 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLodestar: An Online-Learning LLM Inference Router
May 31, 2026Efficiently serving large language model (LLM) inference tasks is crucial both for user-perceived latency such as time-to-first-token (TTFT) and for GPU utilization. However, LLM request routing, that is, assigning each inference request to a GPU instance, is particularly challenging: execution is highly input-dependent; batching and KV-cache reuse create strong cross-request coupling; and latency responds nonlinearly to context length, model/engine settings, and heterogeneous accelerators. As a result, simple traditional load balancing algorithms, and even heuristics tailored for LLM inference, fail to achieve good performance. We present Lodestar, a novel learning-based request routing system for distributed GPU clusters. Lodestar continuously collects a snapshot of the cluster at per-request level, including real-time instance state, request characteristics, and observed performance, and trains an online reward predictor that it uses to route inference requests to the instance that will maximize given reward (e.g., minimizing TTFT). Lodestar is cloud-native and works seamlessly with existing serving stacks (vLLM). With continuous online adaptation to changing workloads and infrastructure conditions, Lodestar achieves 1.41x lower average TTFT and 1.47x lower P99 TTFT on average (up to 2.15x/1.86x on homogeneous and 4.38x/4.42x on heterogeneous clusters) compared to a state-of-the-art prefix cache and load-aware heuristic, and learns these efficient routing strategies within about 5 minutes, based on experiments in a public cloud GPU cluster.
CCLab: Adversarial Testing of Learning- and Non-Learning-Based Congestion Controllers
May 21, 2026Congestion controllers (CCs) are critical to network performance, and yet their robustness under adverse conditions remains insufficiently understood. While recent learning-based CCs have demonstrated strong performance in controlled environments, it is unclear how they compare to traditional CCs when controllers' input signals are corrupted or when environmental conditions become systematically challenging. In this paper, we introduce CCLab, an adversarial testing framework for systematically evaluating the robustness of both learning-based and non-learning-based CCs. CCLab includes a reinforcement learning (RL)-based adversarial agent that operates in a closed loop with the congestion control policy, generating bounded perturbations either on input signals (feature-level) or on external network conditions (environment-level), while preserving realism through explicit constraints. Using this framework, we compare learning-based CCs with non-learning-based CCs under both feature-level and environment-level adversarial conditions. While both types of CCs suffer from performance degradation under adversarial testing, we find that learning-based CCs, in general, are more robust than traditional human-designed algorithms. Finally, we show that our adversarial traces can be used to train more robust CCs that outperform existing learning-based CCs under both challenging and normal conditions.
Assistants, Not Architects: The Role of LLMs in Networked Systems Design
Apr 28, 2026Designing the architecture of modern networked systems requires navigating a large, combinatorial space of hardware, systems, and configuration choices with complex cross-layer interactions. Architects must balance competing objectives such as performance, cost, and deployability while satisfying compatibility and resource constraints, often relying on scattered rules-of-thumb drawn from benchmarks, papers, documentation, and expert experience. This raises a natural question: can large language models (LLMs) reliably perform this kind of architectural reasoning? We find that they cannot. While LLMs produce plausible configurations, they frequently miss critical constraints, encode incorrect assumptions, and exhibit ``stickiness'' to familiar patterns. A natural workaround--iterative validation via simulation or experimentation--is often prohibitively expensive at scale and, in many cases, infeasible, particularly when comparing hardware-dependent alternatives. Motivated by this gap, we present Kepler, a lightweight reasoning framework for architecture design that combines structured, expert-driven specifications with SMT-based optimization. Kepler encodes architecturally significant properties--requirements, incompatibilities, and qualitative trade-offs--about systems, hardware, and workloads as constraints, and synthesizes feasible designs that optimize user-defined objectives. It operates at an abstract level, capturing ``rules-of-thumb'' rather than detailed system behavior, enabling tractable reasoning while preserving key interactions, and provides explanations for its decisions. Through experiments and case studies, we show that Kepler uncovers interactions missed by LLMs and supports systematic, explainable design exploration.
On-Device CPU Scheduling for Sense-React Systems
Aug 14, 2022

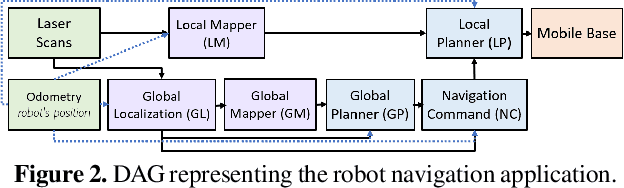
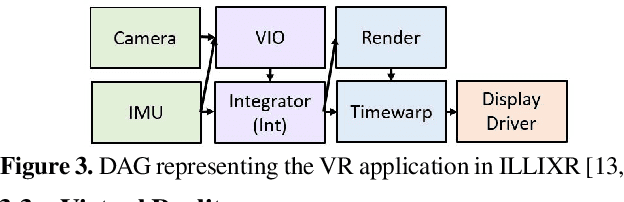
Sense-react systems (e.g. robotics and AR/VR) have to take highly responsive real-time actions, driven by complex decisions involving a pipeline of sensing, perception, planning, and reaction tasks. These tasks must be scheduled on resource-constrained devices such that the performance goals and the requirements of the application are met. This is a difficult scheduling problem that requires handling multiple scheduling dimensions, and variations in resource usage and availability. In practice, system designers manually tune parameters for their specific hardware and application, which results in poor generalization and increases the development burden. In this work, we highlight the emerging need for scheduling CPU resources at runtime in sense-react systems. We study three canonical applications (face tracking, robot navigation, and VR) to first understand the key scheduling requirements for such systems. Armed with this understanding, we develop a scheduling framework, Catan, that dynamically schedules compute resources across different components of an app so as to meet the specified application requirements. Through experiments with a prototype implemented on a widely-used robotics framework (ROS) and an open-source AR/VR platform, we show the impact of system scheduling on meeting the performance goals for the three applications, how Catan is able to achieve better application performance than hand-tuned configurations, and how it dynamically adapts to runtime variations.
Caramel: Accelerating Decentralized Distributed Deep Learning with Computation Scheduling
Apr 29, 2020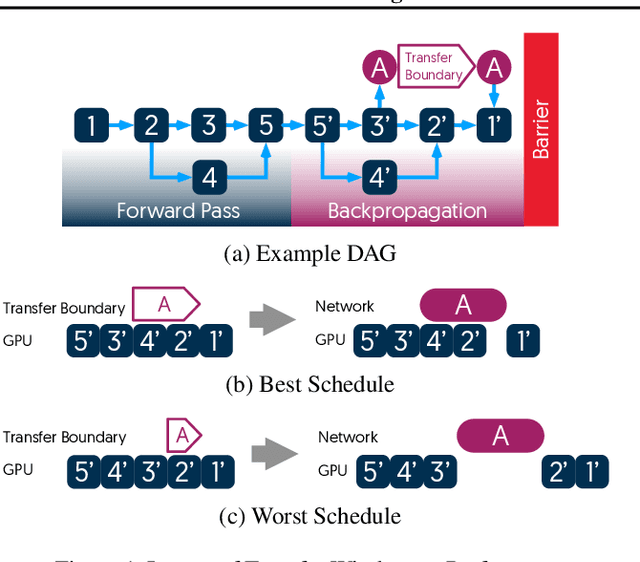
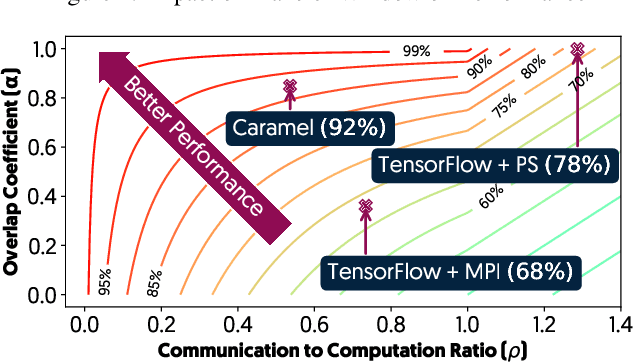
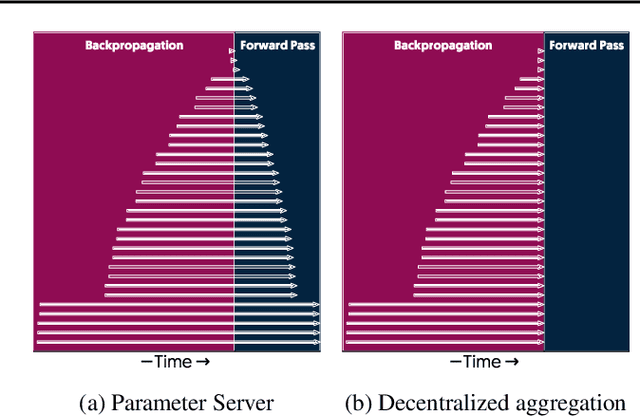
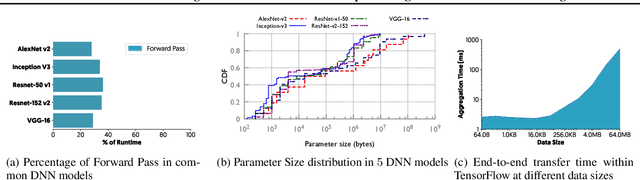
The method of choice for parameter aggregation in Deep Neural Network (DNN) training, a network-intensive task, is shifting from the Parameter Server model to decentralized aggregation schemes (AllReduce) inspired by theoretical guarantees of better performance. However, current implementations of AllReduce overlook the interdependence of communication and computation, resulting in significant performance degradation. In this paper, we develop Caramel, a system that accelerates decentralized distributed deep learning through model-aware computation scheduling and communication optimizations for AllReduce. Caramel achieves this goal through (a) computation DAG scheduling that expands the feasible window of transfer for each parameter (transfer boundaries), and (b) network optimizations for smoothening of the load including adaptive batching and pipelining of parameter transfers. Caramel maintains the correctness of the dataflow model, is hardware-independent, and does not require any user-level or framework-level changes. We implement Caramel over TensorFlow and show that the iteration time of DNN training can be improved by up to 3.62x in a cloud environment.