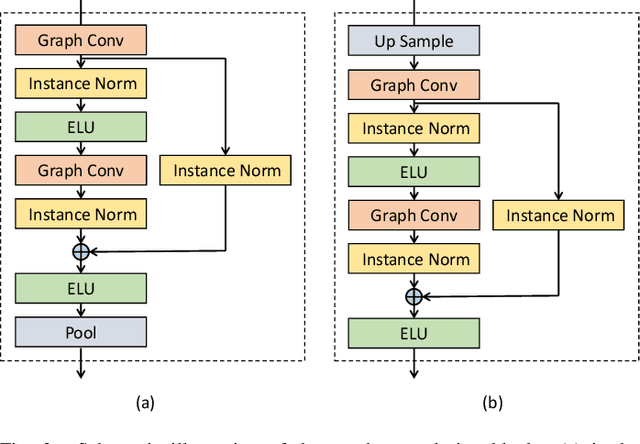
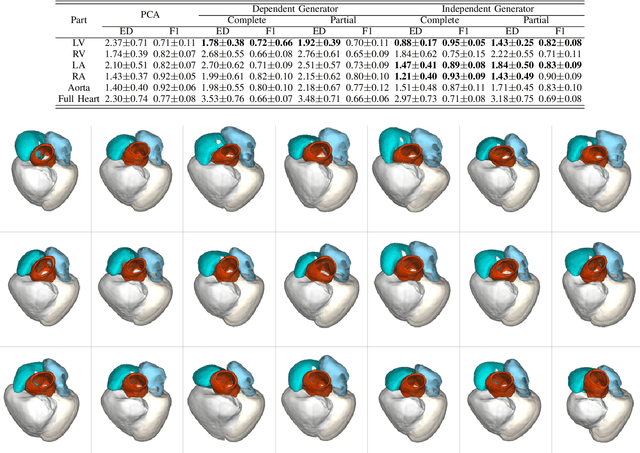
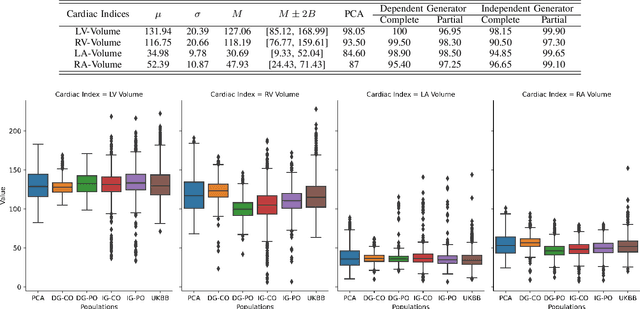
Generating virtual populations of anatomy that capture sufficient variability while remaining plausible is essential for conducting in-silico trials of medical devices. However, not all anatomical shapes of interest are always available for each individual in a population. Hence, missing/partially-overlapping anatomical information is often available across individuals in a population. We introduce a generative shape model for complex anatomical structures, learnable from datasets of unpaired datasets. The proposed generative model can synthesise complete whole complex shape assemblies coined virtual chimaeras, as opposed to natural human chimaeras. We applied this framework to build virtual chimaeras from databases of whole-heart shape assemblies that each contribute samples for heart substructures. Specifically, we propose a generative shape compositional framework which comprises two components - a part-aware generative shape model which captures the variability in shape observed for each structure of interest in the training population; and a spatial composition network which assembles/composes the structures synthesised by the former into multi-part shape assemblies (viz. virtual chimaeras). We also propose a novel self supervised learning scheme that enables the spatial composition network to be trained with partially overlapping data and weak labels. We trained and validated our approach using shapes of cardiac structures derived from cardiac magnetic resonance images available in the UK Biobank. Our approach significantly outperforms a PCA-based shape model (trained with complete data) in terms of generalisability and specificity. This demonstrates the superiority of the proposed approach as the synthesised cardiac virtual populations are more plausible and capture a greater degree of variability in shape than those generated by the PCA-based shape model.
Three-dimensional micro-structurally informed in silico myocardium -- towards virtual imaging trials in cardiac diffusion weighted MRI
Aug 22, 2022
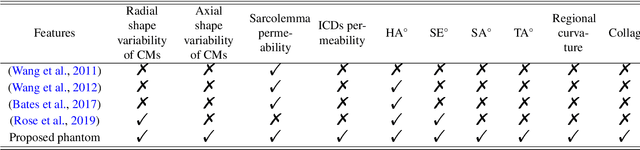
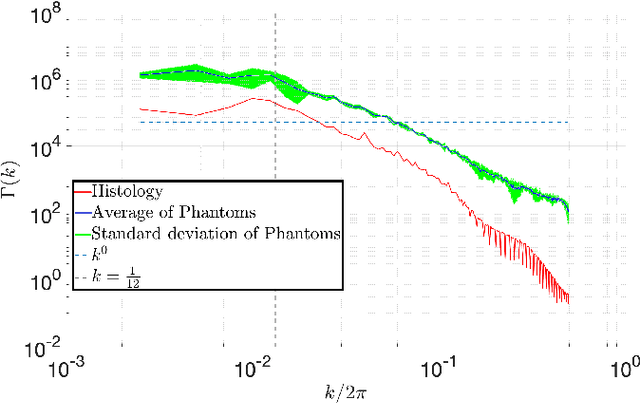
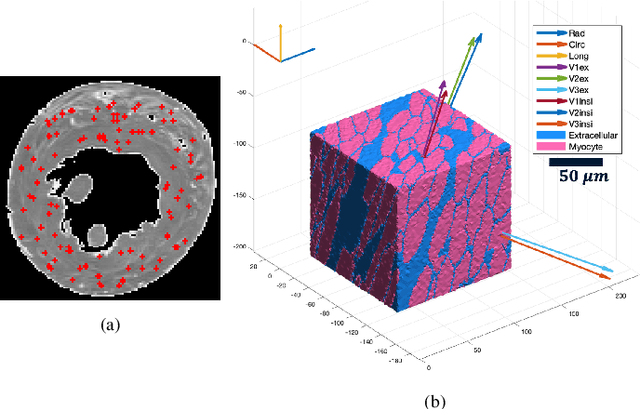
In silico tissue models enable evaluating quantitative models of magnetic resonance imaging. This includes validating and sensitivity analysis of imaging biomarkers and tissue microstructure parameters. We propose a novel method to generate a realistic numerical phantom of myocardial microstructure. We extend previous studies accounting for the cardiomyocyte shape variability, water exchange between the cardiomyocytes (intercalated discs), myocardial microstructure disarray, and four sheetlet orientations. In the first stage of the method, cardiomyocytes and sheetlets are generated by considering the shape variability and intercalated discs in cardiomyocyte-to-cardiomyocyte connections. Sheetlets are then aggregated and oriented in the directions of interest. Our morphometric study demonstrates no significant difference ($p>0.01$) between the distribution of volume, length, and primary and secondary axes of the numerical and real (literature) cardiomyocyte data. Structural correlation analysis validates that the in-silico tissue is in the same class of disorderliness as the real tissue. Additionally, the absolute angle differences between the simulated helical angle (HA) and input HA (reference value) of the cardiomyocytes ($4.3^\circ\pm 3.1^\circ$) demonstrate a good agreement with the absolute angle difference between the measured HA using experimental cardiac diffusion tensor imaging (cDTI) and histology (reference value) reported by (Holmes et al., 2000) ($3.7^\circ\pm6.4^\circ$) and (Scollan et al., 1998) ($4.9^\circ\pm 14.6^\circ$). The angular distance between eigenvectors and sheetlet angles of the input and simulated cDTI is smaller than those between measured angles using structural tensor imaging (gold standard) and experimental cDTI. These results confirm that the proposed method can generate richer numerical phantoms for the myocardium than previous studies.
Physics-informed Deep Learning for Musculoskeletal Modelling: Predicting Muscle Forces and Joint Kinematics from Surface EMG
Jul 04, 2022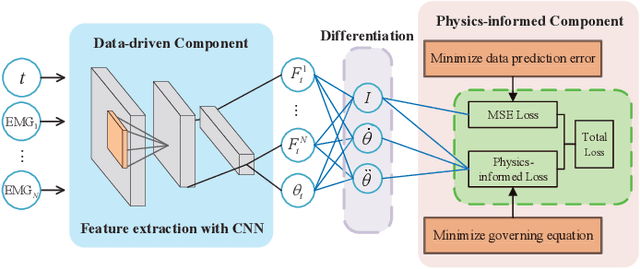
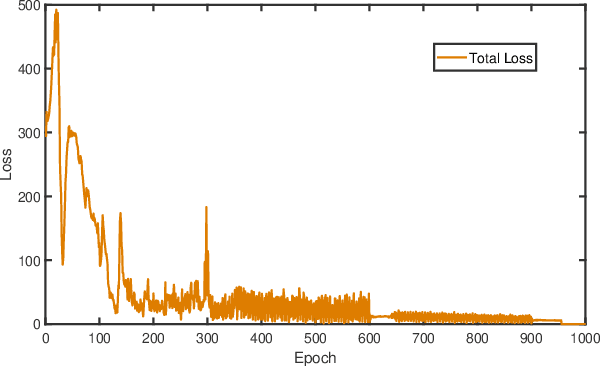
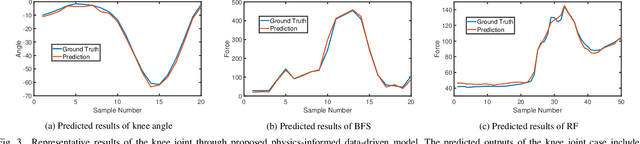
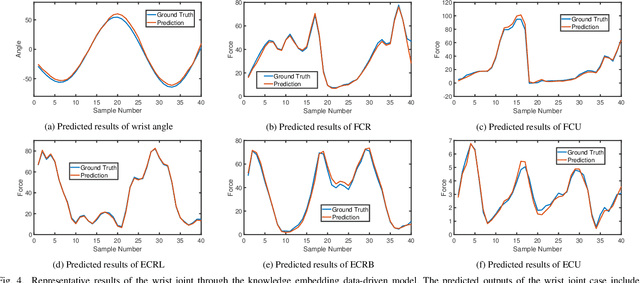
Musculoskeletal models have been widely used for detailed biomechanical analysis to characterise various functional impairments given their ability to estimate movement variables (i.e., muscle forces and joint moment) which cannot be readily measured in vivo. Physics-based computational neuromusculoskeletal models can interpret the dynamic interaction between neural drive to muscles, muscle dynamics, body and joint kinematics and kinetics. Still, such set of solutions suffers from slowness, especially for the complex models, hindering the utility in real-time applications. In recent years, data-driven methods has emerged as a promising alternative due to the benefits in speedy and simple implementation, but they cannot reflect the underlying neuromechanical processes. This paper proposes a physics-informed deep learning framework for musculoskeletal modelling, where physics-based domain knowledge is brought into the data-driven model as soft constraints to penalise/regularise the data-driven model. We use the synchronous muscle forces and joint kinematics prediction from surface electromyogram (sEMG) as the exemplar to illustrate the proposed framework. Convolutional neural network (CNN) is employed as the deep neural network to implement the proposed framework. At the same time, the physics law between muscle forces and joint kinematics is used the soft constraint. Experimental validations on two groups of data, including one benchmark dataset and one self-collected dataset from six healthy subjects, are performed. The experimental results demonstrate the effectiveness and robustness of the proposed framework.
Agent with Tangent-based Formulation and Anatomical Perception for Standard Plane Localization in 3D Ultrasound
Jul 01, 2022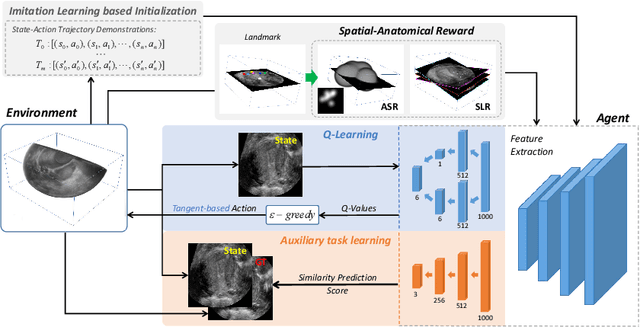
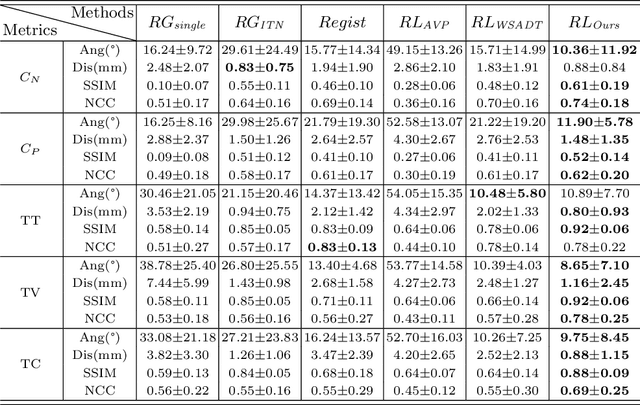
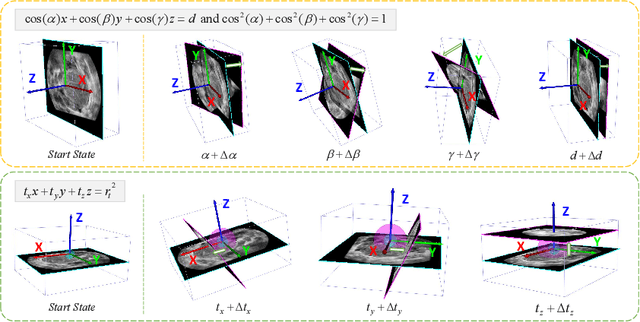
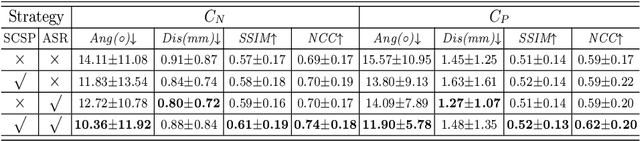
Standard plane (SP) localization is essential in routine clinical ultrasound (US) diagnosis. Compared to 2D US, 3D US can acquire multiple view planes in one scan and provide complete anatomy with the addition of coronal plane. However, manually navigating SPs in 3D US is laborious and biased due to the orientation variability and huge search space. In this study, we introduce a novel reinforcement learning (RL) framework for automatic SP localization in 3D US. Our contribution is three-fold. First, we formulate SP localization in 3D US as a tangent-point-based problem in RL to restructure the action space and significantly reduce the search space. Second, we design an auxiliary task learning strategy to enhance the model's ability to recognize subtle differences crossing Non-SPs and SPs in plane search. Finally, we propose a spatial-anatomical reward to effectively guide learning trajectories by exploiting spatial and anatomical information simultaneously. We explore the efficacy of our approach on localizing four SPs on uterus and fetal brain datasets. The experiments indicate that our approach achieves a high localization accuracy as well as robust performance.