 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Estimator Selection for Off-Policy Evaluation
Feb 18, 2020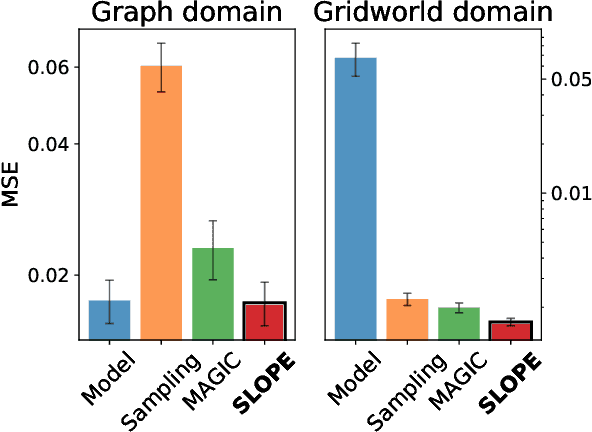

We develop a generic data-driven method for estimator selection in off-policy policy evaluation settings. We establish a strong performance guarantee for the method, showing that it is competitive with the oracle estimator, up to a constant factor. Via in-depth case studies in contextual bandits and reinforcement learning, we demonstrate the generality and applicability of the method. We also perform comprehensive experiments, demonstrating the empirical efficacy of our approach and comparing with related approaches. In both case studies, our method compares favorably with existing methods.
Reward-Free Exploration for Reinforcement Learning
Feb 07, 2020
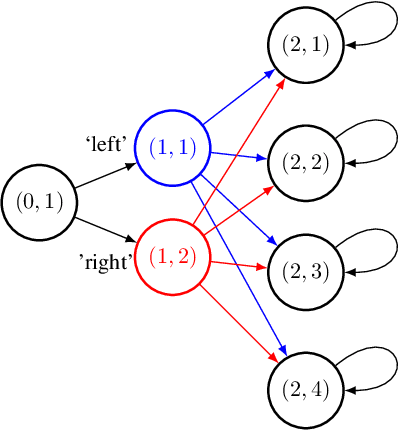
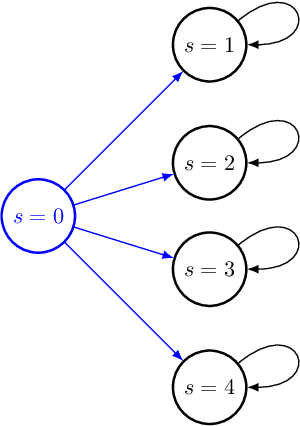
Exploration is widely regarded as one of the most challenging aspects of reinforcement learning (RL), with many naive approaches succumbing to exponential sample complexity. To isolate the challenges of exploration, we propose a new "reward-free RL" framework. In the exploration phase, the agent first collects trajectories from an MDP $\mathcal{M}$ without a pre-specified reward function. After exploration, it is tasked with computing near-optimal policies under for $\mathcal{M}$ for a collection of given reward functions. This framework is particularly suitable when there are many reward functions of interest, or when the reward function is shaped by an external agent to elicit desired behavior. We give an efficient algorithm that conducts $\tilde{\mathcal{O}}(S^2A\mathrm{poly}(H)/\epsilon^2)$ episodes of exploration and returns $\epsilon$-suboptimal policies for an arbitrary number of reward functions. We achieve this by finding exploratory policies that visit each "significant" state with probability proportional to its maximum visitation probability under any possible policy. Moreover, our planning procedure can be instantiated by any black-box approximate planner, such as value iteration or natural policy gradient. We also give a nearly-matching $\Omega(S^2AH^2/\epsilon^2)$ lower bound, demonstrating the near-optimality of our algorithm in this setting.
Algebraic and Analytic Approaches for Parameter Learning in Mixture Models
Jan 19, 2020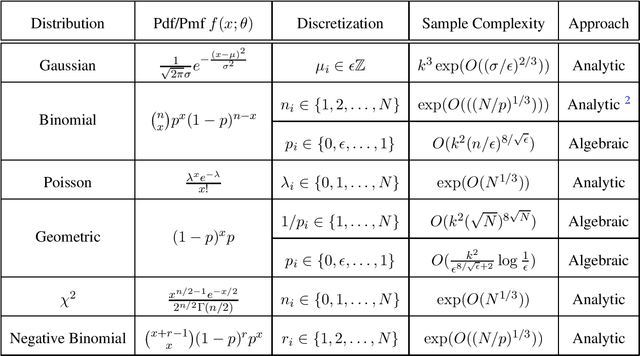
We present two different approaches for parameter learning in several mixture models in one dimension. Our first approach uses complex-analytic methods and applies to Gaussian mixtures with shared variance, binomial mixtures with shared success probability, and Poisson mixtures, among others. An example result is that $\exp(O(N^{1/3}))$ samples suffice to exactly learn a mixture of $k<N$ Poisson distributions, each with integral rate parameters bounded by $N$. Our second approach uses algebraic and combinatorial tools and applies to binomial mixtures with shared trial parameter $N$ and differing success parameters, as well as to mixtures of geometric distributions. Again, as an example, for binomial mixtures with $k$ components and success parameters discretized to resolution $\epsilon$, $O(k^2(N/\epsilon)^{8/\sqrt{\epsilon}})$ samples suffice to exactly recover the parameters. For some of these distributions, our results represent the first guarantees for parameter estimation.
Scalable Hierarchical Clustering with Tree Grafting
Dec 31, 2019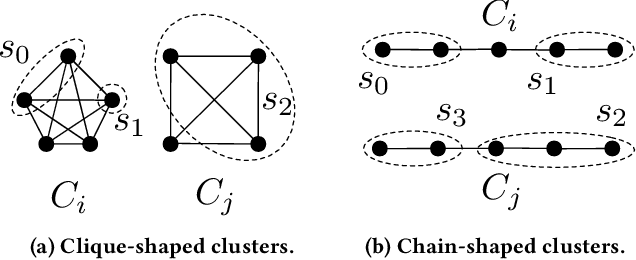
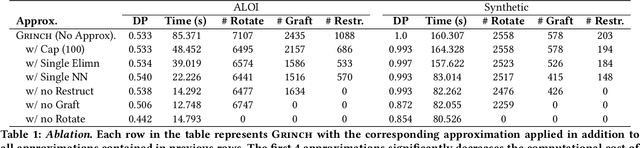
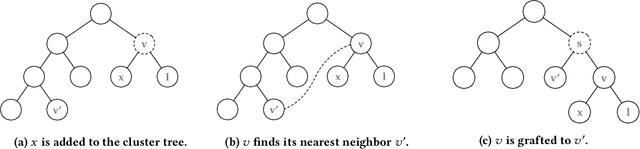
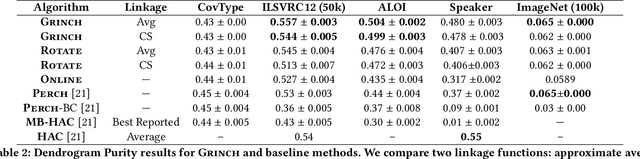
We introduce Grinch, a new algorithm for large-scale, non-greedy hierarchical clustering with general linkage functions that compute arbitrary similarity between two point sets. The key components of Grinch are its rotate and graft subroutines that efficiently reconfigure the hierarchy as new points arrive, supporting discovery of clusters with complex structure. Grinch is motivated by a new notion of separability for clustering with linkage functions: we prove that when the model is consistent with a ground-truth clustering, Grinch is guaranteed to produce a cluster tree containing the ground-truth, independent of data arrival order. Our empirical results on benchmark and author coreference datasets (with standard and learned linkage functions) show that Grinch is more accurate than other scalable methods, and orders of magnitude faster than hierarchical agglomerative clustering.
Optimism in Reinforcement Learning with Generalized Linear Function Approximation
Dec 09, 2019We design a new provably efficient algorithm for episodic reinforcement learning with generalized linear function approximation. We analyze the algorithm under a new expressivity assumption that we call "optimistic closure," which is strictly weaker than assumptions from prior analyses for the linear setting. With optimistic closure, we prove that our algorithm enjoys a regret bound of $\tilde{O}(\sqrt{d^3 T})$ where $d$ is the dimensionality of the state-action features and $T$ is the number of episodes. This is the first statistically and computationally efficient algorithm for reinforcement learning with generalized linear functions.
Kinematic State Abstraction and Provably Efficient Rich-Observation Reinforcement Learning
Nov 13, 2019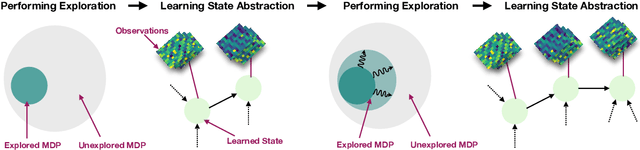

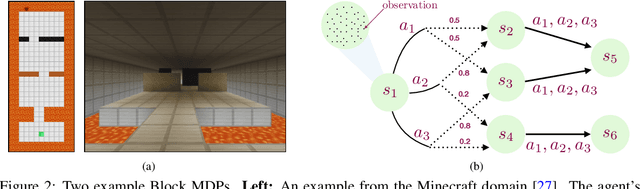

We present an algorithm, HOMER, for exploration and reinforcement learning in rich observation environments that are summarizable by an unknown latent state space. The algorithm interleaves representation learning to identify a new notion of kinematic state abstraction with strategic exploration to reach new states using the learned abstraction. The algorithm provably explores the environment with sample complexity scaling polynomially in the number of latent states and the time horizon, and, crucially, with no dependence on the size of the observation space, which could be infinitely large. This exploration guarantee further enables sample-efficient global policy optimization for any reward function. On the computational side, we show that the algorithm can be implemented efficiently whenever certain supervised learning problems are tractable. Empirically, we evaluate HOMER on a challenging exploration problem, where we show that the algorithm is exponentially more sample efficient than standard reinforcement learning baselines.
Sample Complexity of Learning Mixtures of Sparse Linear Regressions
Oct 30, 2019In the problem of learning mixtures of linear regressions, the goal is to learn a collection of signal vectors from a sequence of (possibly noisy) linear measurements, where each measurement is evaluated on an unknown signal drawn uniformly from this collection. This setting is quite expressive and has been studied both in terms of practical applications and for the sake of establishing theoretical guarantees. In this paper, we consider the case where the signal vectors are sparse; this generalizes the popular compressed sensing paradigm. We improve upon the state-of-the-art results as follows: In the noisy case, we resolve an open question of Yin et al. (IEEE Transactions on Information Theory, 2019) by showing how to handle collections of more than two vectors and present the first robust reconstruction algorithm, i.e., if the signals are not perfectly sparse, we still learn a good sparse approximation of the signals. In the noiseless case, as well as in the noisy case, we show how to circumvent the need for a restrictive assumption required in the previous work. Our techniques are quite different from those in the previous work: for the noiseless case, we rely on a property of sparse polynomials and for the noisy case, we provide new connections to learning Gaussian mixtures and use ideas from the theory of error-correcting codes.
Robust Dynamic Assortment Optimization in the Presence of Outlier Customers
Oct 09, 2019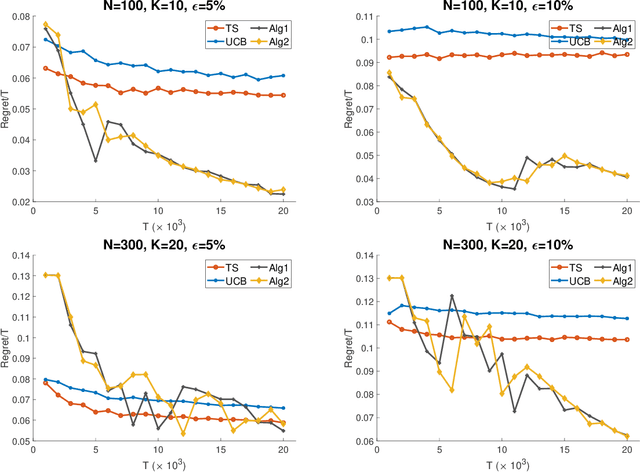
We consider the dynamic assortment optimization problem under the multinomial logit model (MNL) with unknown utility parameters. The main question investigated in this paper is model mis-specification under the $\varepsilon$-contamination model, which is a fundamental model in robust statistics and machine learning. In particular, throughout a selling horizon of length $T$, we assume that customers make purchases according to a well specified underlying multinomial logit choice model in a ($1-\varepsilon$)-fraction of the time periods, and make arbitrary purchasing decisions instead in the remaining $\varepsilon$-fraction of the time periods. In this model, we develop a new robust online assortment optimization policy via an active elimination strategy. We establish both upper and lower bounds on the regret, and show that our policy is optimal up to logarithmic factor in T when the assortment capacity is constant. Furthermore, we develop a fully adaptive policy that does not require any prior knowledge of the contamination parameter $\varepsilon$. Our simulation study shows that our policy outperforms the existing policies based on upper confidence bounds (UCB) and Thompson sampling.
Doubly robust off-policy evaluation with shrinkage
Jul 22, 2019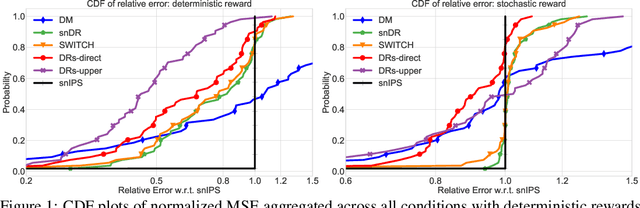

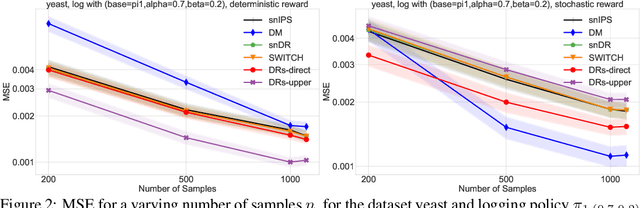
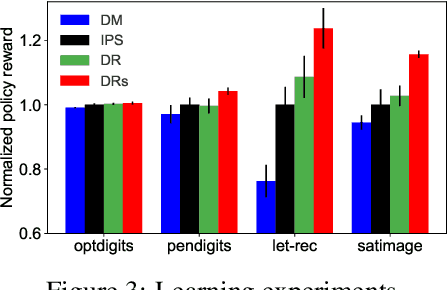
We design a new family of estimators for off-policy evaluation in contextual bandits. Our estimators are based on the asymptotically optimal approach of doubly robust estimation, but they shrink importance weights to obtain a better bias-variance tradeoff in finite samples. Our approach adapts importance weights to the quality of a reward predictor, interpolating between doubly robust estimation and direct modeling. When the reward predictor is poor, we recover previously studied weight clipping, but when the reward predictor is good, we obtain a new form of shrinkage. To navigate between these regimes and tune the shrinkage coefficient, we design a model selection procedure, which we prove is never worse than the doubly robust estimator. Extensive experiments on bandit benchmark problems show that our estimators are highly adaptive and typically outperform state-of-the-art methods.
Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds
Jun 09, 2019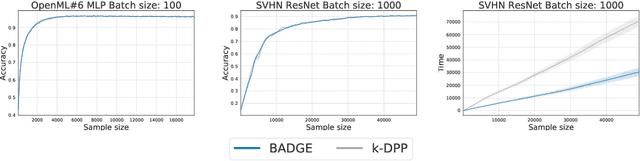
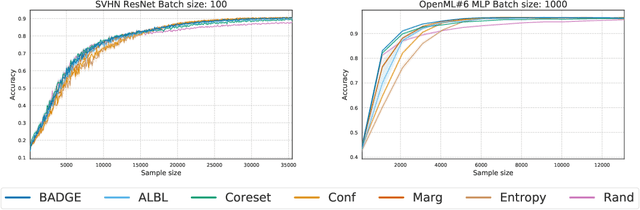
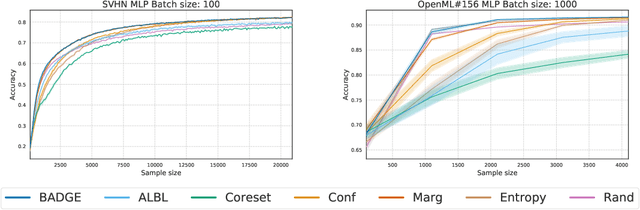
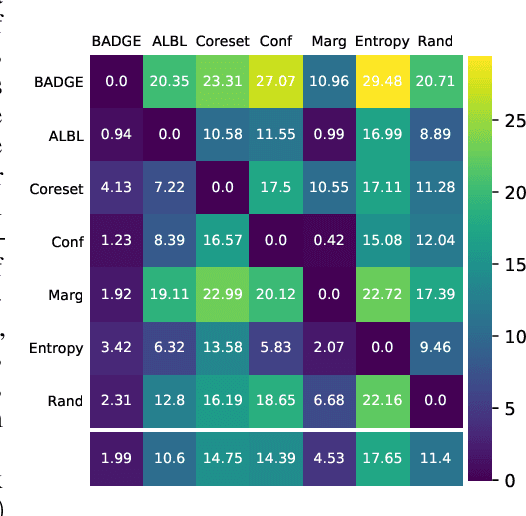
We design a new algorithm for batch active learning with deep neural network models. Our algorithm, Batch Active learning by Diverse Gradient Embeddings (BADGE), samples groups of points that are disparate and high-magnitude when represented in a hallucinated gradient space, a strategy designed to incorporate both predictive uncertainty and sample diversity into every selected batch. Crucially, BADGE trades off between diversity and uncertainty without requiring any hand-tuned hyperparameters. We show that while other approaches sometimes succeed for particular batch sizes or architectures, BADGE consistently performs as well or better, making it a versatile option for practical active learning problems.