 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Image Segmentation with Task-Specific Edge Detection Using CNNs and a Discriminatively Trained Domain Transform
Jun 02, 2016

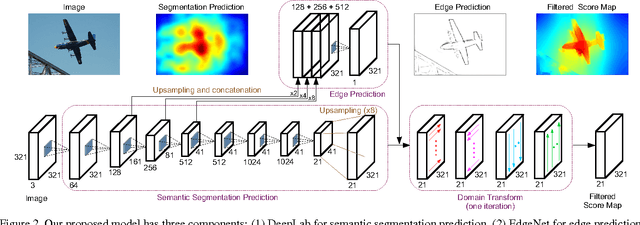
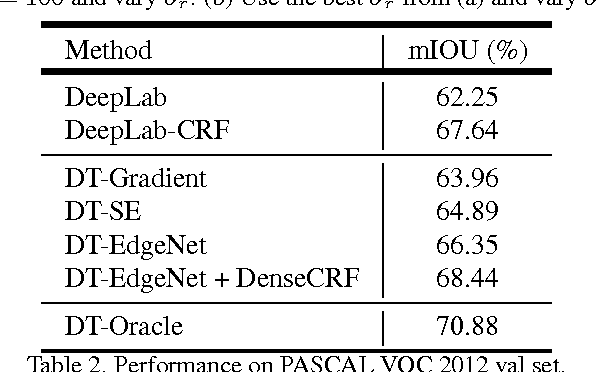
Deep convolutional neural networks (CNNs) are the backbone of state-of-art semantic image segmentation systems. Recent work has shown that complementing CNNs with fully-connected conditional random fields (CRFs) can significantly enhance their object localization accuracy, yet dense CRF inference is computationally expensive. We propose replacing the fully-connected CRF with domain transform (DT), a modern edge-preserving filtering method in which the amount of smoothing is controlled by a reference edge map. Domain transform filtering is several times faster than dense CRF inference and we show that it yields comparable semantic segmentation results, accurately capturing object boundaries. Importantly, our formulation allows learning the reference edge map from intermediate CNN features instead of using the image gradient magnitude as in standard DT filtering. This produces task-specific edges in an end-to-end trainable system optimizing the target semantic segmentation quality.
Attention to Scale: Scale-aware Semantic Image Segmentation
Jun 02, 2016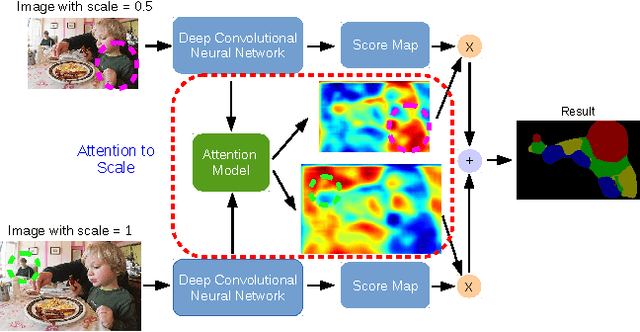
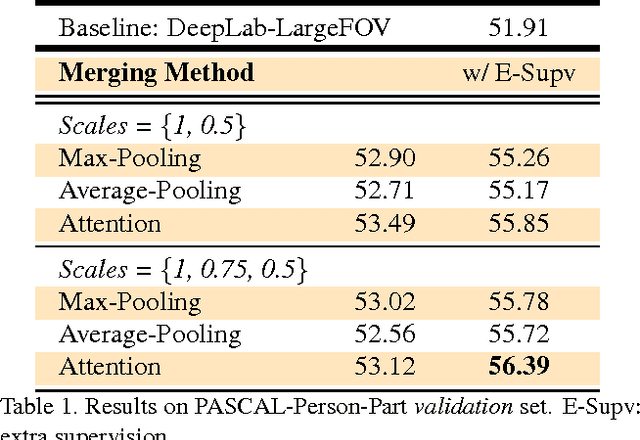
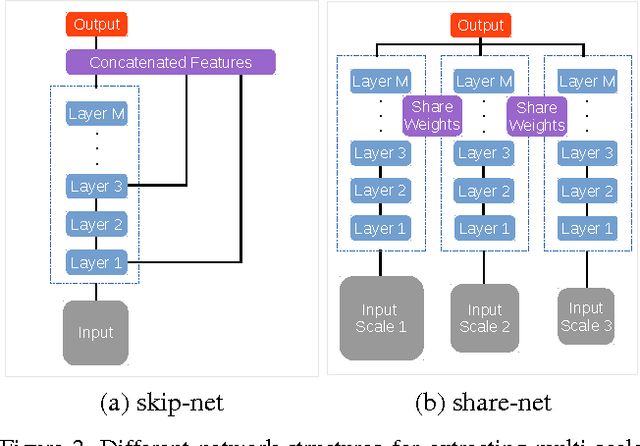

Incorporating multi-scale features in fully convolutional neural networks (FCNs) has been a key element to achieving state-of-the-art performance on semantic image segmentation. One common way to extract multi-scale features is to feed multiple resized input images to a shared deep network and then merge the resulting features for pixelwise classification. In this work, we propose an attention mechanism that learns to softly weight the multi-scale features at each pixel location. We adapt a state-of-the-art semantic image segmentation model, which we jointly train with multi-scale input images and the attention model. The proposed attention model not only outperforms average- and max-pooling, but allows us to diagnostically visualize the importance of features at different positions and scales. Moreover, we show that adding extra supervision to the output at each scale is essential to achieving excellent performance when merging multi-scale features. We demonstrate the effectiveness of our model with extensive experiments on three challenging datasets, including PASCAL-Person-Part, PASCAL VOC 2012 and a subset of MS-COCO 2014.
Zoom Better to See Clearer: Human and Object Parsing with Hierarchical Auto-Zoom Net
Mar 28, 2016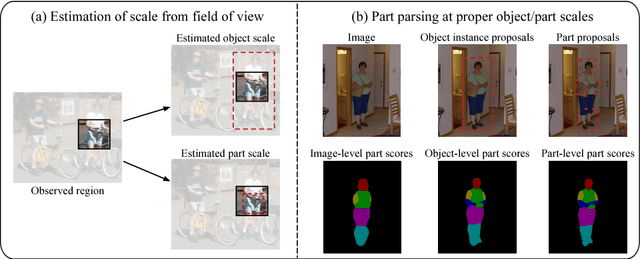
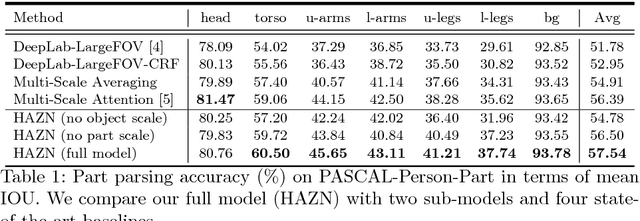
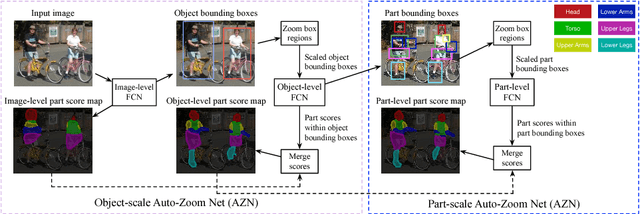
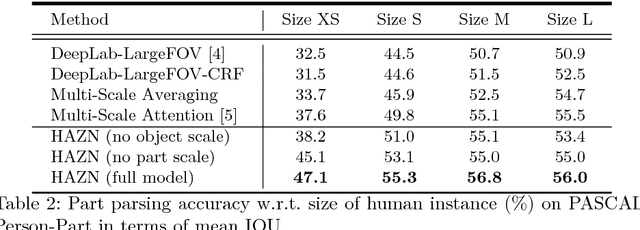
Parsing articulated objects, e.g. humans and animals, into semantic parts (e.g. body, head and arms, etc.) from natural images is a challenging and fundamental problem for computer vision. A big difficulty is the large variability of scale and location for objects and their corresponding parts. Even limited mistakes in estimating scale and location will degrade the parsing output and cause errors in boundary details. To tackle these difficulties, we propose a "Hierarchical Auto-Zoom Net" (HAZN) for object part parsing which adapts to the local scales of objects and parts. HAZN is a sequence of two "Auto-Zoom Net" (AZNs), each employing fully convolutional networks that perform two tasks: (1) predict the locations and scales of object instances (the first AZN) or their parts (the second AZN); (2) estimate the part scores for predicted object instance or part regions. Our model can adaptively "zoom" (resize) predicted image regions into their proper scales to refine the parsing. We conduct extensive experiments over the PASCAL part datasets on humans, horses, and cows. For humans, our approach significantly outperforms the state-of-the-arts by 5% mIOU and is especially better at segmenting small instances and small parts. We obtain similar improvements for parsing cows and horses over alternative methods. In summary, our strategy of first zooming into objects and then zooming into parts is very effective. It also enables us to process different regions of the image at different scales adaptively so that, for example, we do not need to waste computational resources scaling the entire image.
DeePM: A Deep Part-Based Model for Object Detection and Semantic Part Localization
Jan 26, 2016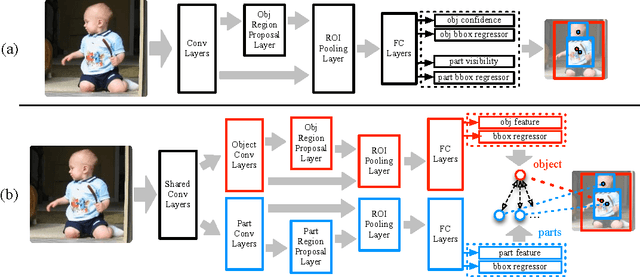
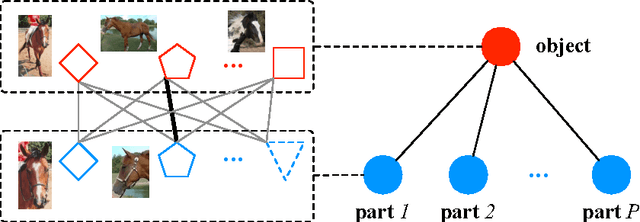
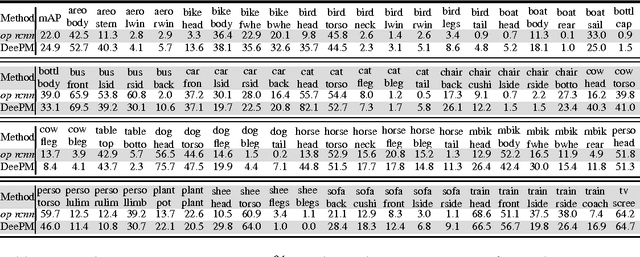

In this paper, we propose a deep part-based model (DeePM) for symbiotic object detection and semantic part localization. For this purpose, we annotate semantic parts for all 20 object categories on the PASCAL VOC 2012 dataset, which provides information on object pose, occlusion, viewpoint and functionality. DeePM is a latent graphical model based on the state-of-the-art R-CNN framework, which learns an explicit representation of the object-part configuration with flexible type sharing (e.g., a sideview horse head can be shared by a fully-visible sideview horse and a highly truncated sideview horse with head and neck only). For comparison, we also present an end-to-end Object-Part (OP) R-CNN which learns an implicit feature representation for jointly mapping an image ROI to the object and part bounding boxes. We evaluate the proposed methods for both the object and part detection performance on PASCAL VOC 2012, and show that DeePM consistently outperforms OP R-CNN in detecting objects and parts. In addition, it obtains superior performance to Fast and Faster R-CNNs in object detection.
PASCAL Boundaries: A Class-Agnostic Semantic Boundary Dataset
Nov 25, 2015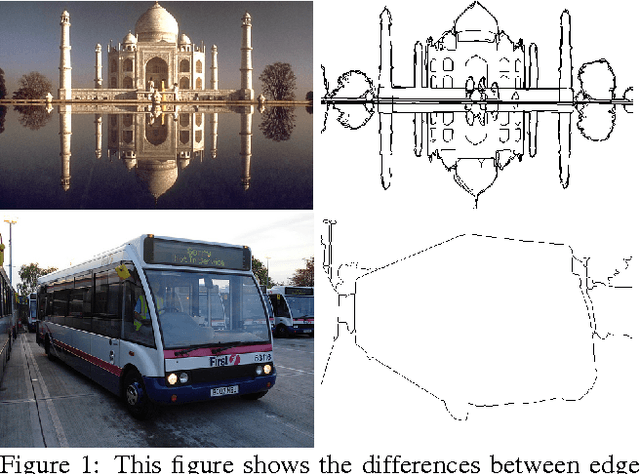
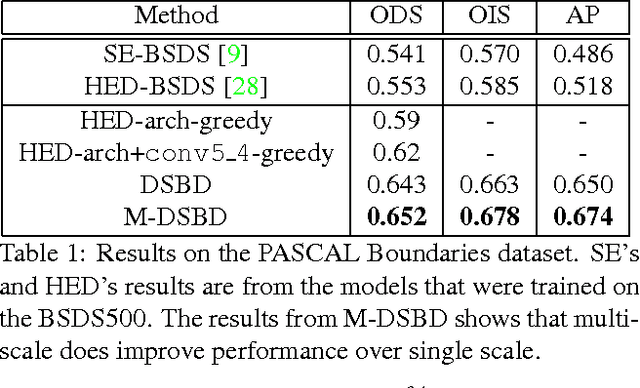
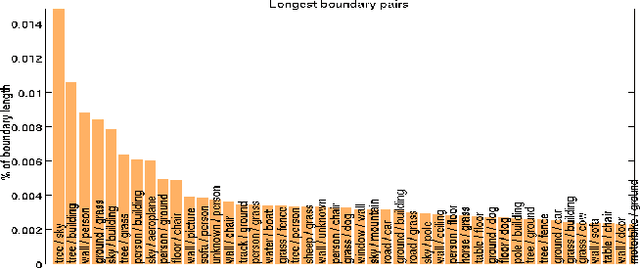

In this paper, we address the boundary detection task motivated by the ambiguities in current definition of edge detection. To this end, we generate a large database consisting of more than 10k images (which is 20x bigger than existing edge detection databases) along with ground truth boundaries between 459 semantic classes including both foreground objects and different types of background, and call it the PASCAL Boundaries dataset, which will be released to the community. In addition, we propose a novel deep network-based multi-scale semantic boundary detector and name it Multi-scale Deep Semantic Boundary Detector (M-DSBD). We provide baselines using models that were trained on edge detection and show that they transfer reasonably to the task of boundary detection. Finally, we point to various important research problems that this dataset can be used for.
Weakly- and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation
Oct 05, 2015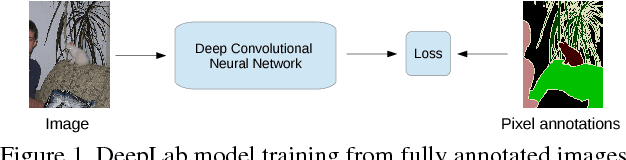
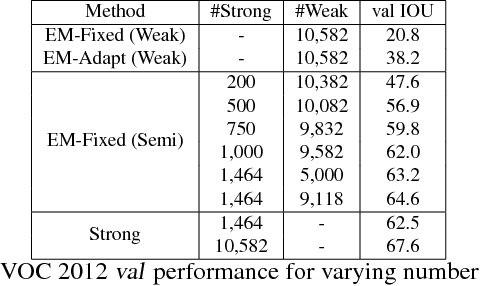
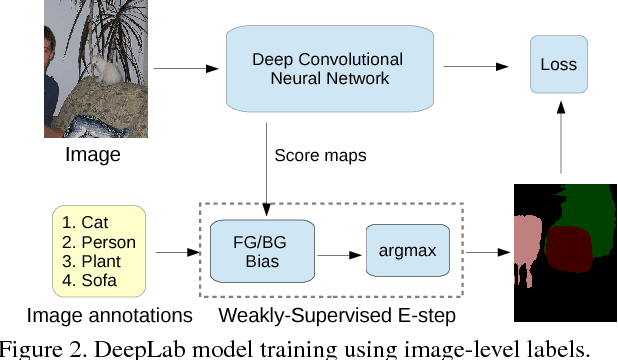
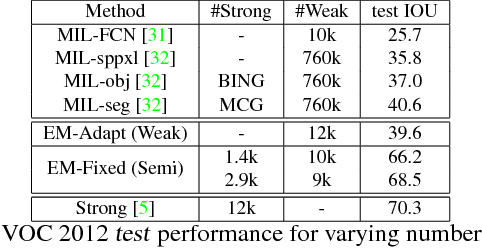
Deep convolutional neural networks (DCNNs) trained on a large number of images with strong pixel-level annotations have recently significantly pushed the state-of-art in semantic image segmentation. We study the more challenging problem of learning DCNNs for semantic image segmentation from either (1) weakly annotated training data such as bounding boxes or image-level labels or (2) a combination of few strongly labeled and many weakly labeled images, sourced from one or multiple datasets. We develop Expectation-Maximization (EM) methods for semantic image segmentation model training under these weakly supervised and semi-supervised settings. Extensive experimental evaluation shows that the proposed techniques can learn models delivering competitive results on the challenging PASCAL VOC 2012 image segmentation benchmark, while requiring significantly less annotation effort. We share source code implementing the proposed system at https://bitbucket.org/deeplab/deeplab-public.
Learning Deep Structured Models
Apr 27, 2015
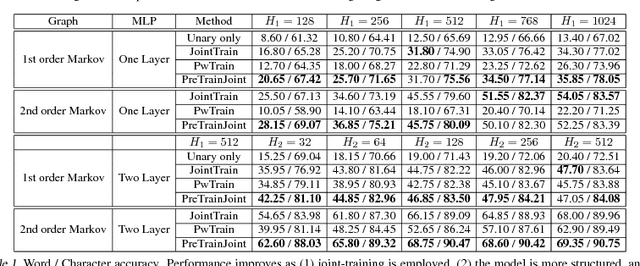

Many problems in real-world applications involve predicting several random variables which are statistically related. Markov random fields (MRFs) are a great mathematical tool to encode such relationships. The goal of this paper is to combine MRFs with deep learning algorithms to estimate complex representations while taking into account the dependencies between the output random variables. Towards this goal, we propose a training algorithm that is able to learn structured models jointly with deep features that form the MRF potentials. Our approach is efficient as it blends learning and inference and makes use of GPU acceleration. We demonstrate the effectiveness of our algorithm in the tasks of predicting words from noisy images, as well as multi-class classification of Flickr photographs. We show that joint learning of the deep features and the MRF parameters results in significant performance gains.
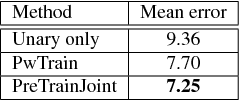
Representing Data by a Mixture of Activated Simplices
Dec 12, 2014
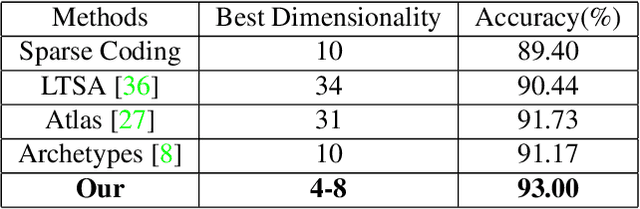


We present a new model which represents data as a mixture of simplices. Simplices are geometric structures that generalize triangles. We give a simple geometric understanding that allows us to learn a simplicial structure efficiently. Our method requires that the data are unit normalized (and thus lie on the unit sphere). We show that under this restriction, building a model with simplices amounts to constructing a convex hull inside the sphere whose boundary facets is close to the data. We call the boundary facets of the convex hull that are close to the data Activated Simplices. While the total number of bases used to build the simplices is a parameter of the model, the dimensions of the individual activated simplices are learned from the data. Simplices can have different dimensions, which facilitates modeling of inhomogeneous data sources. The simplicial structure is bounded --- this is appropriate for modeling data with constraints, such as human elbows can not bend more than 180 degrees. The simplices are easy to interpret and extremes within the data can be discovered among the vertices. The method provides good reconstruction and regularization. It supports good nearest neighbor classification and it allows realistic generative models to be constructed. It achieves state-of-the-art results on benchmark datasets, including 3D poses and digits.
Explain Images with Multimodal Recurrent Neural Networks
Oct 04, 2014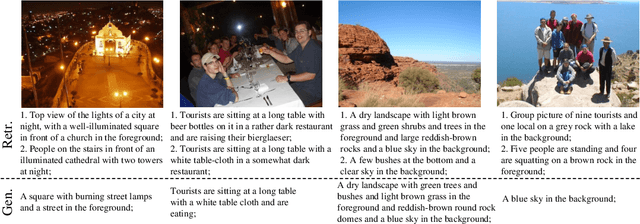
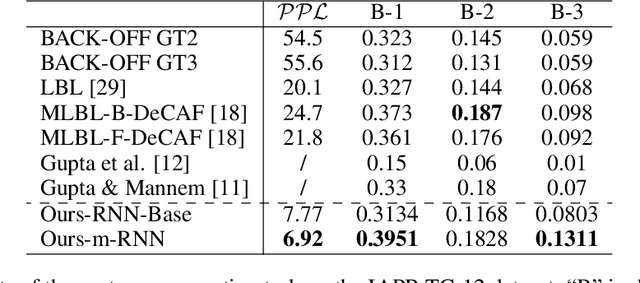
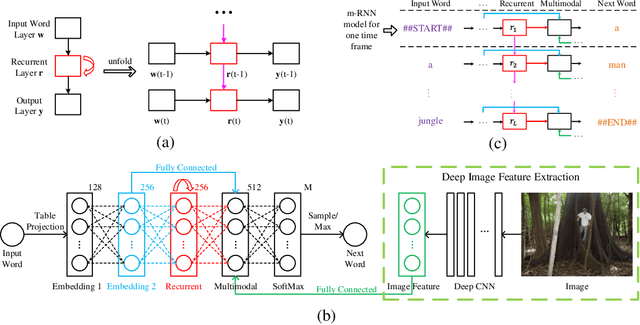

In this paper, we present a multimodal Recurrent Neural Network (m-RNN) model for generating novel sentence descriptions to explain the content of images. It directly models the probability distribution of generating a word given previous words and the image. Image descriptions are generated by sampling from this distribution. The model consists of two sub-networks: a deep recurrent neural network for sentences and a deep convolutional network for images. These two sub-networks interact with each other in a multimodal layer to form the whole m-RNN model. The effectiveness of our model is validated on three benchmark datasets (IAPR TC-12, Flickr 8K, and Flickr 30K). Our model outperforms the state-of-the-art generative method. In addition, the m-RNN model can be applied to retrieval tasks for retrieving images or sentences, and achieves significant performance improvement over the state-of-the-art methods which directly optimize the ranking objective function for retrieval.
The Secrets of Salient Object Segmentation
Jun 12, 2014
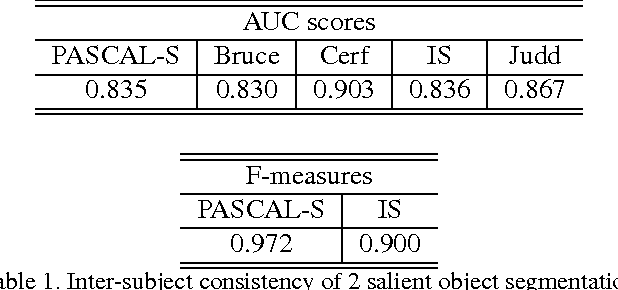
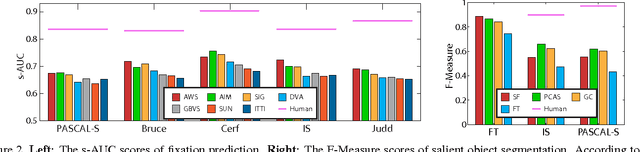
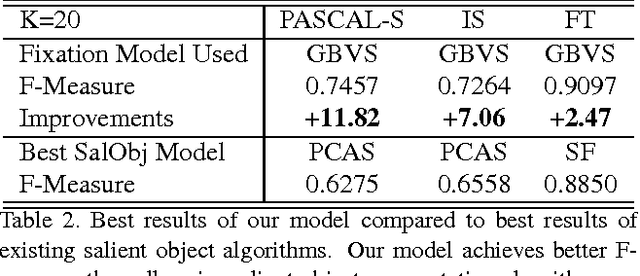
In this paper we provide an extensive evaluation of fixation prediction and salient object segmentation algorithms as well as statistics of major datasets. Our analysis identifies serious design flaws of existing salient object benchmarks, called the dataset design bias, by over emphasizing the stereotypical concepts of saliency. The dataset design bias does not only create the discomforting disconnection between fixations and salient object segmentation, but also misleads the algorithm designing. Based on our analysis, we propose a new high quality dataset that offers both fixation and salient object segmentation ground-truth. With fixations and salient object being presented simultaneously, we are able to bridge the gap between fixations and salient objects, and propose a novel method for salient object segmentation. Finally, we report significant benchmark progress on three existing datasets of segmenting salient objects